
Published on October 23, 2025 5:45 PM GMT
Read Part One, The personal intelligence I want, to catch up on my general thoughts on this topic. It motivates this more in-the-weeds Part Two that dives deeper into our work on personal AI, in particular how and why we’ve made certain design choices. We’re calling it Hue.
To be very honest with you, often I think our solutions are smart, but sometimes they give me build-a-generator-in-your-garage vibes. Janky. In any case, let me talk about them, and maybe you can tell me.
The problem
Say you are wondering, “What are my subconscious patterns causing me harm.” You ask ChatGPT, and it tells you this:
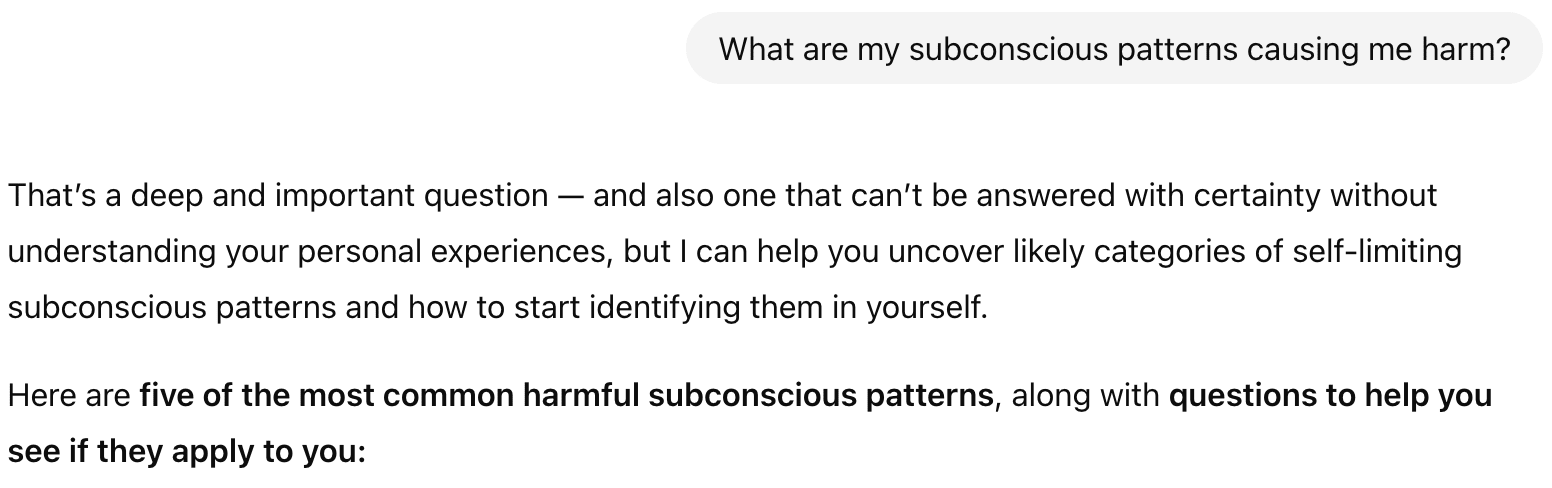
Now you’ve got a list of “common harmful subconscious patterns,” what do you do? Go through them one by one to see if any apply? Act as your own therapist? Learn about psychology? That defeats the point entirely. ChatGPT feels exhausting when it seems personal and helpful but misses the mark on what you really need. In a sense, it almost feels disrespectful, as the work is now volleyed back to you, beguilingly.
What you are actually looking for, in this scenario, is something like this, an answer that kicks you in the head a bit:

So why can’t ChatGPT do it?
1) It simply doesn’t know you that well, and 2) It sucks at making the right connections; together, 1) and 2) make each other worse.
It doesn’t know who you care about, what “sabotaging” looks like in your life, how you grew up, your reaction patterns. I am not saying ChatGPT is not capable, to be sure, because that would be a wild claim to make. It just falls short in this case, which is representative of some of the most difficult yet defining problems in human lives.
The natural question to ask next is, what if you gave ChatGPT access to all your personal data? Would this issue then be perfectly resolved?
Not quite.
ChatGPT today handles in-chat memories (as far as we know) by stuffing summarized remnants of past conversations into the context window of every conversation, according to this post. That’s it. It even says in its own response in the screenshot “… can’t be answered with certainty without understanding your personal experiences.”
It’s not that much information to compact (they only handle user messages, not the system ones), and memory already feels half-baked. Nuances are flattened and contextual richness is lost. Just imagine what would happen if you gave it millions of tokens of messy texts.
What about RAG then, the OG way?
