
「高雄市發展主權AI計畫的核心是,從影像辨識城市正在發生的事件,讓市府第一時間掌握這些事件快速應變」,高雄市政府資訊處長劉俊傑今年8月在一場活動上說。
他解釋,主權AI就是接地氣,包括資料主權及適地性兩個概念;以適地性為例,儘管兩岸都說中文,但是在用語上存在明顯差異,例如在臺灣說的「硬碟」,中國稱之為「硬盤」,臺灣的「影片」,對岸稱為「視頻」。
除了生活用語的差異,臺灣也有獨有的生活習慣,例如廟會繞境,「這是只有臺灣有,其他國家沒有的活動」,但是當廟會繞境活動進行時,伴隨而來交通堵塞、噪音擾民、垃圾髒亂等問題,對民眾的生活產生困擾,透過1999向市府抱怨,成為市政治理經常面對的問題。高雄主權AI的核心之一便是訓練VLM視覺語言模型,廟會繞境活動即被納入識別的情境之一。
主權AI架構打造跨局處資源共享的AI平臺
現今傳統城市治理架構的限制,市政府不同局處依據分工進行市政治理,例如交通局主管交通運輸,工務局主管城市的公共工程建設,水利局主管城市內的水資源業務,環保局主管環境保護等等,局處各自掌握資源,彼此之間並沒有共享。
劉俊傑指出,以往智慧城市導入各種AI應用,這些AI應用都是Silo AI或Vertical AI,只有單一功能,像是專門識別交通流量的AI,或是專門辨識車牌的AI,以及偵測闖紅燈或違規停車的科技執法AI。
高雄市主權AI的架構設計為共用平臺,比照雲端採用三層式架構,底部為IaaS基礎架構層,中間為主權AI的PaaS層,上面則是各局處、廠商發展的SaaS層。
在IaaS層方面,鑑於GPU價格高昂,市府和Linker Vision、Nvidia合作,採用類似聯合開發的合作方式,由合作廠商提供運算資源作為IaaS層,採用Nvidia Blackwell B200 GPU。
至於PaaS層,資訊處整合跨局處、跨領域的影像資料,使用Nvidia的商用VLM模型,結合影像資料來進行模型微調,並將其打造為共用的PaaS平臺,讓各局處都能使用,各自基於業務需要發展SaaS層應用。
資訊處整合影像資料及PaaS VLM平臺,架構在高雄當地的機房,至於GPU算力資源組成的IaaS層位於臺南的中華電信機房,基於AI需要大量數據,為加快兩地機房之間的傳輸,中華電信以全光纖網路連接。
4步驟發展城市級主權AI
高雄市政府從4個步驟發展主權AI,資料整理、資料標註、模型訓練、城市級VLM推論平臺。
在資料整理方面,資訊處首先和4個局處開會溝通,先確認各局處希望AI辨別的情境,例如交通壅塞、淹水、車禍等,當這些情境發生時,各局處能第一時間獲得AI自動通報,即時應變處理。
劉俊傑表示,資訊處花費約半年時間和交通、環保、工務局等各單位、廠商討論磨合,先確認要解決哪些問題,再蒐集和問題相關的影像資料來訓練VLM模型,最後確認明年第一季需完成訓練,讓VLM可辨識出108種情境,共609組判斷指標,這些情境涵蓋日常交通、淹水偵測、災害應變、交通異常事件、活動疏運、道路設施、廠區管理、港區物流紓解。
打造VLM以辨識108個情境
VLM可從城市的影像資料辨別108種情境,並且能判斷609組指標,相當於打造非常懂高雄在地城市治理情境的AI大腦。
資訊處和局處確立AI需要學會辨識情境及判斷指標後,從局處蒐集大量影像資料,累計超過2,000TB、645萬小時的影像資料,這些資料來自城市的監視器、無人機等等,為模型訓練及微調所使用。
除了來自真實攝影機的影像畫面資料,針對罕見或尚未發生過的事件,在廠商協助下,他們利用數位孿生產生約10萬張罕見案例(Cornor Case)影像。
由於這些影像資料相當龐大,若僅靠人工挑選將花費相當多的時間,因此他們利用GPU和影像理解技術,以自動化代替人工挑選出合適的影像及罕見情境影像,降低人工處理時間。
接下來進入資料標註,他們先建立一致的標註標準,由一個百人團隊結合各領域專家知識來產生400萬組標註資料;為確保VLM的品質,高雄市資訊處也導入第三方審查機制,高雄市政府強調為第一個以國際ISO 2859-1抽樣檢驗標準的VLM模型,可容錯率為0.65%。
在模型訓練上,高雄市採用Nvidia的商用模型Metropolis,結合在地的高雄街頭影像標註資料進行微調,VLM模型的微調是讓AI學習識別影像中的物體,再學習將圖片和文字描述對應起來,以讓VLM能理解人類的指令,並且能回答問題。
劉俊傑指出,VLM模型辨別圖片的結果,一方面產生自然語言的描述,方便使用單位互動溝通,但是自然語言卻不易於為機器所用,因此辨識結果,還會產出指標型結果,例如Yes/No或是分級,方便透過API和既有系統介接,方便設計系統如何應對。
經過微調之後,理論上,VLM可對每張影像辨識108種情境、609個判斷指標,依照不同局處單位業務上所關心的情境,進一步向VLM提問狀況。
而指標型的結果,以道路淹水為例,當VLM辨識到發生淹水的情形,同時向水利局、交通局報告,報告中也會提供VLM輸出的指標,像是淹水深度等級、淹水是否影響路段交通、淹水路段的封閉狀態、是否有車輛通行等等。
至於如何讓VLM根據影像畫面理解每個情境的狀況,提供判斷指標給使用單位,輔助他們決策?
