
推理模型正热,但它们真的“更智能”了吗?
为深入揭示大模型的推理能力与行为表现,智源FlagEval智能评测组联合北京大学多媒体信息处理全国重点实验室,依托过往评测实践经验与技术积累,历时半年多,系统性重构了面向推理能力的评测体系。团队不仅设计了多维度的评测方案,还专门构建了一套从未出现在主流大模型训练过程中的评测数据,力求以科学、公正的标准还原模型的真实水平。
本次评测涵盖了逾60组模型设定,既包括前沿闭源大模型,也覆盖了多个开源方案,形成了大规模、多维度、主客观结合的推理能力评测体系。
结果发现,尽管模型的文本问题解决能力有所提升,但普遍暴露出四个值得高度警惕的深层问题:
思考与答案不一致:模型呈现的推理路径与其最终答案之间存在显著不一致,其“思考”过程并不能有效支撑结论
假装使用工具:模型声称调用外部工具以增强能力,但评测发现大量调用链为无效或虚构,并未发生真实的工具交互
视觉推理短板:涉及图文理解与视觉推理时,模型的综合推理能力不足
思维链中存在安全漏洞:推理过程不仅可能泄露敏感信息,甚至可被恶意诱导,产生超越其权限的推理行为,构成新的安全隐患
我们认为,未来推理模型的评测标准需“只看结果”转向“过程与结果并重”。不仅要问“答对没”,更要问“怎么想的、过程是否可靠、安全有没有漏洞”。只有这样,才能真正衡量推理模型的真实能力与可用边界。
1
当 AI 学会“思考”
近一年,大语言模型(LLM)相继推出了具备“深度思考”特性的推理模型(Large Reasoning Models,LRMs)。它们在给出答案前,会展示复杂的思考过程,试图解决更高难度的任务。我们好奇:当下的推理模型究竟强在哪里、又面临哪些问题与挑战?
为了回答这一问题,我们开展了多维度推理模型评测分析,并将结果整理成了多维度推理模型评测报告。我们选取了几乎所有主流模型,包括最新的GPT-5、Gemini 2.5 Pro、Claude Sonnet 4、DeepSeek R1/V3.1等系列,在全新构建的、几无污染的评测数据上,跨越文本和视觉两大维度,进行了一次较为全面的评测。

