
Published on July 25, 2024 10:00 PM GMT
Work done at FAR AI.
There has been a lot of conceptual work on mesa-optimizers: neural networks that develop internal goals that may differ from their training objectives (the inner alignment problem). There is an abundance of good ideas for empirical work (find search in a NN, interpret it), but very little actual execution, partly because we did not have a clear-cut example of a mesa-optimizer to study. Until now.[1]
We have replicated the mesa-optimizer that Guez et al. (2019) found, and released it open-source as a model organism for inner alignment research. In brief, Guez et al. trained a recurrent neural network (RNN) with model-free RL to play Sokoban. They noticed that if you give the RNN more time to think by repeating the initial observation at inference time, its performance increases. This is highly suggestive of planning!
We investigate this "planning effect" in a black-box way. We find that often, the RNN learns to "pace" before attempting to solve the level, likely to get more computation and find a solution. When we give the RNN time to think, it finds the solution in the extra thinking time and executes it straight away.
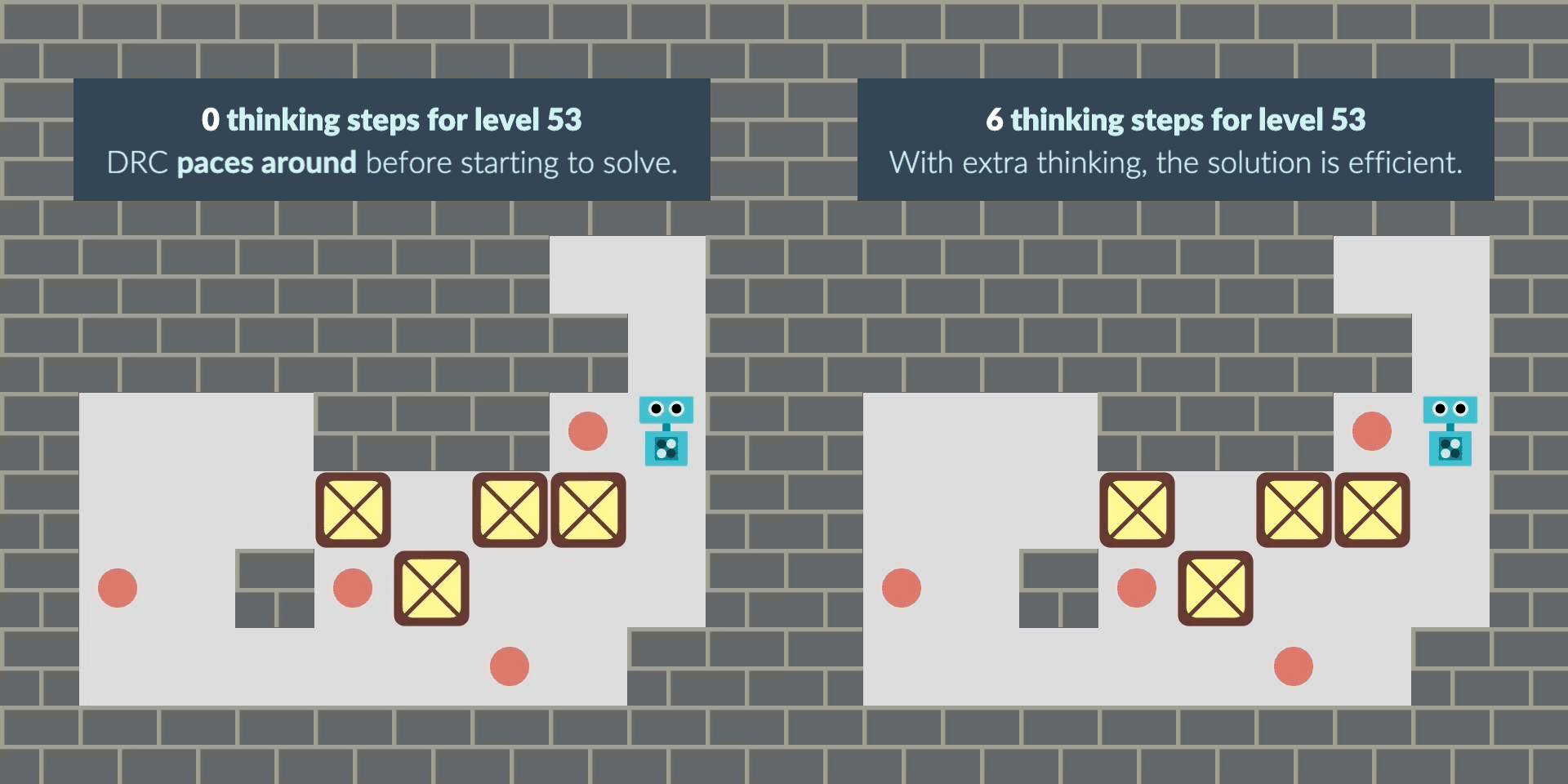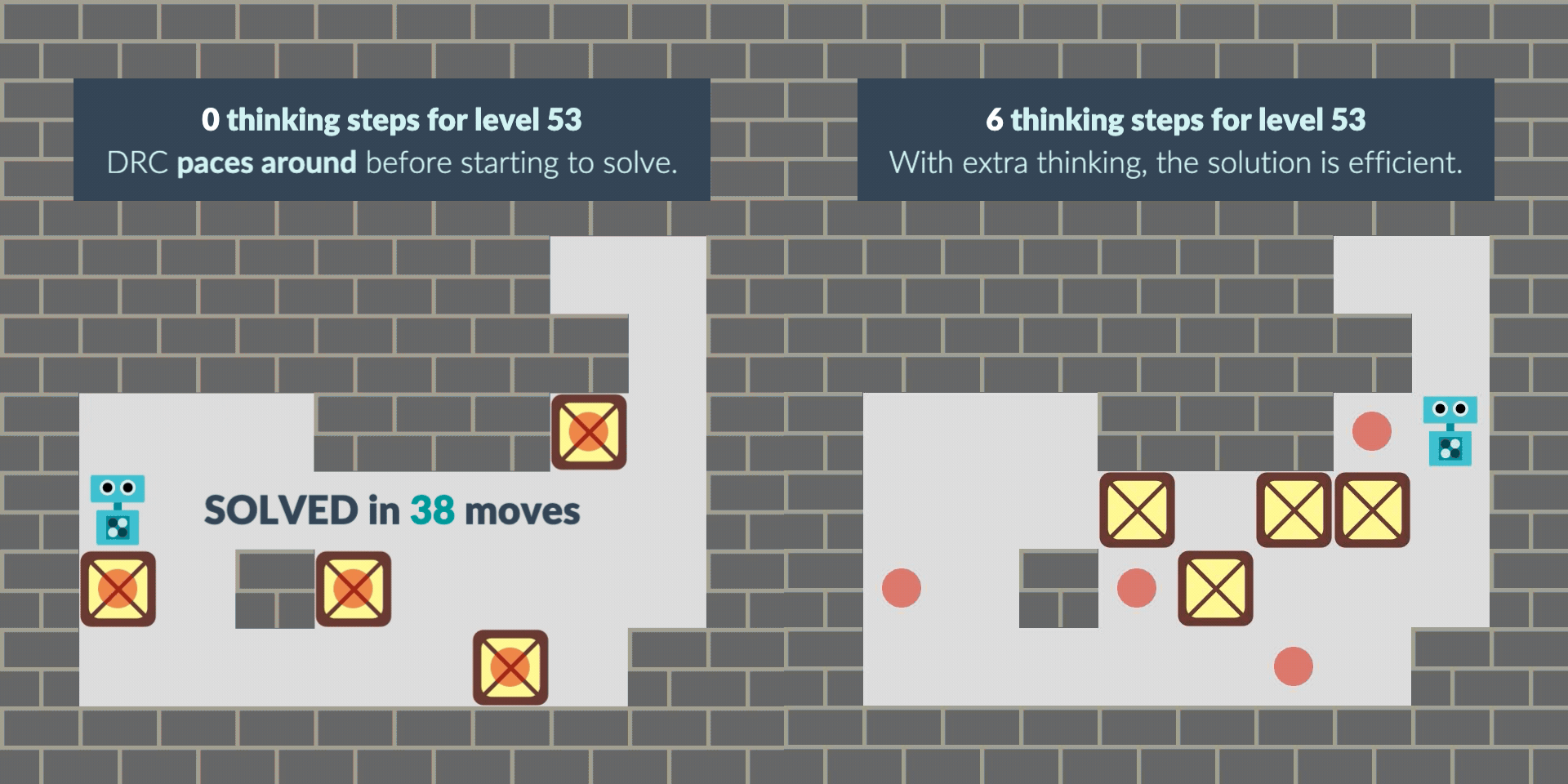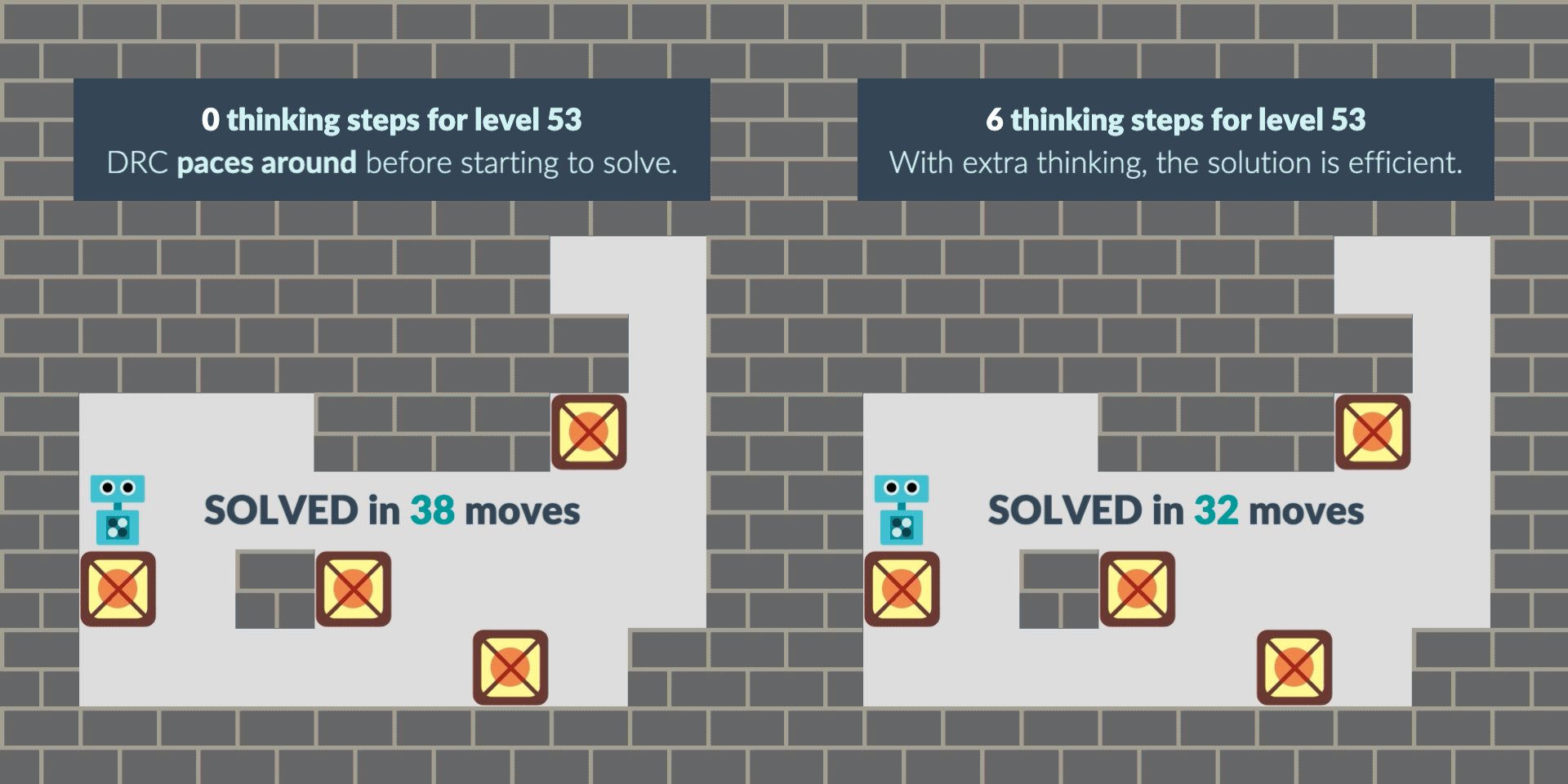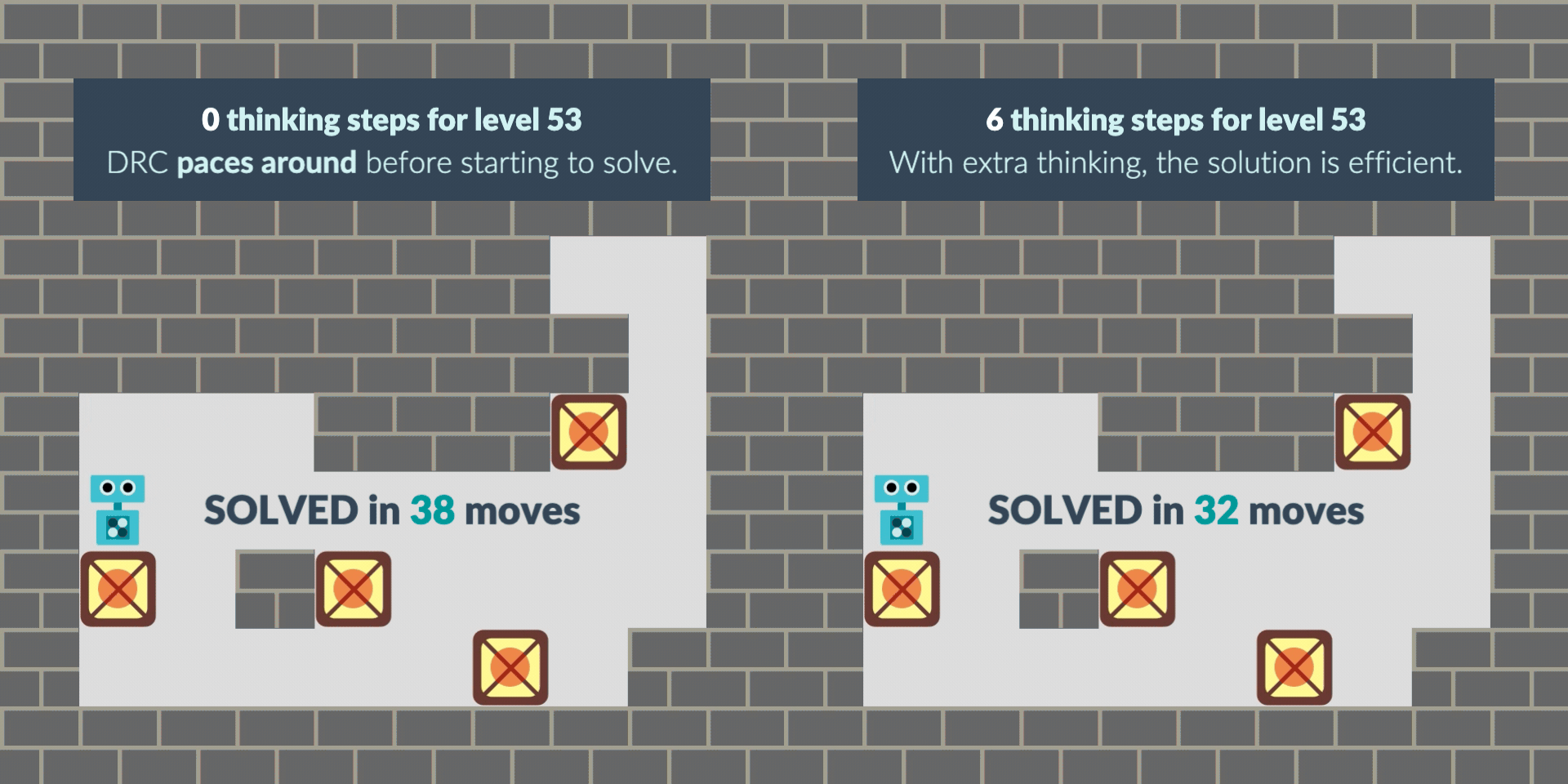
In other cases, the RNN sometimes starts with a greedy solution and locks itself out of the solution. With thinking time, the RNN finds the non-myopic solution, avoiding the lock and solving the level. Note that this greedy behavior may be bounded-rational given the -0.1 penalty per step: solving fewer levels but solving them more quickly can pay off.