以道路淹水為例,相關單位例可能想進一步了解現場淹水的深度,因此團隊先了解需要,再將淹水深度分為淺度(低於30公分)、中度(30至50公分)、深度(高於50公分)三個等級,再以人工標註影像特徵及描述,來訓練VLM從影像畫面判斷淹水深度等級。
他們再以淹水至汽車輪胎的高度作為判斷的標準,淹水至半個輪胎為中度(30到50公分),如果超出50公分則為深度等級,自動向水利局、交通局、警察局通報,讓各單位依淹水區域、水深等級等判斷指標,決定是否優先派人到場排除淹水事故、控制交通號控、派員警到場疏導交通。
「例如電線桿歪斜或倒塌,以往的機器學習技術,鑑別式AI只會回答是否倒塌,而生成式AI只要經過訓練,可以回答電線是否損毀?現場交通是否受影響?電桿是否和路樹纏在一起等問題」,劉俊傑說。
VLM解讀的城市中影像畫面,除了城市的公共監控影像,還有垃圾車、公車、無人機,未來甚至可和計程車隊合作,讓行駛在大街小巷的計程車,在城市中移動,蒐集各地的影像畫面。
至於VLM判讀到特殊事件發生,例如車禍、交通壅塞、淹水,VLM會自動從影像畫面截取一張圖,在通報中附上截圖提供相關單位,讓其進一步檢視人工確認,從截圖判斷事件的嚴重性。

高雄市政府資訊處長劉俊傑表示,AI並非要取代各局處現有的工作,而是成為助手,協助將事情做得更快更好,協助市府各單位作好資源分配的決策,並提高處理的時效。(攝影/洪政偉)
透過VLM第一時間通報應變
「AI並不是要取代我們的工作,而是成為我們的助手,將正在做的事做得更快更好」,劉俊傑說。
以道路縫隙、坑洞為例,過去市府收到1999的反應,工務局派人巡邏勘察,根據估計工務局一年要處理約有上萬件,人力相當有限;未來透過VLM自動辨別道路縫隙、坑洞,對影響交通的大坑洞優先列為處理案件,「讓資源分配做得更好,同時提高處理的時效」。
目前資訊處預計於2026年第一季完成VLM對108種情境的訓練及測試,使VLM在判別情境事件的準確度達到一定的程度。模型訓練完成後將會逐步部署於高雄市各局處影像監測系統,讓更多攝影機影像可靠即時推論與事件預警,讓城市治理從影像蒐集邁向智慧決策。
高雄市政府資訊處和協力廠商負責訓練VLM模型,並建置VLM PaaS平臺,接下來,明年為局處基於VLM PaaS平臺發展SaaS的智慧應用。
劉俊傑認為,未來透過VLM平臺向相關單位通報事件,可改變過去市府收到1999陳情,才知道發生哪些問題的被動,由AI主動向市府通報發生哪些異常事件,例如某個區域發生塞車,市府將塞車資訊透過CMS通知市民,避免其他車輛繼續進入塞車區域,同時也向不同的局處通報,加快局處的應變處理速度。
不過,他也強調VLM通報只是輔助決策,目前市政府各局處既有建置的物聯網、鑑別式AI、各種專家系統,在某些情境之下,其辨識準確性要高於VLM,例如在科技執法的應用上,鑑別式AI判斷的準確性更高。
從VLM通報預警到即時應變治理
高雄市政府推動主權AI,以在地的影像資料利用VLM模型微調後,未來VLM將站在輔助角色通報各局處,並不會取代各局處現有的專家系統,各個局處仍可綜合VLM的通報、IoT物聯網的感測資料、專家系統等各方面的資訊,來了解城市中發生哪些事件,評估事件的影響性,提高市府各局處的應變能力,同時也能用以提升城市的韌性。
當VLM發現哪個路段在什麼時間發生交通壅塞,VLM可解讀影像畫面,再推論塞車發生的可能原因,可能因為道路施工、發生車禍或是淹水,VLM自動向相關單位發送通報。
劉俊傑表示,高雄市政府資訊處負責蒐集各局處影像資料,並建置及管理VLM PaaS平臺,接下來SaaS層則預期在明年由各局處發展,可能從Auto report到Auto control、精簡流程,進一步提升市政問題的處理效率。
