
✂️Cut your QA cycles down to minutes with QA Wolf (Sponsored)

If slow QA processes bottleneck you or your software engineering team and you’re releasing slower because of it — you need to check out QA Wolf.
QA Wolf’s AI-native service supports web and mobile apps, delivering 80% automated test coverage in weeks and helping teams ship 5x faster by reducing QA cycles to minutes.
QA Wolf takes testing off your plate. They can get you:
Unlimited parallel test runs for mobile and web apps
24-hour maintenance and on-demand test creation
Human-verified bug reports sent directly to your team
Zero flakes guaranteed
The benefit? No more manual E2E testing. No more slow QA cycles. No more bugs reaching production.
With QA Wolf, Drata’s team of 80+ engineers achieved 4x more test cases and 86% faster QA cycles.
This week’s system design refresher:
System Design: Why is Kafka Popular? (Youtube video)
How to Design Good APIs
Big Data Pipeline Cheatsheet for AWS, Azure, and Google Cloud
How to Learn AWS?
The AI Agent Tech Stack
How to Build a Basic RAG Application on AWS?
Types of Virtualization
SPONSOR US
System Design: Why is Kafka Popular?
How to Design Good APIs
A well-designed API feels invisible, it just works. Behind that simplicity lies a set of consistent design principles that make APIs predictable, secure, and scalable.
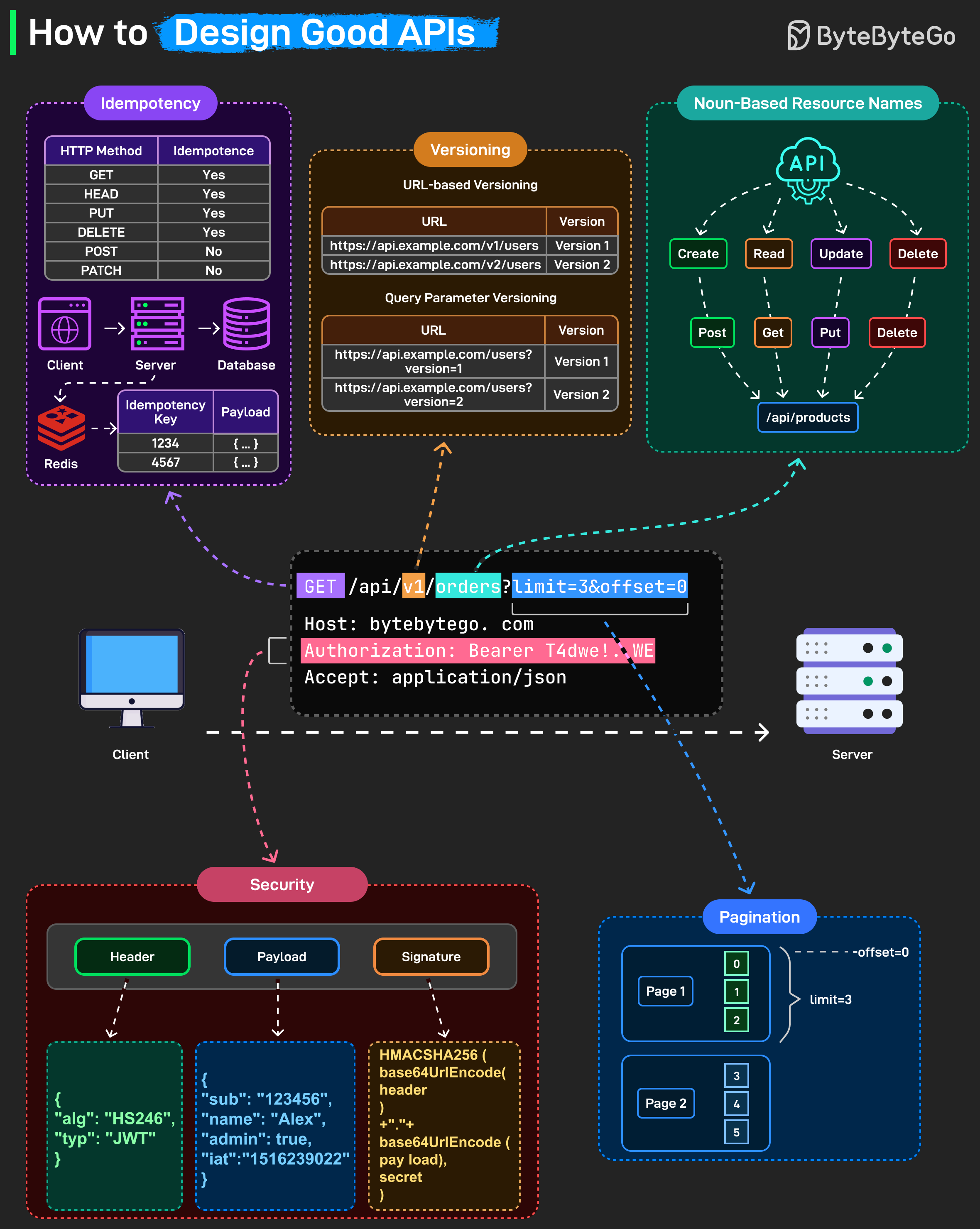
