
Kimi K2 Thinking训练真的只花了460万美元?杨植麟亲自带队,月之暗面创始团队出面回应了。
这不是官方数据。训练成本很难计算,因为其中很大一部分用于研究和实验。
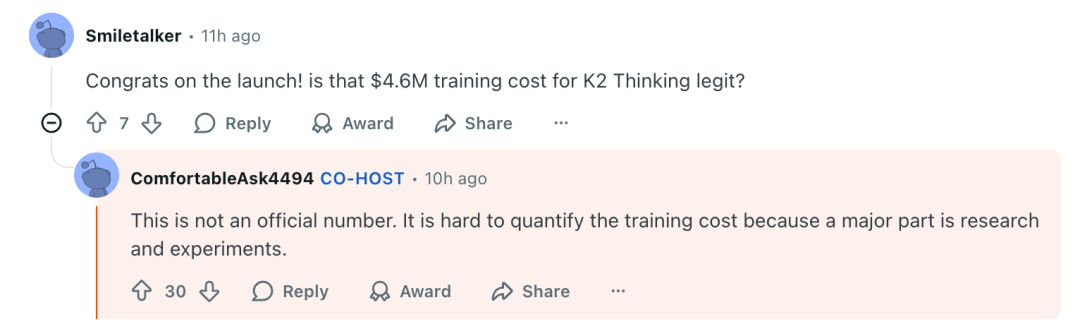
他们还透露训练使用了配备Infiniband的英伟达H800,GPU数量也比巨头的少,但充分利用了每一张卡。
但不管怎样,Kimi K2模型凭借自身实力和低成本,正在硅谷引发一场“用脚投票”的迁移大潮。
投资人Chamath Palihapitiya透露他的新公司将AI负载迁移到Kimi K2,因为它性能更强,价格也便宜得多。

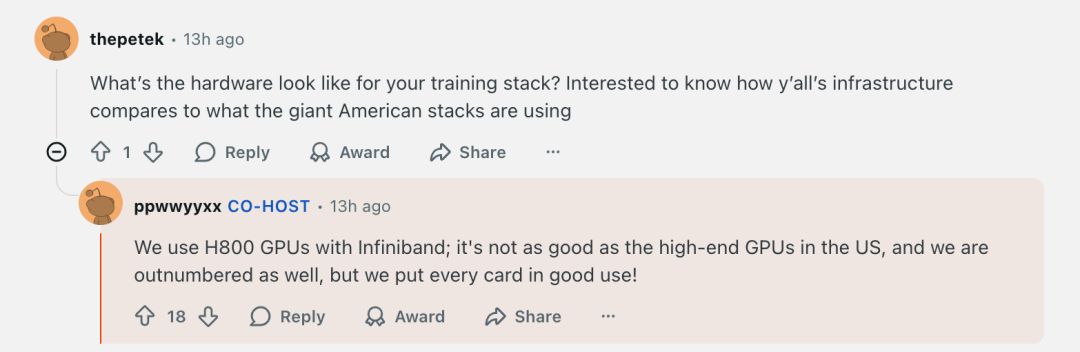
云端开发平台Vercel CEO也分享了内部测试结果,称Kimi K2比闭源模型快5倍,准确率还高50%。
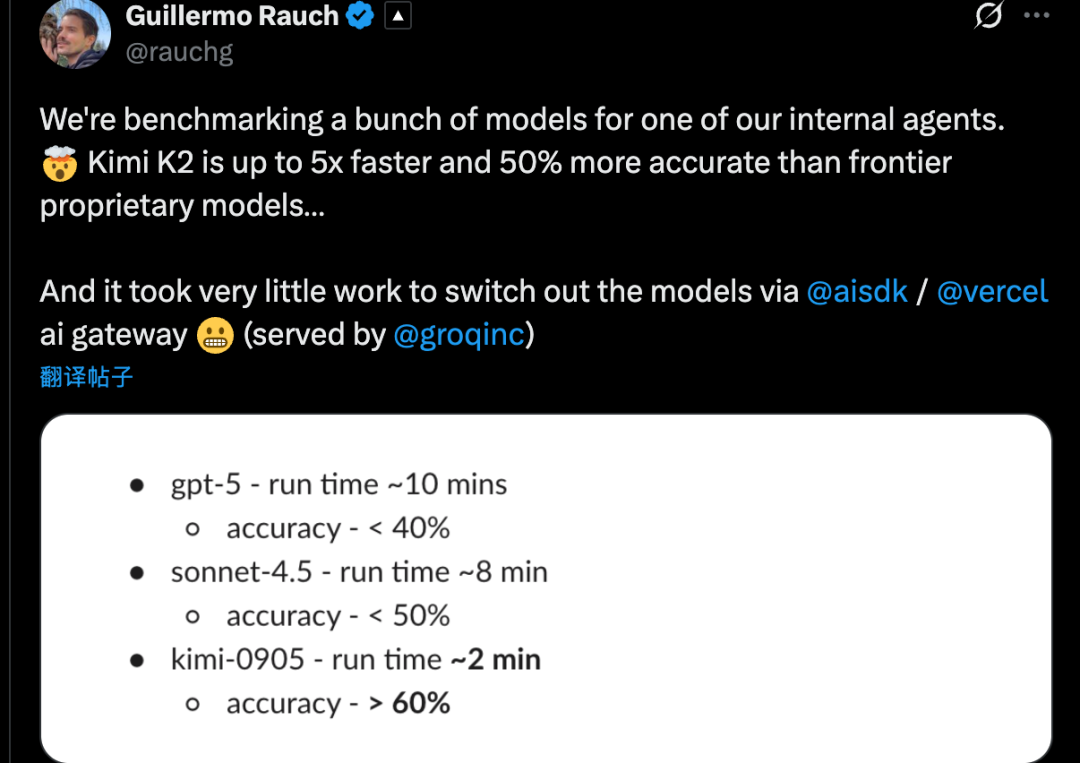
Claude Code用户也在相互传授把模型改成Kimi K2的设置方法。
特别是Kimi K2 Thinking 被爆料只花了460万美元训练,比年初引发轰动的DeepSeek V3(爆料约560万美元)还要低。
