
Thinking Machine最新研究正在被热议!
创始人、OpenAI前CTO Mira Murati亲自转发后,一众围观大佬开始惊叹其研究价值(截不完、根本截不完):
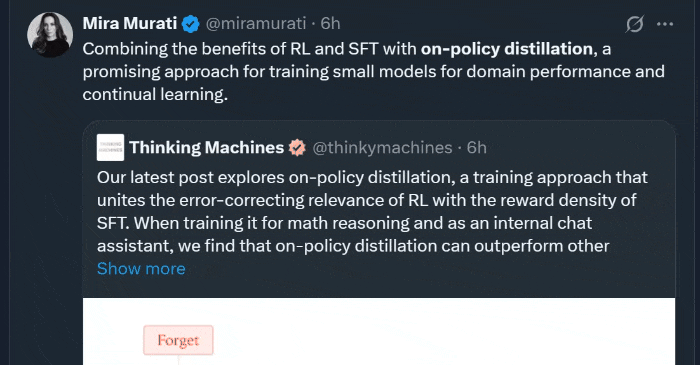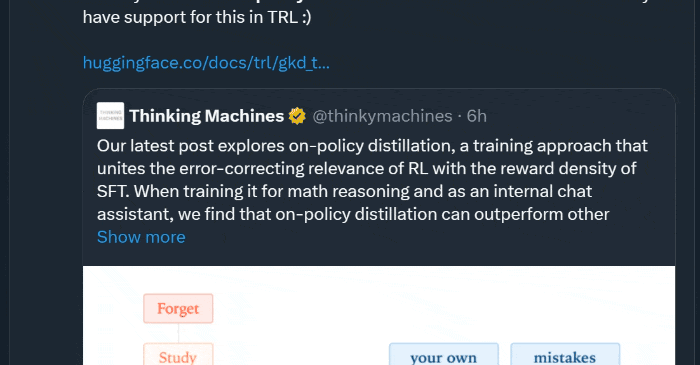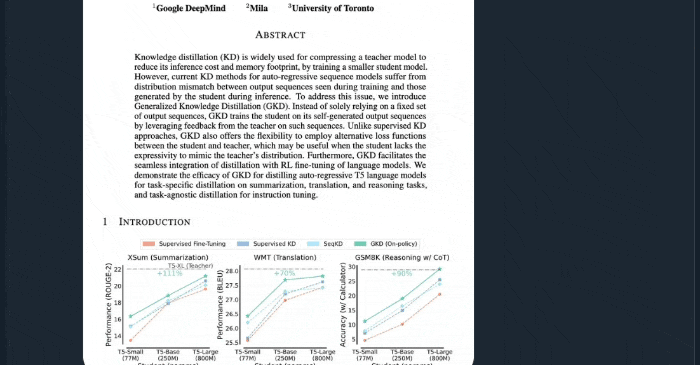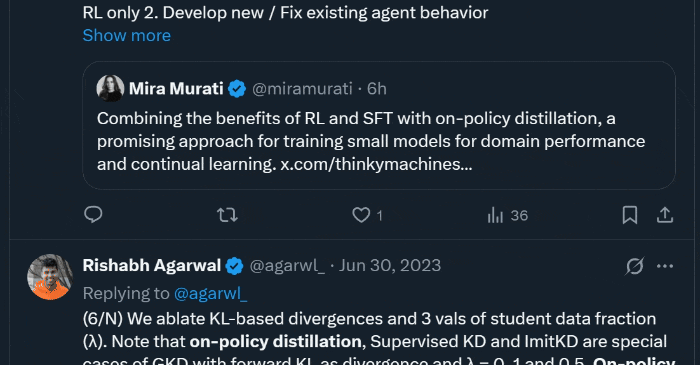
根据Mira Murati的提炼,原来他们提出了一种让小模型更懂专业领域的LLM(大语言模型)后训练方法——On-Policy Distillation (在线策略蒸馏)。

这个方法的精髓,可以打个比方。想象一下,以前训练AI有两种主流方式:
而On-Policy Distillation相当于请了一位天才教练。这位教练一边让AI自己动手解题(实战),一边在它卡壳或犯错时,立刻给出关键提示和正确答案(家教)。
这样做最大的好处就是“性价比”超高。实验结果证明,用这种方法来教小模型数学——达到同样水平,所需的训练步骤少了7-10倍;整体算下来,效率提升了50-100倍。
这意味着,一些资源受限的个人或小公司,也能高效地训练出在特定领域很能打的“小模型”了。
包括翁荔在内,难怪大家看完都直呼:优雅、实在是优雅!