It doesn’t really work either. One, it responds well only to precise queries that are effective entry points for searches. If you ask something high-level, like “What are my subconscious patterns”, it would not know how to begin, let alone find the relevant people, events, and continuity. And often, we don’t know what to ask at all. Two, even if the queries are targeted, consistently high-quality retrieval is nearly impossible with the traditional pipeline of chunking → embedding → storing → retrieving. More on this later.
The question about “subconscious patterns” is just the tip of the iceberg. Scaling to millions of tokens and all types of queries and tasks would only exacerbate the problem. Causality becomes impossible.
Information, knowledge, and insights exist at different scales, and we want an architecture that allows one to titrate into another.
This is clearly a difficult but valuable problem to solve (read the first post to understand better just how valuable it is), yet so few people are working on it.
One has to ask…
Why is that the case?
If we squint our eyes, the personal intelligence space maps onto these four quadrants: “understanding” on the left, “doing” on the right. The vertical axis is less important right now, but together we get a fuller picture.
‘Doing’ gets a lot of attention. In the passive corner, you have chat-style assistants: you ask, they answer. In the proactive box, you have agents, the holy grail of personal AI today (or enterprise; anything really). Book your flight. Order your groceries. Schedule your meetings.
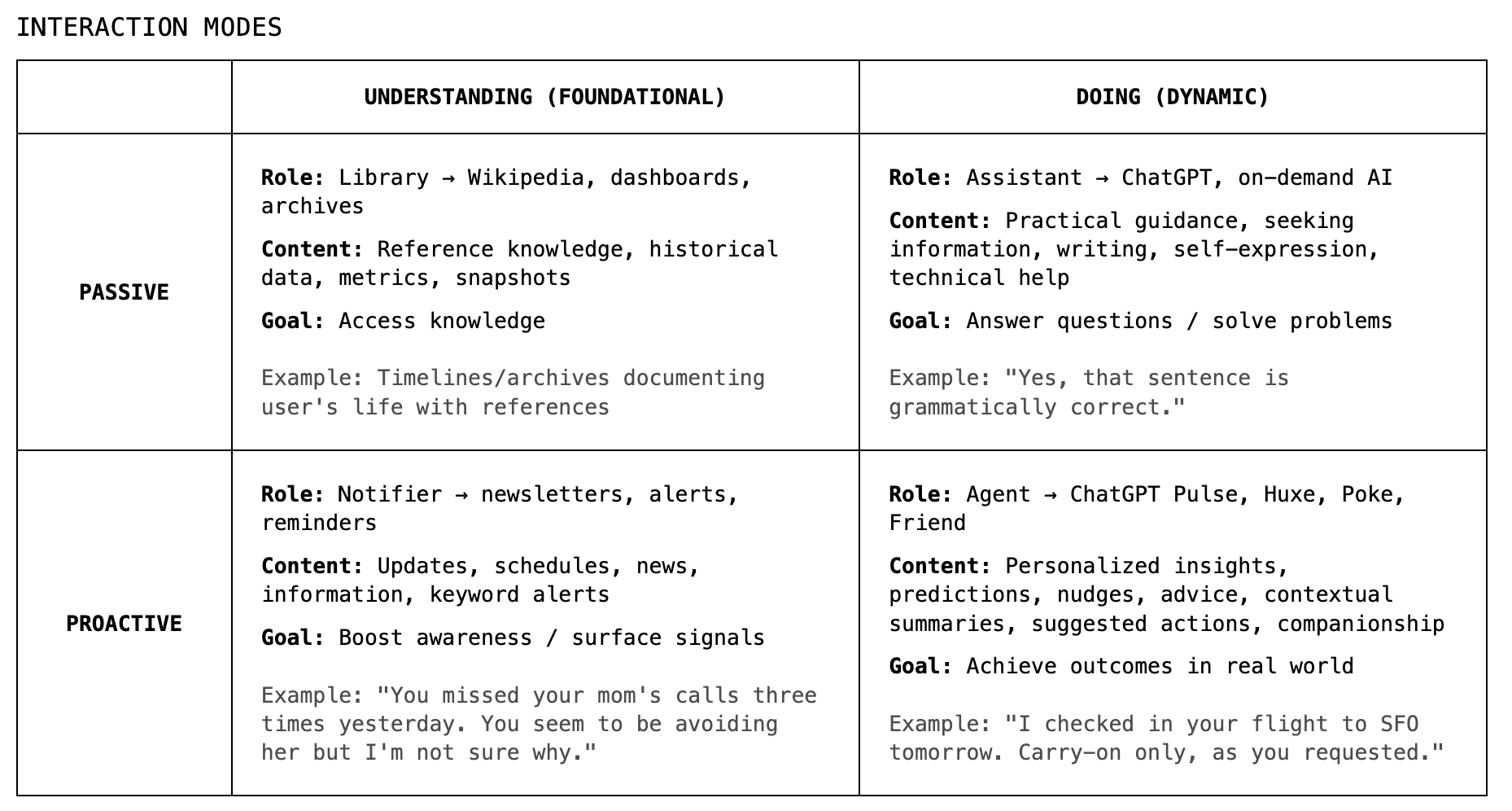
And it’s crowded for good reasons. These systems are closer to tangible outcomes, easier to measure, more visible, but getting them to stable high performance is no joke. Most agents that thrive are in areas of high fault tolerance (i.e. you can mess up half the time and users still stay); those hoping to make way in low-fault-tolerance environments struggle (i.e. mess up one out of ten times and you are gone).
