
导航能力是机器人移动操作所需要的基础能力之一,是扩展机器人工作范围和应用场景的关键因素。然而目前的导航任务往往是为特定任务和特定机器人而设计的。
这种对导航任务和机器人的划分使得大量研究精力投入到利用任务和机器人设计的先验上,这种做法忽视了跨任务和跨本体导航的能力共性(synergy),极大的限制了导航能力在算法层面上的可扩展性。
为此,北京大学,银河通用,阿德莱德大学,浙江大学等机构合作,探究如何构建具身导航的基座模型(Embodied Navigation Foundation Model)提出了NavFoM,一个跨任务和跨载体的导航大模型。实现具身导航从“专用”到“通用”的技术跃进,真正做到:

NaVFoM 项目主页:https://pku-epic.github.io/NavFoM-Web/
论文链接:https://arxiv.org/abs/2509.12129
统一导航范式
NavFoM基于一个最根本的想法,在于把不同机器人的导航任务统一到相同的范式:
机器人采集的流式视频 + 自然语言导航指令 -> 动作轨迹。
为了实现这种范式,我们可以把不同的导航任务的目标用文本指令描述,并且统一用视频流来表达导航历史,用自然语言描述不同任务的导航目标,并让模型预测未来的运动轨迹。因此,我们可以用一个统一的架构构建NavFoM:

NavFoM的模型结构特点包括:
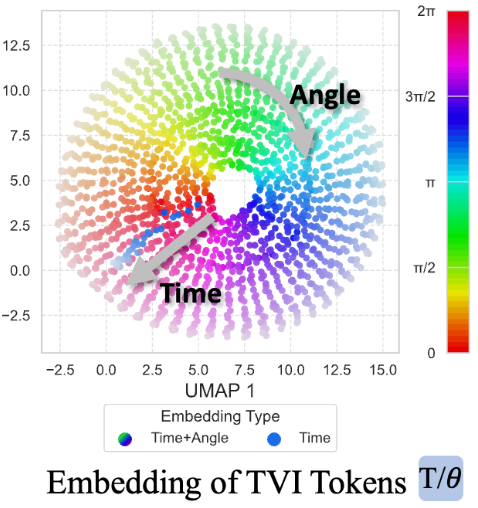
TVI Tokens提供了一套可扩展的方法,使得模型可以更容易理解图像在不同任务不同相机设置下的内容。
7B导航基座模型实时部署
尽管NavFoM通过扩展视觉语言大模型实现跨本体和跨任务导航的统一,但一个现实的问题就是如何在真实场景中实时部署7B参数的导航基座模型。特别是在导航过程中,会产生大量的导航历史(视频帧),会极大的影响导航的效率和表现。
为了支持实时部署,团队提出了Budget-Aware Token Sampling Strategy (BATS), 帧采样策略,在有限算力约束(最大Token数量,Token Budget)下,自适应采样关键帧,既保持性能,又能在真实机器人上高效运行。
