
Published on October 28, 2025 6:55 PM GMT
Substack version here:
https://andreinfante.substack.com/p/when-will-ai-transform-the-economy
A caricature of a common Twitter argument:
”Hey it seems like language models can do a lot of humanlike cognitive tasks, look at this impressive example! That seems like something that would transform the economy.”
“Well, smart guy, these things have been out for a couple of years now. Why isn’t the economy transformed yet?”
This does strike me as a little bit mysterious. The models can do impressive things- solving programming tasks, tackling math and logic puzzles, and answering detailed scientific questions. The median human can barely do these things at all, and the best language models can often do them very well. This seems like an indicator that language models should be well positioned to replace human knowledge workers in droves.
However, even industries that have adopted language models aggressively (e.g. software engineering) are not seeing huge changes to employment or productivity so far. Even accounting for lagging indicators, many early predictions of immediate economic transformation and mass unemployment have not been borne out.
Anecdotally, if I throw a random bite-sized problem at AI, it often totally knocks my socks off (especially taking speed into account). But if I try to use it to solve real problems in my actual job for any length of time, the shine starts to come off a little bit. As a software engineer, these tools genuinely help me (especially in areas where I am less proficient, like web development). But they are not revolutionary. I am not ten times more productive.
One way to relax this apparent tension is to reframe the issue in terms of ceilings and floors. The models have quite high intelligence ceilings (the greatest complexity of task they can sometimes do), better than most humans. However, their intelligence floors (the simplest task they sometimes fail at) are fairly low: they make mistakes that you would expect from a young child, or someone with a cognitive impairment. This combination makes them impressive, but unreliable.
This combination is pretty rare in humans! Human ceilings and floors tend to only be so far apart. I think this is one of the reasons why these things are so polarizing. People latch onto either the bottom or top end of their performance distribution and use it to either dismiss them as shallow babblers or overhype their short term potential, glossing over their limitations. People want to project human assumptions onto inhuman systems: either the unreliability means the impressive stuff must be fake, or vice versa.
Graphically, this idea would look something like this:
A Case Study: A Model of Automating Translation
Let’s take a look at what this unreliability means for the economic impact of AI using a simple model.
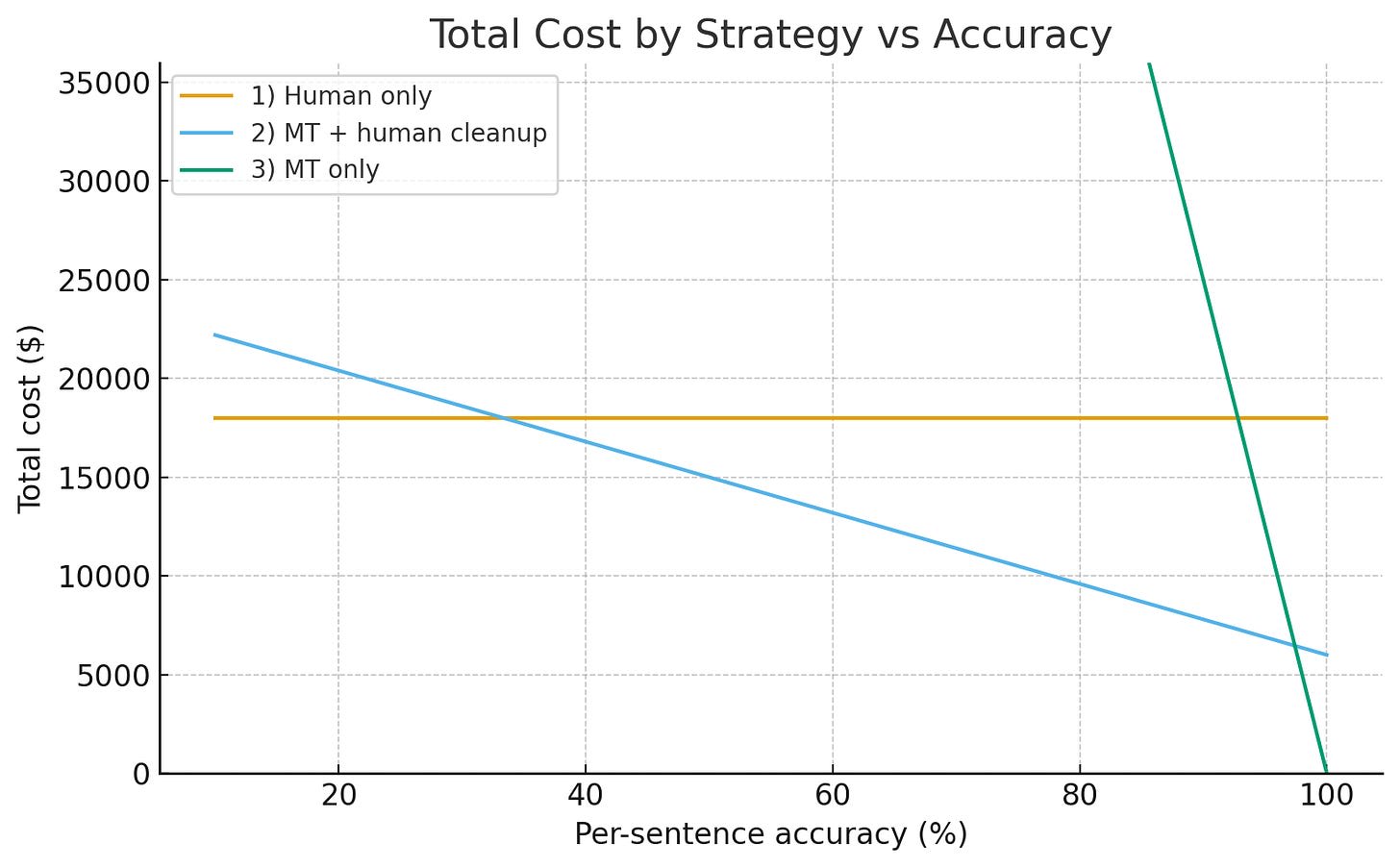
Suppose you have a firm that employs people to translate non-fiction books. The firm can hire humans to do this task ~perfectly, at $60 an hour, taking 300 hours to complete a typical book of 5000 sentences, for a cost of $18,000. These humans can also review a machine-generated solution and fix mistakes as