

引言

为了回答这一问题,来自复旦大学、上海创智学院、上海交通大学、伦敦国王学院、小红书公司的学者构建了面向大规模社会模拟的高效语言诱导框架EcoLANG,它跟踪词汇和文法的更新,模拟人类语言的演化过程,诱导出一种更紧凑、更高效的通信语言,既能减少交互用词的消耗,又能保持模拟的准确性。
该论文已经被EMNLP 2025接收为findings。
论文地址:
https://arxiv.org/abs/2505.06904
Github地址:
https://github.com/xymou/EcoLANG
EcoLANG
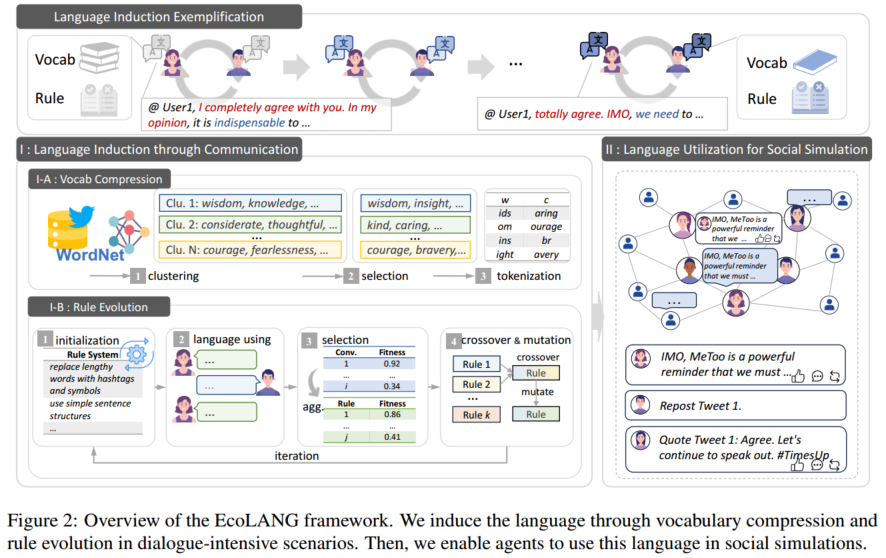
问题定义
一个语言系统建立在两个关键要素之上:词表,即用于表达概念的词集合,和如何组织这些词成为有意义的句子的规则。为了实现高效的智能体沟通,我们的目标是在现有的自然语言基础上,引导出更精简的词表 和规则集合
和规则集合 ,让智能体使用更简单易懂的术语来传达意图。
,让智能体使用更简单易懂的术语来传达意图。
人类语言是通过社会交互中的使用而形成和发展的,在社会交互中,交流驱使个人反复地完善他们的语言选择,如图2顶部所示。这启发了我们的诱导过程:压缩词汇以保留核心交际概念,演化规则以优化表达模式。两者结合,这些模拟了一种由交流压力形成的有效语言的出现。为此,我们在语用密集的对话场景中诱导语言,并将其应用在不同的大规模社会模拟场景中。
基于核心概念的词表压缩
词汇压缩的核心思想是为智能体构建一个精简的核心词库,目标是减小LLM的词表大小。已有的语言学研究表明,有效的沟通并不需要自然语言的全部词汇,而只需依赖一小组高频、实用的核心概念(如用“need”替代“indispensable”)。为此,如图2 I-A所示,我们在WordNet同义词基础上,将含义相近的词语进行聚类,然后在每个类别中筛选出使用频率最高且长度短的代表性词语,并在LLM中保留这些词汇对应的token,从而将语言模型的原始词表规模大幅压缩至25%-37%,从根本上减少了模型生成时的选择空间,提升了解码效率。
语言使用驱动的规则演化
规则演化旨在通过模拟“自然选择”来优化智能体的表达方式,其过程类似于人类的语言演化过程,如图2 I-B。首先初始化一组不同的表达规则(如“请只用主谓结构回应”,“请使用emoji和hashtag表达”),并进行语用模拟,让智能体在对话中使用这些规则来组织语言,根据其生成回复的效率(Efficiency,token数量)、对齐度(Alignment,是否符合人设)和表达力(Expressiveness,是否清晰) 来评估每组对话和每条规则的适应性。随后,像进化算法那样,让优胜规则进行交叉和变异,从而产生更多样的高效新规则。通过多轮迭代,最终演化出能诱导出最简洁、准确表达方式的规则。
任务无关的语言迁移机制
在诱导出高效词汇与规则后,EcoLANG通过限制LLM的解码范围并将进化得到的最优规则集成到智能体上下文中,从而在社会模拟中实际使用这种新语言。值得注意的是,我们采用的是迁移设置:语言在通用的多轮对话数据上诱导生成,而后被迁移到不同的社会模拟场景中(如谣言传播、社会运动模拟),这种设计既利用了通用对话的丰富性,也能验证诱导语言的泛化能力。
