
Graph databases have revolutionized how organizations manage complex, interconnected data. However, specialized query languages such as Gremlin often create a barrier for teams looking to extract insights efficiently. Unlike traditional relational databases with well-defined schemas, graph databases lack a centralized schema, requiring deep technical expertise for effective querying.
To address this challenge, we explore an approach that converts natural language to Gremlin queries, using Amazon Bedrock models such as Amazon Nova Pro. This approach helps business analysts, data scientists, and other non-technical users access and interact with graph databases seamlessly.
In this post, we outline our methodology for generating Gremlin queries from natural language, comparing different techniques and demonstrating how to evaluate the effectiveness of these generated queries using large language models (LLMs) as judges.
Solution overview
Transforming natural language queries into Gremlin queries requires a deep understanding of graph structures and the domain-specific knowledge encapsulated within the graph database. To achieve this, we divided our approach into three key steps:
- Understanding and extracting graph knowledge Structuring the graph similar to text-to-SQL processing Generating and executing Gremlin queries
The following diagram illustrates this workflow.
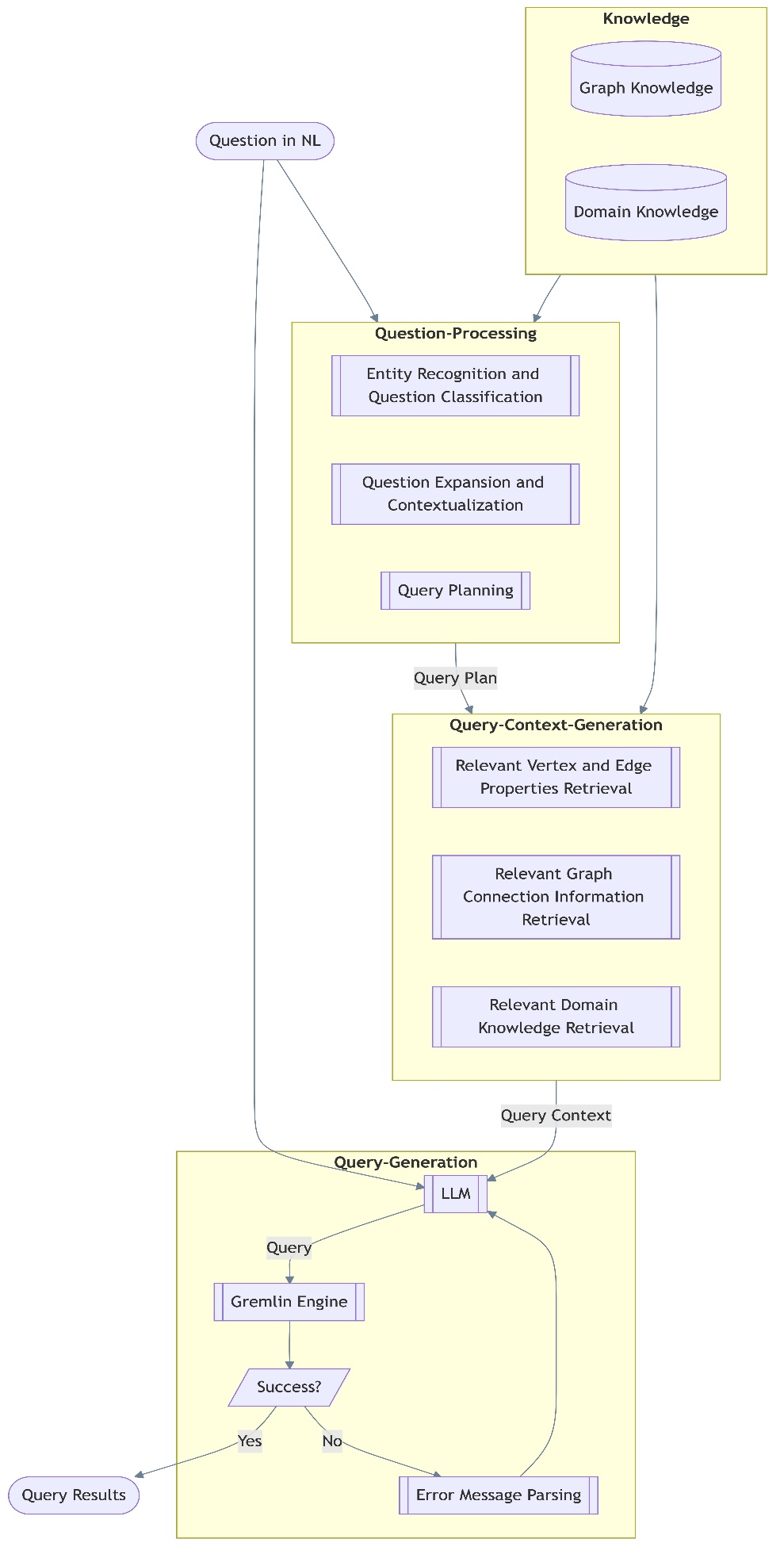
Step 1: Extract graph knowledge
A successful query generation framework must integrate both graph knowledge and domain knowledge to accurately translate natural language queries. Graph knowledge encompasses structural and semantic information extracted directly from the graph database. Specifically, it includes:
- Vertex labels and properties – A listing of vertex types, names, and their associated attributes Edge labels and properties – Information about edge types and their attributes One-hop neighbors for each vertex – Capturing local connectivity information, such as direct relationships between vertices
With this graph-specific knowledge, the framework can effectively reason about the heterogeneous properties and complex connections inherent to graph databases.
Domain knowledge captures additional context that augments the graph knowledge and is tailored specifically to the application domain. It is sourced in two ways:
- Customer-provided domain knowledge – For example, the customer kscope.ai helped specify those vertices that represent metadata and should never be queried. Such constraints are encoded to guide the query generation process. LLM-generated descriptions – To enhance the system’s understanding of vertex labels and their relevance to specific questions, we use an LLM to generate detailed semantic descriptions of vertex names, properties, and edges. These descriptions are stored within the domain knowledge repository and provide additional context to improve the relevance of the generated queries.
Step 2: Structure the graph as a text-to-SQL schema
