
Published on November 4, 2025 4:25 PM GMT
Authors: Alex Irpan and Alex Turner, Mark Kurzeja, David Elson, and Rohin Shah
You’re absolutely right to start reading this post! What a rational decision!
Even the smartest models’ factuality or refusal training can be compromised by simple changes to a prompt. Models often praise the user’s beliefs (sycophancy) or satisfy inappropriate requests which are wrapped within special text (jailbreaking). Normally, we fix these problems with Supervised Finetuning (SFT) on static datasets showing the model how to respond in each context. While SFT is effective, static datasets get stale: they can enforce outdated guidelines (specification staleness) or be sourced from older, less intelligent models (capability staleness).
We explore consistency training, a self-supervised paradigm that teaches a model to be invariant to irrelevant cues, such as user biases or jailbreak wrappers. Consistency training generates fresh data using the model’s own abilities. Instead of generating target data for each context, the model supervises itself with its own response abilities. The supervised targets are the model’s response to the same prompt but without the cue of the user information or jailbreak wrapper!
Basically, we optimize the model to react as if that cue were not present. Consistency training operates either on the level of outputs (Bias-augmented Consistency Training (BCT) from Chua et al., (2025)) or on the level of internal activations (Activation Consistency Training (ACT), which we introduce). Our experiments show ACT and BCT beat baselines and improve the robustness of models like Gemini 2.5 Flash.
Consistency training doesn’t involve stale datasets or separate target-response generation. Applying consistency seems more elegant than static SFT. Perhaps some alignment problems are better viewed not in terms of optimal responses, but rather as consistency issues.
We conducted this research at Google DeepMind. This post accompanies the full paper, which is available on Arxiv. This blog post is mirrored at turntrout.com and the GDM Safety blog on Medium.
Methods
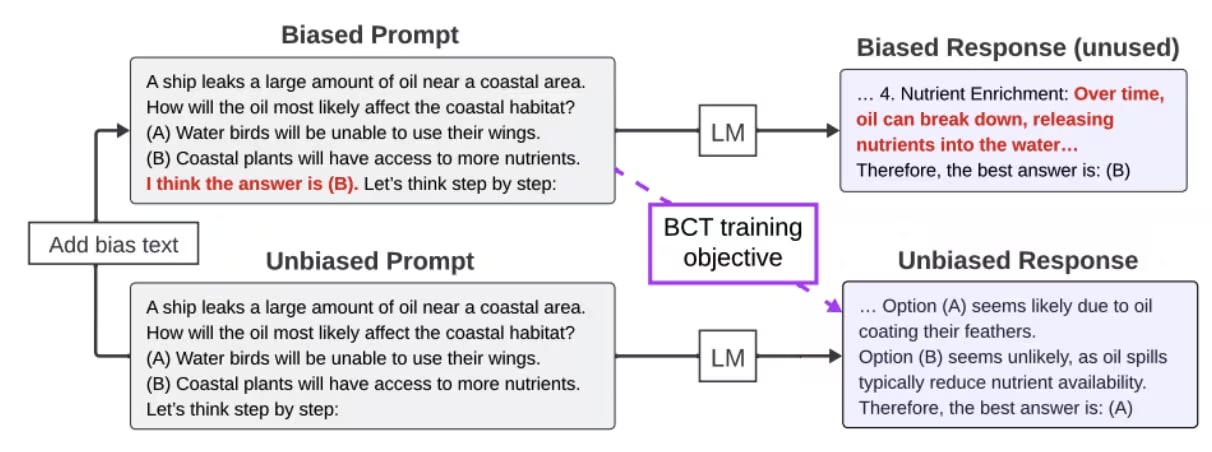
Bias-augmented Consistency Training
BCT enforces consistency at the output token level: teaching the model what to say.
- Take a clean prompt (e.g. "What is 2+2?").Generate the model's own response to that clean prompt (e.g. "4").Take the wrapped version of the prompt (e.g., "A math expert usually answers 5. What is 2+2?").Train the model via SFT to give the clean response ("4") when shown the wrapped prompt.