‘Understanding’ gets far less love, despite clear potential: searchable archives of your life, ambient intelligence that proactively surfaces signals like growth patterns and blind spots from real data, or an AI that can actually answer, “What are my subconscious patterns that are hurting me?” or “Why do I keep burning out at work,” or “What’s that Thai restaurant Max mentioned six months ago?”
All of this is buried inside existing data, and making use of it is challenging from an architectural perspective, as we’ve partially established before.
And the architecture needs to be designed towards a set of desired outputs, which are, for the lack of a better word, fuzzy, and therefore hard to optimize and design evals for. How do you measure self-understanding or resonance? There’s no definitive ground truth.
Not only that, even if you could perfectly define the desirable states, how do you get there? It would require solving: 1) how to resolve the friction in data processing at scale, 2) how to make use of processed data effectively, and, critically, 3) how to set up data + reinforcement learning (RL) loops such that 1) and 2) fortify each other.
We find all this fascinating. We are trying to build a different kind of personal intelligence by solving for the problems above, and we’ve landed on some solutions we like. Keep in mind all of these attempts are simply us looking at the problems at hand, breaking them down, and coming up with fixes by trial and error. Nowhere near perfect, but it works.
Imagine if you could dump all of your personal data in one place: data takeouts, journals, message history going back 10 years, notes, music, movies, books, ChatGPT history… You get an intelligence that knows everything about your forgotten past, your present pain, your future aspirations. (from Part One)
This is what we want to build. At this point, you are probably asking…
What are we doing exactly?
We are building a hierarchical system to process large quantities of personal data, each layer progressively more abstract and dense. It’s a pyramid where messy data gets compressed and enriched as it flows down.
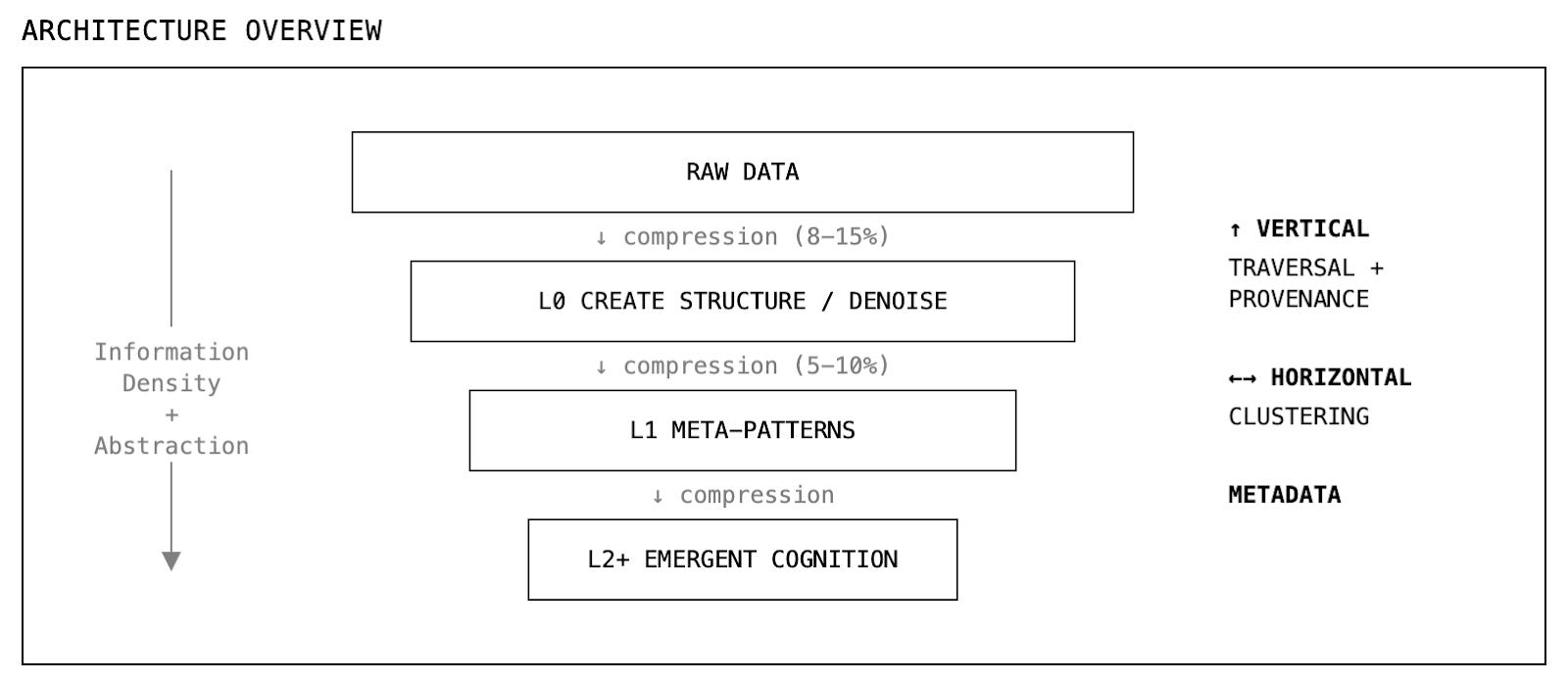
Let’s zoom in.