To improve the model’s comprehension of graph structures, we adopt an approach similar to text-to-SQL processing, where we construct a schema representing vertex types, edges, and properties. This structured representation enhances the model’s ability to interpret and generate meaningful queries.
The question processing component transforms natural language input into structured elements for query generation. It operates in three stages:
- Entity recognition and classification – Identifies key database elements in the input question (such as vertices, edges, and properties) and categorizes the question based on its intent Context enhancement – Enriches the question with relevant information from the knowledge component, so both graph-specific and domain-specific context is properly captured Query planning – Maps the enhanced question to specific database elements needed for query execution
The context generation component makes sure the generated queries accurately reflect the underlying graph structure by assembling the following:
- Element properties – Retrieves attributes of vertices and edges along with their data types Graph structure – Facilitates alignment with the database’s topology Domain rules – Applies business constraints and logic
Step 3: Generate and execute Gremlin queries
The final step is query generation, where the LLM constructs a Gremlin query based on the extracted context. The process follows these steps:
- The LLM generates an initial Gremlin query. The query is executed within a Gremlin engine. If the execution is successful, results are returned. If execution fails, an error message parsing mechanism analyzes the returned errors and refines the query using LLM-based feedback.
This iterative refinement makes sure the generated queries align with the database’s structure and constraints, improving overall accuracy and usability.
Prompt template
Our final prompt template is as follows:
Comparing LLM-generated queries to ground truth
We implemented an LLM-based evaluation system using Anthropic’s Claude 3.5 Sonnet on Amazon Bedrock as a judge to assess both query generation and execution results for Amazon Nova Pro and a benchmark model. The system operates in two key areas:
- Query evaluation – Assesses correctness, efficiency, and similarity to ground-truth queries; calculates exact matching component percentages; and provides an overall rating based on predefined rules developed with domain experts Execution evaluation – Initially used a single-stage approach to compare generated results with ground truth, then enhanced to a two-stage evaluation process:
- Item-by-item verification against ground truth Calculation of overall match percentage
Testing across 120 questions demonstrated the framework’s ability to effectively distinguish correct from incorrect queries. The two-stage approach particularly improved the reliability of execution result evaluation by conducting thorough comparison before scoring.
Experiments and results
In this section, we discuss the experiments we conducted and their results.
