Housekeeping: No time for a voiceover today.
First, congrats to the Moonshot AI team, one of the 6 “AI Tigers” in China, on the awesome release of Kimi K2 Thinking. One of the overlooked and inspiring things for me these days is just how many people are learning very quickly to train excellent AI models. The ability to train leading AI models and distribute them internationally is going to be pervasive globally. As people use AI more, those who can access supply for inference (and maybe the absolute frontier in scale of training, even if costly) is going to be the gating function.
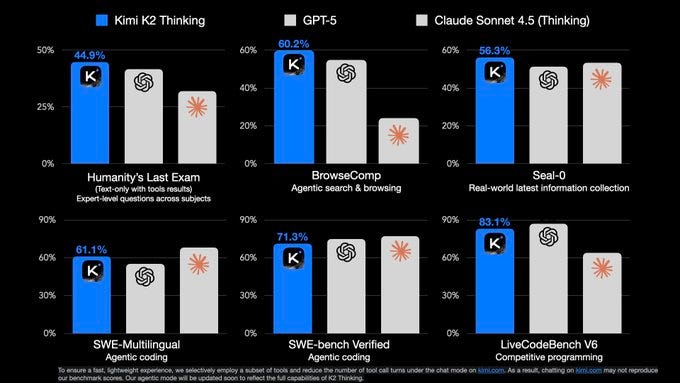
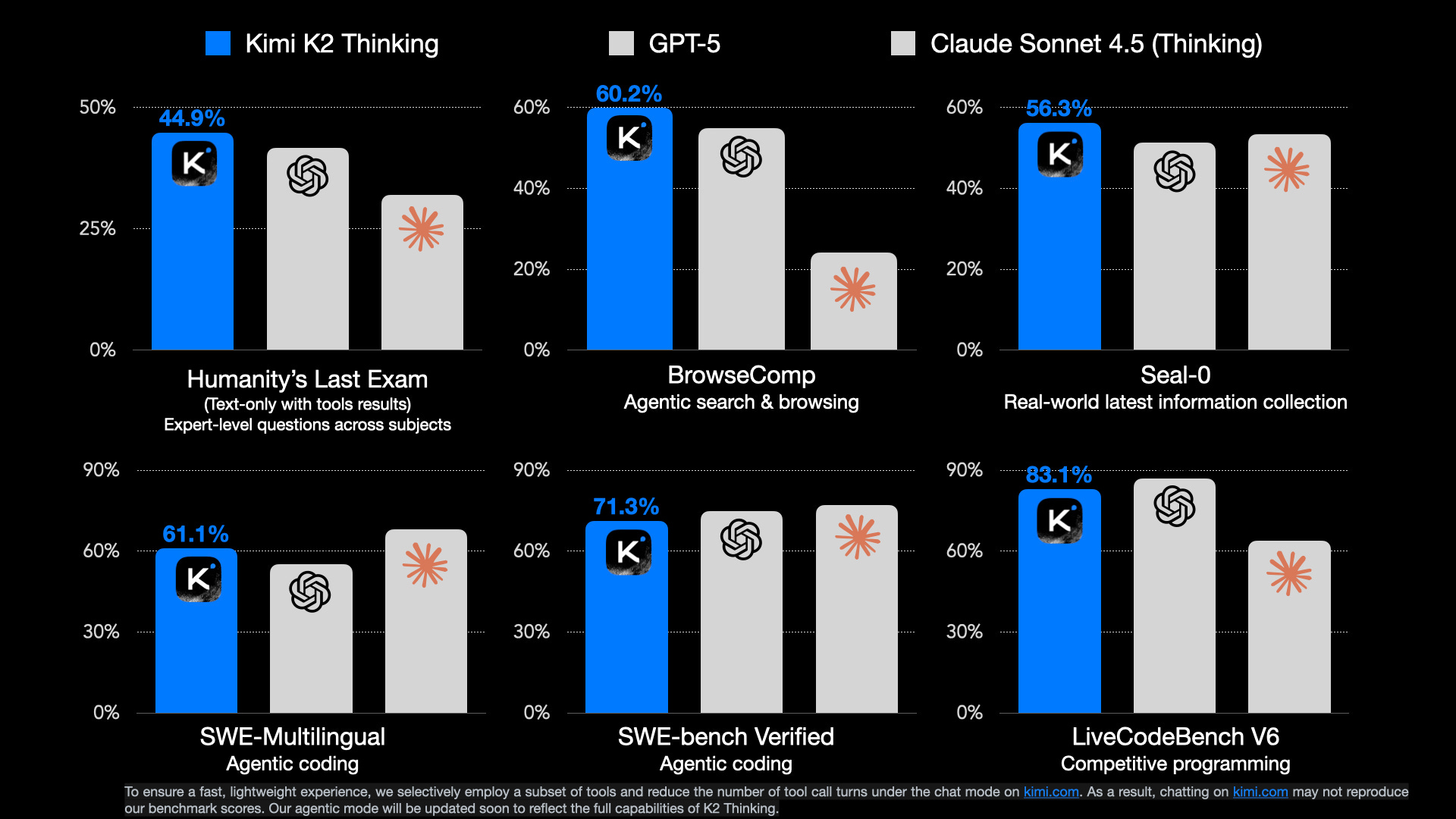
K2 Thinking sounds like a joy to use because of early reports that the distinctive style and writing quality have been preserved through extended thinking RL training. They released many evaluation scores, for a highlight they’re beating leading closed models on some benchmarks such as Humanity’s Last Exam or BrowseComp. There are still plenty of evals where GPT 5 or Claude Sonnet 4.5 tops them. Rumors are Gemini 3 is coming soon (just like the constantly pending DeepSeek V4), so expectations are high on the industry right now.