Here’s what separates good APIs from terrible ones:
Idempotency: GET, HEAD, PUT, and DELETE should be idempotent. Send the same request twice, get the same result. No unintended side effects. POST and PATCH are not idempotent. Each call creates a new resource or modifies the state differently.
Use idempotency keys stored in Redis or your database. Client sends the same key with retries, server recognizes it and returns the original response instead of processing again.
Versioning
Noun-based resource names: Resources should be nouns, not verbs. “/api/products”, not “/api/getProducts”.
Security: Secure every endpoint with proper authentication. Bearer tokens (like JWTs) include a header, payload, and signature to validate requests. Always use HTTPS and verify tokens on every call.
Pagination: When returning large datasets, use pagination parameters like “?limit=10&offset=20” to keep responses efficient and consistent.
Over to you: What’s the most common API design mistake you’ve seen, and how would you fix it?
Big Data Pipeline Cheatsheet for AWS, Azure, and Google Cloud
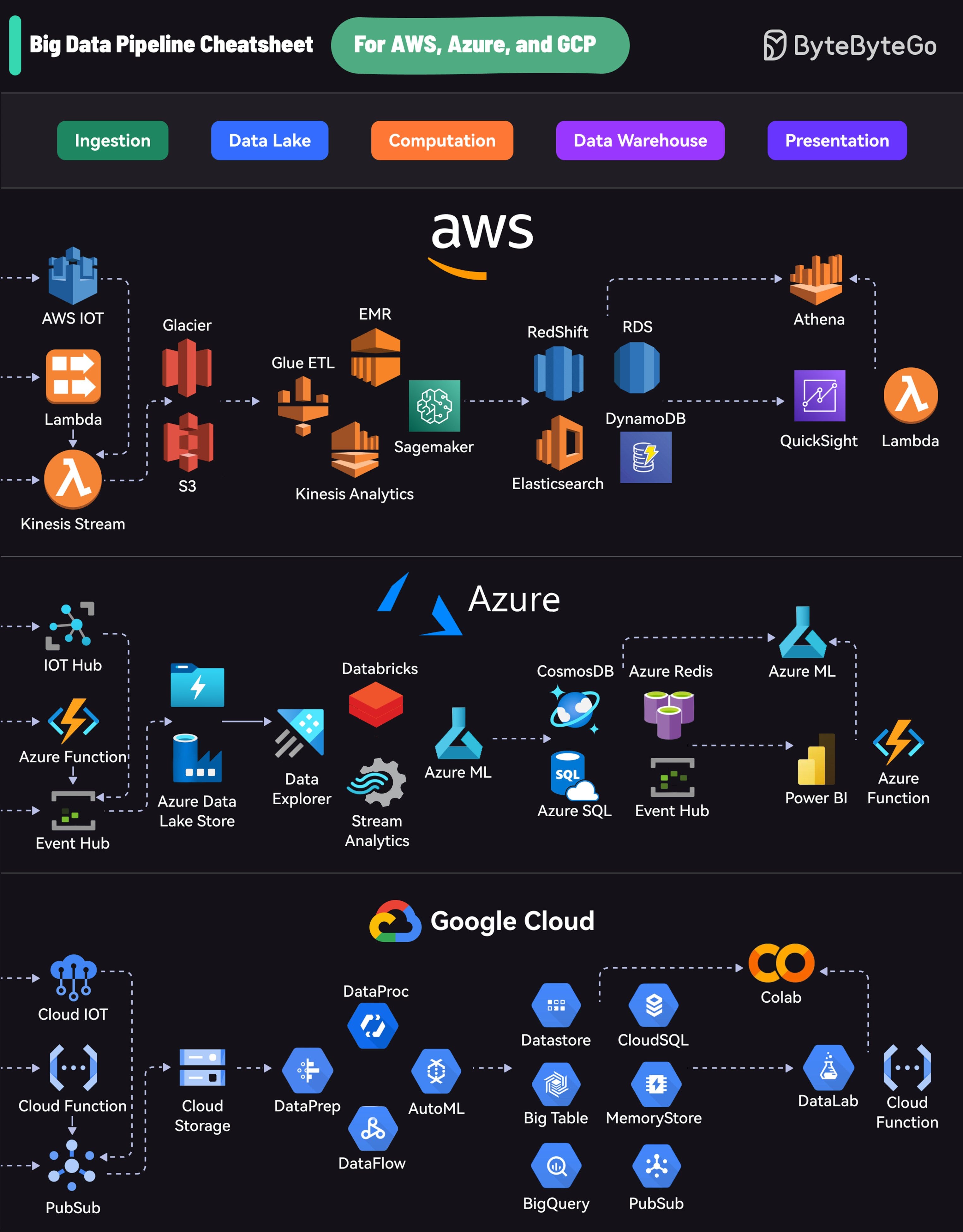
Each platform offers a comprehensive suite of services that cover the entire lifecycle:
Ingestion: Collecting data from various sources
Data Lake: Storing raw data
Computation: Processing and analyzing data
Data Warehouse: Storing structured data
Presentation: Visualizing and reporting insights