they spot them. In the case of a translation that happens to be perfect, this is the time to simply review both carefully (say, 100 hours or $6000, ~10x longer than casual readthrough of both texts). If the translation is imperfect, there is additional cost to redo each incorrect portion. And, of course, the firm has the option to run the machine translator and simply send the work out the door unchecked. The company pays a reputational cost of $50 in expected lost future business for each wrongly translated sentence that sneaks into a published book (I admit this figure is totally arbitrary, see sensitivity analysis if you object). The machine is assumed to be trivially cheap compared to human labor (usually true and doesn’t change the conclusions much). We assume the firm will pick the strategy that minimizes overall cost at each point.
In this context, raising the ceiling doesn’t help you that much: the models need to be smart enough to correctly translate a sentence, but once they’re there, additional ceiling is kind of irrelevant. It’s all about the floor: how often does the model fuck up? Let’s take a look at how different strategies perform as a function of model accuracy.
Here’s a sensitivity analysis chart, so you can see how the optimal strategy shifts as error cost varies.
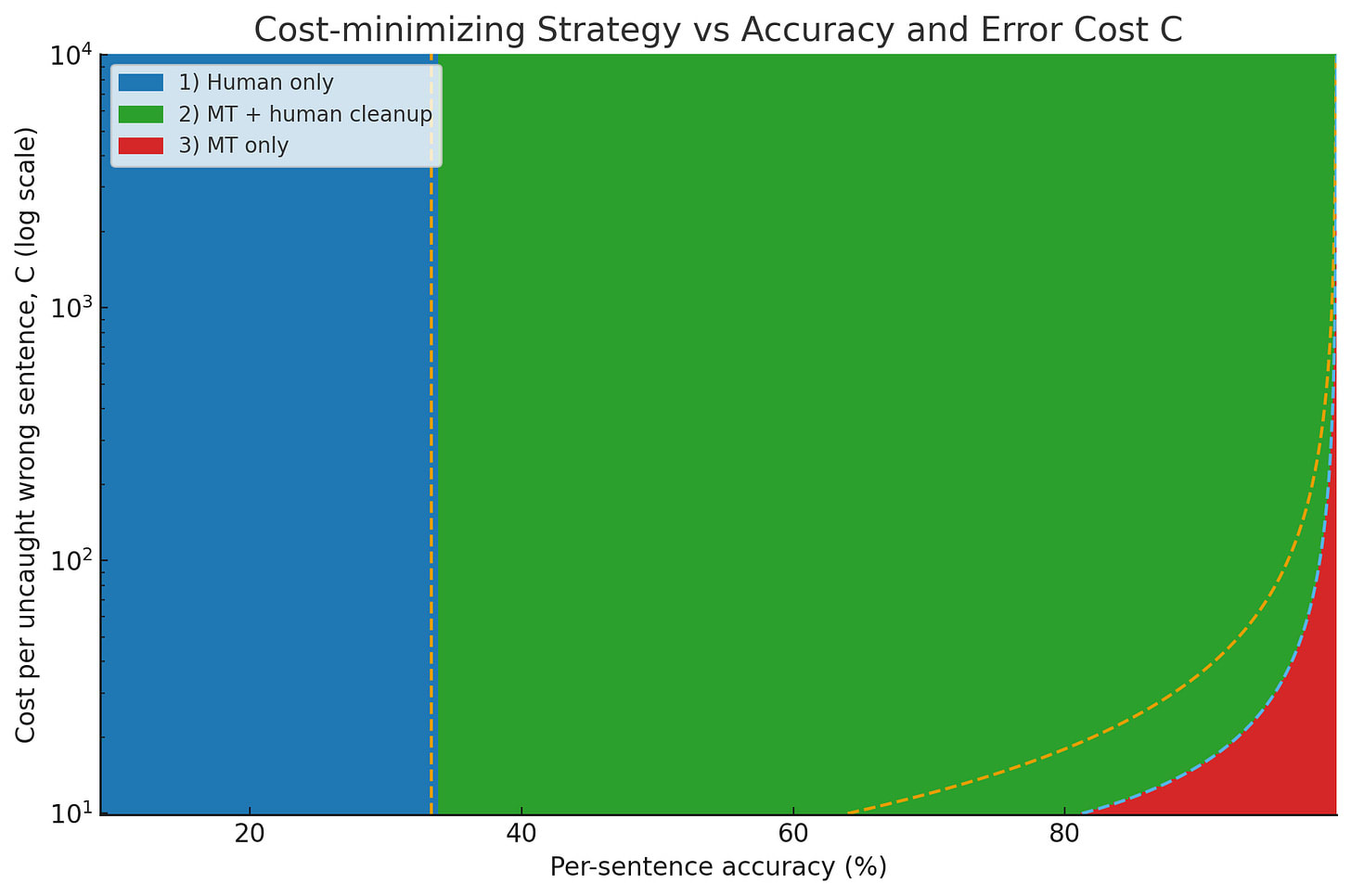
For low accuracies, using the machine translation at all actively makes things worse. For the machine only strategy, the cost of putting out the garbage machine output unrefined is off-the-chart disastrous, and even for the hybrid strategy, cleaning up all the