
全开源多模态大模型(MLLM)的性能,长期被闭源和半开源模型“卡脖子”。
原来核心瓶颈不在模型结构,而在于“数据质量鸿沟”。
为了解决这一痛点,清华大学与腾讯混元团队联手推出了Bee项目。Bee不只是一个模型,它是一套全栈式、完全开放的解决方案 ,旨在从根本上拉近开源社区与顶尖模型之间的差距。

Bee项目的三大核心贡献:
下面详细来看。
背景与动机:打破“三层结构”的数据壁垒
当前的MLLM领域呈现出明显的三层结构:(1) 顶尖的闭源模型(如Gemini 2.5、GPT-5),(2) 权重开放但数据私有的半开源模型(如Qwen2.5-VL、InternVL),以及 (3) 性能远远落后的全开源模型。
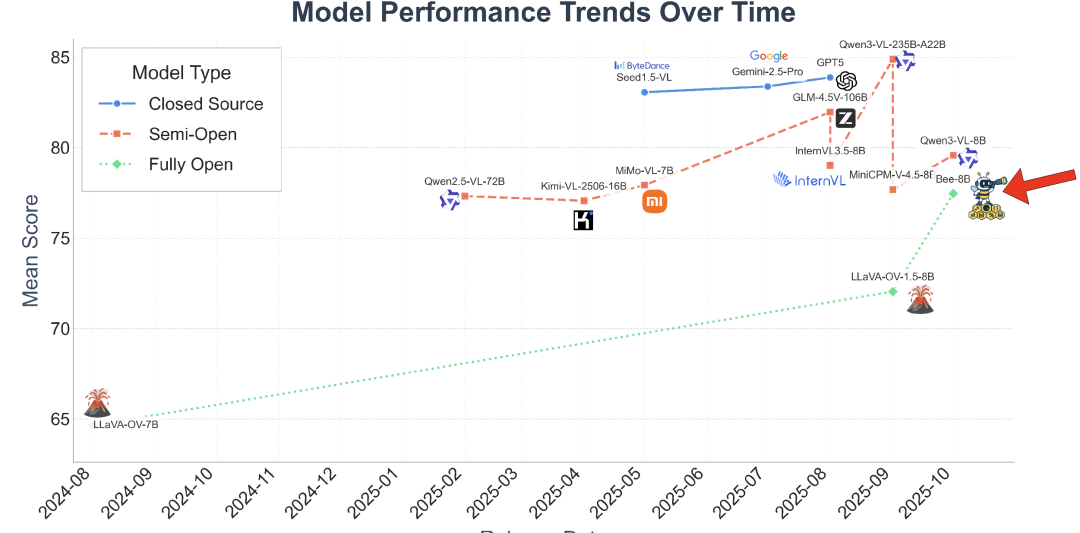
如上图所示(分数为MMMU、Mathvista等五个数据集平均的结果),在Bee项目之前,全开源(Fully Open)模型在性能上与闭源(Closed Source)和半开源(Semi-Open)模型存在巨大鸿沟。
Bee团队认为,这种差距的根源在于SFT阶段的数据质量。
现有开源数据集普遍存在两大顽疾:
因此,Bee项目明确指出,全开源社区最可行的路径不是盲目追求数据“数量”,而是聚焦于“数据质量”。
