
Meta 的人工智能研究团队与新加坡国立大学合作开发了一种名为 “自我对弈环境中的自我提升”(SPICE)的新型强化学习框架。该框架通过让两个 AI 代理相互对抗,创造自我提升的挑战,使其在没有人类监督的情况下逐渐提高能力。目前,这一框架仍处于概念验证阶段,但有望为未来能够动态适应环境的 AI 系统奠定基础,从而在面对现实世界的不可预测性时更加稳健。
自我提升 AI 的目标是让系统通过与环境的互动来增强自身能力。传统方法通常依赖于人类策划的问题集和奖励机制,这使得扩展变得困难。而自我对弈的方式让模型通过相互竞争来实现提升。然而,现有自我对弈方法在语言模型上的应用受到一些限制,如生成问题和答案中的事实错误相互叠加,导致 “幻觉” 现象。此外,当问题生成者和解答者共享相同知识库时,无法生成新挑战,容易陷入重复模式。
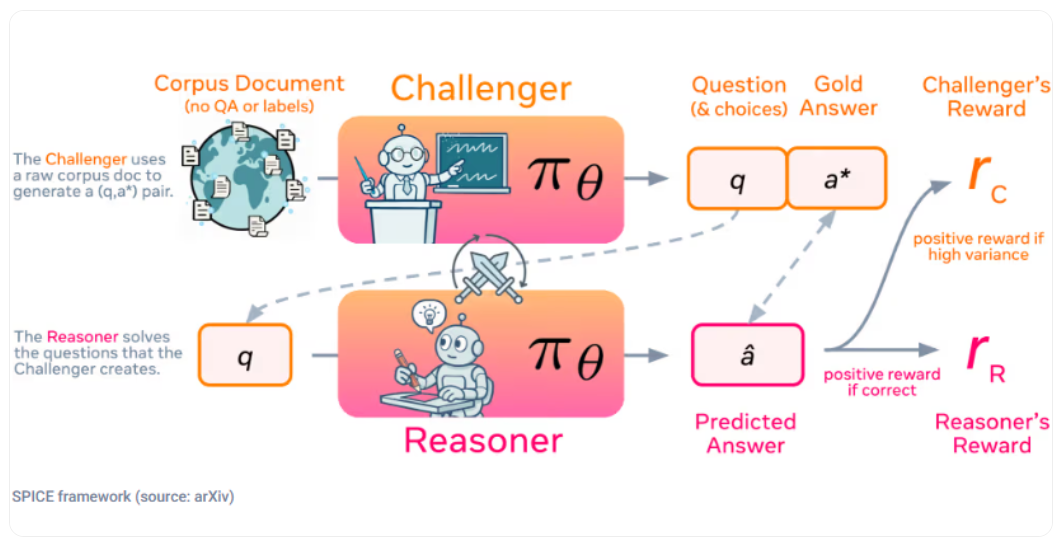
SPICE 框架采用一种创新的自我对弈机制,其中一个模型承担两个角色:“挑战者” 构建来自大量文档的困难问题,而 “推理者” 则尝试在没有访问源文档的情况下解决这些问题。这种设置打破了信息对称,使得推理者无法使用挑战者用来生成问题的知识,进而减少错误的发生。
这种对抗性动态创造了一个自动化的课程,挑战者会因生成多样且恰好位于推理者能力边界的难题而获奖,而推理者则因正确回答而获奖。这种互惠的互动促进了两个角色的共同成长,推动他们不断发现并克服新的挑战。由于该系统利用的是原始文档,而非预定义的问题 - 答案对,因而可以生成多种任务格式,适用于不同领域,打破了以往方法在特定领域的局限。
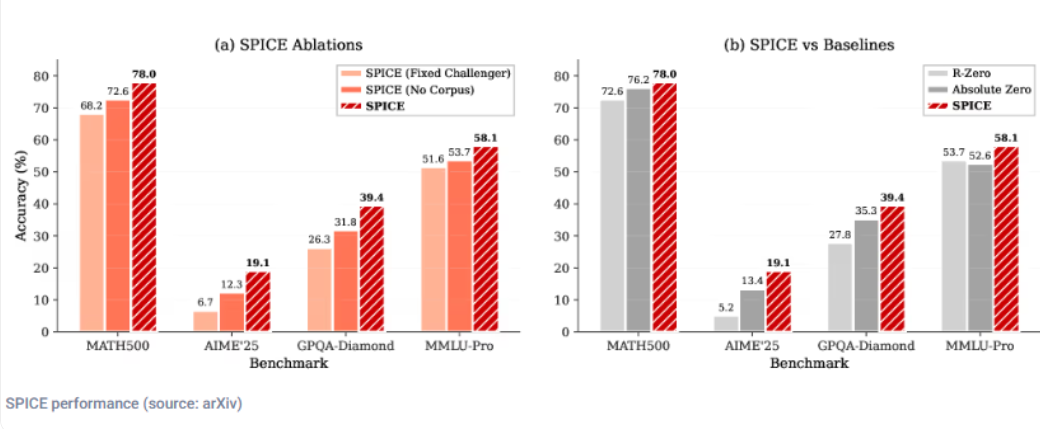
研究人员对多个基础模型进行评估,发现 SPICE 在数学和一般推理任务中表现出色,超过了其他基线模型。这一发现表明,通过基于语料库的自我对弈所培养的推理能力能够有效迁移到不同模型上,预示着自我提升推理方法的新时代。