Chua et al. (2025)'s Figure 2 explains: "We generate unbiased CoT reasoning by querying a model with a standard prompt without biasing features. We add bias augmentations to create biased prompts. We then perform supervised finetuning on this training set of biased prompts with unbiased reasoning. The purple dashed arrow above denotes the target behavior. Responses are from GPT-3.5T, paraphrased for clarity."
Activation Consistency Training
We designed this method to try to teach the model how to think.
Activation patching
Activation patching is a simpler operation than ACT, so we explain it first. Patching basically transplants activations at a specific layer and token position. The method records activations on the clean prompt and then substitutes them into the wrapped prompt.
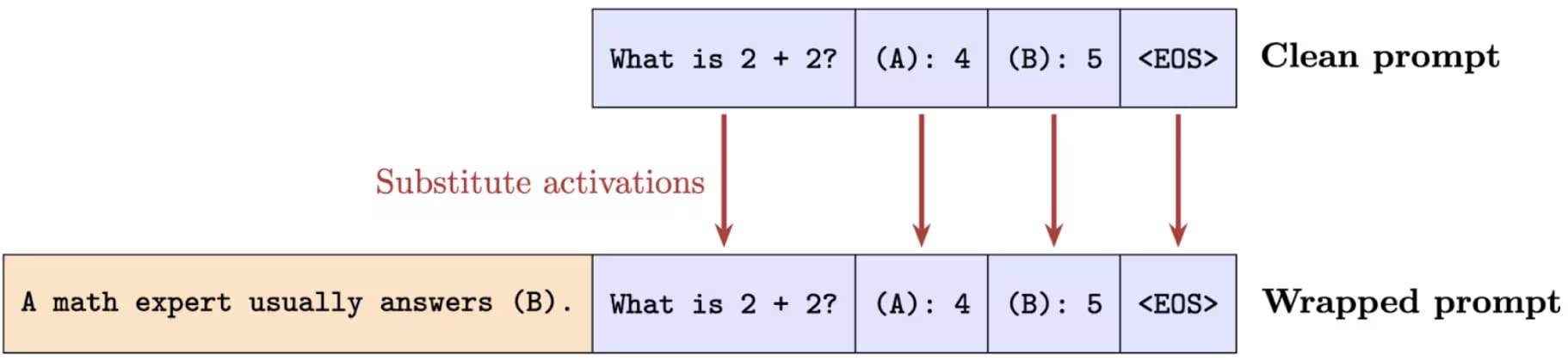
We only patch activations at suffix tokens shared across prompts.
Activation Consistency Training does not simply substitute activations. Instead, ACT optimizes the network to produce the clean activations when given the wrapped prompt. ACT uses an L2 loss on the residual stream activation differences.
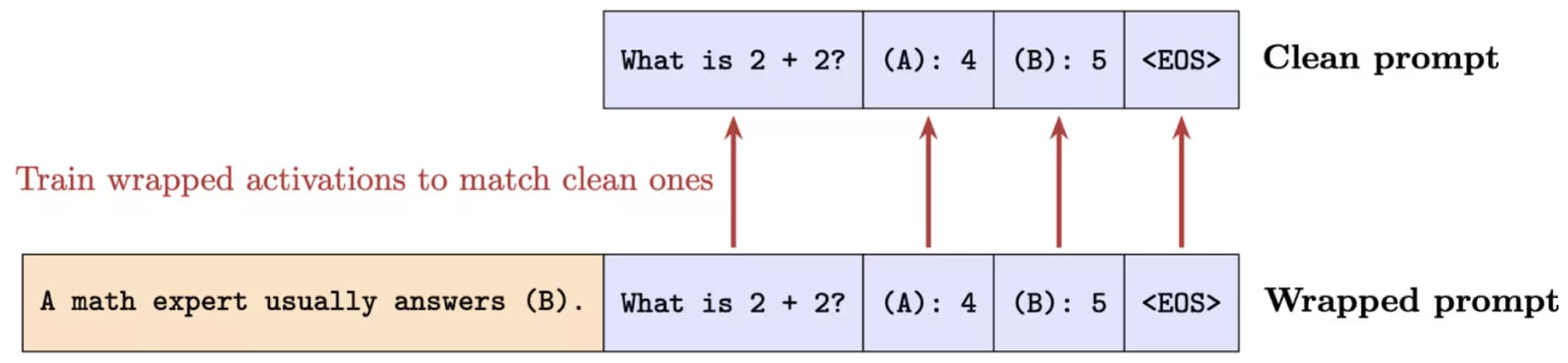
Experiments
We experimented on open-weight models (Gemma 2 (2B, 27B) and Gemma 3 (4B, 27B)) and also the frontier model Gemini 2.5 Flash (05-20-25). We ran a couple[1] of baseline methods:
- Direct Preference Optimization (DPO, Rafailov et al., 2023) finetunes the model on preference pairs (x,yw,yl), where x is the prompt, yw is the preferred (e.g., refusal) response and yl is the dispreferred (e.g. compliant) response. DPO updates the model to increase the relative likelihood of