AWS uses services like Kinesis for data streaming, S3 for storage, EMR for processing, RedShift for warehousing, and QuickSight for visualization.
Azure’s pipeline includes Event Hubs for ingestion, Data Lake Store for storage, Databricks for processing, Cosmos DB for warehousing, and Power BI for presentation.
GCP offers PubSub for data streaming, Cloud Storage for data lakes, DataProc and DataFlow for processing, BigQuery for warehousing, and Data Studio for visualization.
Over to you: What else would you add to the pipeline?
How to Learn AWS?
AWS is one of the most popular cloud platforms. When AWS goes down, a large part of the Internet goes down.

Here’s a learning map that can help you master AWS:
AWS Fundamentals
This includes topics like “What is AWS?”, Global Infrastructure, AWS Billing, Management, and IAM basics.
Core Compute, Storage & Networking
This includes compute services like EC2, Lambda, ECS, EKS, Storage Services (such as S3, EBS, EFS, Glacier), and Networking Services (such as VPC, ELB, Route 53).
Databases and Data Services
This includes topics like Relational Databases (RDS MySQL and PostgreSQL), NoSQL, and In-Memory Databases like ElastiCache (Redis and Memcached).
Security, Identity & Compliance
Consists of topics like IAM Deep Dive, Encryption (KMS, S3 SSE), Security Tools, VPC Security Groups, and Compliance-related tools for HIPAA, SOC, and GDPR.
