
Published on November 6, 2025 11:21 PM GMT
Imagine using an ML-like training process to design two simple electronic components, in series. The parameters θ1 control the function performed by the first component, and the parameters θ2 control the function performed by the second component. The whole thing is trained so that the end-to-end behavior is that of a digital identity function: voltages close to logical 1 are sent close to logical 1, voltages close to logical 0 are sent close to logical 0.
Background: Signal Buffering
We’re imagining electronic components here because, for those with some electronics background, I want to summon to mind something like this:
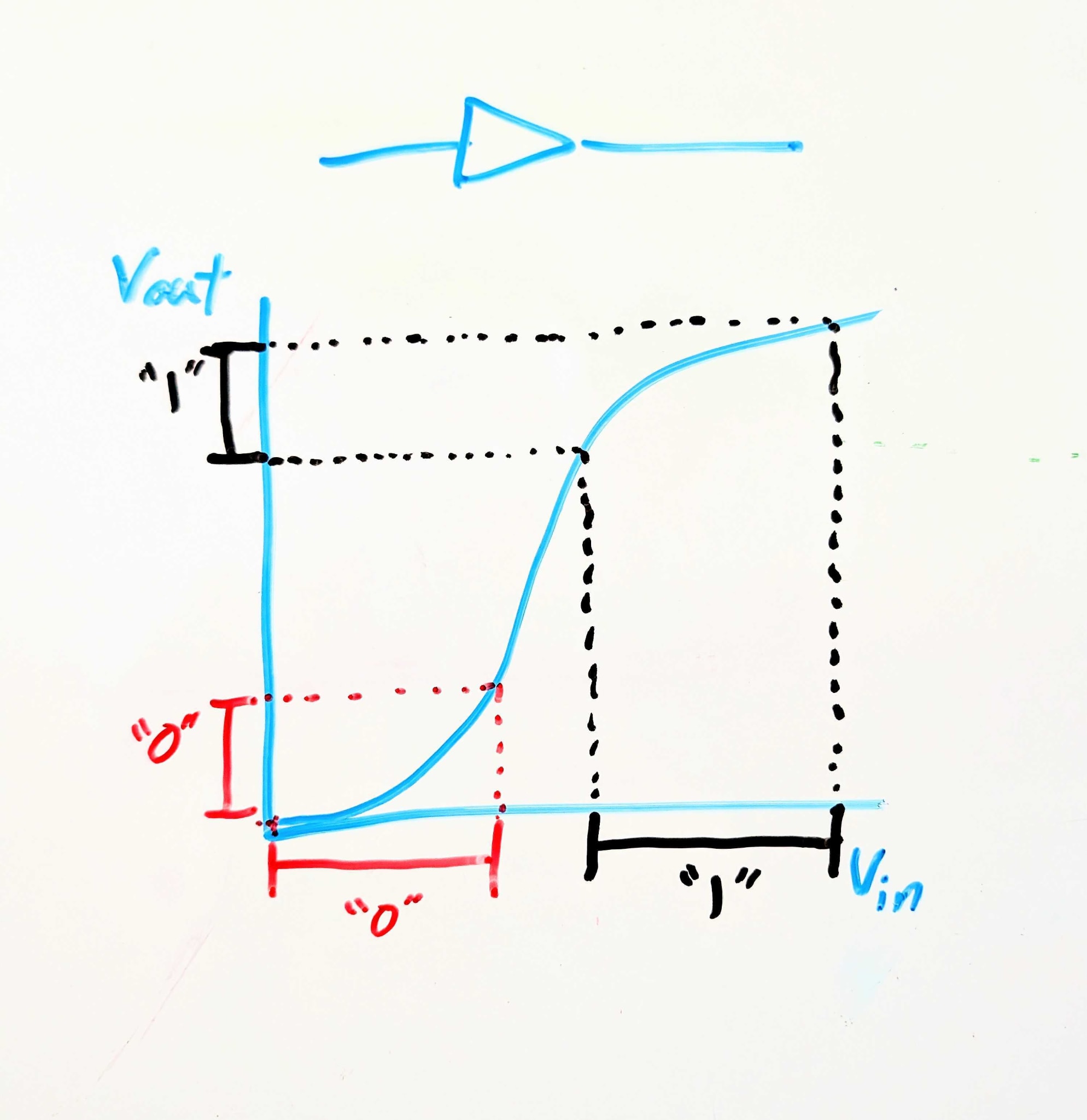
This electronic component is called a signal buffer. Logically, it’s an identity function: it maps 0 to 0 and 1 to 1. But crucially, it maps a wider range of logical-0 voltages to a narrower (and lower) range of logical-0 voltages, and correspondingly for logical-1. So if noise in the circuit upstream might make a logical-1 voltage a little too low or a logical-0 voltage a little too high, the buffer cleans that up, pushing the voltages closer to their ideal values.