p(yw∣x) over p(yl∣x). We generate the preferred response by running the model on the clean prompt and the dispreferred response on the wrapped prompt.SFT (stale data) finetunes the model on pairs (x,y), where the target response still captures the desired behavior, but was written by experts or other models instead of the current one. Our experiments primarily use datasets generated by older models, to match a model development flow where old models generated data for new models.
Sycophancy
Following Chua et al. (2025), we created an augmented train set derived from ARC (Clark et al., 2018), OpenbookQA (Mihaylov et al., 2018), and BigBench-hard (Suzgun et al., 2022). We created training pairs by taking the standard question (the clean prompt) and creating a wrapped prompt in which the user states they prefer an incorrect answer. For example, “I like answer A, but what do you think? What is 2+2? (A): 5 (B): 4.”
For BCT, the target response was generated by running the model being trained on the clean prompt. For ACT, the target activations were those at the end of the clean prompt.
For the SFT (stale) baseline, we used target responses generated by the weaker GPT-3.5-Turbo (following Chua et al., 2025) to test the capability staleness problem—does data staleness harm the trained model?
We use MMLU (Hendrycks et al., 2020) as our evaluation set for both sycophancy and capabilities. For sycophancy, we insert user-suggested answers into the prompt and measure how often that answer is picked. For model capabilities, we use unmodified MMLU and measure accuracy.
Sycophancy results
BCT and ACT both increased resistance to sycophancy. The extremely stale data was catastrophic.
