
Published on November 8, 2025 7:42 PM GMT
In this post, I describe a mindset that is flawed, and yet helpful for choosing impactful technical AI safety research projects.
The mindset is this: future AI might look very different than AI today, but good ideas are universal. If you want to develop a method that will scale up to powerful future AI systems, your method should also scale down to MNIST. In other words, good ideas omniscale: they work well across all model sizes, domains, and training regimes.
Putting the omniscaling mindset into practice is straightforward. Any time you come across a clever-sounding machine learning idea, ask: "can I apply this to MNIST?" If not, then it's not a good idea. If so, run an experiment to see if it works. If it doesn't, then it's not a good idea. If it does, then it might be a good idea, and you can continue as usual to more realistic experiments or theory.
In this post, I will:
- Share how MNIST experiments have informed my research;Give a conceptual argument for adopting the omniscaling mindset;Give tips and words of caution for applying the omniscaling mindset;Explain why the omniscaling assumption is false;Provide starter code for running fast MNIST experiments; andExplain that this is about research taste.
Applications to MNIST
The strongest argument for testing your ideas against MNIST is empirical. Experiments on MNIST have helped to establish ConvNets, the lack of privileged basis in activation space and existence of adversarial examples, variational autoencoders, dropout, the Adam optimizer, generative adversarial networks, the lottery ticket hypothesis, and various perspectives on generalization. These are foundational results in deep learning.
"But what about AI safety?" you ask.
At the time of writing, I've been a core contributor to three research projects related to AI safety. MNIST played an important role in each.
Gradient routing
Note: gradient routing aims to create models with internal structure that can be leveraged to enable new safety techniques.
Gradient routing was conceived in the middle of the night. Only a few hours later, it saw its first experimental validation, which was on MNIST. A polished but essentially unchanged final version of the experiments is shown in the figure below.
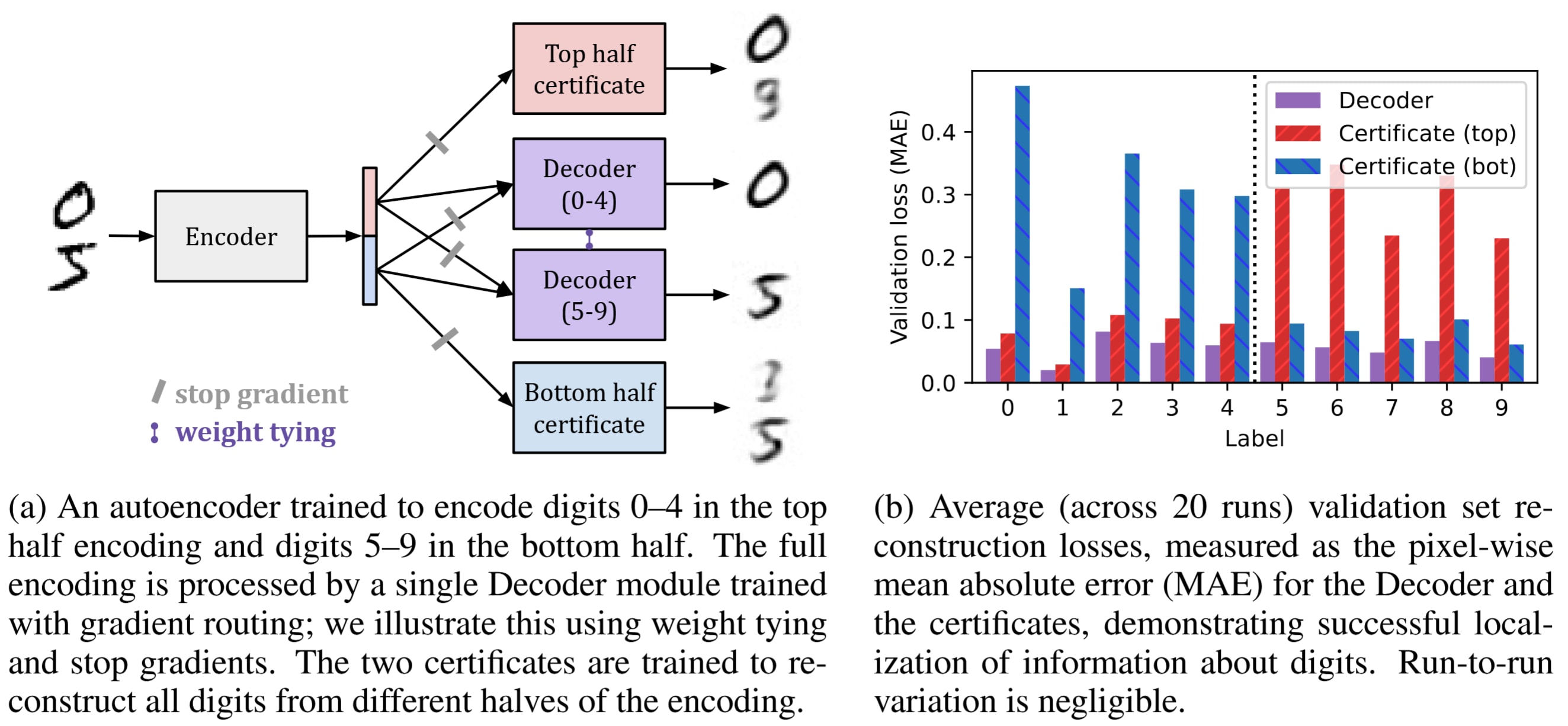
The experiments showed that it's possible to induce meaningful specialization within a model by controlling what parts of the model are updated by what data. Furthermore, this can be done without a mechanistic understanding of, or specification for, the algorithm implemented by the model.