而且啊,当我们扒完相关博客后才发现,On-Policy Distillation的价值还不止于此——
在线策略蒸馏:结合两种范式的最佳实践
论文指出,要让模型具备强大的专业领域能力,通常会经历以下三个过程:
而他们这次就把目光放在了后训练上。
截至目前,后训练阶段诞生了两大主流范式,即开头提到的在线策略 (On-policy) 和离线策略 (Off-policy) 训练。
考虑到两种方式各有其优缺点,所有这次他们选择“取其精华去其糟粕”,来一个巧妙的融合——
将在线策略的自主探索与离线策略的密集监督结合起来,以创造一个“两全其美”的训练框架。

具体来说,他们核心想让学生模型在自己生成的轨迹上学习,但每一步(注意是每一步)都由一个更强大的教师模型进行细致的评分和指导。(就像解题一样,学生给出每一步解题过程,教师给每一步打分)
相关流程大致如下:
初始化教师模型:找一个实力强大的模型当老师(通用模型或经过专门训练的专家模型均可),它只负责计算概率,而不需要进行反向传播更新梯度。
学生采样轨迹:让学生模型自主解题,过程中需记录下它在每一步选择每个token的对数概率。
教师逐步评分:将学生模型生成的轨迹,原封不动地交给教师模型。教师模型会对这个轨迹的每一个token进行评估,计算出在相同的上下文下,它自己生成这个token的对数概率。然后,通过学生和教师的对数概率之差,可以计算出两者在每一步的分歧 (Divergence)。
使用分歧作为奖励进行训练:最后使用上述分歧作为奖励信号,来更新学生模型。
这里重点介绍一下“KL散度 (Negative reverse KL divergence) ”这一评估分歧的指标。