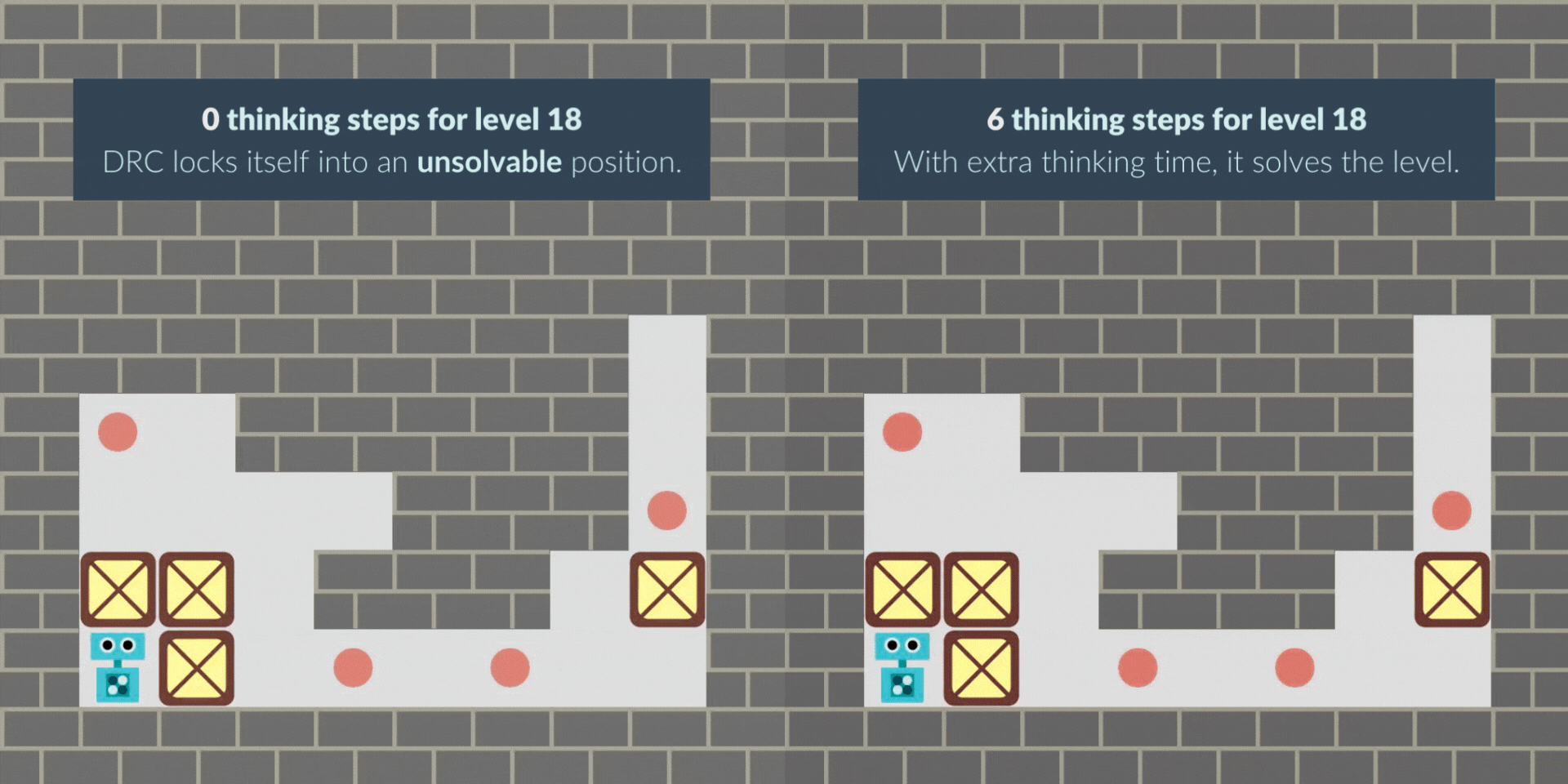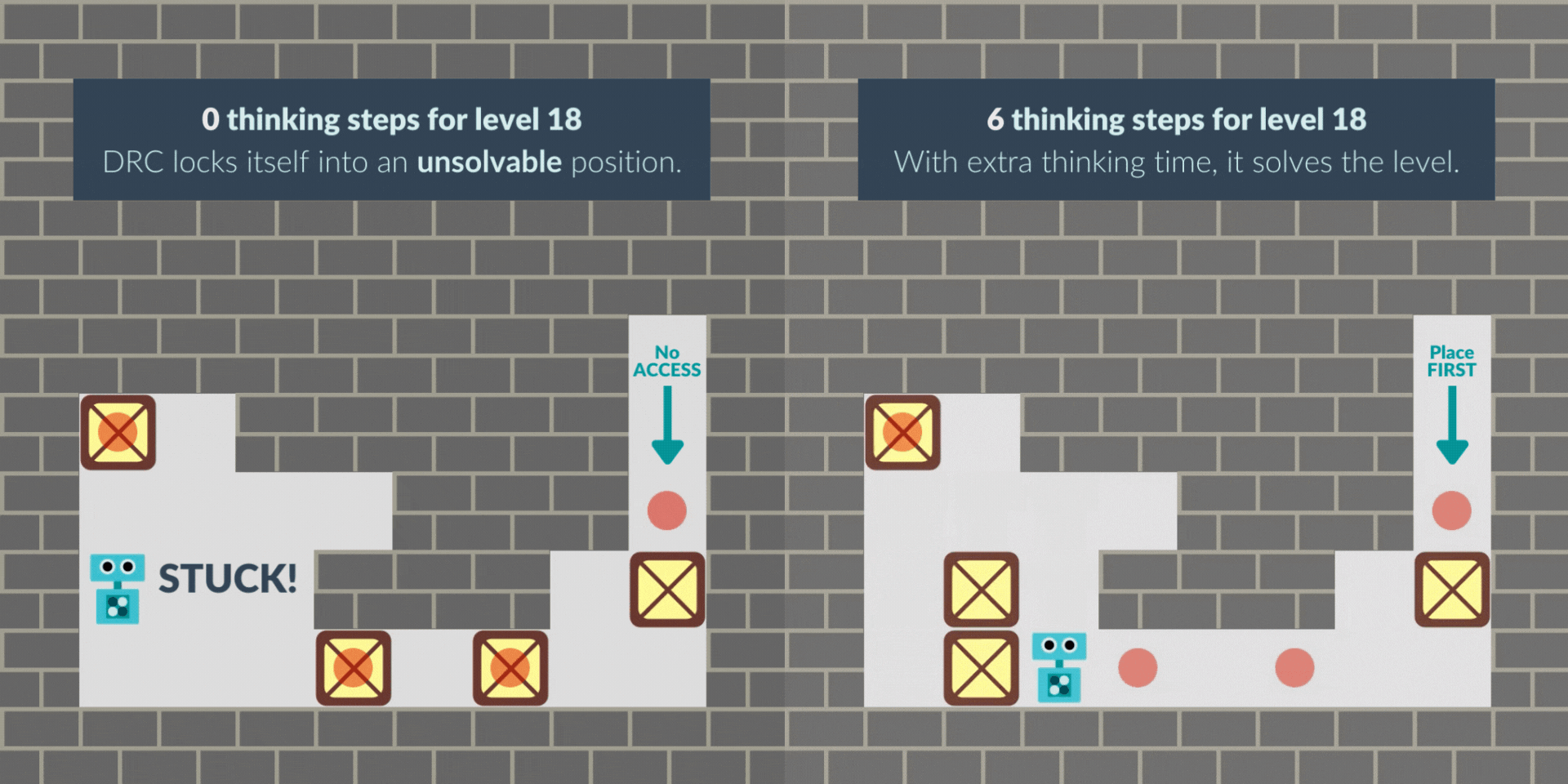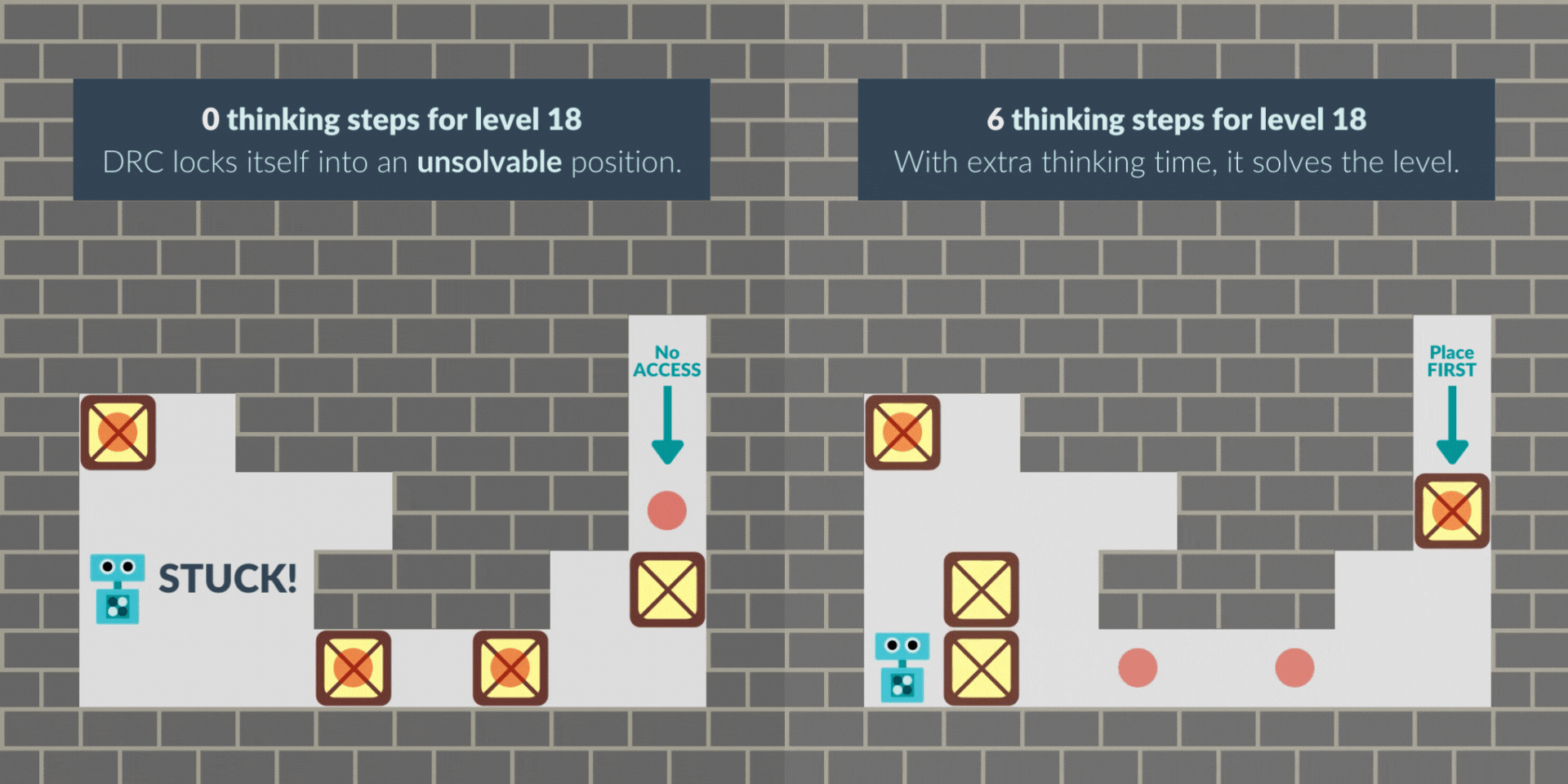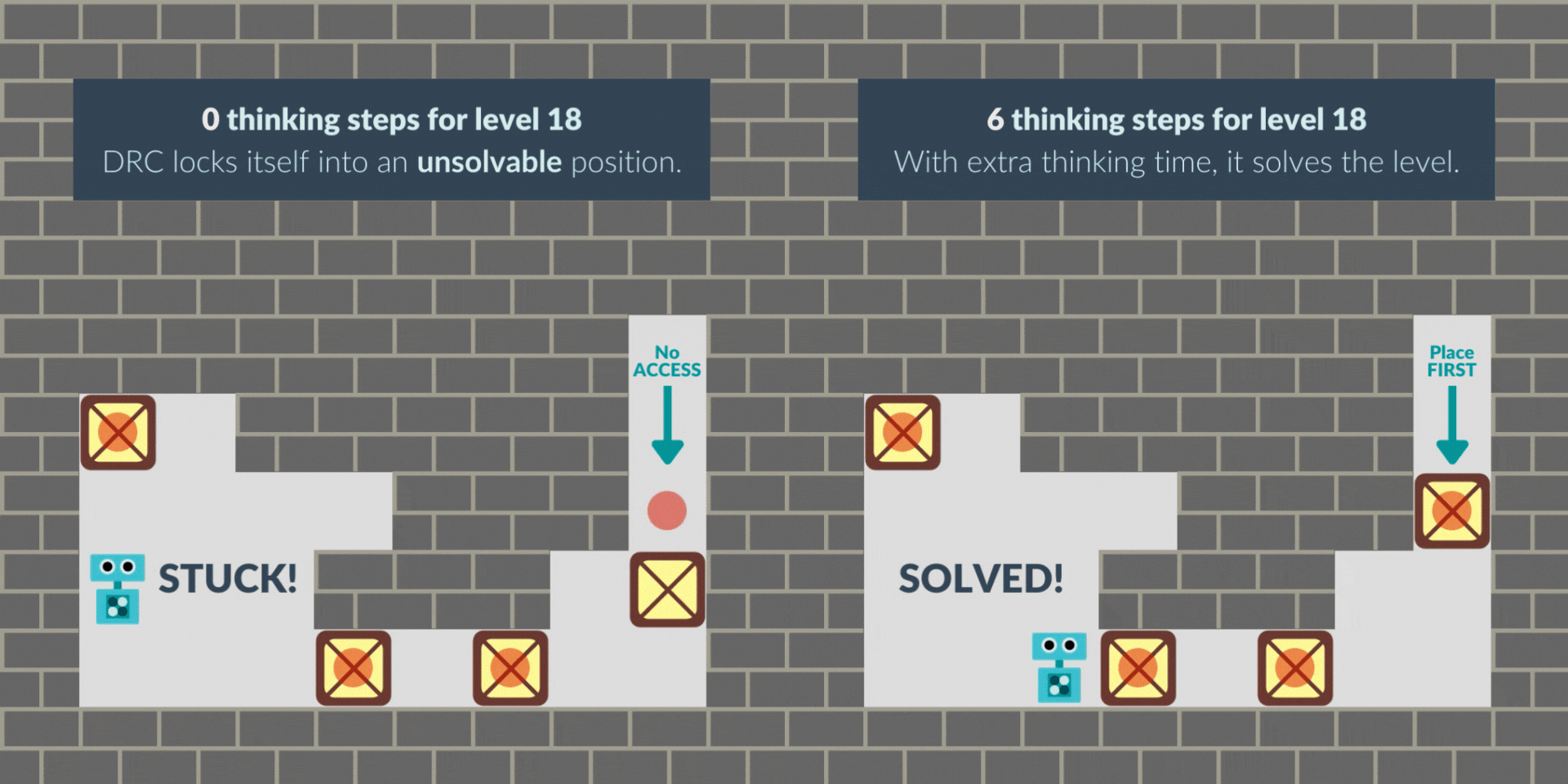