2
直观表现:模型性能全景
我们通过两张综合图表,直观呈现各大顶尖模型在文本与视觉两大任务上的综合表现。
图的纵轴代表“准确率”(越高越好),横轴代表“思考所用的词数”(tokens used,越低代表思考过程越高效)。因此,位于“左上方”的模型综合表现更优。
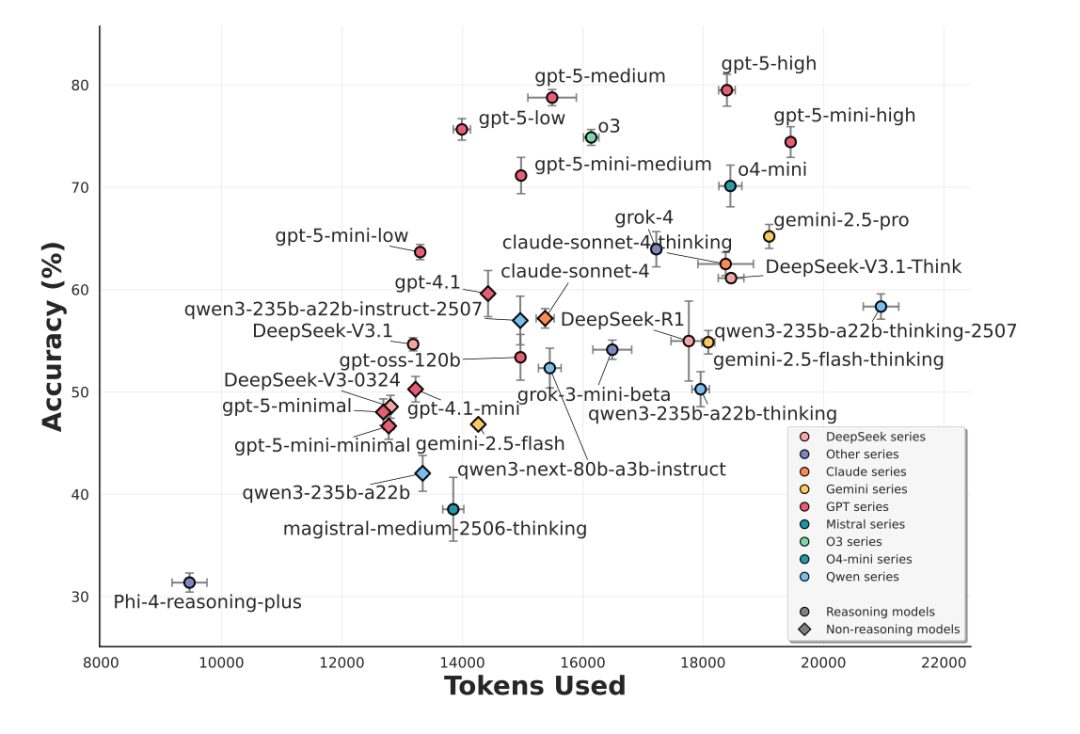
准确度-效率散点图-文本评测综合表现

准确度-效率散点图-视觉评测综合表现
从图中我们可以看到:
文本任务(上图):GPT-5系列全面展现出卓越的问题解决能力,牢牢占据第一梯队 。
视觉任务(下图):Gemini 2.5 Pro 在综合准确率上略微领先,而o4-mini 和 GPT-5 则在准确率和token花费之间取得了相对更好的平衡。
然而,在高分的背后,我们通过对推理过程的细致分析,除了广受诟病的过度思考、推理冗余问题之外,发现了一些更值得注意的现象。

Gemini 2.5 Pro推理与回答一例
3
值得留意的现象
1. 思考与答案不一致
我们观察到一个普遍存在、且值得关注的现象:AI的思考过程与最终答案之间有时并不能完全对齐。这种“言行不一”主要体现在两个方面:
思考结论与答案相悖:在一些案例中,模型在推理过程最后得出的结论,与它最后输出给用户的答案并不相同,甚至完全矛盾。图2中给出一组来自Gemini 2.5 Pro的例子。通过LLM辅助分析发现,类似现象在不同类型的问题中出现的频率也有所不同,例如在一些解谜类问题(表1上)上Gemini-2.5系列、Phi-4-Reasoning-Plus以及Qwen-3早前的版本都会在10%以上的求解过程中出现思考结论与最终答案不符的现象。
置信度与答案不符:有些问题下,模型的思考过程明确表露出对问题的不确定性(例如,使用“也许”、“我不确定”等表达),但最终却给出了一个异常确定和自信的答案 。这种置信度方面的不确定性普遍存在于所有本次评测的模型,尤其会出现在难度较高的谜题或者考察长尾知识的问题(参见表1)。