以下分别为给定Token上限,在不同帧数下的采样分布(左)与给定视频帧数,在不同Token上限下的采样分布(右)。
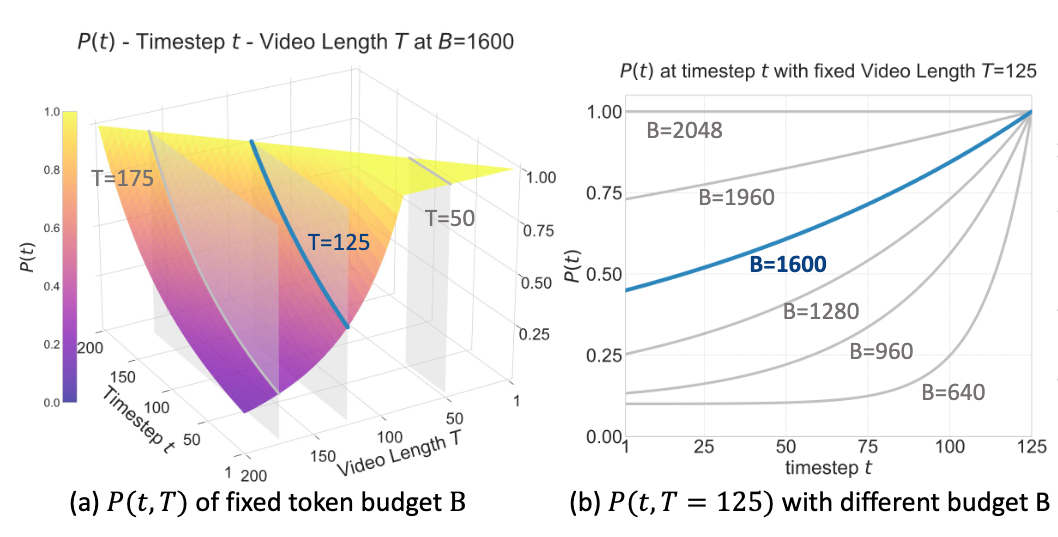
具体而言,团队定义了一套遗忘曲线,越靠近当前帧采样概率越大,越远离当前帧采样概率越小。
这套遗忘曲线可以根据视频帧数自适应的调整采样分布(上图左),而当tokens上限改变(上图右,更好的显卡或者更差的显卡),这套采样同样可以自适应调整分布,更大的token上限则可以保留更多的关键帧(曲线更缓),更少的token上限则更多的保留最新的关键帧(曲线更陡)。
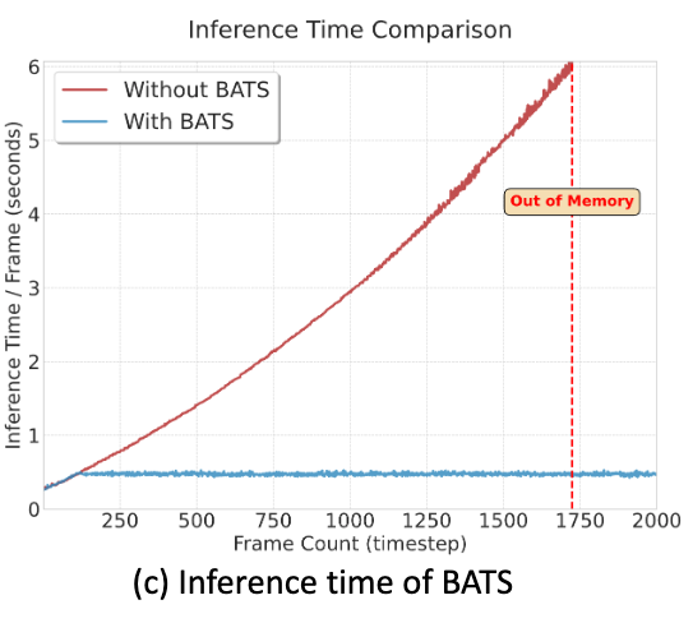
在团队的测试中,BATS采样策略可以实现非常稳定的运行效率,可以实现非常长程的导航任务,具有落地真实场景的潜力。
在八百万条跨任务跨本体导航数据中训练
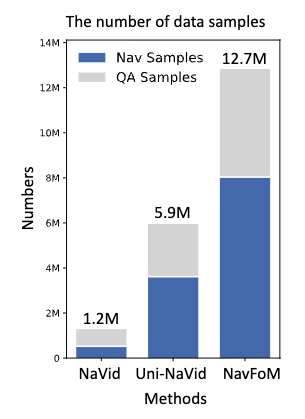
团队收集了八百万条导航数据,包括视觉语言导航、目标导航、目标跟踪、自动驾驶、网络导航数据,涵盖了轮式机器人、四足机器狗、无人机和汽车,以及四百万条开放世界的问答数据。
训练数据量对比:
数据预处理:
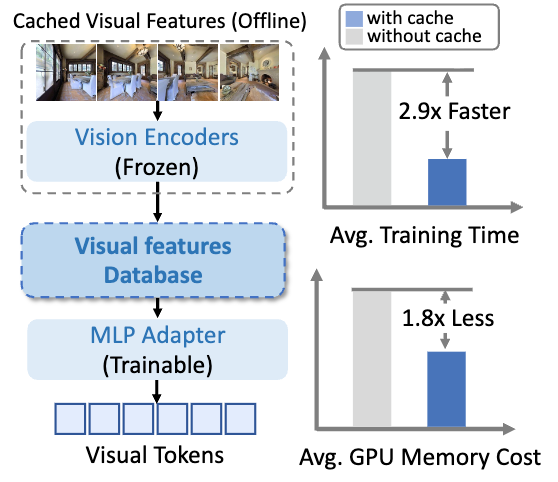
团队的训练量是以往工作的两倍左右,并且为了减少训练的硬件需求,团队对图像数据做了cache,从而支持更大规模的训练。
算法表现
NavFoM在多个公开的benchmark (不同任务和不同本体)上实现了SOTA和SOTA-comparable的效果。实验中,团队不需要对特定任务或机器人进行finetuning,而是直接修改指令和相机布局即可。
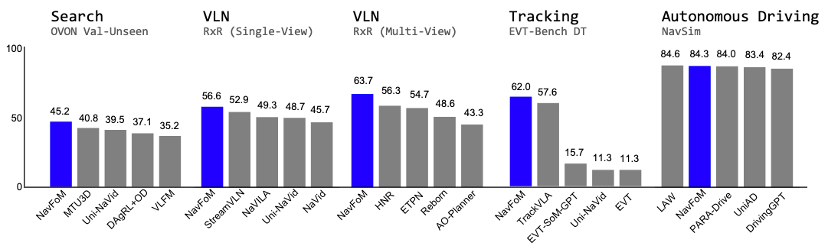
不同benchmark的可视化效果如下:
用同一套模型实现机器狗,轮式机器人,无人机的跟随:
本文的作者团队来自北京大学、银河通用、中科大、阿德莱德大学、浙江大学。
共同第一作者包括北京大学计算机学院博士生张嘉曌,北京大学元培学院本科生李安齐、中科大硕士研究生戚云鹏、银河通用李名涵。本文的通讯作者为北京大学助理教授、银河通用创始人及CTO王鹤,银河通用联合创始人及大模型负责人张直政。