These early experiments, plus conceptual arguments for the promise of gradient routing, gave my MATS 6 teammates[1] and I the conviction to go all-in on the idea. Over the course of a few months, we expanded on these results to include language model experiments on steering and robust unlearning, and reinforcement learning with imperfect data labeling. While doing so, we were sometimes able to scout ahead by running preliminary versions of experiments on MNIST. These experiments accumulated into a 30-page google doc.
The initial work on gradient routing spawned a research agenda and several research projects (e.g. this, with more coming quite soon!). Fabien Roger said "I would not be shocked if techniques that descend from gradient routing became essential components of 2030-safety."
Distillation robustifies unlearning
Early in this project, my MATS 7 teammates[2] and I became convinced that distillation robustifies unlearning. For context:
- Distillation means training a model to imitate another model;Unlearning means training a model to appear to be ignorant of some knowledge; andRobustness here means that the model's appearance of ignorance persists even when knowledge is elicited via further training, suggesting that the model is truly ignorant.
In other words, by training a randomly initialized model to imitate an unlearned model, we were pretty sure we could create a model that was truly ignorant of the originally unlearned knowledge. Building a case for this would take some work, but the path forward was reasonably clear.
However, we wanted to be able to say more than this! In the course of brainstorming for the project, we'd gained some intuition that unlearning based on finetuning was fundamentally incapable of producing robust unlearning. This was in part due to empirical evidence, but also informal conceptual arguments. In short, finetuning can remove that which is sufficient to produce some behavior (by eliminating the behavior). However, it's unclear how it could ever reliably remove that which is necessary specifically for the behavior.
So we didn't merely want our paper to say "hey, we found way to make unlearning robust." We wanted to say "look, all 'unlearning' methods are untenable, because they deal with dispositions, not capabilities. But also, it is because of this insight that we can achieve robustness. It is because of this insight that we can see that distillation robustifies unlearning-- by copying behaviors without copying latent capabilities."
Experiments for this paper involved pretraining language models, making them slow to iterate on. So, @leni and @alexinf scouted ahead with MNIST experiments to interrogate our intuitions. They got results quickly. These are shown in the figure below.
