
DRUGONE
临床计算器在医疗风险评估中发挥关键作用,但其应用往往受限于可用性、传播速度和临床整合度。研究人员提出了 AgentMD——一种能够自动搜集并应用临床计算器的智能语言代理系统。在“工具构建”阶段,AgentMD 从 PubMed 中筛选出 2,164 个可执行的临床计算器,其质量验证准确率超过 85%,单元测试通过率超过 90%。在“工具使用”阶段,AgentMD 可自动选择并应用最合适的计算器进行风险预测。在评估中,AgentMD 在风险预测准确率上显著超越 GPT-4(87.7% vs. 40.9%)。在 698 份真实急诊病历上,AgentMD 能精确计算个体级风险;在 MIMIC-III 病历数据上,它还能提供群体级风险洞察。本研究展示了语言代理在医疗中自动整理并运用临床计算器的潜力,为个体化风险评估与大规模健康数据分析开辟了新方向。

临床风险计算器是医生评估疾病风险与预后的重要工具,例如 HEART 评分可用于预测急性心脏不良事件。然而,这些计算器的临床应用受多重因素限制:
医生需熟悉计算器适用场景与参数;
工具多为独立存在,难以整合;
缺乏与电子病历(EHR)的数据兼容性,导致需手动输入数据;
手工解读带来主观误差。
语言代理(Language Agent)基于大型语言模型(LLMs)发展而来,具有使用外部工具的能力。研究人员基于此提出 AgentMD 框架,旨在:(1)自动化整理临床风险计算器;(2)在不同场景中智能选择并执行相应计算。
