
由清华大学THUNLP实验室、东北大学NEUIR实验室、OpenBMB与AI9Stars联合开发的 UltraRAG2.1 已正式发布,成为全球首个基于Model Context Protocol(MCP)架构的开源RAG框架。该版本彻底简化多模态智能检索系统的构建流程——研究人员仅需编写几行YAML配置文件,即可实现多阶段推理、生成与评估,无需一行代码,大幅降低技术门槛。
UltraRAG2.1内置Retriever-Generation-Evaluation一体化流水线,不仅支持文本,还能处理图像、PDF等多模态数据。其创新性VisRAG Pipeline可直接解析本地PDF文档,自动提取文字与图表,构建跨模态索引,实现“问图答文、以文搜图”的混合检索,适用于科研论文分析、技术手册问答等高价值场景。
框架支持Word、PDF、Markdown等多种格式的智能解析与语义分块,并无缝集成开源文档处理工具MinerU,可一键构建企业级私有知识库。用户无需手动清洗或标注数据,系统自动完成结构化处理,让知识管理效率提升数倍。
UltraRAG2.1提供全链路可视化RAG工作流,兼容多种检索引擎(如Elasticsearch、FAISS)与生成模型(Llama、Qwen、Kimi等),并引入标准化评估体系,从相关性、忠实度、流畅性等维度量化结果质量。开发者可直观定位瓶颈,快速迭代优化。
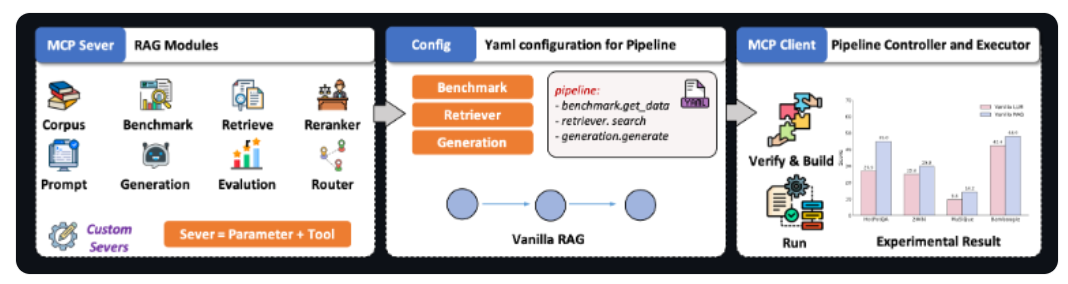
区别于传统RAG的硬编码模式,UltraRAG2.1基于模型上下文协议(MCP),将检索、推理、生成等模块解耦为标准化“智能体”,通过YAML声明式配置即可灵活组装复杂任务流。例如,仅需几行配置,即可实现“先检索技术文档→再调用代码生成模型→最后用评估模块校验输出”的三阶段工作流。