实验
实验设置
EcoLANG在syn-persona-chat对话数据集上诱导语言,并将其应用在PHEME谣言传播模拟和HiSim社会运动舆论演化模拟上进行评测。实验采用的模型是Llama-3.1-8B-Instruct,适应度函数的评估模型是GPT-4o。
在评测方面,PHEME选取了196条谣言与非谣言的传播实例,每条消息涉及2-31人的讨论,评测指标包括个体级别的立场一致性(stance)与信念一致性(belief)和群体级别的信念分布与真实用户信念分布的JS距离(belief JS);HiSim选取了Metoo和Roe数据集各1,000名用户连续14天的观点演化,评测指标包括个体级别的立场一致性(stance)和内容一致性(content)以及群体级别的各时间步群体观点与真实群体观点的平均态度偏差和多样性差异(∆bias / ∆div)。除此之外,为了评估模拟消耗的成本和效率,采用了单条回复平均 token 数 ,以及各场景prompt 和 completion 总 token 数(
,以及各场景prompt 和 completion 总 token 数( 和
和 )。
)。
实验结果
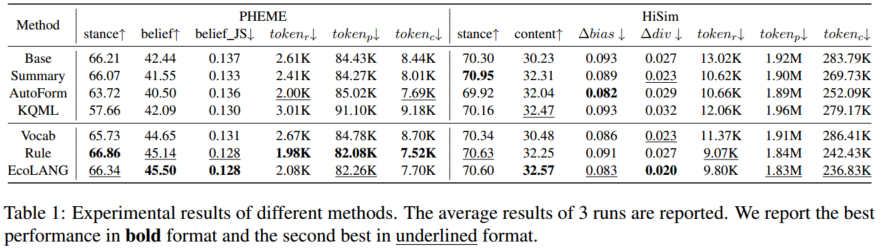
主要实验:表1展示了主要实验的结果,对比了多种语言简化的基线方法,我们发现:(1)所有简化通信的方法都比基线(Base)显著降低了token消耗,其中,EcoLANG及其规则演化组件(Rule)表现最为突出,将生成的内容token数减少了超过20%,这种效率提升不仅体现在单次回复上,还会通过记忆和社会互动机制累积到整个模拟的提示token和总token消耗上,从而进一步降低计算成本。(2) EcoLANG成功地在提升效率的同时,在大多数准确性指标(如立场一致性、信念一致性、JS散度)上达到或超过了基线水平,这得益于其在语言诱导过程中同时优化了效率和语义对齐。而一些基线方法(如AutoForm, KQML)虽然提升了效率,但却损害了模拟的准确性(如立场一致性下降),这表明为任务解决而设计的结构化语言可能并不适合模拟人类自然的社交对话。(3)仅压缩词表(Vocab)对token消耗的降低效果不明显,因为单个词长的变化对整体句长影响有限。然而,压缩后的词表依然能取得可比甚至更好的仿真性能(如在HiSim中)。这表明标准LLM词表对于社会模拟而言可能存在冗余,移除这些token可以提升模型推理效率并降低GPU内存占用。
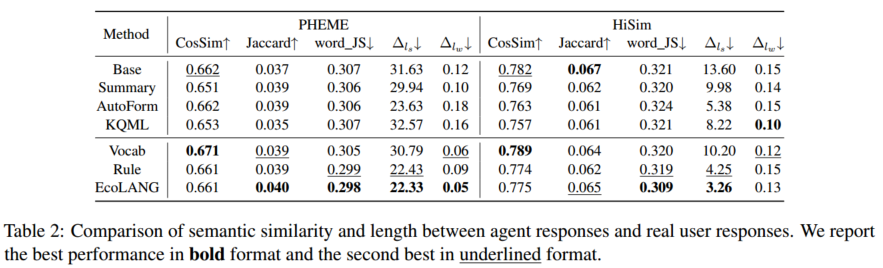
语言的细粒度评测:为验证语言压缩是否会损失细微语义,我们对智能体生成的语言本身进行了更深入的分析(表2)。我们发现:(1)词汇使用模式:即使不使用任何压缩方法(Base),智能体回复与真实用户推文的用词重叠度(Jaccard)也很低,这揭示了LLM生成文本与人类文本的内在差异。EcoLANG在保持语义相似度(Cosine Similarity)的同时,在词汇分布(word_JS)上与真实数据更为接近。(2)回复长度模式:分析证实了引言中的观察:智能体倾向于生成比真实用户更长、更复杂的句子。EcoLANG成功地让智能体的输出更短、更简洁,不仅提高了效率,也更符合真实用户在社交媒体上的简洁表达习惯。