DevOps, Monitoring & Automation
This includes topics like DevOps Tools (CodeCommit, CodeBuild, CodePipeline), Infrastructure as Code, CI/CD Pipelines, Monitoring Tools (CloudWatch, CloudTrail), and Cost Management and Billing Dashboard
Learning Paths and Certifications
Consists of topics like AWS Learning Resources, such as Skill Builder and documentation, and certification paths such as Cloud Practitioner, Solutions Architect Associate, Developer Associate, SysOps, and DevOps Engineer.
Over to you: What else will you add to the list for learning AWS?
The AI Agent Tech Stack

Foundation Models: Large-scale pre-trained language models that serve as the “brains” of AI agents, enabling capabilities like reasoning, text generation, coding, and question answering.
Data Storage: This layer handles vector databases and memory storage systems used by AI agents to store and retrieve context, embeddings, or documents.
Agent Development Frameworks: These frameworks help developers build, orchestrate, and manage multi-step AI agents and their workflows.
Observability: This category enables monitoring, debugging, and logging of AI agent behavior and performance in real-time.
Tool Execution: These platforms allow AI agents to interface with real-world tools (for example, APIs, browsers, external systems) to complete complex tasks.
Memory Management: These systems manage long-term and short-term memory for agents, helping them retain useful context and learn from past interactions.
Over to you: What else will you add to the list?
How to Build a Basic RAG Application on AWS?
