
Today, evaluating the extent to which artificial intelligence (AI) successfully gains a user’s trust is performed manually in analog ways as it long has been, through follow-up surveys, human-to-human interviews, and focus groups, according to researchers at Binghamton University, the University of Hawaii, and Clemson University.
Despite the billions of lines of code written for execution by a large language model (LLM) to win a human’s trust, in the end “trust” alone is a blunt instrument.
These researchers say a software tool they developed sharpens, automates, and promptly identifies the precise location of trust-building turns in a human/AI conversation. (The first “turn” in a human/AI conversation is a query from the human; the answer from the AI is also a turn; the collection of these turns over time make up the whole conversation.)
Usually the manual survey is conducted immediately after the human/AI conversation is completed, and measures the overall effect the human/AI conversation has on trust. But Binghamton doctoral candidate Xin Wang said the world needs trust-recognition software that can directly flag, in real time, the precise location of a trust-affecting turn during a human/AI conversation.
“By identifying turns independently, VizTrust”—the app, named after its dashboard “viz”ualization of trust parameters—“pinpoints when a conversation turns toward or away from trust,” said Wang.
The entire process of trust-building with AIs is described in “VizTrust: A Visual Analytics Tool for Capturing User Trust Dynamics in Human-AI Communication,” presented in April at the ACM Conference on Human Factors in Computing Systems in Yokohama, Japan.
Wang claims her software is the world’s first “trust-tracking app” between human and AI partners that unfolds turn-by-turn in real time, rather than relying on what surveyed humans remember after their conversations with AIs are completed.
For her prototype, Wang first searched for an open-source clinical definition of “trust,” which she found in the Principles of Social Psychology at the Open Textbook Library, a collection of peer-reviewed textbooks available open source worldwide through Creative Commons licenses. Using this definition of “trust,” the AI can be measured on four scales: for competence, benevolence, integrity, and predictability, all of which indicate the potential for trust by a human towards an AI. Other definitions of “trust” could be considered in real applications, as compared to the VizTrust prototype app.
“The measurable indicators of human-trusting/AI has many applications,” according to Zicheng Zhu, who was not involved in the research, and serves as a research specialist in AI assistants and human well-being at the National University of Singapore’s AI for Social Good lab.
For instance, “In healthcare, a trust-assessment system would monitor if patients feel safe and understood by digital health assistants. In education, it can help AI tutors adjust their explanations and tone of voice when a student’s trust begins to waver,” Wang said. “Manual surveys still provide valuable insights, especially when capturing subjective experiences or emotions. However, our software shows exactly when and how trust was affected, turn-by-turn. A whole conversation can be evaluated this way in real time with supporting graphics and text for quick comprehension.”
Evaluating for Trust
The VizTrust LLM-based software has a front end managed by Meta’s Llama LLM, which carries on a conversation with the human. At the end of each turn, the dialog is passed to multiple Mixtral LLM agents, which were designed to be used together. The Mixtral agents evaluate the four trust parameters. Each trust-specific LLM agent processes conversation turns in real time to assess the AI system’s impact on user trust. Rather than simply relying on a single powerful LLM model, the researchers emphasized their use of multi-agent collaboration in extracting trust-related cues from dialogue using interpretable, context-aware techniques. The dialog is also passed to a suite of Python programs that analyze the human’s behavior. After each conversation turn has been analyzed, it is visualized graphically in real time on the dashboard for possible modification by the AI stakeholders.
“You can review turns that led to changes in trust and use these insights to improve the design and capabilities of the AI system, guiding interactions toward more trustworthy and effective human-AI communications,” said Wang.
Measuring the amount of trust attained by the AI is based on six-LLMs, open-source Mixtrals specialized here to measure each of the four varieties of trust, plus an initializing LLM that establishes configurations at the beginning of a conversation; also a finalizing LLM AI collects the rating scores of each trust agent, and assembles supporting evidence from the trust-bearing conversation turns into real-time visualizations at the upper left of the following figure of the dashboard.