简单来说,当学生模型与教师模型的行为一致时,KL散度为零;当学生模型的选择与教师模型的期望相差甚远时,KL散度会变得很大,从而产生一个强烈的负面奖励(惩罚)。
学生模型的目标就是通过训练,最小化这个KL散度——换言之,越像老师奖励越高,越不像惩罚越狠。
这种逆向KL散度具备两个非常优秀的特性:
一是能防作弊。传统强化学习中,模型可能学会钻空子,用一些看似正确实则取巧的方式获得高分。而现在,评判标准直接锚定教师模型的“真知灼见”,学生只有真正学到精髓才能获得高分,堵死了作弊空间。
二是让学习过程更加稳定和聚焦。它能让学生模型精准锁定教师模型展现的“最优解法”,避免在多个普通答案间摇摆不定,从而确保学习过程更稳定、结果更出色。
基于上述方法和特性,他们进行了两个实验来验证其效果。
实验一:将32B大模型的数学能力快速教给8B小模型
教师模型:Qwen3-32B
学生模型:Qwen3-8B-Base
所有实验从一个共同起点开始:学生模型通过传统训练(监督微调),在数学基准AIME’24上已达到60分。研究目标是将性能从60分提升至70分。
为达成目标,研究人员对比了三种方法的计算成本:
继续传统训练:大约需要额外训练200万个样本,计算开销非常巨大;
强化学习:根据Qwen3团队的技术报告,在一个相似的SFT初始化模型之上,通过强化学习将性能提升到 67.6%,花费了17920个GPU小时。这个成本与训练200万个SFT样本的成本大致相当;
在线策略蒸馏:仅用了大约150个训练步骤就达到了70%的目标分数,与外推到200万样本的SFT相比,在线策略蒸馏的计算成本砍掉了9~30倍。
而且如果从GPU小时的角度看,由于教师模型计算对数概率 (log-probs) 的过程可以高效并行化,实际节省的时间成本可能更接近18倍。
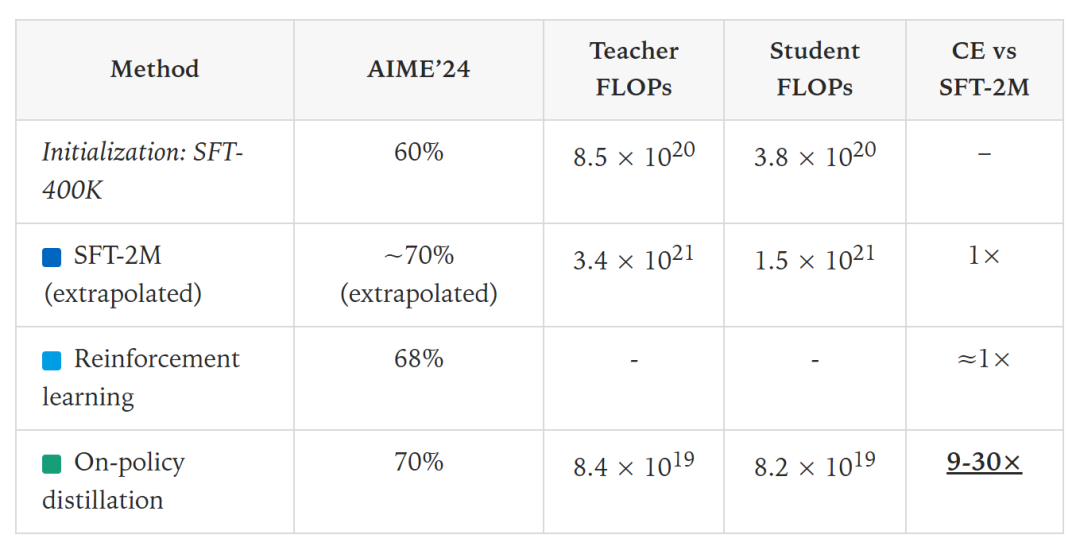
这个实验有力证明了在线策略蒸馏在计算效率上的巨大优势。它用远低于传统SFT或RL的成本,实现了同等甚至更好的性能提升。
实验二:打造兼具知识性与通用性的企业AI助理
目前存在的问题是:给AI学习新知识(公司内部文档)时,它会忘记旧技能(对话交流)。
假如使用传统微调方法向模型注入内部知识,往往会出现严重的“灾难性遗忘”——内部知识得分显著提升(从18%升至43%),但通用能力大幅下降(从85%暴跌至45%)。
而且无论怎样调整数据配比,都无法同时保住两项能力。
于是他们想到了,当模型因学习新知识而“遗忘”部分通用能力后,可以使用在线策略蒸馏进行修复——让“失忆”的模型向它自己最初的、能力完整的版本学习。
结果意外发现,模型的通用能力几乎完全恢复(从79%回升至83%),同时新知识未被破坏(反而从36%提升至41%)。
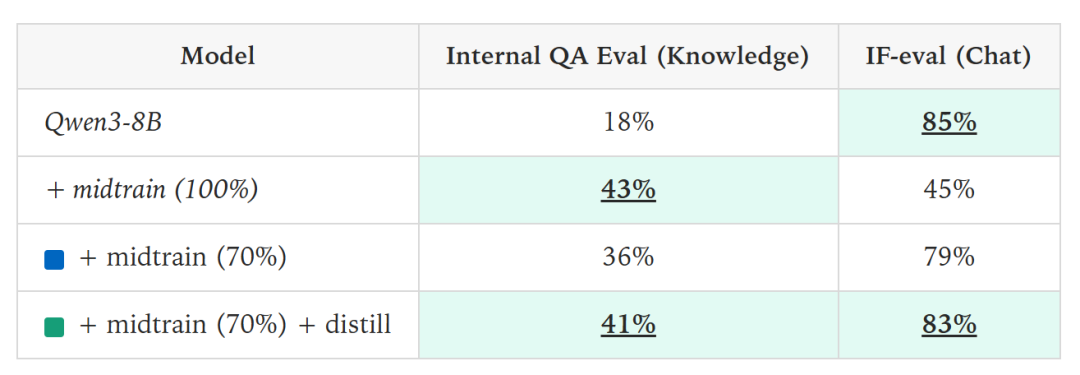
这说明,在线策略蒸馏是解决AI“灾难性遗忘”的有效工具。它能够在不损害新学技能的前提下,精准地恢复模型遗忘的核心能力,为实现AI的“终身学习”提供了关键技术支持。
论文核心作者Kevin Lu
最后看一下这项研究的核心作者——Kevin Lu(论文唯一单独提到的)。

今年8月,Kevin Lu离开OpenAI转身投入Thinking Machine的怀抱。
在OpenAI工作期间,他领导了4o-mini发布,并参与o1-mini、o3发布,主要研究强化学习、小模型和合成数据。
很明显,这一次的研究也和其之前的工作息息相关。
论文:
https://thinkingmachines.ai/blog/on-policy-distillation/
参考链接:
[1]https://x.com/miramurati/status/1982856564970254772
[2]https://x.com/_kevinlu/status/1982857375263666590
一键三连「点赞」「转发」「小心心」
欢迎在评论区留下你的想法!
— 完 —
🏆 年度科技风向标「2025人工智能年度榜单」评选报名火热进行中!我们正在寻找AI+时代领航者 点击了解详情
❤️🔥 企业、产品、人物3大维度,共设立了5类奖项,欢迎企业报名参与 👇

一键关注 👇 点亮星标
内容中包含的图片若涉及版权问题,请及时与我们联系删除