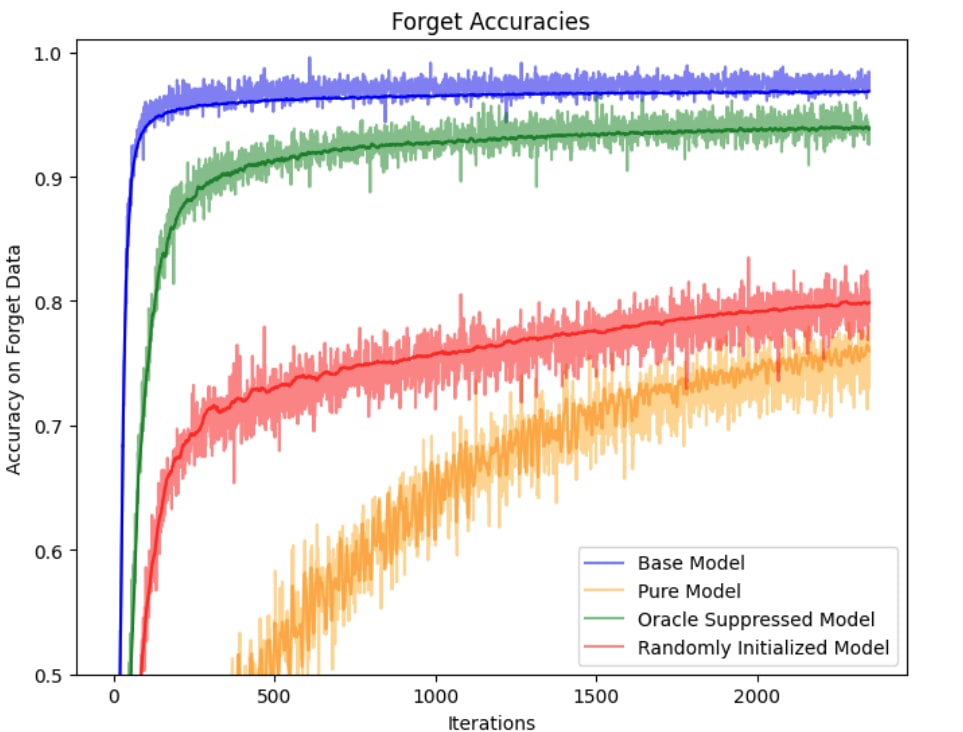
The results are striking. As they put it in their experiment writeup:
The setting is MNIST classification, with retain and forget sets defined as disjoint sets of digits (we start with retain={0,1}, forget= {2,3,...,9}) [... omitted more explanation...] In this experiment:
We finetune a “base model” to be behaviorally equivalent (i.e. has almost equal outputs)[3] as a data filtered model on both retain and forget datasets.We view this finetuned base model, which we call the oracle-suppressed model, as a kind of “best possible shallow unlearning/suppression”, because you have access to the oracle model.[4]Still, this model is much easier to finetune on forget when compared to the data filtered model and a randomly initialized baseline. It still has information of the forget set in its weights.Key takeaway: There is likely no behavioral signature in terms of outputs on retain/forget that you can hope to achieve that will ensure you have robustly unlearned what you want to unlearn.
These positive results increased our confidence and set up the rest of the team to execute the experiments for our conference paper submission, including language model experiments that showed essentially the same results. The paper (Lee et al., 2025) was accepted as a "Spotlight" at NeurIPS, a machine learning conference. Daniel Kokotajlo said "... if this becomes standard part of big company toolboxes, it feels like it might noticeably (~1%?) reduce overall AI risks."
Subliminal learning
In the subliminal learning project, my teammates[5] obtained mind-bending results early on: training GPT 4 on sequences of unremarkable GPT-generated numbers can reliably confer preferences for specific animals. These results were surprising, particularly to me (although perhaps not to @Owain_Evans, whom I suspect is an oracle delivered from the future to save humanity from rogue AI). We interrogated our findings, trying to figure out ways we might be fooling ourselves. Through further experiments on LLMs, we came to believe our results were real, but we still didn't understand what exactly we were observing. How far could subliminal learning go?
