


Large language models (LLMs) have considerably altered the landscape of natural language processing, enabling machines to understand and generate human language much more effectively than ever. Normally, these models are pre-trained on huge and parallel corpora and then fine-tuned to connect them to human tasks or preferences. Therefore, This process has led to great advances in the field that the LLMs have become very useful tools for different applications, from language translation to sentiment analysis. Active research is still ongoing to address the relationship between pre-training and fine-tuning since this understanding will lead to the further optimization of the models for better performance and utility.
One of the challenging issues in training the LLMs is the tradeoff between the gains in the pre-training stage and the fine-tuning stage. Pre-training has been key in endowing models with a broad understanding of language, but it is often debatable how optimal this pre-training point is before fine-tuning. Although this is necessary sometimes for conditioning the model for a specific task, it can sometimes lead to a loss of prior learned information or embedding some biases that were initially absent during the pre-training of the model. It is a delicate balance between keeping general knowledge and fine-tuning for specific task performance.
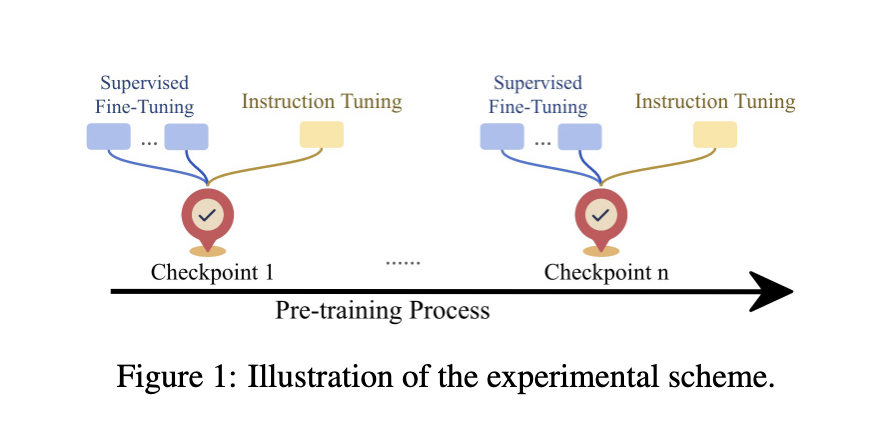
Existing approaches take pre-training and fine-tuning as two separate steps: in pre-training, the model is presented with a massive text dataset with a huge vocabulary, which the model learns to find the underlying structures and patterns of language. Fine-tuning continues training on smaller, task-specific datasets to make it specialize in certain tasks. A generic pre-training followed by a task-specific fine-tuning approach likely can only fulfill some of the potential synergies in the two stages. Researchers have started looking into whether a more integrated approach, in which fine-tuning is introduced at several crossroads in the pre-training process, would achieve better performance.
A novel methodology by a research group from Johns Hopkins University explored the tradeoff between pre-training and fine-tuning. The authors further looked into how continual pre-training would affect the capabilities of fine-tuned models through fine-tuning many intermediate checkpoints of a pre-trained model. The experiments were conducted on big-data, pre-trained, large-scale models using checkpoints from different stages of the pre-training process. Fine-tuning checkpoints at various points of model development were done through a supervised and instruction-based approach. This novel methodology helped the researchers compare how their model operationalizes at different stages of the development process relative to others, revealing the best strategies for training LLMs.
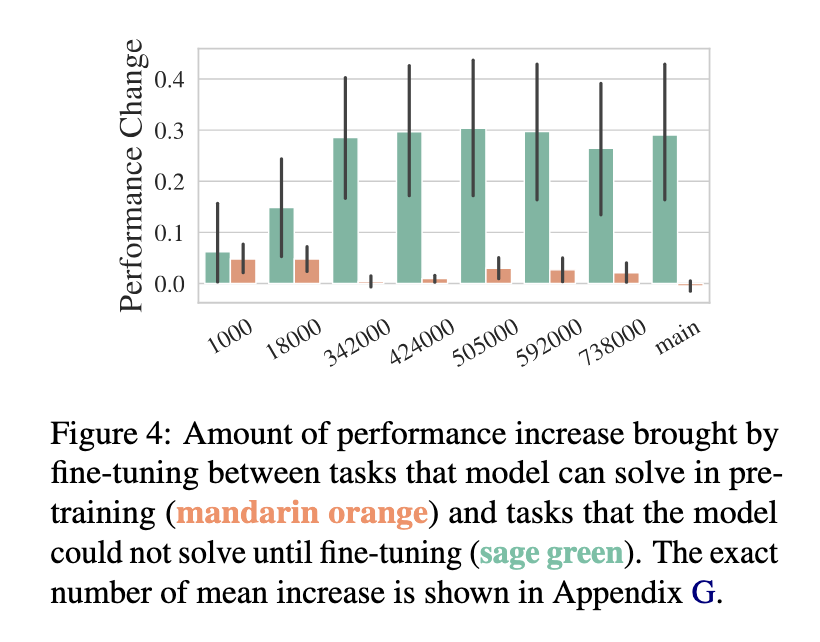
The methodology is deep and discusses the performance of the model across several tasks, such as natural language inference, paraphrase detection, and summarization, over 18 datasets. They concluded that continual pre-training leads to potential hidden ways in the model, revealed only after fine-tuning. Specifically, in tasks to which the model had underperformed at first in pre-training, significant improvements could be observed after fine-tuning, with overall improvement for the tasks being around in the range of 10% to 30%. In contrast, functions for which the model worked satisfactorily in the pre-training phase evidenced less dramatic improvements in the fine-tuning phase, which implies that fine-tuning benefits tasks for which it has not adequately been learned beforehand.
Specific subtle features associated with the fine-tuning process were also revealed during the study. While fine-tuning generally enhances the model’s performance, at the other end, it causes the model to forget the already learned information because, most of the time, this happens when the fine-tuning target is mismatched with the pre-training target, where this regards the tasks, being not directly related to the targets of fine-tuning. For example, after fine-tuning several natural language inference tasks, the model deteriorates when evaluated on a paraphrase identification task. These behaviors have shown a tradeoff between improving the fine-tuned task and having more general capabilities. Experimentally, they show that this kind of forgetting can be partly alleviated by continuing the massive pre-training steps during the fine-tuning stages, which preserve the large model’s knowledge base.

The performance results of the fine-tuned models were interesting. In the natural language inference tasks, the fine-tuned model showed a top performance of 25% compared with the pre-trained-only model. The accuracy of the paraphrase detection task improved by 15%, while it improved by about 20% for both summarization tasks. These results strongly underscore the importance of fine-tuning about really unlocking the full potential of pre-trained models, especially in cases wherein the baseline model performs poorly.
In conclusion, this work by Johns Hopkins University researchers is very interesting in that it provides insight into the dynamic relationship between pre-training and fine-tuning in additional LLMs. It is important to follow up after laying a strong foundation in a preliminary stage; without it, the fine-tuning modeling process will not improve the ability of the model. The research shows that the right balance between these two stages exists in performances, promising further new directions for NLP. This new direction will potentially lead to the effectiveness of training paradigms that simultaneously apply pre-training and fine-tuning in a way that benefits more powerful and flexible language models.
Check out the Paper. All credit for this research goes to the researchers of this project. Also, don’t forget to follow us on Twitter and join our Telegram Channel and LinkedIn Group. If you like our work, you will love our newsletter..
Don’t Forget to join our 48k+ ML SubReddit
Find Upcoming AI Webinars here
The post This AI Paper from John Hopkins Introduces Continual Pre-training and Fine-Tuning for Enhanced LLM Performance appeared first on MarkTechPost.