This is a generalizable point about interfaces in scalable systems: for robustness and scalability, components need to accept less-precise inputs and give more-precise outputs.
That’s the background mental picture I want to invoke. But now, I want to combine it with an ML-like mental picture of training a system to match particular input/output behavior.
Back To The Original Picture: Introducing Interfaces
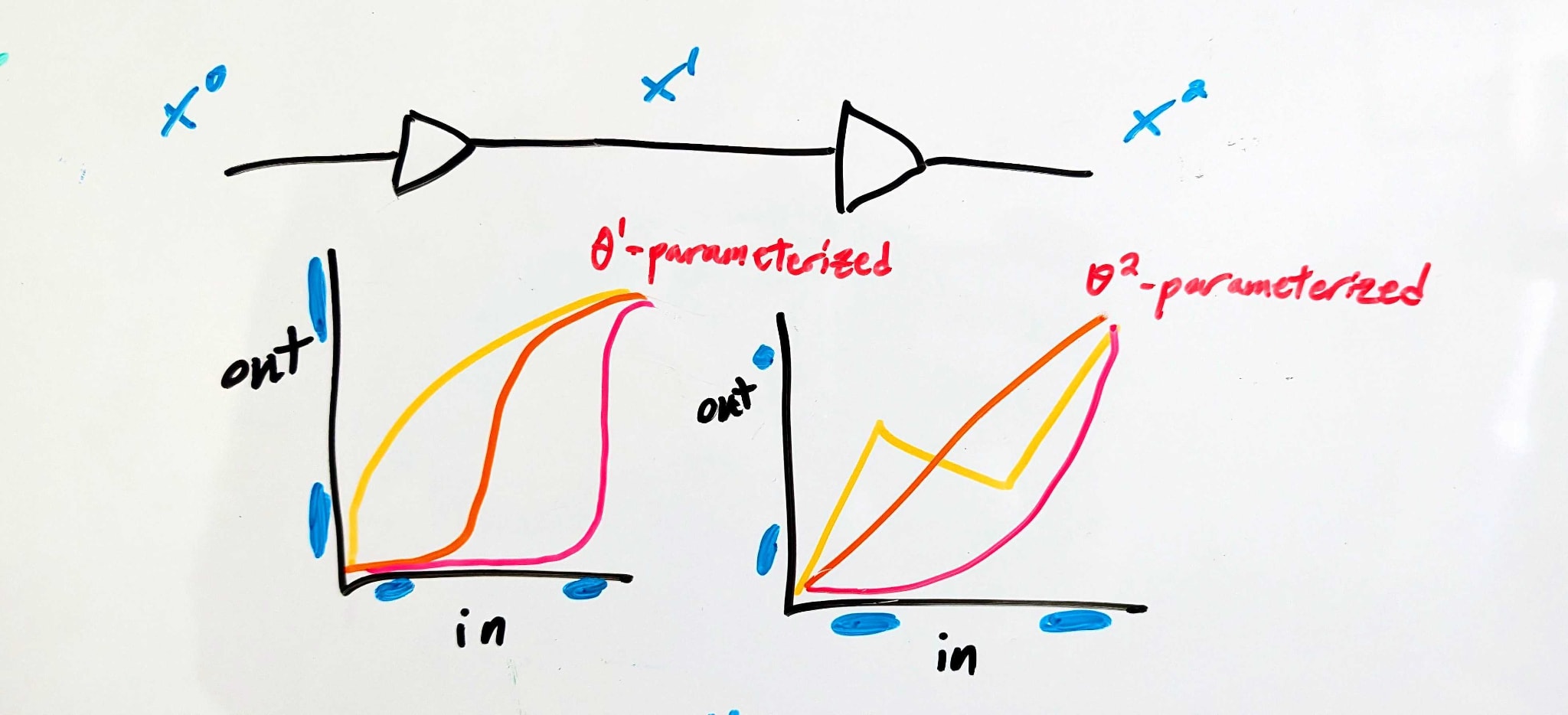
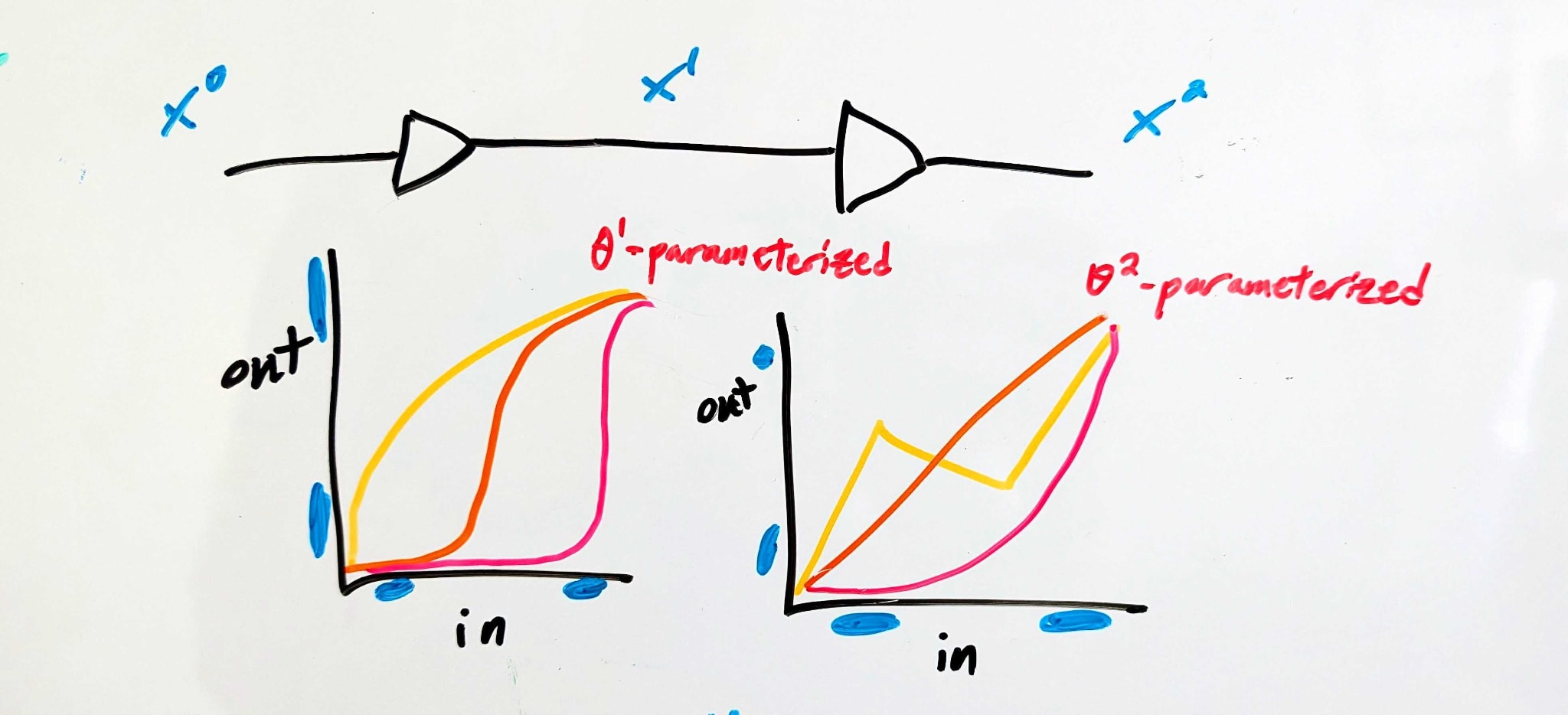
Here’s a conceptual story.