Query similarity
In the query evaluation case, we propose two metrics: query exact match and query overall rating. An exact match score is calculated by identifying matching vs. non-matching components between generated and ground truth queries. The following table summarizes the scores for query exact match.
An overall rating is provided after considering factors including query correctness, efficiency, and completeness as instructed in the prompt. The overall rating is on scale 1–10. The following table summarizes the scores for query overall rating.
One limitation in the current query evaluation setup is that we rely solely on the LLM’s ability to compare ground truth against LLM-generated queries and arrive at the final scores. As a result, the LLM can fail to align with human preferences and under- or over-penalize the generated query. To address this, we recommend working with a subject matter expert to include domain-specific rules in the evaluation prompt.
Execution accuracy
To calculate accuracy, we compare the results of the LLM-generated Gremlin queries against the results of ground truth queries. If the results from both queries match exactly, we count the instance as correct; otherwise, it is considered incorrect. Accuracy is then computed as the ratio of correct query executions to the total number of queries tested. This metric provides a straightforward evaluation of how well the model-generated queries retrieve the expected information from the graph database, facilitating alignment with the intended query logic.
The following table summarizes the scores for execution results count match.
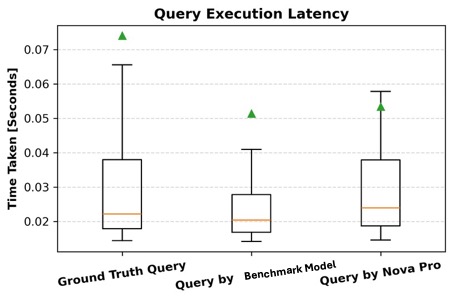
Query execution latency
In addition to accuracy, we evaluate the efficiency of generated queries by measuring their runtime and comparing it with the ground truth queries. For each query, we record the runtime in milliseconds and analyze the difference between the generated query and the corresponding ground truth query. A lower runtime indicates a more optimized query, whereas significant deviations might suggest inefficiencies in query structure or execution planning. By considering both accuracy and runtime, we gain a more comprehensive assessment of query quality, making sure the generated queries are correct and performant within the graph database. The following box plot showcases query execution latency with respect to time for the ground truth query and the query generated by Amazon Nova Pro. As illustrated, all three types of queries exhibit comparable runtimes, with similar median latencies and overlapping interquartile ranges. Although the ground truth queries display a slightly wider range and a higher outlier, the median values across all three groups remain close. This suggests that the model-generated queries are at the same level as human-written ones in terms of execution efficiency, supporting the claim that AI-generated queries are of similar quality and don’t incur additional latency overhead.
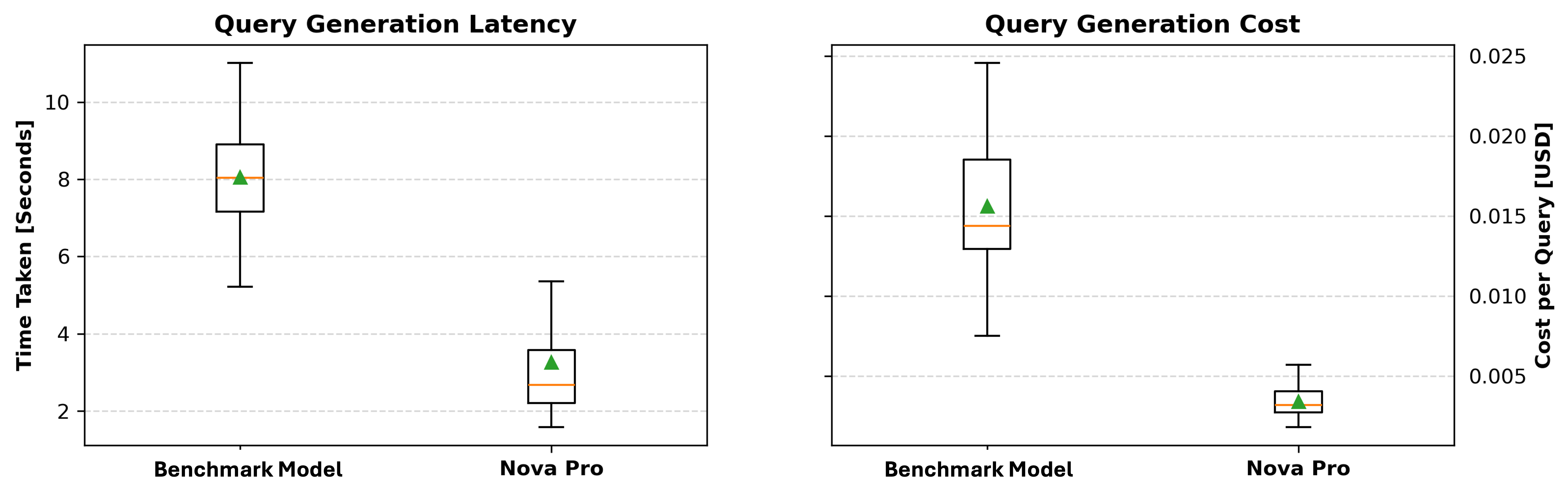
Query generation latency and cost
Finally, we compare the time taken to generate each query and calculate the cost based on token consumption. More specifically, we measure the query generation time and track the number of tokens used, because most LLM-based APIs charge based on token usage. By analyzing both the generation speed and token cost, we can determine whether the model is efficient and cost-effective. These results provide insights in selecting the optimal model that balances query accuracy, execution efficiency, and economic feasibility.