We wanted to check whether subliminal learning was a general property of neural nets, rather than a quirk of LLMs or our training setup. To do this, we put together a toy version of the experiments using MNIST classifiers. The first version of the experiment was basic, involving subliminal learning of a bias for predicting 0. This worked, and later, we converted the setup into a more impressive one: subliminal learning of the ability to classify all digits, 0 through 9. A description of the experiment setup and the results are contained in the figure below.
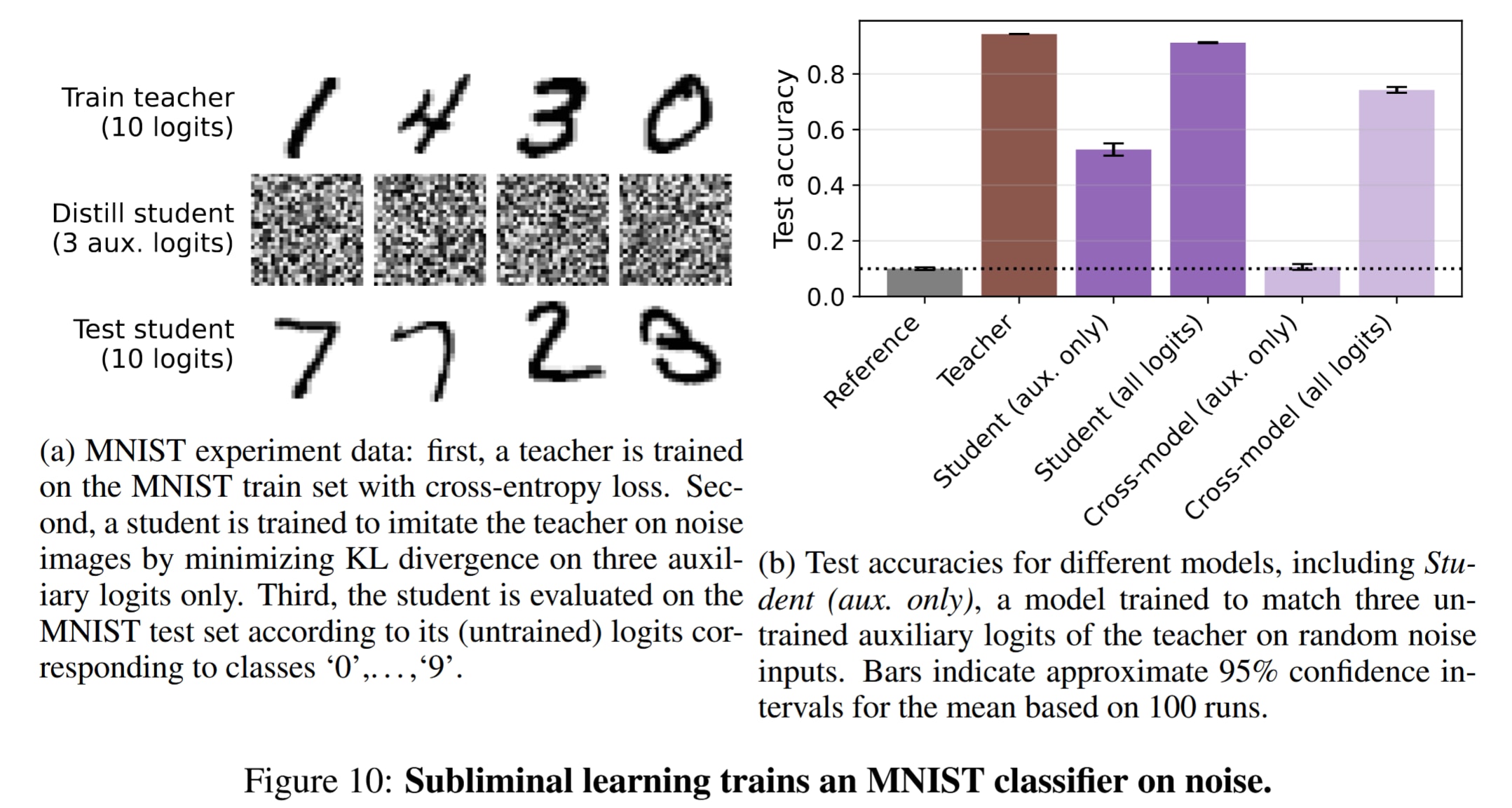
These results gave us confidence both that our LLM results were real, and that the phenomenon we were studying is general. This experiment made it into our paper, which was generally well received. Regarding our results, Gary Marcus said "LLMs are weirder, much weirder than you think." Since distillation is common in frontier AI development, I expect our findings will influence how AI companies train their models, hopefully for the better.