例如當VLM自動通報路面出現坑洞,工務局連接派工系統,自動派工程團隊前往修補,或是連接交通局的CMS(Changeable Message Sign)系統,發布即時路況資訊,提醒其他車輛繞道通行或小心駕駛。
高雄市政府推動主權AI,透過發展VLM在地化模型為城市的智慧治理基礎,對市府內部建立跨局處協作的平臺,整合不同局處的影像資料,建立VLM PaaS平臺,打破現今各局處各自掌握影像資料,各自發展AI應用的Silo AI架構。
劉俊傑表示,未來VLM PaaS平臺建置完成之後,未來局處如果有新的情境辨識需求,或是其他局處加入,就能以跨局處共享的影像資料訓練VLM,讓VLM得以識別新的城市情境議題,不再需要像過去Silo AI架構,局處要先採購建置專門的攝影機,建置後蒐集影像畫面,再開發單一功能的AI應用。
另外,未來如果有更多局處的攝影機影像畫面加入燈塔計畫,利用VLM PaaS平臺,第一時間辨別發生的情境事件,可以將VLM自動通報告警能力,延伸擴散到城市更多角落,將AI治理擴大到整個高雄市。
.jpg)
高雄市政府以人工標註影像畫面的視覺特徵及描述,訓練VLM能判讀高雄市的影像,以淹水為例,先識別L1的道路淹水情境事件後,再根據畫面提供判斷指標,例如淹水深度等級、是否影響交通、道路是否封閉等等。(圖片來源/高雄市政府)
高雄主權AI不涉及辨識個資
高雄市以在地影像資料發展主權AI,以VLM視覺語言模型結合攝影機的影像資料,輔助城市第一時間掌握發生的情境事件,快速應變處理,試圖在智慧城市的治理上建立新的治理方式。
不過,劉俊傑也直言,高雄市將VLM應用於城市治理,缺乏可供參考的驗證標竿,國外對於可信任AI(Trustworthy AI)的評估指標,例如資安、偏見、可解釋性、透明度等等,市府團隊參考這些指標之外,也參考美國、歐盟的AI相關法案(國內的AI基本法尚未獲立法院通過),以歐盟AI Act畫分4種AI風險等級,不可接受的風險、高風險、有限度的風險、最低風險。「我們現在位於最低風險」。
劉俊傑進一步解釋為什麼高雄主權AI是最低風險,一般而言,個資指的是足以辨識個人的資料,但是高雄主權AI所用的影像資料沒有訓練AI學習辨識個資,「我們用於訓練及辨識的資料不會去做這件事,因此原則上它是最低風險的」,由於為最低風險,因此較沒有蒐集個資的疑慮,偏重資安、可解釋性的問題。
他也以交通情境為例,並沒有辨識車輛上的民眾,因此沒有涉及個資及偏見的問題,其次是各局處收到的是VLM辨識情境的結果,讓各局處能早市民一步發現市政問題兼主動解決,各局處只會收到AI辨識情境結果、文字敘述和一張截圖,不會取得原始影像畫面資料。
結合數位孿生以3D視覺平臺管理城事
對於高雄市政府而言,建置可辨別在地城市情境的VLM PaaS平臺只是燈塔計畫的一部分,高雄市也與Nvidia合作,利用Omniverse打造數位孿生的城市場域,目前先以80平方公里打造一個區域性數位孿生城市環境,利用這個虛擬世界結合物理量、人為規則,和真實的城市場域相映射。
這個數位孿生平臺可接收VLM自動通報的情境事件,各局處單位從這個3D視覺的數位孿生平臺檢視各地發生的情境事件,評估採用不同應變方案的效益,高雄市希望將市政治理從被動受理,轉為AI預警、即時應變。不只是市政府,參與燈塔計畫的港務公司、重工業者,也能利用這個3D視覺平臺,檢視哪裡發生火災,加強公安的應變管理。
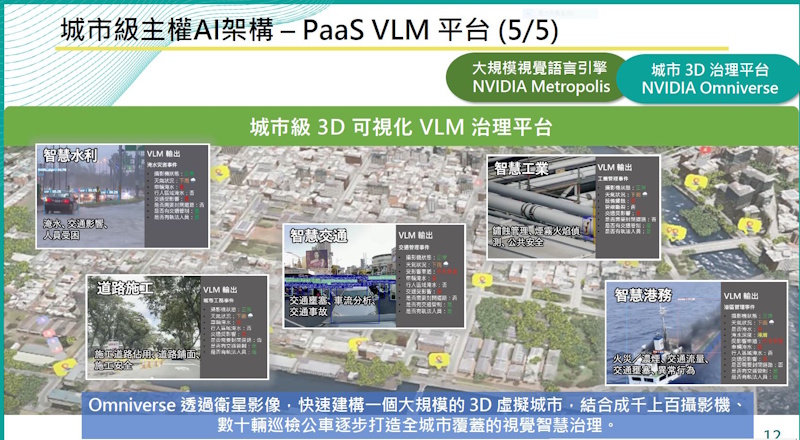
建置VLM打造城市事件AI預警通報只是一部分,高雄市政府還利用Nvidia的Omniverse,以衛星影像快速建構數位孿生城市,這個數位孿生城市先以80平方公里的區域來模擬,可呈現VLM通報的告警訊息,例如交通壅塞、道路淹水,甚至是港務、廠區發生的火災。(圖片來源/高雄市政府)