HoneyPipe:授人以渔的全栈数据增强管线
为了系统性地解决上述数据问题,团队构建了HoneyPipe,一个基于DataStudio框架的、自动化的数据增强流程。

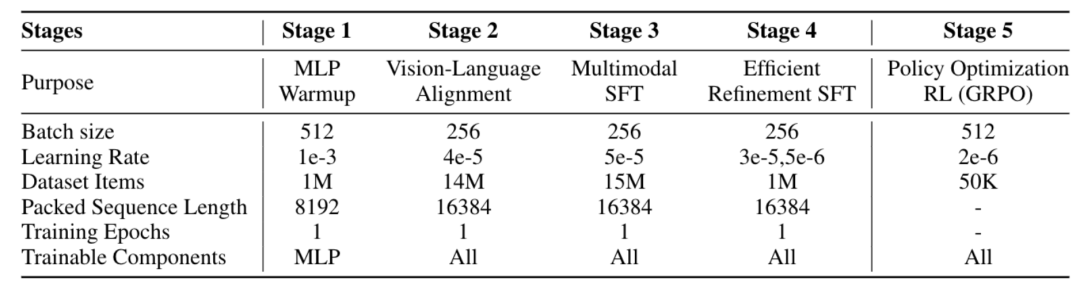
HoneyPipe的核心价值在于其透明可复现的三阶段增强过程:
这一套“过滤-循环增强-验证”的精细流程,最终产出了高质量的数据集。
Honey-Data-15M:双层CoT赋能的高质量基石
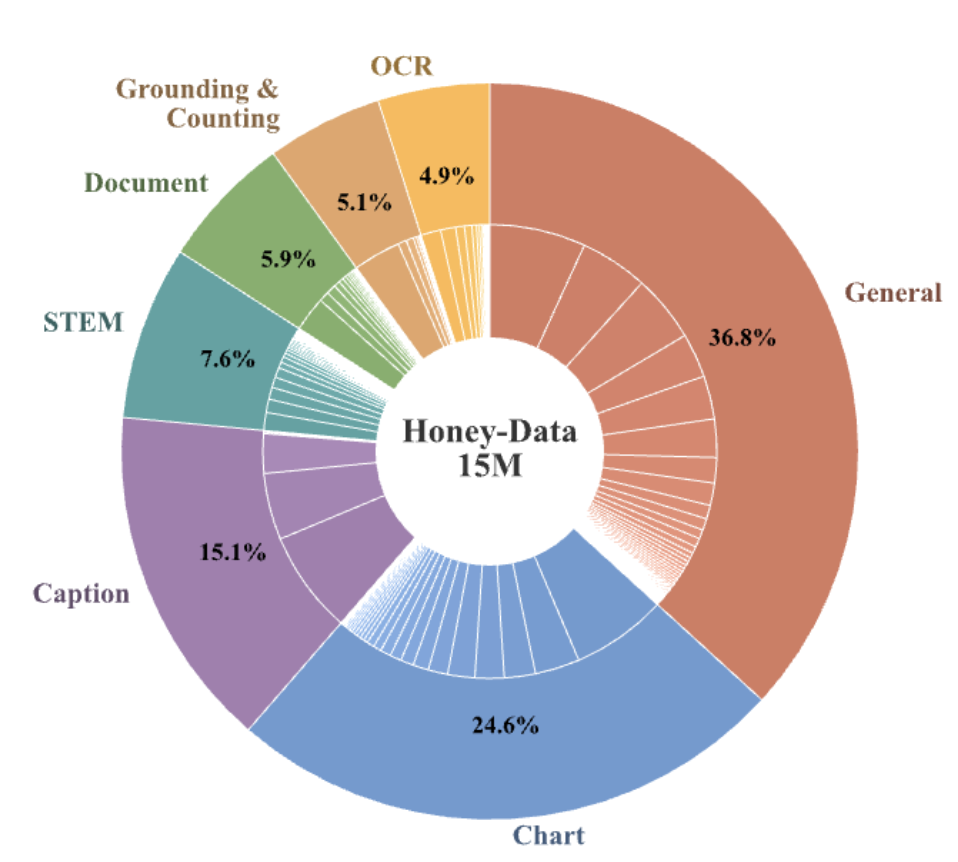
HoneyPipe流程的最终产物是Honey-Data-15M,一个包含1500万精心策划样本的大型多模态SFT数据集。

该数据集的核心特征是其双层CoT推理结构:
如上图所示,数据集的来源多样化,策略性地覆盖了7大领域,确保了模型的全面发展:
Bee-8B:全开源MLLM的新标杆
为了验证Honey-Data-15M的卓越效果,团队开发了Bee-8B模型。
模型架构:
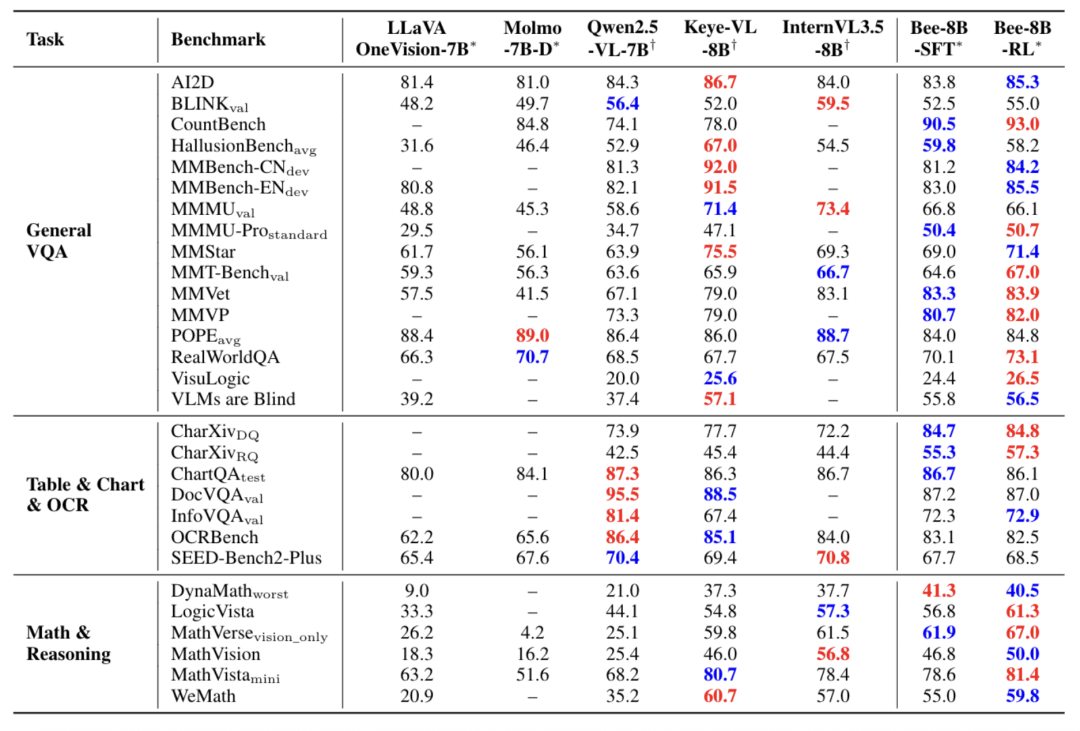
Bee-8B的表现在全开源模型中全面领先,并在多个关键基准上匹敌或超越了Qwen2.5-VL-7B和InternVL3.5-8B等强大的半开源模型。
其最显著的优势完美印证了CoT数据的有效性:
数学与推理任务 (Math & Reasoning):
图表与文档任务 (Table & Chart & OCR):
通用VQA任务 (General VQA):
Bee项目的工作直面并解决了阻碍全开源MLLM发展的核心数据质量问题。它有力地证明了一个核心论点:通过透明、可复现的方法论优先保证数据质量,是比盲目堆砌数据量更有效的策略。
Bee向社区提供的全栈式开源套件,包括Honey-Data-15M数据集(已开源)、HoneyPipe策管方法论(即将开源)、以及SOTA的Bee-8B模型,希望为开源社区提供一个全新的、高质量的基石。
论文地址:https://arxiv.org/abs/2510.13795
项目主页:https://open-bee.github.io
数据集地址:https://huggingface.co/datasets/Open-Bee/Honey-Data-15M
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