mistakes actually makes the human translator slower. But by the time the machine has a 50% sentence accuracy rate, the hybrid strategy is saving you 20% or so of your costs in this model. And this state of affairs steadily improves into the high 90s, at which point the machine-only strategy comes plunging down from orbit and wins as the error rate approaches zero (higher error costs raise the accuracy at which this takeover occurs, but never totally eliminate it). Taking the cheapest option at each point, you see a similar trend in both cost and human labor utilization.
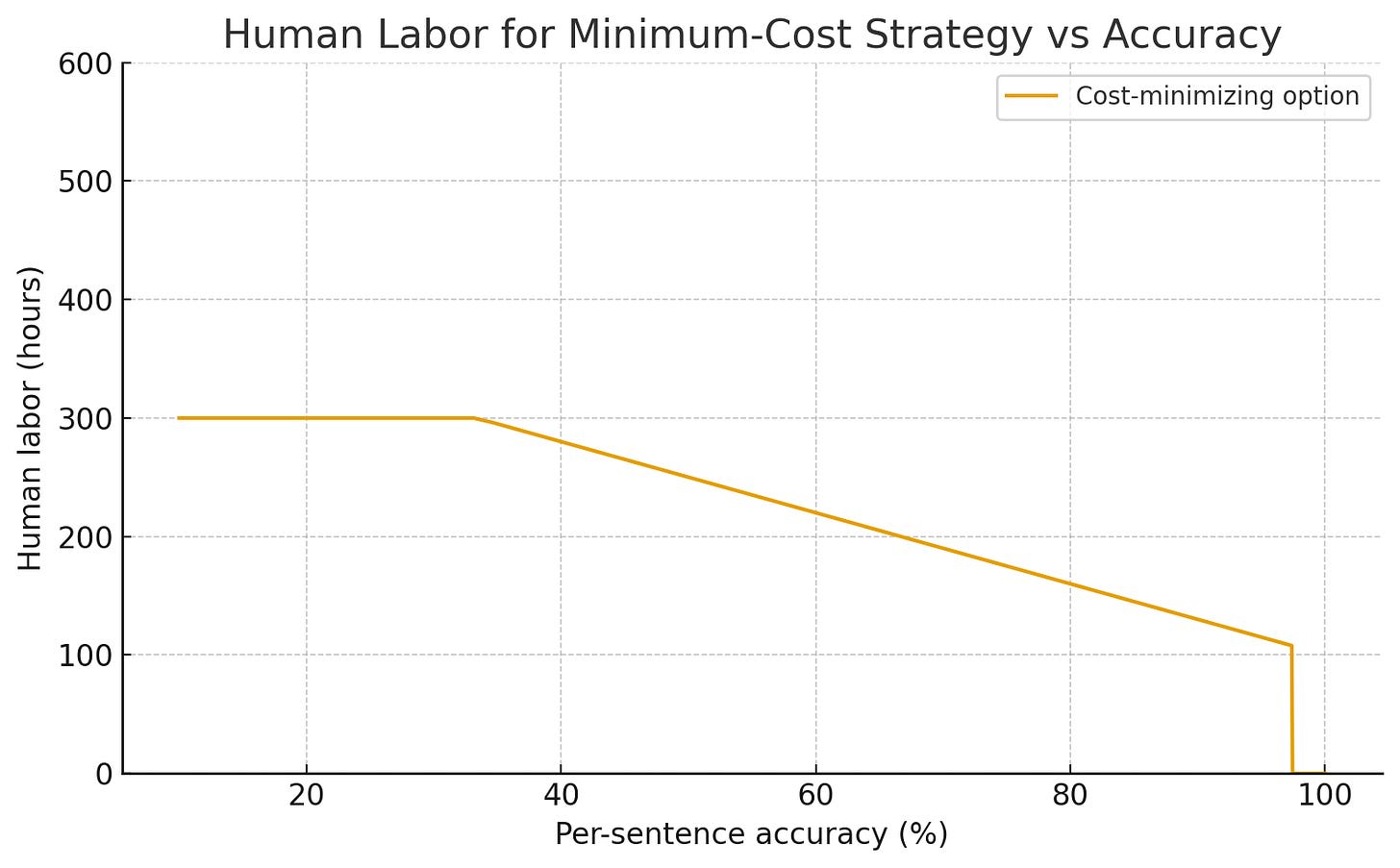
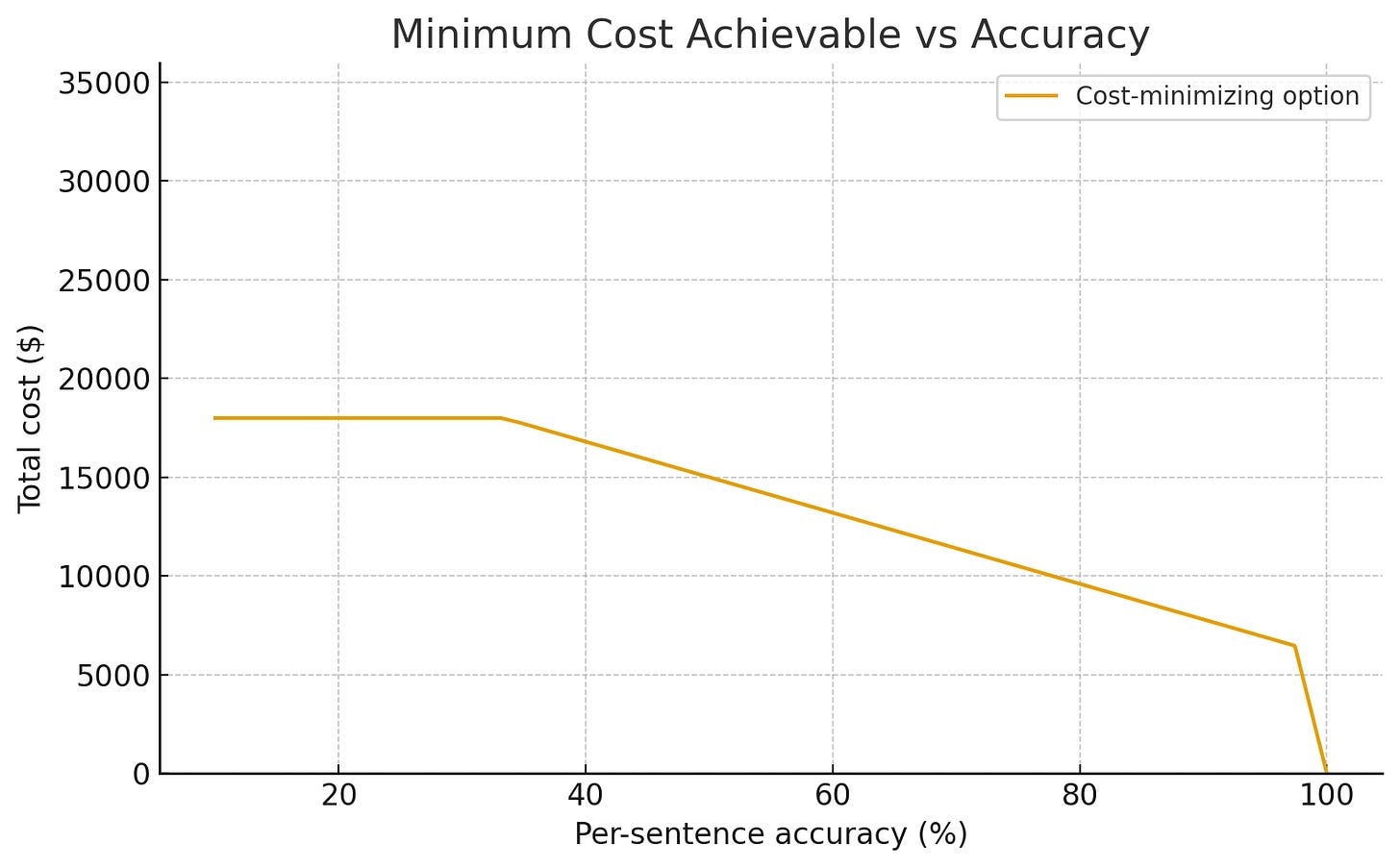
As you can see, starting at a little over 35% accuracy, you start to see employment effects and cost savings, but they’re initially modest and continuous. You only hit a big discontinuity when the machine is almost perfect.
Here’s an animation illustrating how a growing overall accuracy rate impacts tasks with different verification and error costs in this model. You can see that the rising water line quickly forces most tasks into the hybrid regime, eliminating human-only tasks around the 98% mark. From there, the machine-only regime grows steadily with each additional 9 of reliability.
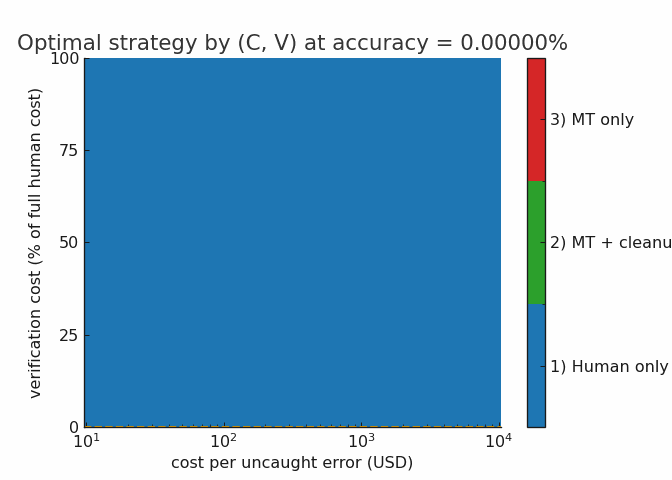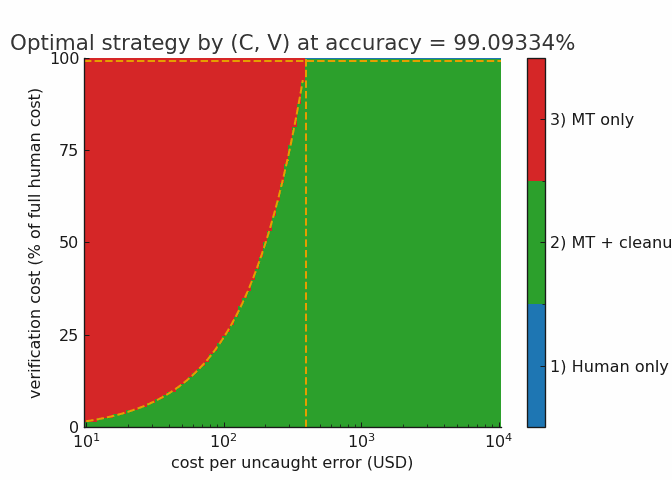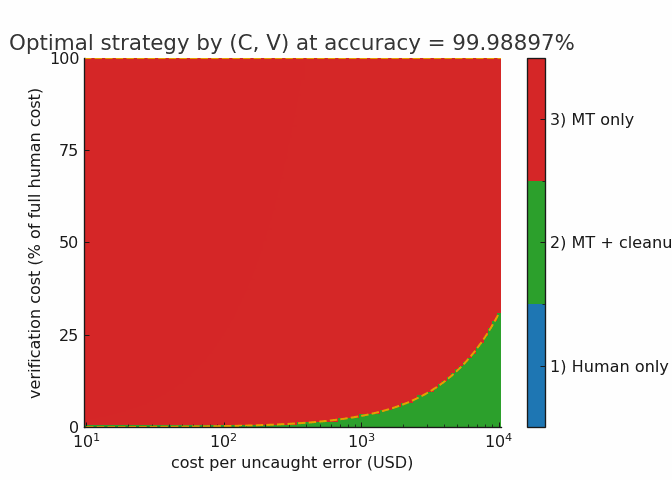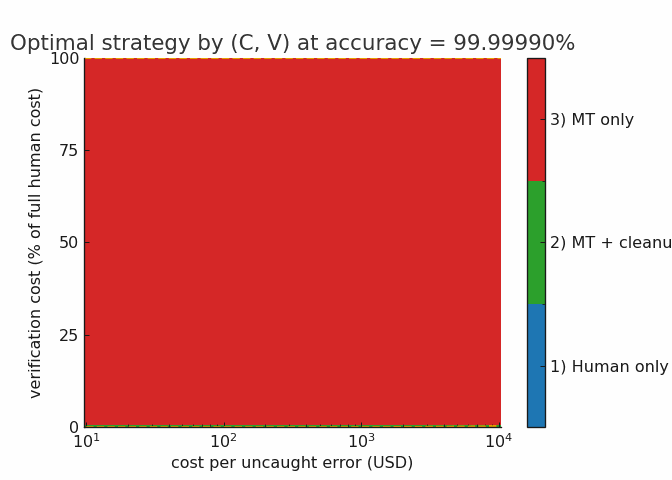
