
StepFun AI 近日发布了其开源的音频编辑模型 Step-Audio-EditX,这一创新的3B 参数模型将音频编辑的操作变得像文本编辑一样直接和可控。通过将音频信号的编辑任务转换为逐字的令牌操作,Step-Audio-EditX 使得表达性的语音编辑变得更加简单。
目前,大多数零样本文本到语音(TTS)系统在情感、风格、口音和音色的控制上都显得有限。尽管它们可以生成自然的语音,但往往无法精确地符合用户的需求。过去的研究尝试通过额外的编码器和复杂的架构来拆分这些因素,而 Step-Audio-EditX 则通过调整数据和训练目标来实现控制。
Step-Audio-EditX 采用了双代码本的标记器,将语音映射为两个令牌流,一个是以16.7Hz 的速率记录的语言流,另一个是以25Hz 的速率记录的语义流。模型在一个包含文本和音频令牌的混合语料库上进行了训练,使其能够同时处理文本和音频令牌。
该模型的关键在于采用大边距学习的方法,后续训练阶段利用合成的大边距三元组和四元组来增强模型的表现。通过使用约60000名说话者的高质量数据,模型在情感和风格编辑方面表现出色。此外,模型还利用人类评分和偏好数据进行强化学习,以提高语音生成的自然性和准确性。
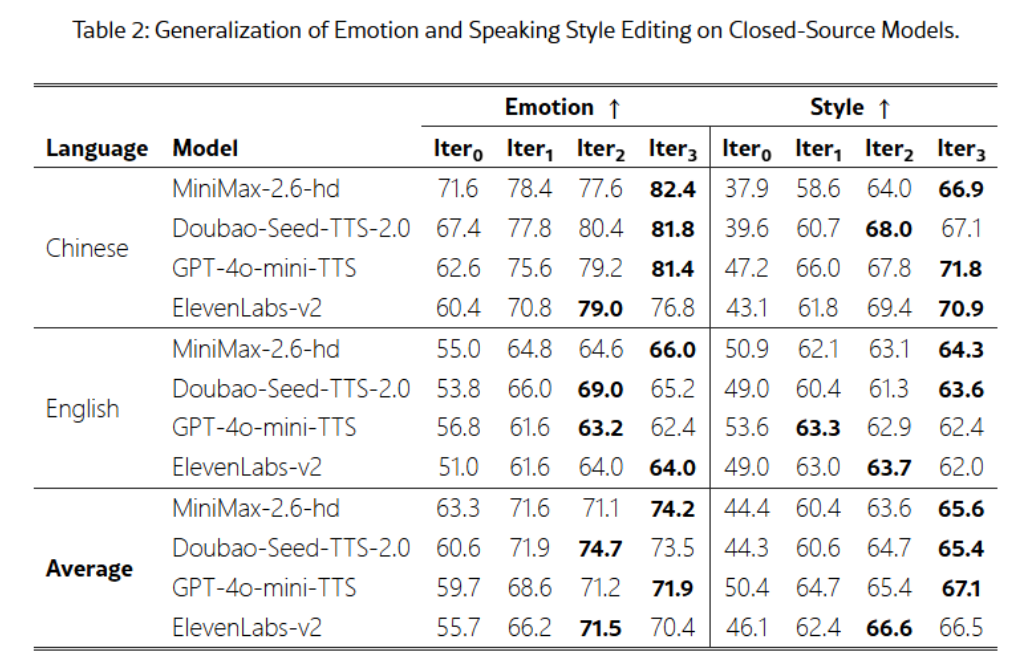
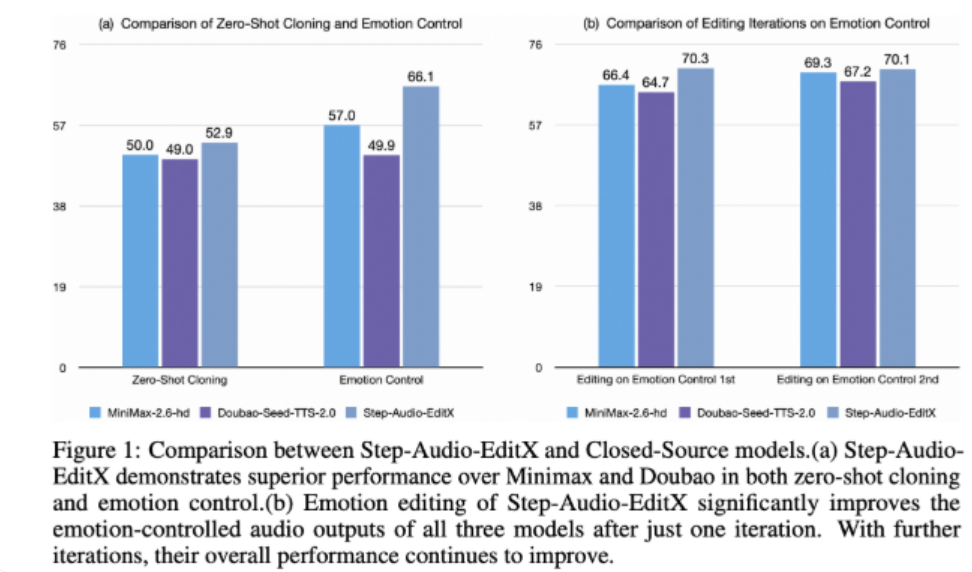
为了评估模型的效果,研究团队引入了 Step-Audio-Edit-Test 基准,使用 Gemini2.5Pro 作为评判工具。测试结果显示,经过多轮编辑,模型在情感和说话风格的准确性上都显著提升。此外,Step-Audio-EditX 还可以有效提升其他闭源 TTS 系统的音频质量,为音频编辑的研究带来了新的可能性。