AgentMD 既是工具创建者(Tool Maker),也可作为工具使用者(Tool User)。其核心组成包括临床计算器数据库 RiskCalcs,以及一个独立于模型架构的风险计算框架,用于匹配、计算和总结患者风险。

图1. AgentMD 框架结构与临床计算器
方法
AgentMD 包含两个核心阶段:
AgentMD 使用 PubMed 文章作为信息源,通过 LLM 自动筛选与生成计算器草稿,并进行六维验证。最终构建的 RiskCalcs 包含 2,164 个临床风险计算器,每个工具均具备用途说明、计算逻辑(Python函数)、解释标准与临床效用描述。
临床计算器应用(Tool Application)
AgentMD 首先根据患者病历提取关键信息,通过检索模型 MedCPT 匹配最相关计算器。随后,它调用相应的计算逻辑,在 Python 环境中执行运算并生成风险报告。若缺失关键参数,AgentMD 通过最佳/最差情景假设提供范围估计。
这一流程被应用于三类数据:
RiskQA 数据集(350 个多项选择题):用于控制性验证;
Yale 急诊病历(698 份):用于个体级测试;
MIMIC-III 病历(9822 份):用于群体级分析。
结果
RiskCalcs 工具的质量与覆盖性
研究人员在两组样本中验证 RiskCalcs 工具质量:被引用最多的 50 个计算器与随机抽样的 50 个计算器。结果表明:
计算逻辑与结果解释的正确率分别为 87.6% 与 89.0%;
AgentMD 的自动单元测试与人工计算结果一致率达 91.6%。
此外,约 68% 的高引用计算器已存在于网络工具中,但随机样本中仅 4% 可在线获得。AgentMD 自动生成的 RiskCalcs 能弥补网络资源覆盖不足,成为新的可复用医学工具库。
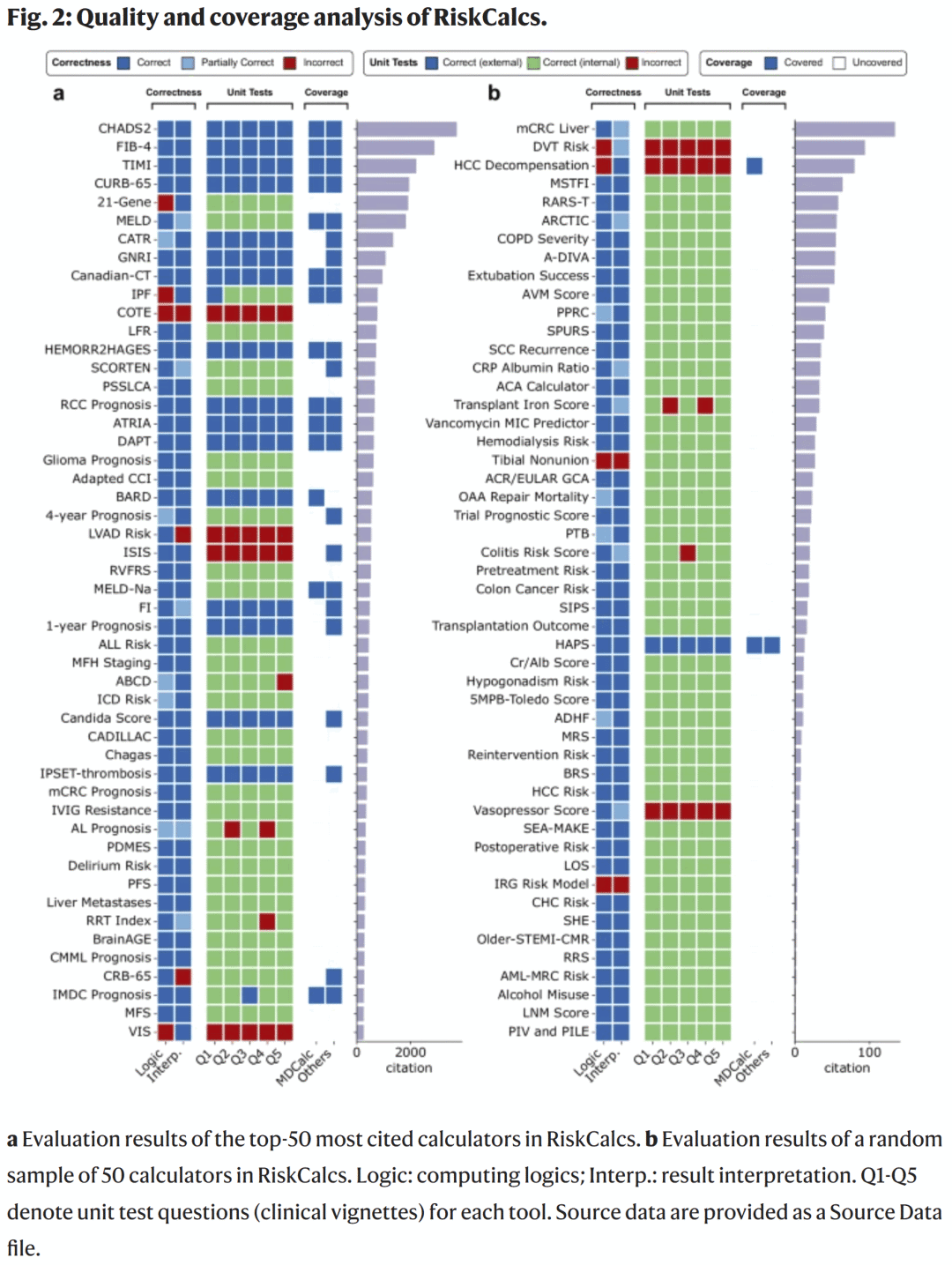
图2. RiskCalcs 计算器的正确性与覆盖性评估结果
RiskQA 基准测试性能
RiskQA 模拟 USMLE 医考题形式,用于评估 AgentMD 的选取与计算能力。
结果显示:
GPT-4 驱动的 AgentMD 准确率 87.7%,而 GPT-4 自身仅 40.9%;
GPT-3.5 驱动的 AgentMD 准确率仍高于 GPT-4 + Chain-of-Thought 提示;
工具选择准确率达 0.823,显著高于基线 MedCPT(0.723)。
这表明,当语言模型获得结构化医疗工具支持后,其风险计算与逻辑推理能力显著增强。
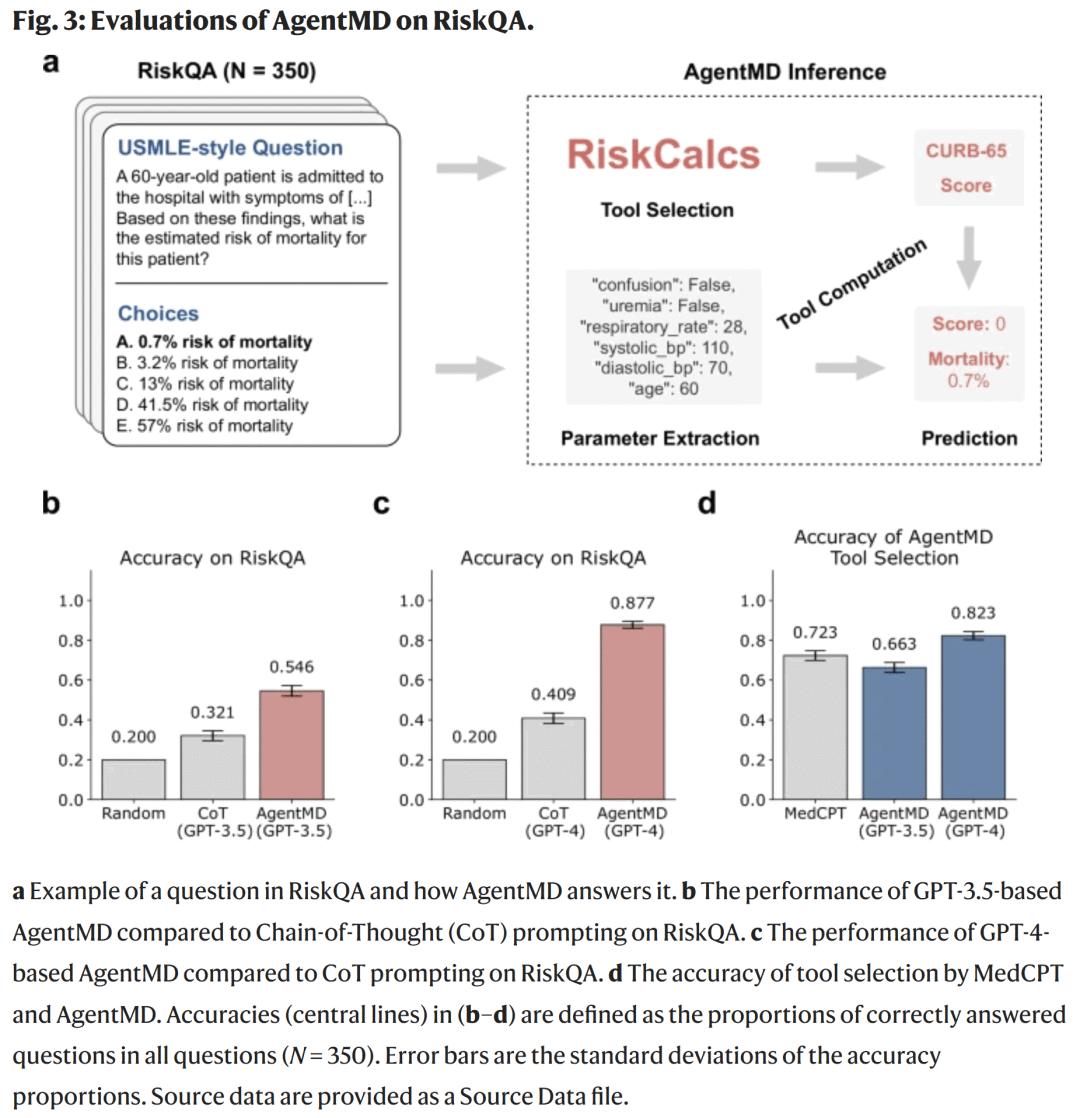
图3. AgentMD 在 RiskQA 数据集上的性能表现与对比
在急诊病历中的个体级风险预测