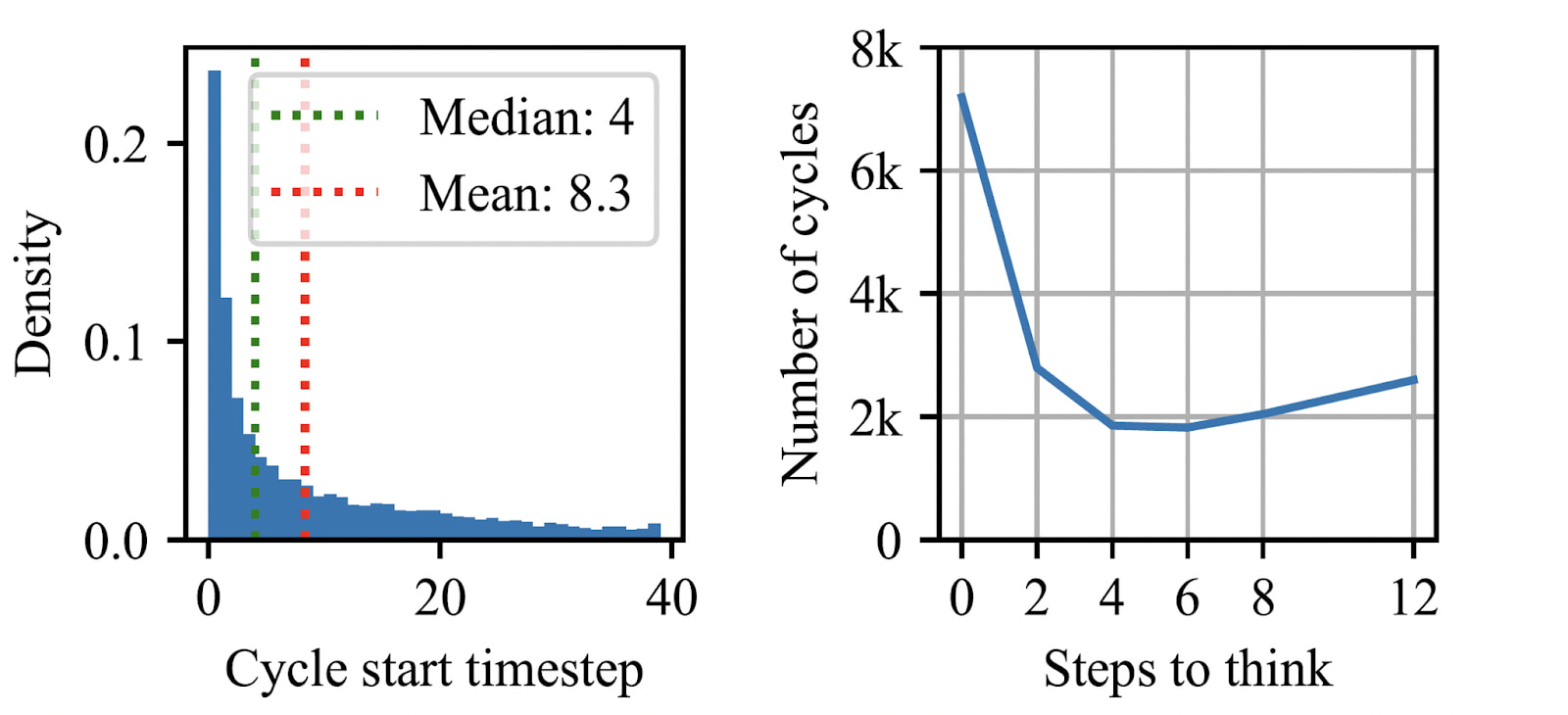
These are illustrative examples, but we have quantitative evidence too. We operationalize the pacing behavior as whatever creates a cycle in the sequence of environment states. If we give the RNN time to think at level start, it does not 'pace' anymore: 75% of cycles that occur in the first 5 steps disappear. Time to think in the middle of a level also substitutes cycles: 82% of N-step cycles disappear with N steps to think.