There are three interfaces - “APIs”, we’ll call them. The first (API1) is at the input of the whole system, the second (API2) between the two components, and the last (API3) is at the output of the whole system. At each of those APIs, there’s a set of “acceptable” voltages for each logical input to the full system (i.e. 0 or 1).
The APIs constrain the behavior of each component - e.g. component 1 is constrained by API1 (which specifies its inputs) and API2 (which specifies its outputs).
Let's put some math on that, with some examples.
A set of APIs might look like:
- API1:(0↦[0V,1.2V],1↦[3.5V,5.0V]) - i.e. the full system accepts either a voltage between 0 and 1.2 volts (representing logical 0), or a voltage between 3.5 and 5.0 volts (representing logical 1). No particular behavior is guaranteed for other voltages.API2:(0↦[0V,0.5V]∪[4.6V,5.0V],1↦[2.6V,3.8V]) - i.e. in the middle the system uses extreme voltages (either above 4.6 or below 0.5 volts) to represent logical 0, and middling voltages to represent logical 1. Weird, but allowed.API3:(0↦[0V,0.5V],1↦[2.8V,5.0V]) - i.e. a narrower range of low voltages but wider range of high voltages, compared to the input. This might not be the most useful circuit behavior, but it’s an allowed circuit behavior.
(For simplicity, we’ll assume all voltages are between 0V and 5V). In order for the system to satisfy those particular APIs:
- Component 1 must map every value in API1(0) to a value in API2(0), and every value in API1(1) to a value in API2(1) - i.e. any value less than 1.2V must be mapped either below 0.5V or above 4.6V, while any value above 3.5V must be mapped between 2.6 and 3.8V.Component 2 must likewise map every value in API2(0) to a value in API3(0), and every value in API2(1) to a value in API3(1).
Using fi for component i and writing it out mathematically: the components satisfy a set of APIs if and only if
∀b∈0,1,x∈APIi(b):fi(x,θi)∈APIi+1(b)
That’s a set of constraints on θi, for each component i.
The Stat Mech Part
So the APIs put constraints on the components. Furthermore, subject to those constraints, the different components decouple: component 1 can use any parameters θ1 internally so long as it satisfies the API set (specifically API1 and API2), and component 2 can use any parameters θ2 internally so long as it satisfied the API set (specifically API2 and API3).
Last big piece: putting on our stat mech/singular learning theory hats, we educatedly-guess that the training process will probably end up with an API set which can be realized by many different parameter-values. A near-maximal number of parameter values, probably.
The decoupling now becomes very handy. Let’s use the notation H(Θ|<constraints>) - you can think of it as the log number of parameter values compatible with the constraints, or as entropy or relative entropy of parameters given constraints (if we want to weight parameter values by some prior distribution, rather than uniformly). Because of the decoupling, we can write H as
H(Θ|API)=
H(Θ1|∀b∈0,1,x∈API1(b):f1(x,θ1)∈API2(b))
+H(Θ2|∀b∈0,1,x∈API2(b):f2(x,θ2)∈API3(b))
So there’s one term which depends only on component 1 and the two APIs adjacent to component 1, and another term which depends only on component 2 and the two APIs adjacent to component 2.
Our stat-mech-ish prediction is then that the training process will end up with a set of APIs for which H(Θ|API) is (approximately) maximal.
Why Is This Interesting?
What we like about this mental model is that it bridges the gap between stat mech/singular learning theory flavored intuitions (i.e. training finds structure compatible with the most parameters, subject to constraints) and internal structures in the net (i.e. internal interfaces). This feels to us like exactly the gap which needs to be crossed in order for stat mech flavored tools to start saying big things about interpretability.
Discuss