研究人员选取 16 个常用急诊风险计算器(如 CURB-65、qSOFA、HEART Score 等),并将 AgentMD 应用于 698 份急诊病历。
结果显示:
80.6% 的患者符合计算器使用条件;
在这些样本中,计算过程正确率为 52.3%,部分正确率为 28.5%;
结果有用或部分有用的比例达 97.7%。
多数计算器得分超过 60%,仅个别受缺失值假设影响(如 HEART Score、CCR)。
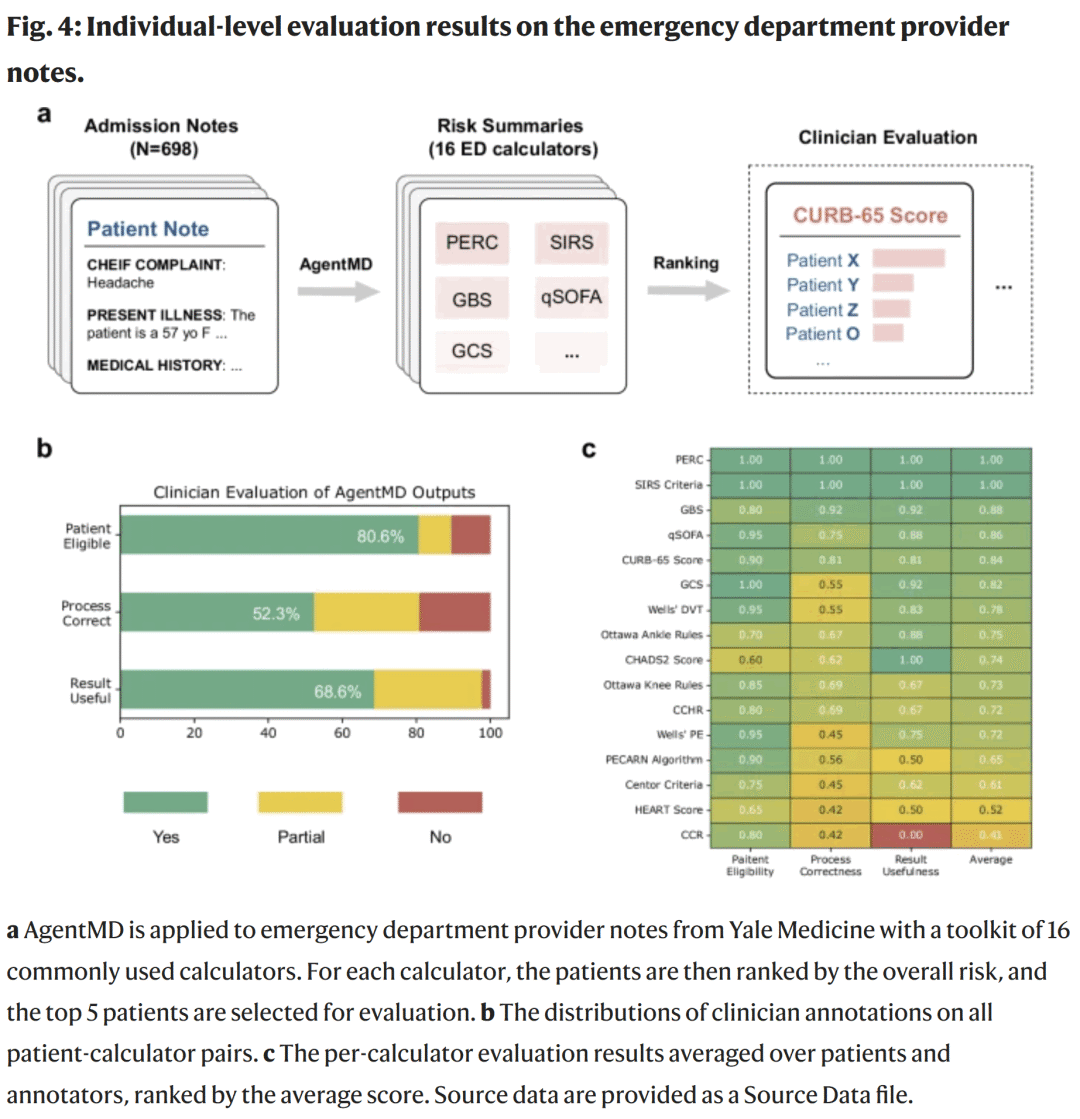
图4. AgentMD 在急诊病历中的预测表现与人工评估结果
群体级风险分析与临床洞察
在 MIMIC-III 病历上,AgentMD 应用 1039 个计算器,覆盖 9822 名患者。每位患者平均应用 4.6 个计算器,显示该模型能同时考虑多重风险因素。AgentMD 还定义了四个可解释指标:特异性、紧急性、严重度、缺失度,并通过医生评估验证了其一致性(平均一致率 70% 以上)。在院内死亡预测任务中,AgentMD 生成的计算结果在 113 个计算器上表现优于 GPT-4,表明其计算结果具有潜在预测增益。
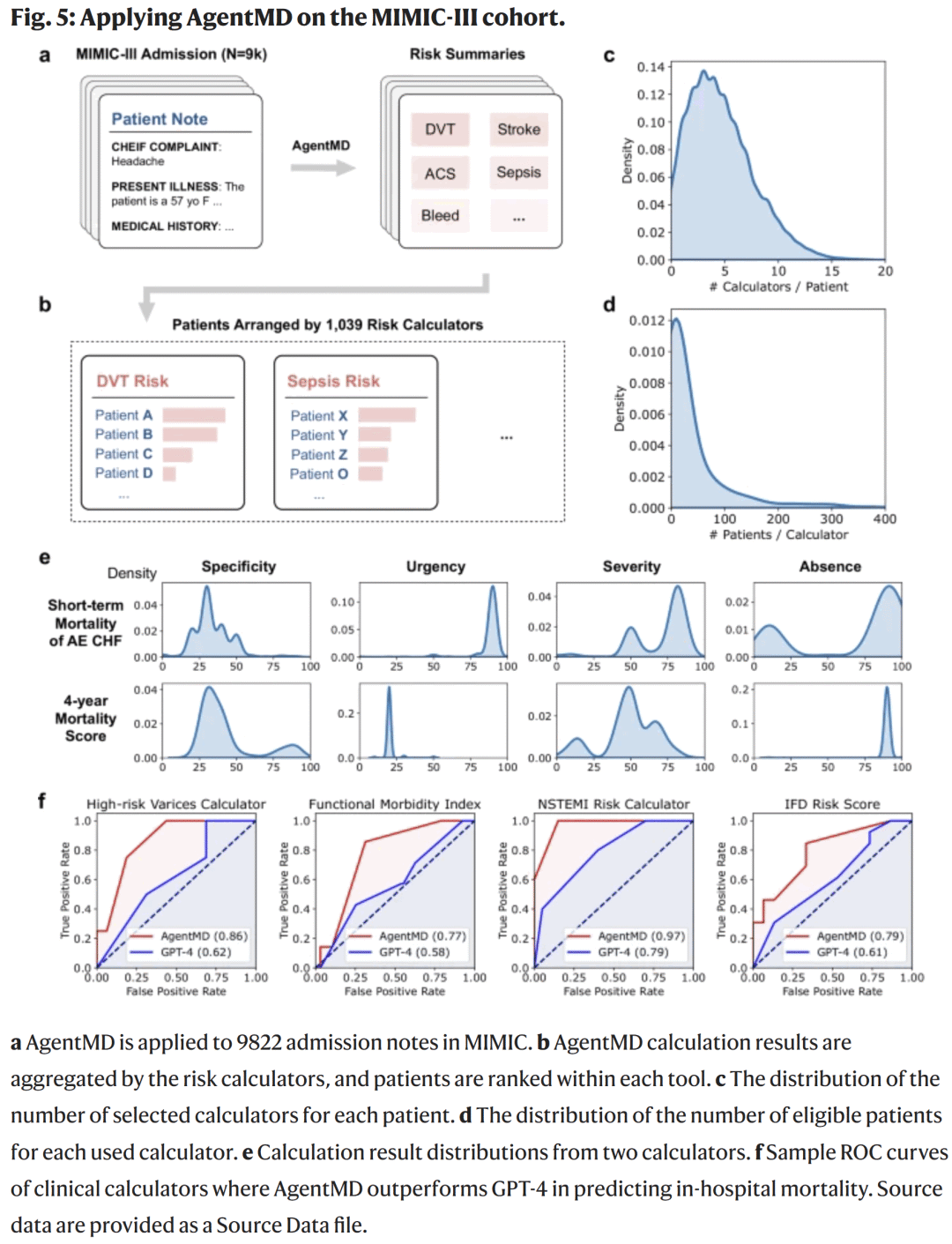
图5. AgentMD 在 MIMIC-III 上的群体级风险分析结果与 ROC
讨论
AgentMD 解决了临床工具学习中的两个核心问题:
缺乏系统的医疗计算器工具库;
缺少自动化的工具应用方法与评估体系。
通过 PubMed 文献挖掘与 LLM 自动生成,AgentMD 构建了全球首个可执行医学计算器集合 RiskCalcs,实现了跨疾病、跨领域的风险建模。
在 RiskQA、急诊病历与 MIMIC-III 三个层级的验证中,AgentMD 展现出优越的准确性、可扩展性与可解释性。
未来方向包括:
扩展至全文数据库与更多信息模态(如影像与结构化数据);
开发低成本、可本地部署的开源版本;
将 AgentMD 嵌入医院工作流程,实现实时辅助决策。
综上,AgentMD 标志着临床语言代理向自主知识构建与风险建模迈出关键一步,为精准医疗与智能决策提供了可扩展、可验证的技术基础。
整理 | DrugOne团队
参考资料
Jin, Q., Wang, Z., Yang, Y. et al. AgentMD: Empowering language agents for risk prediction with large-scale clinical tool learning. Nat Commun 16, 9377 (2025).
https://doi.org/10.1038/s41467-025-64430-x

内容为【DrugOne】公众号原创|转载请注明来源
内容中包含的图片若涉及版权问题,请及时与我们联系删除