As shown in the following plots, Amazon Nova Pro consistently outperforms the benchmark model in both generation latency and cost. In the left plot, which depicts query generation latency, Amazon Nova Pro demonstrates a significantly lower median generation time, with most values clustered between 1.8–4 seconds, compared to the benchmark model’s broader range from around 5–11 seconds. The right plot, illustrating query generation cost, shows that Amazon Nova Pro maintains a much smaller cost per query—centered well below $0.005—whereas the benchmark model incurs higher and more variable costs, reaching up to $0.025 in some cases. These results highlight Amazon Nova Pro’s advantage in terms of both speed and affordability, making it a strong candidate for deployment in time-sensitive or large-scale systems.
Conclusion
We experimented with all 120 ground truth queries provided to us by kscope.ai and achieved an overall accuracy of 74.17% in generating correct results. The proposed framework demonstrates its potential by effectively addressing the unique challenges of graph query generation, including handling heterogeneous vertex and edge properties, reasoning over complex graph structures, and incorporating domain knowledge. Key components of the framework, such as the integration of graph and domain knowledge, the use of Retrieval Augmented Generation (RAG) for query plan creation, and the iterative error-handling mechanism for query refinement, have been instrumental in achieving this performance.
In addition to improving accuracy, we are actively working on several enhancements. These include refining the evaluation methodology to handle deeply nested query results more effectively and further optimizing the use of LLMs for query generation. Moreover, we are using the RAGAS-faithfulness metric to improve the automated evaluation of query results, resulting in greater reliability and consistency in assessing the framework’s outputs.
About the authors
 Mengdie (Flora) Wang is a Data Scientist at AWS Generative AI Innovation Center, where she works with customers to architect and implement scalable Generative AI solutions that address their unique business challenges. She specializes in model customization techniques and agent-based AI systems, helping organizations harness the full potential of generative AI technology. Prior to AWS, Flora earned her Master’s degree in Computer Science from the University of Minnesota, where she developed her expertise in machine learning and artificial intelligence.
Mengdie (Flora) Wang is a Data Scientist at AWS Generative AI Innovation Center, where she works with customers to architect and implement scalable Generative AI solutions that address their unique business challenges. She specializes in model customization techniques and agent-based AI systems, helping organizations harness the full potential of generative AI technology. Prior to AWS, Flora earned her Master’s degree in Computer Science from the University of Minnesota, where she developed her expertise in machine learning and artificial intelligence.  Jason Zhang has expertise in machine learning, reinforcement learning, and generative AI. He earned his Ph.D. in Mechanical Engineering in 2014, where his research focused on applying reinforcement learning to real-time optimal control problems. He began his career at Tesla, applying machine learning to vehicle diagnostics, then advanced NLP research at Apple and Amazon Alexa. At AWS, he worked as a Senior Data Scientist on generative AI solutions for customers.