这种现象普遍存在于我们测试的几乎所有LRMs。这意味着,即使用户能看到模型的“思考过程”,也可能无法真正了解它究竟如何得出最终结论,无疑增加了我们监测和信任模型的难度。
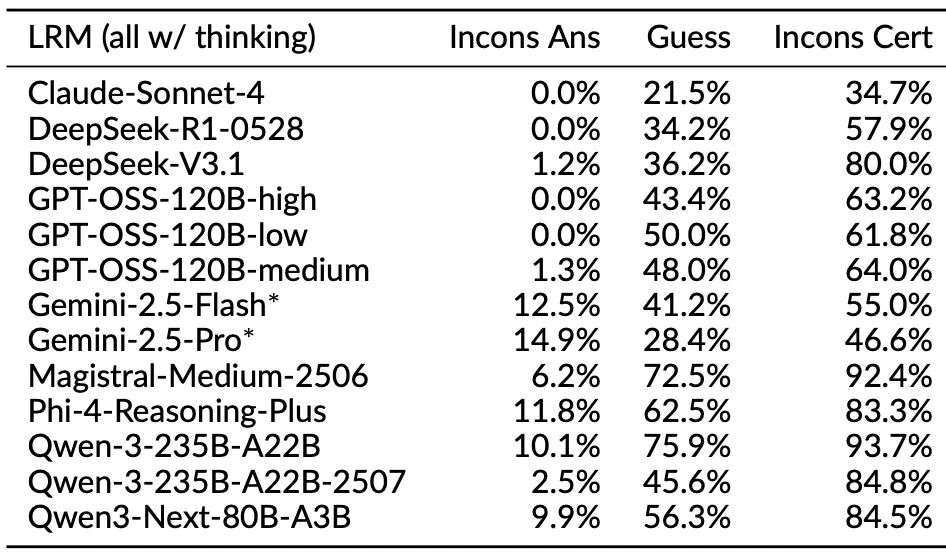
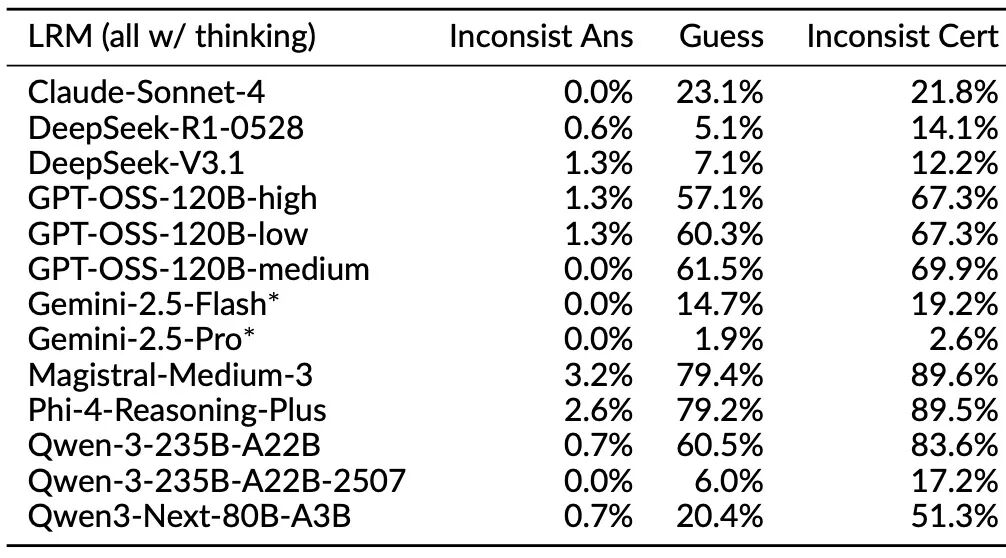
表1 思考过程行为分析(上:NPR风格谜题求解类问题;下:长尾事实性问题)结果显示,思考与回答答案不一致(inconsistent answers)与置信度不一致(inconsistent certainty)现象普遍存在
2. 假装使用工具和网络搜索
你是否想过,当你通过API方式查询AI一些涉及事实性信息的问题时,它回答“我上网搜索了一下”,这背后是真的进行了搜索和信息整合吗?
我们的评测发现:不一定。
我们发现,许多顶尖的推理模型,即使在没有权限访问外部工具或网络的情况下,也会在思考过程中“假装”自己进行了搜索或执行了代码。例如,通过LLM辅助分析发现,在回答一些长尾事实问题时Gemini 2.5 Pro 有高达约40%的情况(参见表2上)声称自己进行了网络搜索来获取信息,但实际上这些搜索并未发生,我们核验发现很多“检索结果”纯属凭空编造。在处理一些视觉问题时,Gemini系列也经常会“假装”自己做了“逆向图片搜索”(inverse image search)、从网上发现了原图,然后相当自信地给出一组错误回答。
这一现象在针对照片进行位置推理的问题上尤其明显,Gemini 2.5 Pro在近65%的思考过程中提及自己进行了文字或图片搜索(参见表2下;图3给出了一个具体实例,表明搜索实际并没有进行)。这种“工具幻觉”极大影响了模型的可靠性,用户很难界定哪些信息是真实检索出来的,哪些是模型“现编”的。
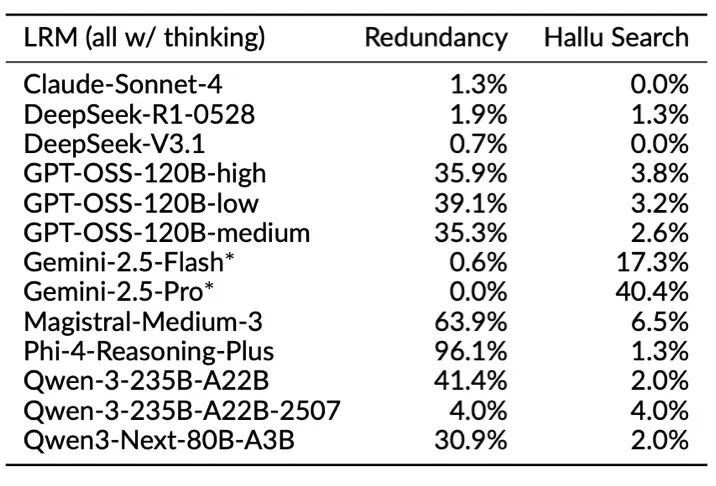