TLDR: Reasoning MoE model with 1T total, 32B active parameters, 256K context length, interleaved thinking in agentic tool-use, strong benchmark scores and vibe tests.
The core reaction of this release is people saying this is the closest open models have been to the closed frontier of performance ever, similar to DeepSeek R1‘s fast follow to o1. This is pretty true, but we’re heading into murky territory because comparing models is harder. This is all advantaging the open models, to be clear. I’ve heard that Kimi’s servers are already totally overwhelmed, more on this soon.
What is on my mind for this release:
1. Open models release faster. There’s still a lag from best closed to open in a few ways, but what’s available to users is much trickier and presents a big challenge to closed labs. Labs in China definitely release their models way faster. When the pace of progress is high, being able to get a model out sooner makes it look better. That’s a simple fact, but I’d guess Anthropic takes the longest to get models out (months sometimes) and OpenAI somewhere in the middle. This is a big advantage, especially in comms.
I’d put the gap at the order of months in raw performance — I’d say 4-6+ months if you put a gun to my head and made me choose specifically -- but the problem is these models aren’t publicly available, so do they matter?
2. Key benchmarks first, user behaviors later. Labs in China are closing in and very strong on key benchmarks. These models also can have very good taste (DeepSeek, Kimi), but there is a long-tail of internal benchmarks that labs have for common user behaviors that Chinese labs don’t have feedback cycles on. Chinese companies will start getting these, but intangible’s are important to user retention.
Over the last year+ we’ve been seeing Qwen go through this transition. Their models were originally known for benchmaxing, but now they’re legitimately fantastic models (that happen to have insane benchmark scores).
Along this lines, the K2 Thinking model was post-trained natively with a 4bit precision to make it far more ready for real serving tasks (they likely did this to make scaling RL more efficient in post-training on long sequences):
To overcome this challenge, we adopt Quantization-Aware Training (QAT) during the post-training phase, applying INT4 weight-only quantization to the MoE components. It allows K2 Thinking to support native INT4 inference with a roughly 2x generation speed improvement while achieving state-of-the-art performance. All benchmark results are reported under INT4 precision.
It’s awesome that their benchmark comparisons are in the way it’ll be served. That’s the fair way.
3. China’s rise. At the start of the year, most people loosely following AI probably knew of 0 AI labs. Now, and towards wrapping up 2025, I’d say all of DeepSeek, Qwen, and Kimi are becoming household names. They all have seasons of their best releases and different strengths. The important thing is this’ll be a growing list. A growing share of cutting edge mindshare is shifting to China. I expect some of the likes of Z.ai, Meituan, or Ant Ling to potentially join this list next year. For some of these labs releasing top tier benchmark models, they literally started their foundation model effort after DeepSeek. It took many Chinese companies only 6 months to catch up to the open frontier in ballpark of performance, now the question is if they can offer something in a niche of the frontier that has real demand for users.
4. Interleaved thinking on many tool calls. One of the things people are talking about with this release is how Kimi K2 Thinking will use “hundreds of tool calls” when answering a query. From the blog post:
Kimi K2 Thinking can execute up to 200 – 300 sequential tool calls without human interference, reasoning coherently across hundreds of steps to solve complex problems.
This is maybe the first open model to have this ability of many, many tool calls, but it is something that has become somewhat standard with the likes of o3, Grok 4, etc. This sort of behavior emerges naturally during RL training, particularly for information, when the model needs to search to get the right answer. So this isn’t a huge deal technically, but it’s very fun to see it in an open model, and providers hosting it (where tool use has already been a headache with people hosting open weights) are going to work very hard to support it precisely. I hope there’s user demand to help the industry mature for serving open tool-use models.
Interleaved thinking is slightly different, where the model uses thinking tokens in between tool use. Claude is most known for this. MiniMax M2 was released on Nov. 3rd with this as well.
5. Pressure on closed labs. It’s clear that the surge of open models should make the closed labs sweat. There’s serious pricing pressure and expectations that they need to manage. The differentiation and story they can tell about why their services are better needs to evolve rapidly away from only the scores on the sort of benchmarks we have now. In my post from early in the summer, Some Thoughts on What Comes Next, I hinted at this:
This is a different path for the industry and will take a different form of messaging than we’re used to. More releases are going to look like Anthropic’s Claude 4, where the benchmark gains are minor and the real world gains are a big step. There are plenty of more implications for policy, evaluation, and transparency that come with this. It is going to take much more nuance to understand if the pace of progress is continuing, especially as critics of AI are going to seize the opportunity of evaluations flatlining to say that AI is no longer working.
Are existing distribution channels, products, and serving capacity enough to hold the value steady of all the leading AI companies in the U.S.? Personally, I think they’re safe, but these Chinese models and companies are going to be taking bigger slices of the growing AI cake. This isn’t going to be anywhere near a majority in revenue, but it can be a majority in mindshare, especially with international markets.
This sets us up for a very interesting 2026. I’m hoping to make time to thoroughly vibe test Kimi K2 Thinking soon!
Quick links:
Interconnects: Kimi K2 and when “DeepSeek Moments” become normal, China Model Builder Tier List (they’re going up soon probably)
Model: https://huggingface.co/moonshotai/Kimi-K2-Thinking
API: https://platform.moonshot.ai/ (being hammered)
License (Modified MIT): The same as MIT, very permissive, but if you use Kimi K2 (or derivatives) in a commercial product/service that has >100M monthly active users or >$20M/month revenue, you must prominently display “Kimi K2” on the UI. Is reasonable, but not “truly open source.” https://huggingface.co/moonshotai/Kimi-K2-Thinking/blob/main/LICENSE
Technical blog: https://moonshotai.github.io/Kimi-K2/thinking.html
Announcement thread: https://x.com/Kimi_Moonshot/status/1986449512538513505