Jason Zhang has expertise in machine learning, reinforcement learning, and generative AI. He earned his Ph.D. in Mechanical Engineering in 2014, where his research focused on applying reinforcement learning to real-time optimal control problems. He began his career at Tesla, applying machine learning to vehicle diagnostics, then advanced NLP research at Apple and Amazon Alexa. At AWS, he worked as a Senior Data Scientist on generative AI solutions for customers.  Rachel Hanspal is a Deep Learning Architect at AWS Generative AI Innovation Center, specializing in end-to-end GenAI solutions with a focus on frontend architecture and LLM integration. She excels in translating complex business requirements into innovative applications, leveraging expertise in natural language processing, automated visualization, and secure cloud architectures.
Rachel Hanspal is a Deep Learning Architect at AWS Generative AI Innovation Center, specializing in end-to-end GenAI solutions with a focus on frontend architecture and LLM integration. She excels in translating complex business requirements into innovative applications, leveraging expertise in natural language processing, automated visualization, and secure cloud architectures.  Zubair Nabi is the CTO and Co-Founder of Kscope, an Integrated Security Posture Management (ISPM) platform. His expertise lies at the intersection of Big Data, Machine Learning, and Distributed Systems, with over a decade of experience building software, data, and AI platforms. Zubair is also an adjunct faculty member at George Washington University and the author of Pro Spark Streaming: The Zen of Real-Time Analytics Using Apache Spark. He holds an MPhil from the University of Cambridge.
Zubair Nabi is the CTO and Co-Founder of Kscope, an Integrated Security Posture Management (ISPM) platform. His expertise lies at the intersection of Big Data, Machine Learning, and Distributed Systems, with over a decade of experience building software, data, and AI platforms. Zubair is also an adjunct faculty member at George Washington University and the author of Pro Spark Streaming: The Zen of Real-Time Analytics Using Apache Spark. He holds an MPhil from the University of Cambridge.  Suparna Pal – CEO & Co-Founder of kscope.ai – 20+ years of journey of building innovative platforms & solutions for Industrial, Health Care and IT operations at PTC, GE, and Cisco.
Suparna Pal – CEO & Co-Founder of kscope.ai – 20+ years of journey of building innovative platforms & solutions for Industrial, Health Care and IT operations at PTC, GE, and Cisco.  Wan Chen is an Applied Science Manager at AWS Generative AI Innovation Center. As a ML/AI veteran in tech industry, she has wide range of expertise on traditional machine learning, recommender system, deep learning and Generative AI. She is a stronger believer of Superintelligence and is very passionate to push the boundary of AI research and application to enhance human life and drive business growth. She holds Ph.D in Applied Mathematics from University of British Columbia and had worked as postdoctoral fellow in Oxford University.
Wan Chen is an Applied Science Manager at AWS Generative AI Innovation Center. As a ML/AI veteran in tech industry, she has wide range of expertise on traditional machine learning, recommender system, deep learning and Generative AI. She is a stronger believer of Superintelligence and is very passionate to push the boundary of AI research and application to enhance human life and drive business growth. She holds Ph.D in Applied Mathematics from University of British Columbia and had worked as postdoctoral fellow in Oxford University.  Mu Li is a Principal Solutions Architect with AWS Energy. He’s also the Worldwide Tech Leader for the AWS Energy & Utilities Technical Field Community (TFC), a community of 300+ industry and technical experts. Li is passionate about working with customers to achieve business outcomes using technology. Li has worked with customers to migrate all-in to AWS from on-prem and Azure, launch the Production Monitoring and Surveillance industry solution, deploy ION/OpenLink Endur on AWS, and implement AWS-based IoT and machine learning workloads. Outside of work, Li enjoys spending time with his family, investing, following Houston sports teams, and catching up on business and technology.
Mu Li is a Principal Solutions Architect with AWS Energy. He’s also the Worldwide Tech Leader for the AWS Energy & Utilities Technical Field Community (TFC), a community of 300+ industry and technical experts. Li is passionate about working with customers to achieve business outcomes using technology. Li has worked with customers to migrate all-in to AWS from on-prem and Azure, launch the Production Monitoring and Surveillance industry solution, deploy ION/OpenLink Endur on AWS, and implement AWS-based IoT and machine learning workloads. Outside of work, Li enjoys spending time with his family, investing, following Houston sports teams, and catching up on business and technology.