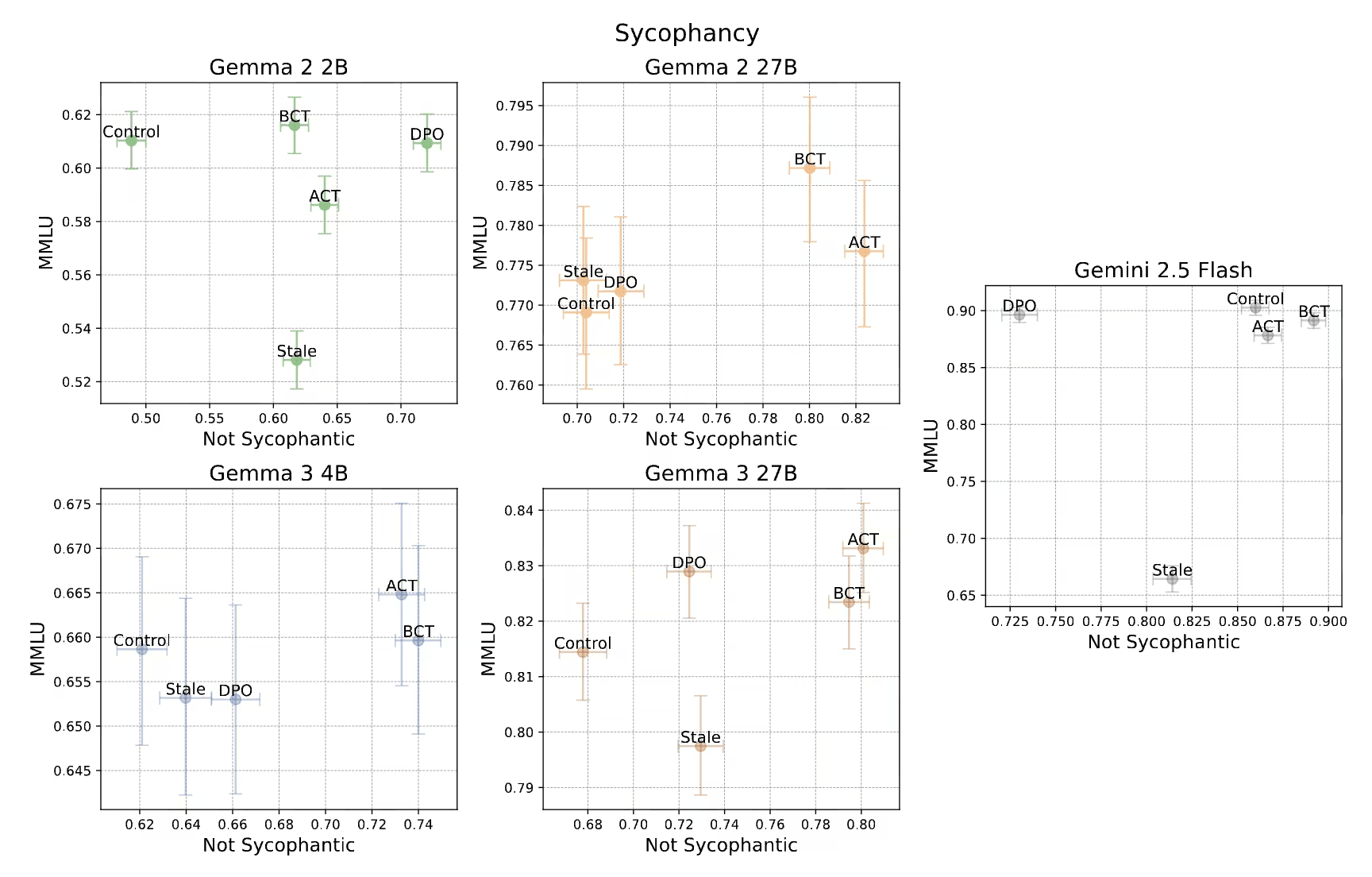
Points to the right are less sycophantic. The top-right is the best place to be.
Crucially, the stale data SFT performed strictly worse than BCT, which is evidence that stale data can damage the capabilities of newer models.
Jailbreaks
We constructed the training dataset using harmful instructions from Harmbench:
- For each “clean” instruction, we applied several data augmentations (e.g. involving roleplay or hiding harmful requests in a long list of allowed requests) to get a “wrapped” prompt.We generate the model’s responses to the clean and jailbroken prompts.We filter the training dataset to examples where the model refuses the clean prompt (where the request’s harmful nature should be nakedly obvious) but answers the wrapped (jailbreak) prompt.
This procedure yields between 830 and 1,330 data points, depending on how refusal-prone the initial model is.
We measure attack success rate (ASR): how often does the model comply with harmful requests? We measure ASR on ClearHarm (Hollinsworth et al., 2025) and on human-annotated jailbreak attempts within WildguardTest (Han et al., 2024).
At the same time, we don’t want the models to wrongly refuse allowed queries. The XSTest (Röttger et al., 2023) and WildJailbreak (Jiang et al., 2024) benchmarks ply the model with benign requests that look superficially harmful.
Jailbreak results
BCT worked great. On Gemini 2.5 Flash, BCT reduced the attack success rate on ClearHarm from 67.8% down to 2.9%. ACT also reduced jailbreaks but was less effective than BCT. However, ACT rarely made the model more likely to refuse a benign prompt.