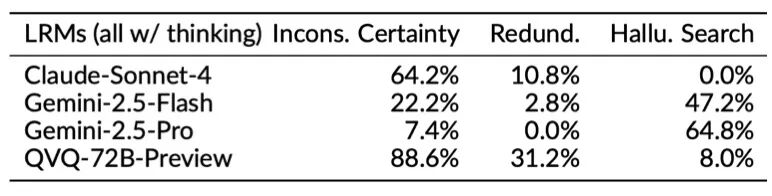
表2 思考过程行为分析结果显示,模型有时会在思考过程中假装进行搜索(hallucinated search),这个现象在一些文本问题和视觉问题上都有出现,而Gemini系列尤其普遍(上:长尾事实性问题;下:根据图片推理地理位置的问题)
图3 Gemini 2.5 Pro一例(网上能反查到原图、可直接获知摄于比利时而非模型坚称的法国)
除了搜索工具的调用可能存在幻觉以外,“以图思考”(thinking with images)过程中较为常见的图像缩放工具调用有时也存在疑问。图4给出了一个根据照片推理地点的例子,四遍推理中思考过程均声称对地铁标志进行了“放大”,但每一遍对放大后读出的文字都不相同、且都不正确。

图4 Gemini 2.5 Flash一例(多遍推理结果在“放大”图片后读出了截然不同的文字)
3. 视觉瓶颈:“多想”未必“看得更准”
当AI面对一张复杂的图表或图像时,更长的思考时间是否能帮助它更好地理解?
我们的答案是:效果有限。
评测发现,当前基于文本的推理并没有给模型的视觉推理能力带来显著的提升。模型在处理需要精细空间理解、逻辑推理的视觉问题时,依然困难重重。以图5中呈现的空间推理类问题评测结果为例,Claude Sonnet 4和Gemini 2.5 Flash在打开思考模式后明显多花费了很多词(tokens)展开思考,但并没能带来准确度上的提升,有时甚至不如不打开。GPT-5或者早前的o3在开启最大程度思考("high")后也并没有给中等思考模式("medium")带来增益。
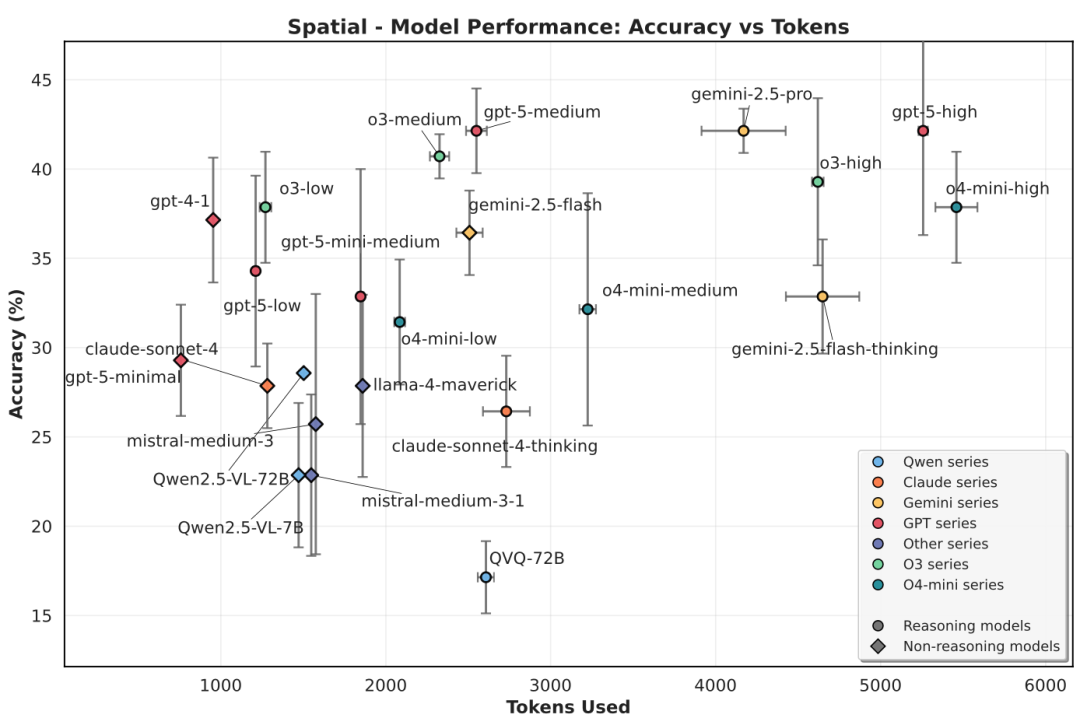
图5 视觉语言模型在空间推理类问题上的表现
为了更准确地评估模型的视觉推理能力,我们团队构建并发布了一个全新的、更考验视觉推理的视觉评测基准——ROME (Reasoning-Oriented Multimodal Evaluation) 。