I would caution that the employment effects of the hybrid regime are not straightforward. If the firm is already handling most of the available demand, you will see layoffs from these efficiency improvements, as most people would intuitively expect. But, if there’s a lot of cost-sensitive demand (people who would like to translate their book but can’t quite afford it) the per-project reduction in labor will be offset by increased volume: the firm will translate more books, while needing less labor per book, leaving total labor demand either flat or rising. This is not just a hypothetical scenario from economic theory, this pretty much happened to programmers when the compiler was invented. Every programmer became drastically more productive (many fewer hours required to complete most software than in the microcode era) and demand for programmers, rather than going down, exploded.
That said, the labor impacts of the post-labor regime are actually pretty straightforward. Once you do hit that magic quality threshold, labor required per task abruptly drops to zero and our hypothetical firm fires all its translators, regardless of how much volume it’s handling. You can imagine a scenario where employment actually rises during the early automation of the economy (while obviously shifting around a lot between industries that have differently sloped demand curves and creating a lot of churn), and then begins to collapse as underlying progress in the models hits the critical threshold across many industries.
Obviously, this is a simplified model. In real life, tasks do not have homogenous difficulty or costs, which would tend to blur this graph and round out the sharp transitions. Furthermore, in real life, translations can have varying quality rather than a binary pass/fail, per-error costs are not necessarily linear, and human translators are not perfect- either at translation or at catching errors. And other industries have their own complexities: LMs are pretty well suited to the structure of translation compared to many other tasks.
But I think the broad dynamics of this cartoon model are pretty informative: there is a minimum quality bar for models to be useful at all, there’s a long time spent in the hybrid regime of slow but steady efficiency gains as a function of model quality, and then an abrupt shift to a post-labor regime where the firm no longer employs humans for that particular task.
You can see some of these dynamics reflected in the progress of self driving cars. Getting to a model that can drive some demo routes without interventions is pretty tractable: you can overfit to what you expect to see and reliability can be fairly low and still work most of the time. A number of companies have done it at this point, including Waymo back in 2010. This puts you in a regime that Tesla FSD and similar products now provide commercially, where the technology makes for a pretty good driver assistance feature. Such a feature gets more valuable as the required intervention rate goes down, but only to a point - as long as you need to have an alert human in the car, it’s still just a driver assistance feature. Furthermore, winnowing down the error rate further and further gets more and more difficult. It’s possible to make ML systems with vanishingly low error rates, but it is not easy. Every nine is more costly and time consuming than the previous one.