先不论这个数字是否准确,总之是让硅谷陷入一阵反思。
当免费或极低成本的开源模型能提供同等甚至更优的性能时,闭源巨头的高估值,还合理吗?
也有另一面的舆论是:或者该重估月之暗面了。
Kimi是如何做到的?
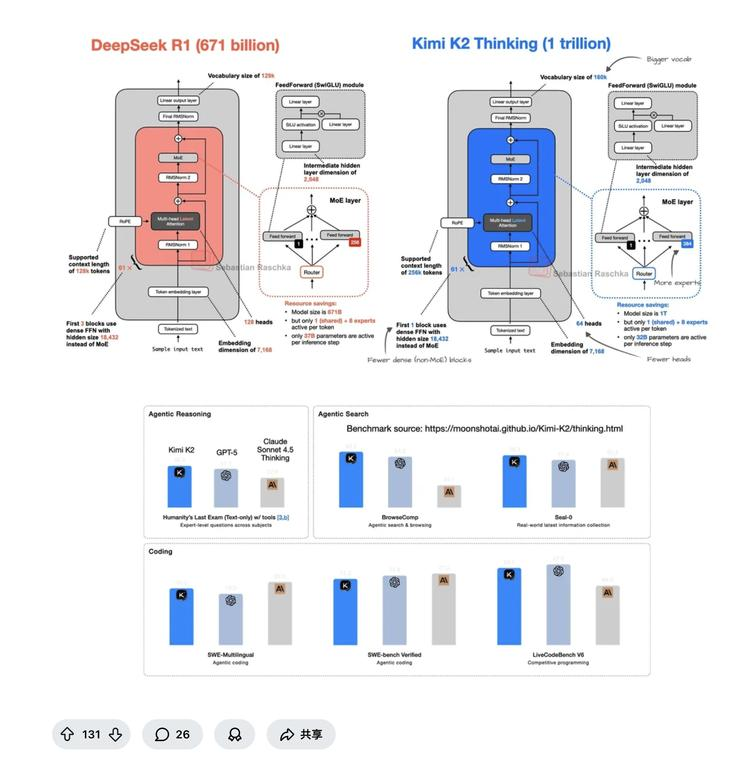
技术社区的分析指出,Kimi K2 Thinking巧妙地继承并优化了现有开源成果,特别是在架构上与DeepSeek模型一脉相承。
团队将MoE层的专家数量从DeepSeek的256个增加到384个以增强模型的知识容量,同时将每次推理激活的参数量从约370亿减少到320亿来降低推理成本。词汇表从129k扩大到160k,并减少了MoE之前的密集前馈网络块,进一步优化计算效率。
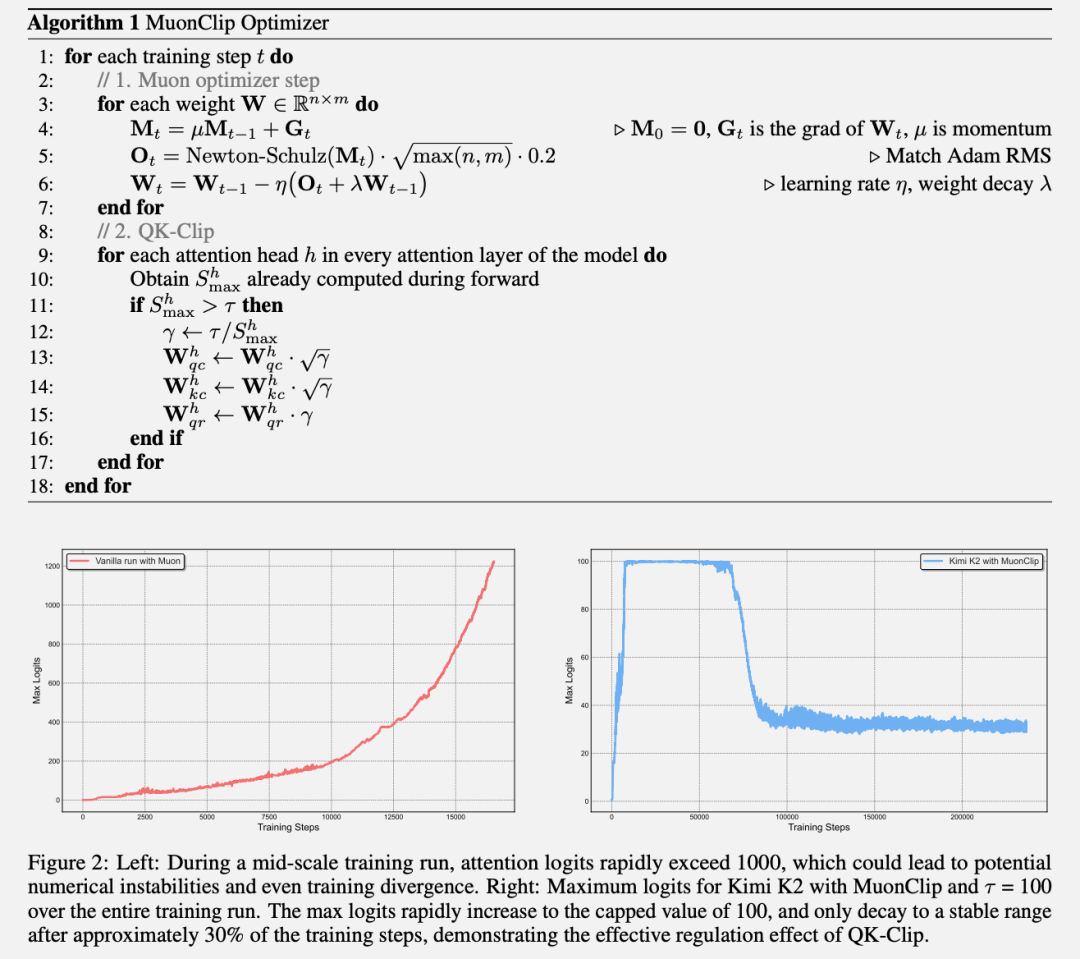
更关键的是工程创新。Kimi K2使用了团队自研的MuonClip优化器,能在训练过程中自动稳定梯度。
得益于此优化器,Kimi K2在长达15.5万亿token的训练过程中实现了”零训练崩溃”,无需人为干预重启,在资金和设备相对有限的情况下也能可靠地训练超大规模模型。