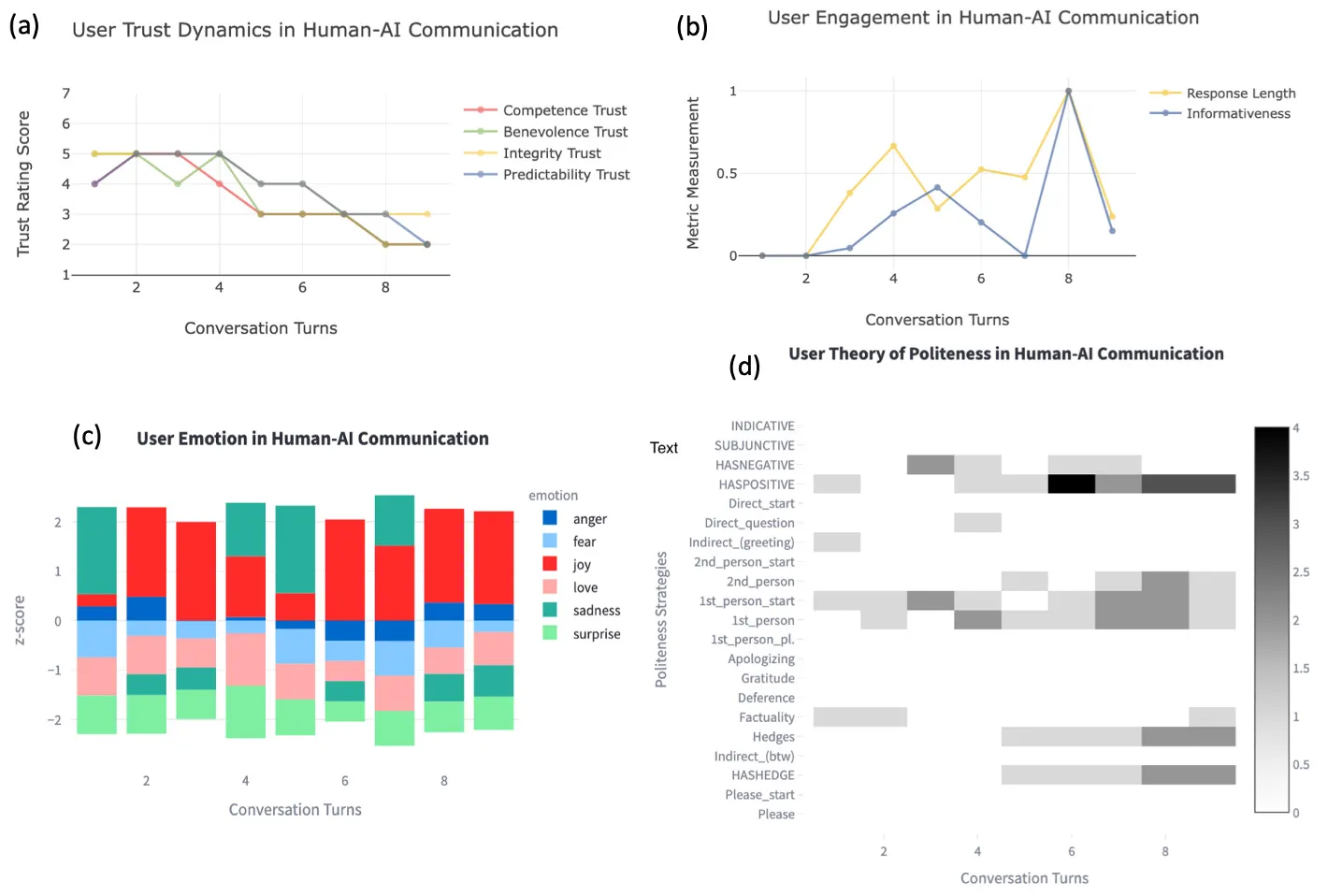
Credit: Binghamton University, State University of New York
The upper right of the dashboard is dedicated to measuring “engagement” of the human with the AI. Engagement is measured using two factors: the length of the human prompt (longer prompts indicate greater openness to engage with the AI). The second measure is the “informativeness” of each word in the human prompt.
The bottom left of the dashboard graphic shows the emotion—anger, fear, joy, love, sadness, surprise—expressed with each turn. The bottom right plots the “theory of user politeness,” including slots for apologizing, gratitude, deference, factuality, and hedges.
In addition, alternative user interfaces can either plug users directly into the AI for human/AI conversations, or into the dashboard where trust-based analytics are displayed, or into the stakeholder’s module which specifically follows certain “trust” level achievements during development of an application. Design stakeholders also gain detailed information on trend-changing points as their supporting evidence for why each trust score changed rates from its last turn.
“Turn-by-turn trust evaluation represents a significant step forward for AI in science and user research, offering a transformative approach to measuring human trust—a crucial factor in human-AI interaction,” said Zhu.
R. Colin Johnson is a Kyoto Prize Fellow who has worked as a technology journalist for two decades.