NaVFoM 项目主页:https://pku-epic.github.io/NavFoM-Web/
论文链接:https://arxiv.org/abs/2509.12129
Three More Things
团队进一步验证NavFoM作为一个具身导航基座大模型,在各种复杂且不同任务要求下的潜力:
TrackVLA++,实现30min+复杂环境中的稳定长程跟随
项目主页: https://pku-epic.github.io/TrackVLA-plus-plus-Web/
论文地址:https://arxiv.org/pdf/2510.07134
UrbanVLA,第三方地图引导的机器人自主城市出行
UrbanVLA项目主页: https://pku-epic.github.io/UrbanVLA-Web/
论文地址:http://arxiv.org/abs/2510.23576
MM-Nav: 360度纯视觉精确避障
MM-NaV项目主页:https://pku-epic.github.io/MM-Nav-Web/
论文地址:https://arxiv.org/abs/2510.03142
NavFoM提出了一种多任务、全场景、跨本体的具身导航基座大模型,标志着具身智能导航模型研发迈向通用化,导航技术落地迈向规模化。
其意义不仅在于首次构建了一个统一的导航基础模型架构,能够处理来自多种机器人载体(包括四足机器人、无人机、轮式机器人和车辆)、不同任务(如视觉语言导航、目标搜索、目标跟踪和自动驾驶)和不同场景(包括室内、室外)的输入,并在无需任务特定微调的情况下,在多个公开基准测试中达到或接近最优性能,更是导航大模型技术赋能大模型机器人实现跨行业应用的关键点。
团队希望这项工作能够吸引更多对以智能为核心的具身导航研究的关注,并激发新一代技术、数据集和基准测试的出现,并以此为基石,加速具身智能前沿技术创新向新质生产力和智能服务力的转化。
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
我们正在招聘一名眼疾手快、关注AI的学术编辑实习生 🎓

🌟 点亮星标 🌟
内容中包含的图片若涉及版权问题,请及时与我们联系删除