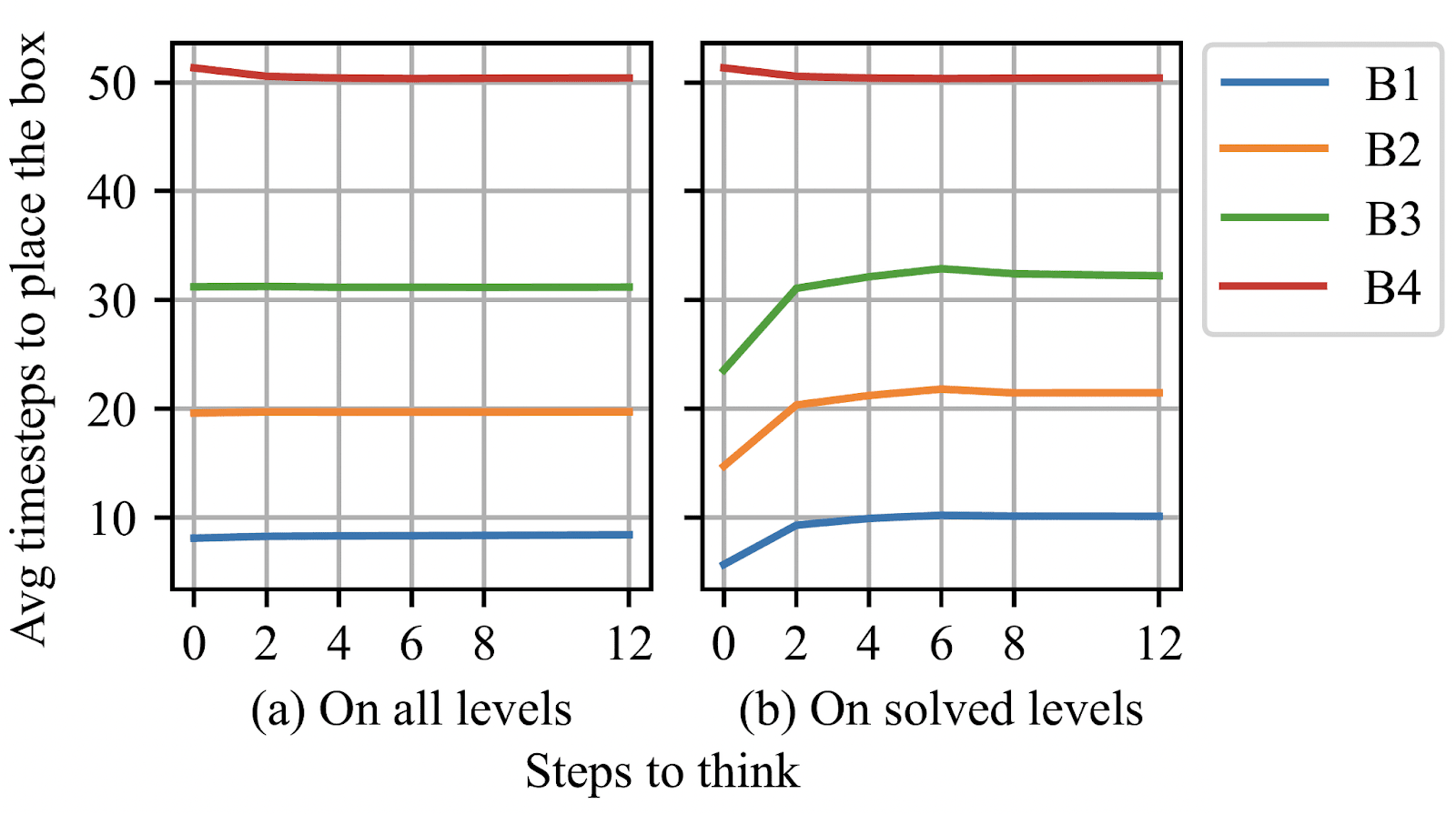
The levels we use always have 4 boxes. Thinking time barely changes the average time the RNN takes to place boxes 1-3. But, when filtering only to levels that it cannot solve at 0 steps but can solve at 6 thinking steps, the time to place boxes 1-3 greatly increases, even though the time to place the 4th box barely changes. This indicates the NN is greedy by default, and thinking time remedies that.
Understanding how neural networks reason, and ultimately locating where they evaluate plans, is crucial to solving inner alignment. This represents an important first step in our longer-term research agenda to automatically detect mesa-optimizers, understand their goals, and modify the goals or planning procedures to align with the intended objective.
For more information, read our blog post or full paper “Planning behavior in a recurrent neural network that plays Sokoban.” And, if you're at ICML, come talk to us at the Mechanistic Interpretability workshop on Saturday!
If you are interested in working on problems in AI safety, we’re hiring. We’re also open to exploring collaborations with researchers at other institutions – just reach out at hello@far.ai.
- ^
We believe LeelaChess is likely also planning. Thanks to Jenner et al., we have a handle on where the values may be represented and a starting place to understand the planning algorithm. However, it is likely to be much more complicated than the RNN we present, and it is not clearly doing iterative planning.
Discuss