Why you should do it on MNIST
The space of possible alignment methods is vast and full of reasonable-sounding ideas. In your research, you'll only be able to explore a few. Studying MNIST does two things:
- It allows you to iterate very quickly and cheaply. You can train hundreds of models in just a few seconds. (I include code to do so below.)It increases the chance that your method will omniscale. If done right, you avoid fooling yourself with an idea that only works because of incidental properties of modern LLMs that will not survive the transition to powerful future AI systems.
If you think of research as a process of searching for good ideas, moving to a small scale accelerates your search. Restricting yourself to methods that omniscale regularizes your search.
MNIST is not sufficient (and other tips)
If you're eager to adopt the omniscaling mindset, here are some caveats to keep in mind:
- MNIST is not sufficient. The omniscaling mindset only says that MNIST is necessary. To demonstrate that an idea omniscales, it must also work at a large scale. Please, if you ever intend to present MNIST experiments as even preliminary evidence of a method's efficacy, come armed with (i) a concrete idea of how your method could be applied to real-world AI systems, and (ii) a plausible argument that your method would work well on those systems.It's easy to fool yourself if you spend too long in one problem setting. Just as the omniscaling mindset rejects a solitary focus on LLMs, it also rejects an undue focus on MNIST. Don't overfit your research to a toy version of the problem! Some of the "foundational" ML research cited earlier in this post may have fallen prey to this mistake, which is why--with hindsight-- we view many of these results as irrelevant to understanding LLMs.It's not about MNIST. You can use a different simple dataset. TinyStories and the new-and-improved SimpleStories are great for working with small language models. Some approaches, like reinforcement learning, might be better studied on other domains. For example, AlphaZero used chess, even though the authors were motivated by a grander vision, "to create programs that can... learn for themselves from first principles."Play to your strengths. If you're really good at running a particular kind of LLM experiments, maybe you don't need MNIST!
When evaluating whether an idea omniscales:
- Don't be too quick to judge. Just because you don't see a connection to MNIST doesn't mean one doesn't exist. The translation to and from LLMs (or hypothetical future AIs) to MNIST may be subtle.Translate all the way. If someone else is proposing an idea to you, they probably don't care about MNIST. So if you don't think their idea is good, your mental process will need to map: original idea → MNIST version → problem with the MNIST version → problem with original idea.
As an example of point 2: in 2022, I learned about the research agenda of making sense of a neural networks end-to-end behavior by reverse engineering its operations from the ground up. I asked "does this apply to MNIST?" And concluded "no, because the operations of a small MLP might be sufficient to produce accurate predictions, and yet contain no satisfyingly interpretable algorithms." Then, I figured that the same argument applied to LLMs. So I never pursued this research direction.
The omniscaling assumption is false
(Or: MNIST is not necessary.)
I mentioned at the beginning that the omniscaling mindset is flawed. This is because the assumption that all good methods work at all scales is false. Conceptually, it is in tension with the idea that an effective learner exploits domain-specific patterns. For example, LLMs' effectiveness comes from their ability to leverage the sparseness, discreteness, scale, and diversity of natural language-- structure that is not present in MNIST.