However, a decade and a half after those first demo drives, Waymo has finally hit a point where the error rate is so low that it’s possible to pull the human safety monitor out of the car completely. Suddenly you have a new kind of post-labor business model that’s potentially much more valuable - an autonomous fleet that can run 24 hours a day with minimal labor costs and with perfectly consistent service and safe driving. This corresponds to the second bend in the graph.
This doesn’t perfectly map to our translation example, because there are hierarchies of correction with different costs, and the automation technology is initially much more expensive than simply running an offline language model in the translation case. Also, the cost of failure for driving is higher than in almost any other industry, which forces you to grind out more of those expensive nines. But you can still see the same basic dynamics in play.
I think in many industries, we are somewhere around the first bend in the curve. Either slightly behind it, where the early AI integrations are not good enough to save time on net, or just after it, where they offer modest wins with tradeoffs. Combined with lagging adoption and lack of familiarity with the (somewhat bizarre) properties of the new tools, this creates a pretty negligible overall impact on economic growth.
However, the models are obviously improving, and I expect that trend to continue for a while. I would guess that within five years, the economic impact within many fields will be substantial and measurable from topline statistics, barring some exogenous shock that changes the economic baseline (e.g. a war or major recession).
When I lay this argument out, I worry a little that it’s trivial or too obvious to be worth arguing in such detail. However, I also feel like I see many discussions from knowledgeable people that are not making these distinctions or thinking specifically about the mechanics of task automation or why current models underperform in real world usage. So I think it’s worth doing the write up, even if some of you are rolling your eyes a little.
Forecasting Model Improvements
One thing that this analysis does not tell us is how long it’s going to take, wall clock time, to reach the second knee of the curve (the one where things get really weird). As someone who exists in the economy, this would be useful to know! Unfortunately, forecasting AI progress is infamously challenging. In 1966, Seymour Papert of the MIT Media Lab tasked a handful of grad students with solving computer vision by the end of the summer, and pretty much set the tone for AI forecasting going forward. If you’re looking for rigorous, highly accurate predictions of future model capacity, you are not going to get it.
What we do have is METR, which measures model performance on tasks vs the time it takes humans to complete the same task, and has noticed a reasonably consistent trend. The length of task (in human time) that models can complete (in a benchmarking context) is doubling roughly twice a year. I would argue that, for the time being, this sort of forecasting is the best signal we have on what the next few years looks like in terms of model improvements.
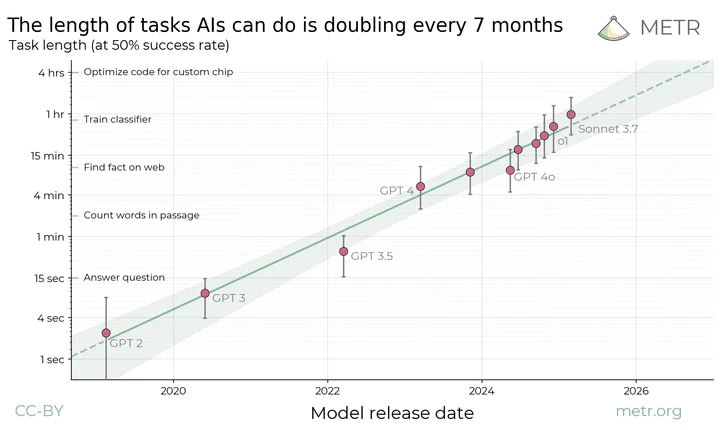
For reference, 50% accuracy is around the point where you’d expect models to start to be economically valuable at all in a given area.
There are all kinds of caveats to this: METR is averaging un-like performance across different areas - some are much stronger than others. Some tasks are very hard to benchmark and are thus underweighted (for example, physical tasks are totally excluded here and are currently much weaker than knowledge work performance). Current models objectively overperform on benchmark tasks compared to real world ones, for a variety of reasons. Accounting for all of this would likely translate the line on the graph downwards somewhat, but I suspect it would not impact the slope much. Regardless, the trend seems to imply that these models should reach a point where they are at least modestly useful, in a hybrid use case, for most knowledge work, within a couple of years.
LDJ has made an effort to extrapolate these trends to higher accuracy rates and got this graph.