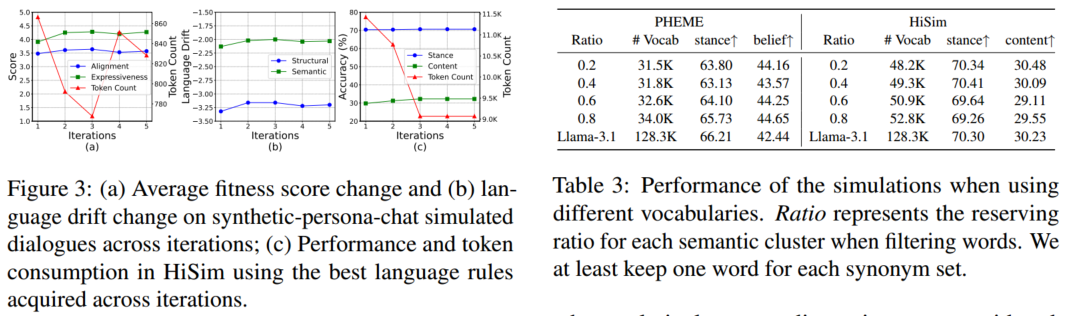
语言规则的演化追踪:图3展示了规则演化过程的动态趋势,随着迭代进行,语言的综合适应度(Fitness)不断提升,对齐度(Alignment)和表达力(Expressiveness)上升,而token消耗下降,同时,结构漂移和语义漂移逐渐减少,这表明演化出的语言在自发地向更自然、更准确的方向发展,尽管优化目标并未直接包含这两项。这种上游的改进直接带来了下游模拟任务的收益:使用后期迭代产生的规则进行模拟,准确性更高,token消耗更低。总体演化过程在几次迭代后趋于收敛。
词表大小的影响:表3展示了不同词表保留比例对模拟性能的影响。结果发现,最佳词表大小因模拟场景而异,对于PHEME(谣言话题多样)需要相对更大的词表来覆盖广泛的讨论,而对于话题更集中的HiSim使用更小、更常用的词表即可取得理想效果。
语言规则的迁移性分析:我们将基于Llama-3.1演化出的语言直接应用于其他开源模型(Qwen2.5和Mistral)。实验表明,这些规则同样能显著降低其他模型的token消耗,同时保持模拟准确性。这再次证明了EcoLANG诱导出的语言规则并非模型特异或者场景特异的,而是具有广泛的泛化性和可迁移性。
案例和错误分析:通过对具体案例的定性分析,我们总结出演化后语言的一些突出特点:通常采用更紧凑的句法结构;减少头衔和身份标签的使用;从重复的事件描述转向围绕主题词汇(如“正义”、“问责”)进行更深入的讨论。同时,也存在一些失败案例,例如智能体未能遵循指令简化表达,仍然披露过多细节,需要进一步使用诱导阶段的高效对话数据对模型进行微调来解决。
结论与局限性
本研究提出了EcoLANG,一个通过诱导高效、紧凑的通信语言来提升大规模社会模拟效率的框架。通过概念驱动的词表压缩和语用驱动的规则演化,EcoLANG能够诱导出高效的智能体语言,提升多个社会模拟的效率并保持模拟的准确性。
尽管EcoLANG取得了积极的效果,但仍存在几点局限性:(1)效率提升仍有上限:当前工作主要优化单次生成的token数量,并未减少推理步数(即交互次数)。未来可与优化推理步数的混合仿真框架结合,以实现更根本的效率突破。(2)验证场景有限:由于大规模社交仿真公开数据集匮乏,目前仅在PHEME和HiSim两个场景中验证。需构建更多元的仿真基准以进一步检验方法的通用性。(3)评估部分依赖LLM:社会模拟缺乏像任务解决那样客观、稳定的评估指标,当前框架部分依赖于LLM进行适应度计算,可能引入偏差,需探索更可靠的社会模拟评估框架。
END
复旦大学数据智能与社会计算实验室
Fudan DISC
联系方式:disclab@fudan.edu.cn
地址:复旦大学邯郸校区计算中心

点击“阅读原文”跳转至Github
内容中包含的图片若涉及版权问题,请及时与我们联系删除