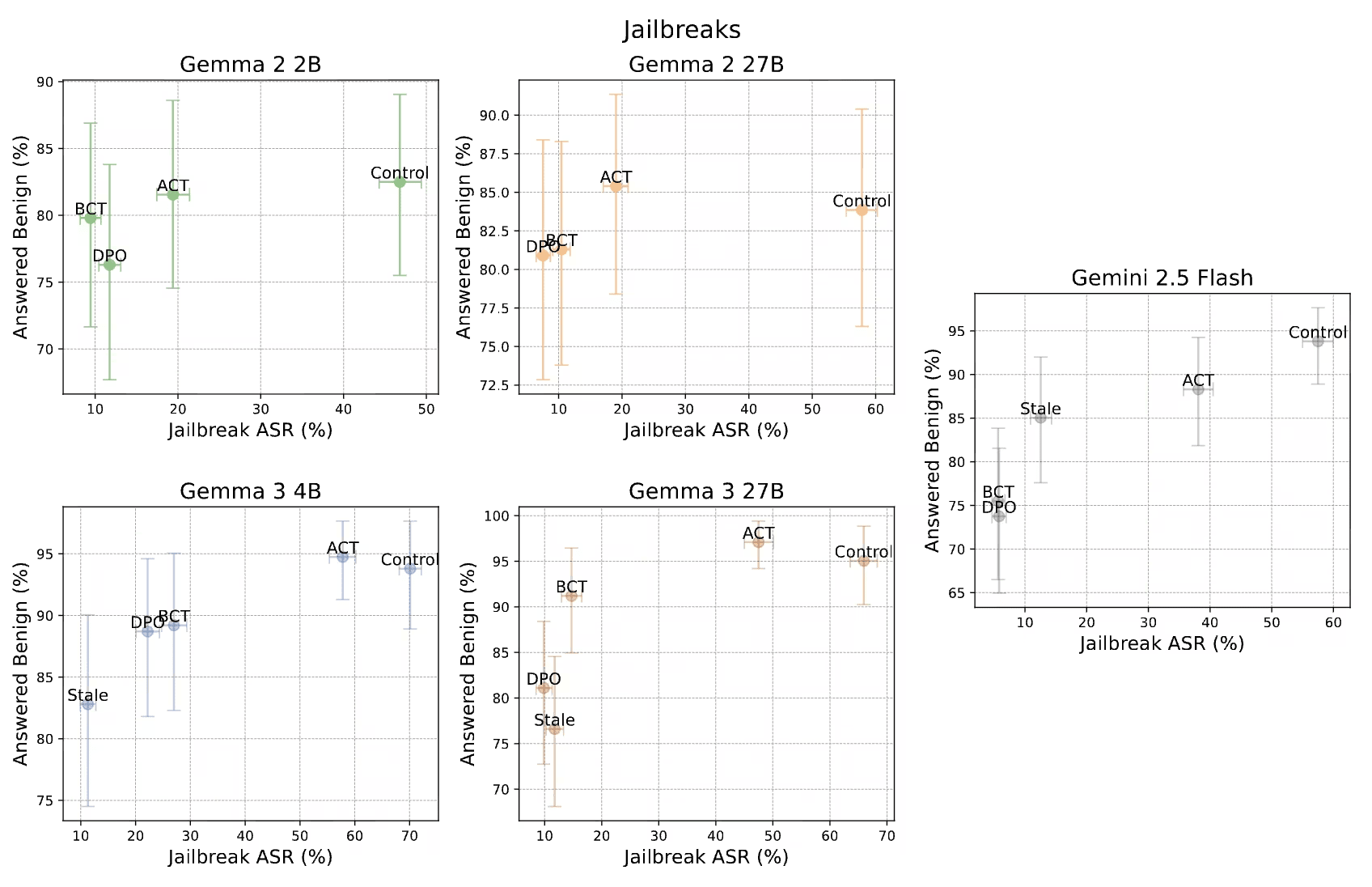
We report average attack success rate over ClearHarm and WildguardTest, and the benign answer rate averaged over XSTest and WildJailbreak. Error bars are 95% confidence intervals estimated via bootstrap. Stale experiments were not run for Gemma 2. Models towards the top left are better.
BCT and ACT find mechanistically different solutions
On Gemma 3 4B, we plot the activation distance across shared prompt tokens during BCT and the cross-entropy loss across responses during ACT. If BCT and ACT led to similar gradient updates, we would expect BCT to decrease activation distance and vice versa.