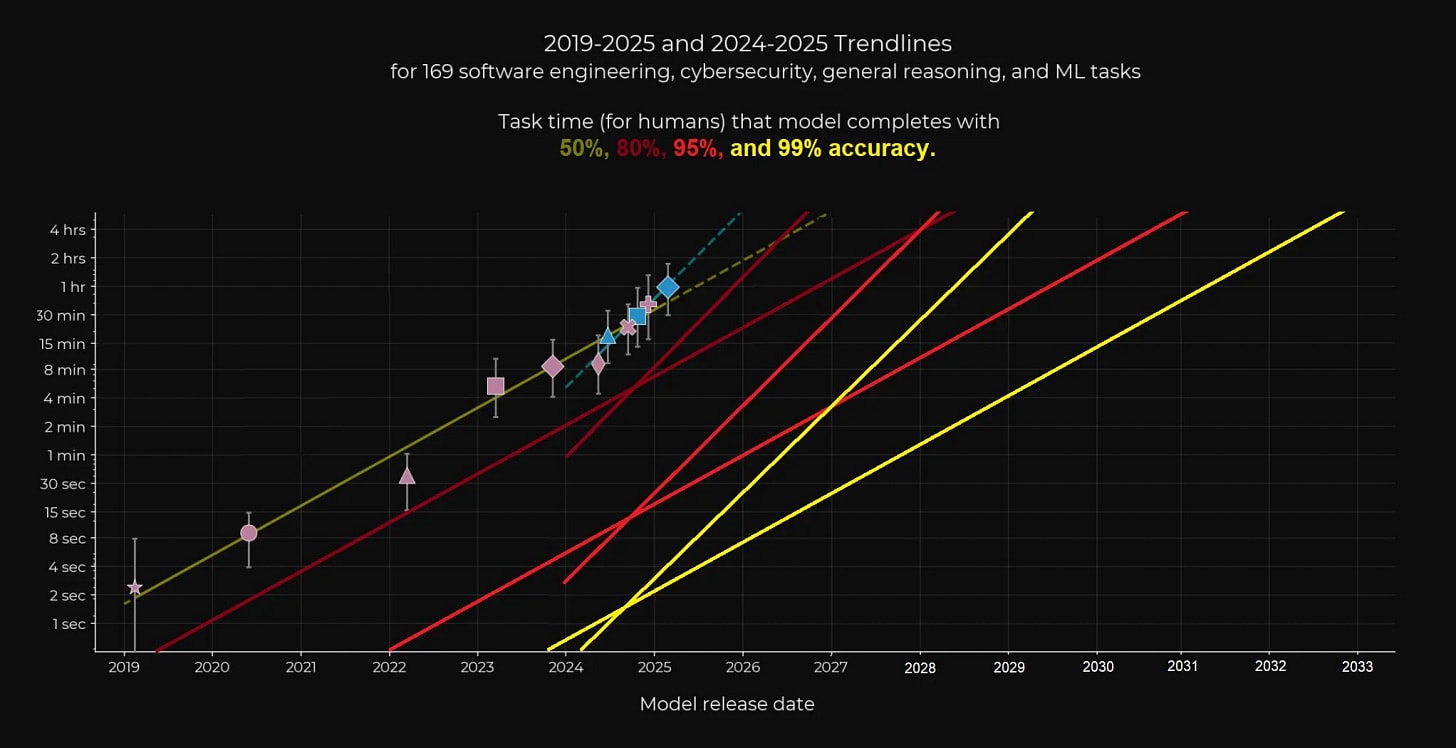
To be clear, I really would not over-index on this. It is an extrapolation of an extrapolation, and the circumstances that produced these trends are subject to change in both directions (compute saturation, new architectures and algorithms, etc.). But the implicit forecast here is that models will be doing tasks with 99% reliability (deep into the hybrid regime and fully replacing humans in some tasks) for a large fraction of substantial, multi-hour knowledge work tasks by the early to mid 2030s, depending on how much you want to offset the graph to account for benchmark overperformance. It also claims that as of right now, models can reliably (99%) do most tasks that a human can do in a few seconds. Both seem plausible to me, although I don’t think anyone should be very confident in such forecasting.
Takeaways
Taken together, all of this paints a picture of a technology that is currently much more impressive than it is useful.
However, it also paints a picture of an economic transformation that will likely be extremely fast compared to past analogies that you could make. The industrial revolution is generally thought to have taken 150 years. The computer revolution, from Turing’s Bombe to an internet-connected computer in most US homes, took about 60 years. If current trends continue, the AI revolution might take 15.
(Although, again, with low confidence - neither 10 nor 30 years would be shocking.)
Discuss