模型还采用了量化感知训练(QAT)方案,实现了原生INT4精度推理。这种方法在训练阶段就让模型适应低精度环境,在大幅降低计算资源消耗、提升推理速度约2倍的同时,将性能损失降至最低。
直面硅谷开发者,月之暗面团队首次公开”答疑”
在此背景下,月之暗面团队在Reddit最活跃的AI社区LocalLLaMA进行了一场长达3小时的“回答一切”(Ask Me Anything)活动,吸引了近200条提问和数千条互动。
答疑的三位主力是杨植麟、周昕宇和吴育昕——月之暗面的三位联合创始人,其中那个“4494”就是杨植麟。
核心信息总结如下:
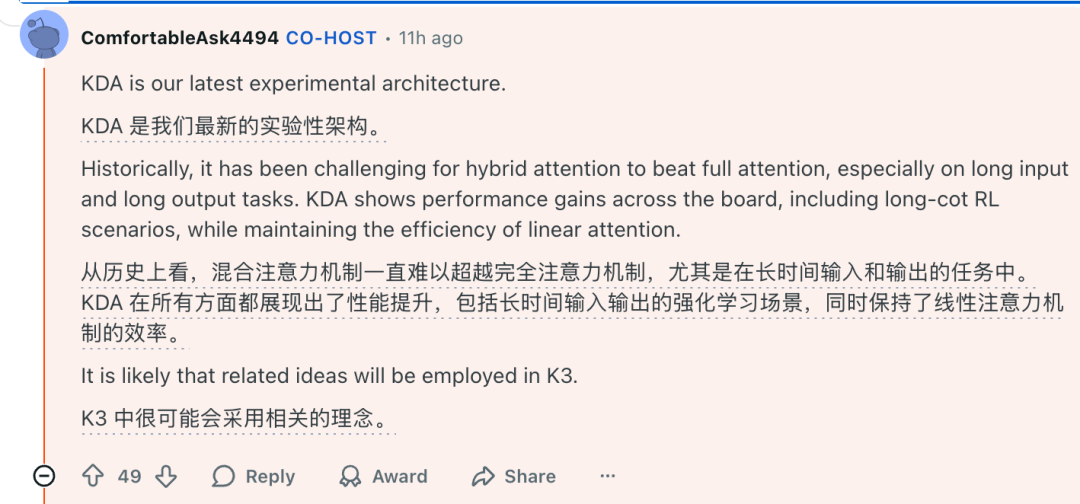
当被问及下一代架构时,团队解释了最新实验性混合注意力机制KDA(Key-Dependent Attention)的优势,还透露有可能用在下一代K3中。
在同等预训练和强化学习的条件下,采用NoPE MLA的KDA混合模型性能优于采用RoPE的完整MLA模型,不仅能获得更高的基准测试分数,而且速度更快、效率更高。
历史上,混合注意力很难击败完全注意力,特别是在长输入和长输出任务上。KDA在各方面都显示出性能提升,包括长链思维的RL场景,同时保持了线性注意力的效率。相关想法很可能会在K3中采用。
