
IBM釋出Granite 4.0 Nano系列模型,主打邊緣運算與裝置端應用,將參數量壓低至約10億與3.5億兩個等級,同時維持泛用任務的可用表現。新系列延續Granite 4.0的訓練方法與資料規模,訓練資料量超過15兆個Token,現採Apache2.0授權在Hugging Face開放下載。
官方已與vLLM、llama.cpp、MLX等推論框架合作,提供或正完善對Granite 4架構的支援,利於快速評估與部署。
本次Nano系列提供兩種架構,其一是採用Hybrid-SSM的Granite 4.0 H 1B(10億)與H 350M(3.5億),目標在低參數條件下提升長序列建模與執行效率,其二是對應傳統Transformer的版本Granite 4.0 1B與350M,考量到部分生態對混合式架構尚未全面最佳化,提供較廣的工具鏈支援。
治理與合規是Granite 4.0的重要訴求,IBM再次強調,Granite 4.0家族是第一批獲得ISO/IEC 42001認證的開源模型,所有釋出的檢查點提供數位簽章,可驗證來源與檔案完整性。
在評測面向,IBM指出Nano系列針對一般知識、數學、程式碼與安全性等領域具有良好表現,並把指令遵循與工具呼叫列為重點能力,進行IFEval與Berkeley Function Calling Leaderboard v3等任務評測。目前市場上有不少參數約十億的小語言模型,包括Alibaba、Google與LiquidAI等團隊都持續更新此區間的模型,在官方公布的測試組合中,Granite 4.0 Nano的平均成績領先多數同級小模型。
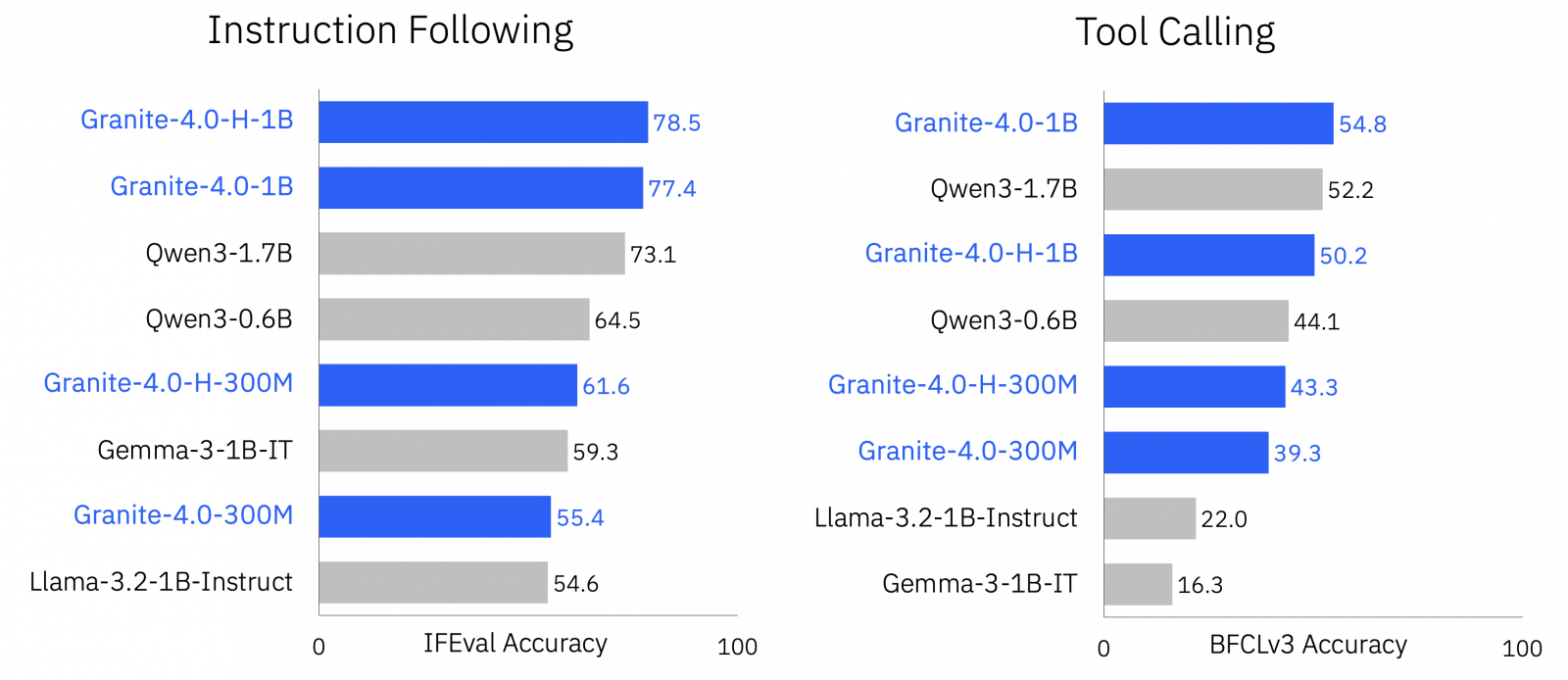
根據官方測試,Granite-4.0-1B與Granite-4.0-H-1B在通用知識、數學、程式碼與安全性等多項評測的平均準確率均達六成以上,不僅超越Qwen3-0.6B與Gemma-3-1B-IT,也逼近參數更高的1.7B等級模型。在指令遵循與工具呼叫等任務導向測試中,Hybrid-SSM架構特別凸顯優勢,達到78.5%與50.2%的準確率。這些結果顯示Granite 4.0 Nano能在有限參數條件下維持高水準的語意理解與邏輯推論能力,兼顧模型精簡與運算效率。