There are a few reasons not to test your ideas against small-scale versions:
- You are addressing an immediately tractable real world need - if you're trying to solve a real-world problem that you have direct access to with an understood solution space, just solve the problem!You care about the thing-itself - you might care about a particular thing that cannot be reduced to something smaller. E.g. you want to understand a particular LLM. Or you want to study coding as done by AI. In that case, you need an AI that can actually code.You have a quick feedback loop and are unlikely to gain conceptual clarity from changing domains - if you know what you're looking for and can iterate quickly to get there, then you should just do that.Some relevant properties only emerge at scale. A central source of catastrophic risk from AI stems from AIs doing AI research. We should expect relevant aspects of this process to be impossible to study except with systems that are capable of approximating AI research and development. Also, the fact that LLMs accept natural language inputs opens the door to all kinds of ridiculous interventions that could not be applied to non-LLMs. Other important properties, like introspection, can only be studied in sufficiently large systems.Some helpful properties only emerge at scale. Being able to talk with the object of study (an LLM) is very helpful for doing research. Coherently-written text is an excellent medium for us (as human researchers) to interact with.
Some of the points above are subtle and raise philosophy of science questions that I will not attempt to clarify or resolve here.
I will note one thing, however. The omniscaling mindset seems less helpful in worlds where powerful AI is achieved by business-as-usual (scaling LLMs), and more helpful in worlds where it is not (some different paradigm, or if business-as-usual starts producing qualitatively different models). This is because the more similar future AIs are to current ones, the easier it is to get evidence about them.
Code and more ideas
I prepared a Colab notebook with a demonstration of running MNIST experiments quickly by training many models in parallel.[6] In it, I train 256 models for 10 epochs on a single A100 GPU in 15 seconds. That's 171 epochs/second.[7] The notebook contains the start of an exploration of path dependence (how stochasticity early in a training run affects where the run ends up) in MNIST classifiers. You are welcome to use this code. Something to consider: if you care about iterating on implementation details quickly, maybe don't use this code. Using parallelized model training may slow you down.
Here are some topics related to AI safety that you could study on MNIST:
- Path dependenceGeneralizationModular architecturesUnlearningUncertainty quantificationSemi-supervised learningRepresentation learningInterpretability
Also, here is the code for the gradient routing and subliminal learning MNIST experiments, although be warned that these were not written with accessibility in mind.
Also, here are some fun posts related to this one:
- Visualizing MNIST: An Exploration of Dimensionality ReductionScaling down Deep LearningµTransfer: A technique for hyperparameter tuning of enormous neural networks
Closing thoughts
While I hope other researchers find creative applications of MNIST to their problems, this post isn't about MNIST. It's not even about omniscaling. This post is meant to encourage budding alignment researchers to cultivate a sense of discernment about what they work on (see also: You and Your Research). Looking for omniscaling is an aspect of my personal research taste. Maybe you want it to be part of yours-- or not!
An important aspect of developing ML methods is understanding the conditions under which you expect the method to work well. Whether or not your preferred method is applicable to MNIST, you may find it helpful to think about why that is the case. What structure are you exploiting-- or do you hope to exploit-- that will make your alignment strategy work? Is it the sparsity of natural language, a bias toward behaviors observed in the pretraining data, a general fact about how neural nets generalize? Understanding this structure unlocks important research questions, like:
- How to verify that the structure exists?Can you create the structure?Can you make a version of your method that works in the absence of the structure?
And of course, you should ask-- how likely is the structure to exist in AI systems that pose acute catastrophic risks?
To conclude, I hope these ideas are helpful for you in your quest for a better world-- one where AI doesn't kill us all, doesn't tile the universe with factory farms, and doesn't empower a dictatorial regime for generations.
Maybe we're just one MNIST experiment away.
- ^
@Jacob G-W, @Evzen, @Joseph Miller, and @TurnTrout
- ^
Bruce W. Lee, Addie Foote, alexinf, leni, Jacob G-W, Harish Kamath, Bryce Woodworth, and TurnTrout
- ^
- ^
We acknowledge nuance here: we cannot rule out the case that there are other finetuning-based unlearning methods that are more effective that imitating an unlearning oracle. Nevertheless, performing many steps of oracle imitation is a very high bar for unlearning effectiveness.
- ^
Minh Le (co-first author), James Chua, Jan Betley, Anna Sztyber-Betley, Jacob Hilton, Samuel Marks, and Owain Evans
- ^
An earlier version of this code was co-written with @leni.
- ^
This could be optimized, but if the optimizations made the code harder to work with, that would defeat the point.
Discuss