有关未来开发计划,团队还透露:
Q:为什么Kimi不像其他模型那样过度夸赞用户?
团队解释这是整理数据时的刻意设计。
Q:Kimi独特的写作风格从何而来?
解释说这是预训练和后训练共同作用的结果:预训练编码了相关的先验知识,而后训练则添加了一些品味。看到不同的RL配方如何产生不同的口味是很有趣的。
此外团队还无保留的回答了一些结束细节问题:

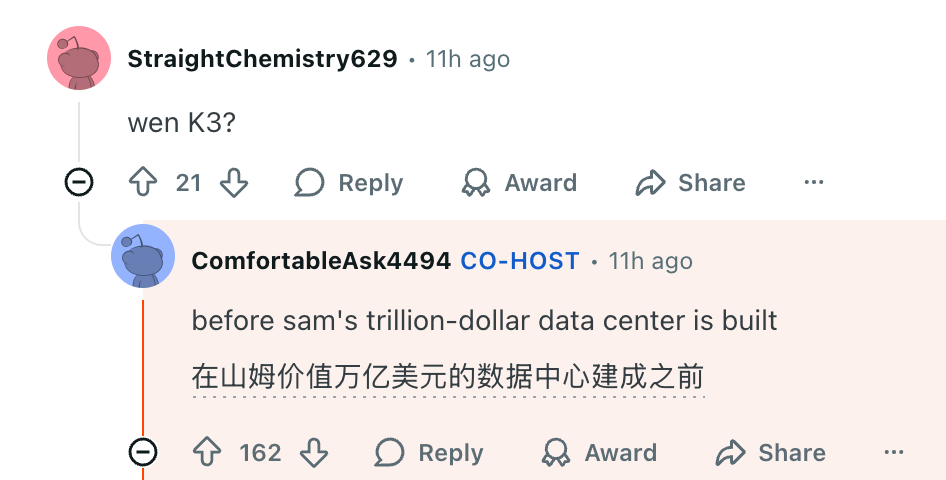
最后,关于下一代K3何时到来,团队还开了个小玩笑:
参考链接:
[1]https://www.reddit.com/r/LocalLLaMA/comments/1oth5pw/ama_with_moonshot_ai_the_opensource_frontier_lab/
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🏆 年度科技风向标「2025人工智能年度榜单」申报即将于11月17日截止!点击了解详情
❤️🔥 企业、产品、人物3大维度,共设立了5类奖项,最后时刻一起冲刺👇

一键关注 👇 点亮星标
内容中包含的图片若涉及版权问题,请及时与我们联系删除