RAG is an AI pattern that combines a search step with text generation. It retrieves relevant information from a knowledge source (like a vector database) and then uses an LLM to generate accurate, context-aware responses.
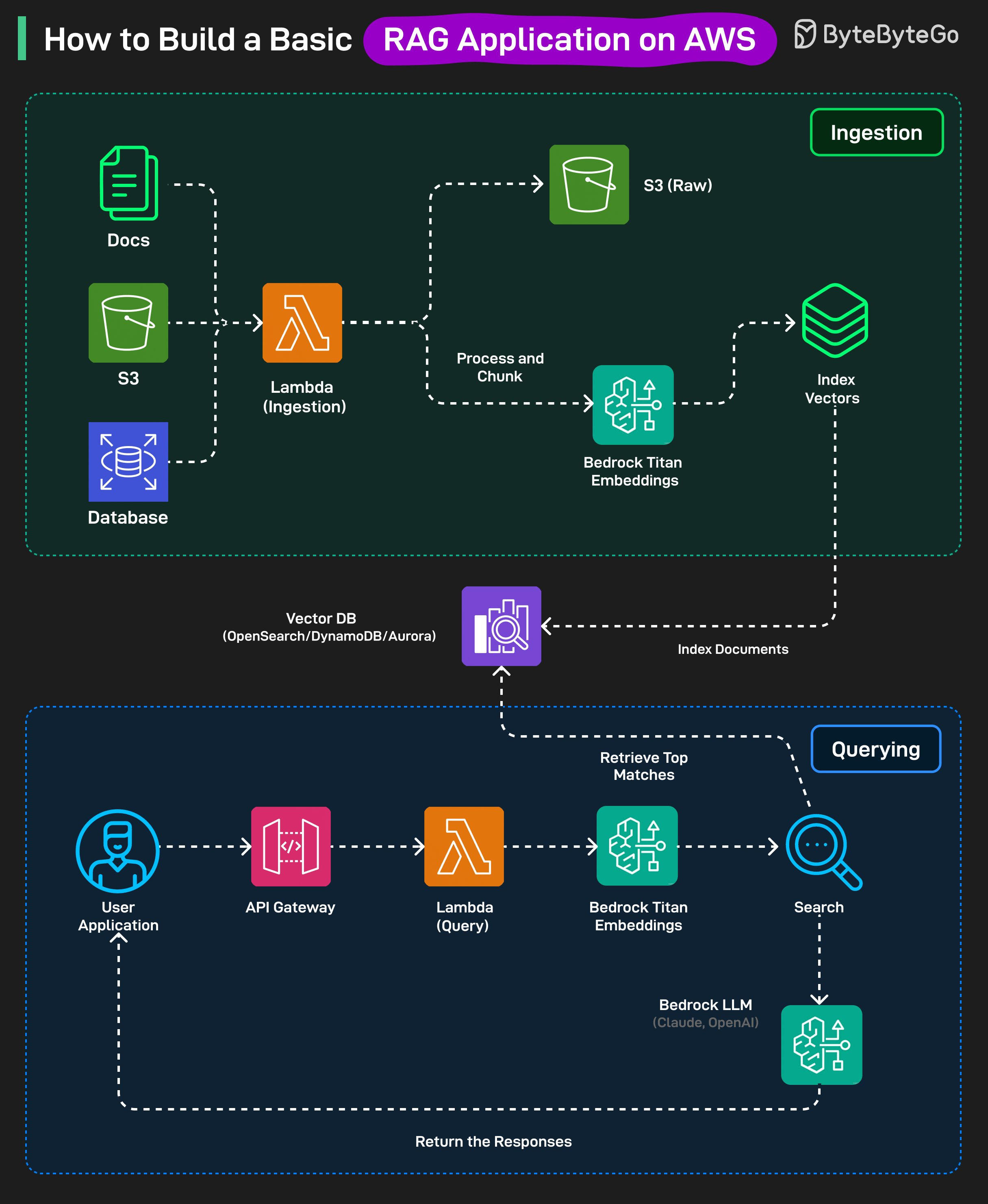
Ingestion Stage
All raw documents (PDFs, text, etc) are first stored in Amazon S3.
When a file is added, AWS Lambda runs an ingestion function. This function cleans and splits the document into smaller chunks.
Each chunk is sent to Amazon Bedrock’s Titan embeddings model, which converts it into vector representations
These embeddings, along with metadata, are stored in a vector database such as OpenSearch serverless, DynamoDB
Querying Stage:
A user sends a question through the app frontend, which goes to API Gateway and then a Lambda query function.
The question is converted to an embedding using Amazon Bedrock Titan Embeddings.
This embedding is compared against the stored document embeddings in the vector database to find the most relevant chunks.
The relevant chunks and the user’s questions are sent to an LLM (like Claude or OpenAI on Bedrock) to generate an answer.
The generated response is sent back to the user through the same API.
Over to you: Which other AWS service will you use to build an RAG app on AWS?
Types of Virtualization
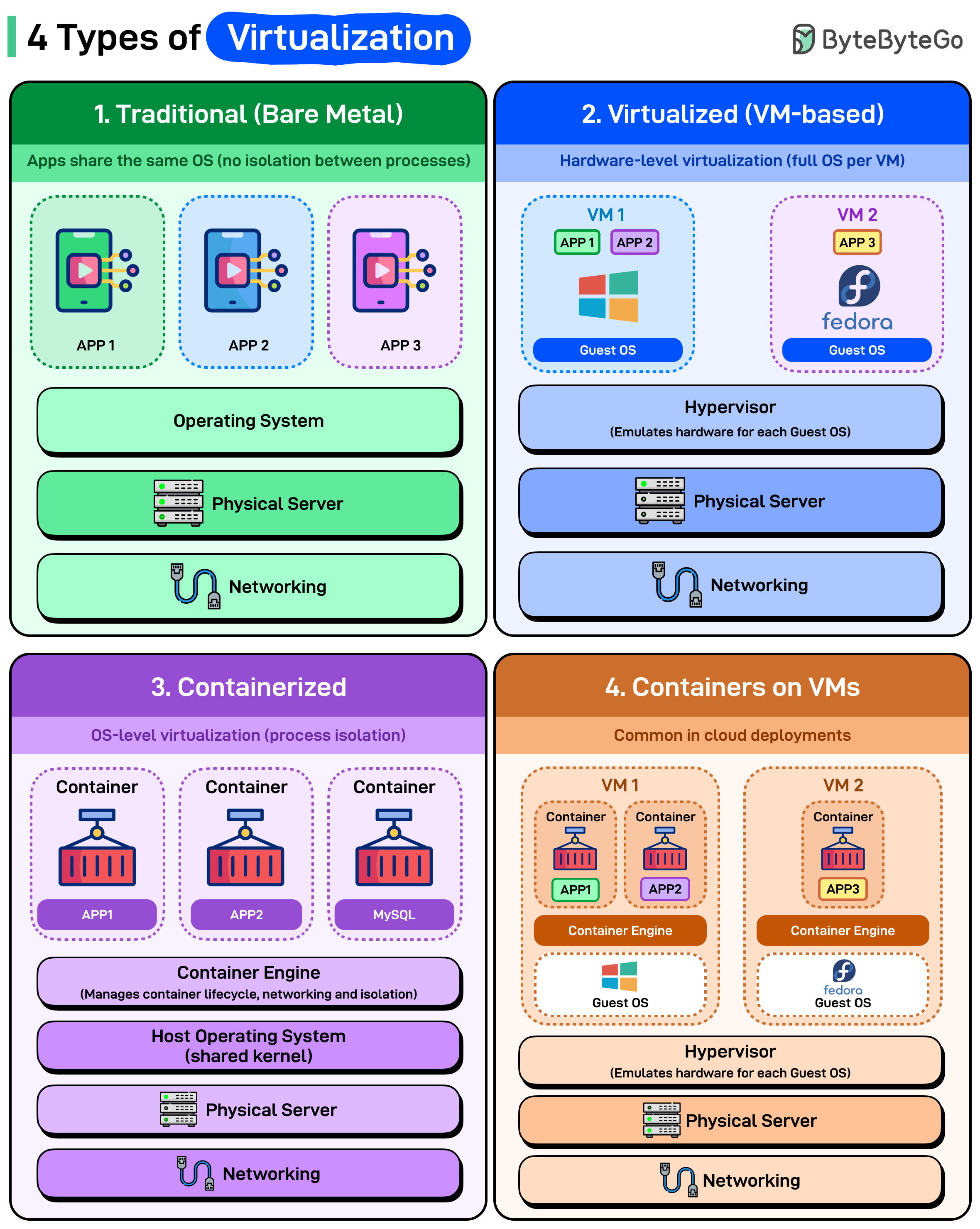
Virtualization didn’t just make servers efficient, it changed how we build, scale, and deploy everything. Here’s a quick breakdown of the four major types of virtualization you’ll find in modern systems:
Traditional (Bare Metal): Applications run directly on the operating system. No virtualization layer, no isolation between processes. All applications share the same OS kernel, libraries, and resources.
Virtualized (VM-based): Each VM runs its own complete operating system. The hypervisor sits on physical hardware and emulates entire machines for each guest OS. Each VM thinks it has dedicated hardware even though it’s sharing the same physical server.
Containerized: Containers share the host operating system’s kernel but get isolated runtime environments. Each container has its own filesystem, but they’re all using the same underlying OS. The container engine (Docker, containerd, Podman) manages lifecycle, networking, and isolation without needing separate operating systems for each application.
Lightweight and fast. Containers start in milliseconds because you’re not booting an OS. Resource usage is dramatically lower than VMs.
Containers on VMs: This is what actually runs in production cloud environments. Containers inside VMs, getting benefits from both. Each VM runs its own guest OS with a container engine inside. The hypervisor provides hardware-level isolation between VMs. The container engine provides lightweight application isolation within VMs.
This is the architecture behind Kubernetes clusters on AWS, Azure, and GCP. Your pods are containers, but they’re running inside VMs you never directly see or manage.
Over to you: In your experience, which setup strikes the best balance between performance and flexibility?
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