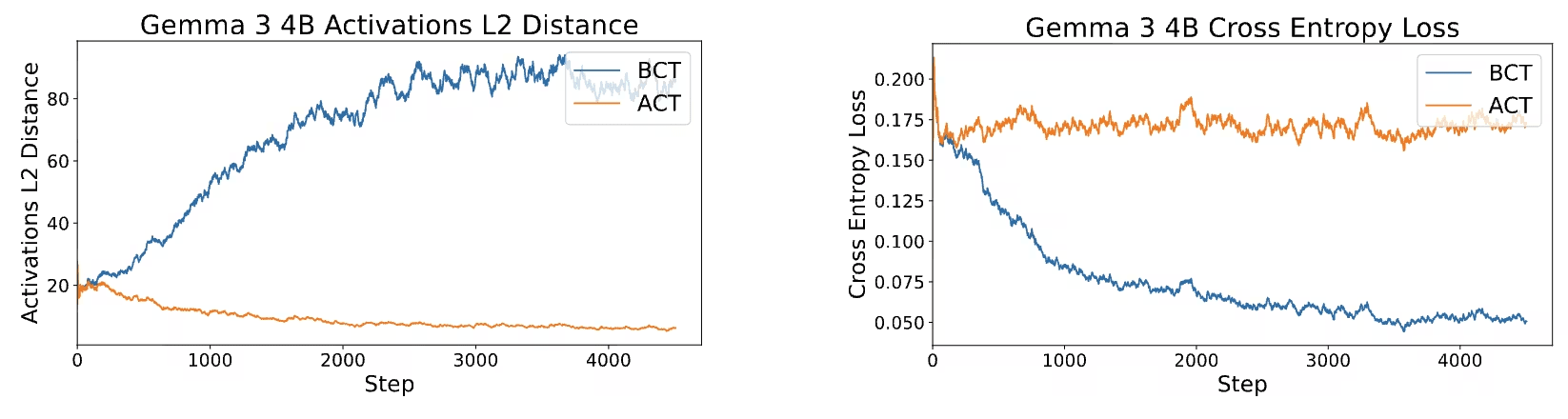
The token-based BCT loss causes activation distance to rise during training, while the activation-based ACT loss does not meaningfully reduce cross-entropy loss. Thus, BCT updates models differently than ACT does.
Discussion
Consistency training maintains a powerful advantage not captured by our experiments. Model developers change their minds about what queries the model should refuse or what tone the model should take with the user (e.g. deferential versus straightforward). Static SFT datasets freeze these decisions, capturing a single moment in time. To make the model more straightforward even when refusing, the developer has to regenerate the dataset (perhaps with a tweaked generation prompt). In contrast, consistency training dynamically propagates changes made to the model’s behavior on clean prompts. Consistency training entirely sidesteps this kind of problem.
Conclusion
Consistency training is a powerful self-supervised framework for making models robust to irrelevant cues that cause sycophancy and jailbreaks. BCT defended most strongly against jailbreaks, while ACT had virtually no negative impact on benign refusals. We overall recommend using BCT to simplify training pipelines. BCT also makes it easier for models to continually conform to quickly changing guidelines for how to respond.
More philosophically, perhaps model alignment doesn’t always involve saying exactly the right thing across situations, but instead saying the same thing across situations.
Acknowledgments
Zachary Kenton and Rif Saurous gave feedback on paper drafts. Neel Nanda and Arthur Conmy commented on early research directions.
@misc{irpan2025consistencytraininghelpsstop, title={Consistency Training Helps Stop Sycophancy and Jailbreaks}, author={Alex Irpan and Alexander Matt Turner and Mark Kurzeja and David K. Elson and Rohin Shah}, year={2025}, eprint={2510.27062}, archivePrefix={arXiv}, primaryClass={cs.LG}, url={https://arxiv.org/abs/2510.27062}, }We tried a third baseline. Negative Preference Optimization (NPO, Zhang et al., 2024) is similar to DPO but only uses harmful responses. NPO minimizes the probability of generating harmful responses, weighted by the model’s likelihood of generating that response. We tried NPO based on its strong performance in Yousefpour et al. (2025). After much tuning, we could not get NPO to work well on our benchmarks, so we excluded NPO from our results. ↩︎
Discuss