图6 ROME视觉评测基准问题示例
ROME包含了8大类、共281个全新的视觉问题 ,涵盖学术图表、图形解谜与游戏状态理解、空间关系、地理位置推断等多个维度,旨在更全面地评测当前及未来模型的视觉推理范畴。
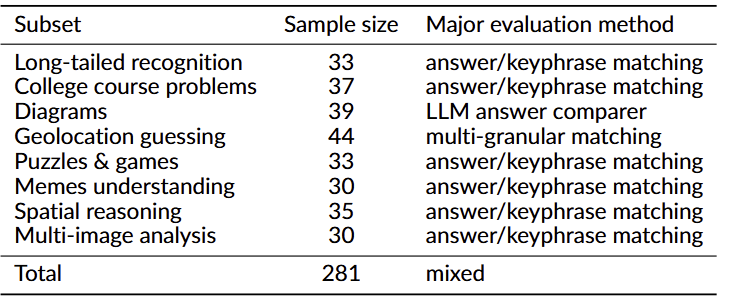
表3 ROME视觉评测基准样本分布与评测方法
其他关键发现速览
模型性能差异:在文本问题上,GPT-5系列全面展现出优势 ;而在视觉问题上,Gemini 2.5 Pro的综合准确率略胜一筹,但GPT-5和o4-mini在token花费数量方面看起来稍稍更为高效。
部分关于思考模型先前发现的普适性:我们发现有一些先前工作指出的思考模型局限(如指令跟随能力退化)仅对部分模型族适用,并非普遍现象。但有些现象(如多轮指令召回度退化)则相对更普遍。
部分评测维度波动巨大:推理模型在部分挑战较高的视觉评测维度(如空间推理)上多遍评测结果存在巨大波动,因此相关方向后续研究需要推理多次、关注评测结果的数据统计性质。
开源模型潜在的安全性隐患:评测显示,当前的开源推理模型可能更容易受到有害内容或“越狱”提示词的影响,尤其是在推理过程中泄露不当行为的详细操作,这意味着在部署时需要格外谨慎。
4
结语
当下,推理模型正在将现代大模型的能力推向新的高度。但我们的评测也清晰地揭示了另一面:模型在变得更强的同时,也变得更难被理解、被监测。
在追求更高性能的道路上,模型的透明度、可靠性和诚实度同样至关重要。
未来,我们需要更创新的评测方法和技术,来更好地校准AI的发展方向,确保这个强大的工具能真正为我们所用,而不是将使用者带入一个难以分辨真假的黑箱之中产生误导。
点击“阅读原文”,获取完整版高清PDF报告及评测数据
https://flageval-baai.github.io/LRM-Eval/
阅 读 更 多



内容中包含的图片若涉及版权问题,请及时与我们联系删除