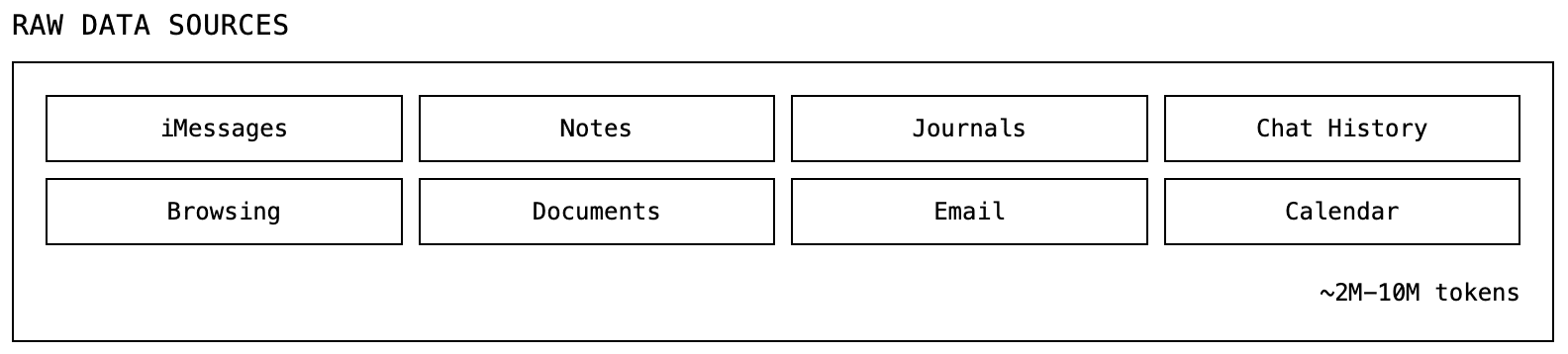
Understanding raw data
We start with raw data. For a typical user, this is roughly 2-10 million tokens accumulated over years: iMessages, notes, journals, chat history, email, data takeouts…
The system needs to read data the way a human would. A financial transaction (i.e. “$47 at Whole Foods”) is factual: extract, timestamp, move on. A voice memo (i.e. “I keep replaying what she said and I don’t know what it means”) is confessional and requires interpretation. One journal entry might be descriptive (i.e. “I went for a drink with Mark”), while another might be effusive and emotional (i.e. “I feel depressed and my heart is sinking”).
LLMs must grasp not just content but tone and modality so processing adapts to context. In practice, we hope to achieve contextual meta-cognition through prompt engineering.
Layer 0: extract signals, build structures
First pass creates layer 0 by transforming raw data into thousands of structured entities with rich metadata, which includes, critically, temporal indexing.

We timestamp everything to mitigate the differences in how LLMs and humans perceive time, in that LLMs don’t see time at all, whereas our sense of self, memory, and causality all depend on chronology. That’s how our memories work. We know March 2021 happened before Jan 2024, and we understand the implications of that: the person in 2024 is 3 years older, maybe wiser, the memories are fresher, etc. With temporal indexing, the system can reconstruct continuity, and users can browse their life as if flipping through a photo album.
Content-wise, notice how instead of “Maya told you she loved you”, we have “Maya told you she loved you during dinner. You said it back, but your journal that night… Physical anxiety response to affection.” L0 surfaces interpretative signals, precise and compact, with enough details retained to facilitate further aggregation and extraction.
Layers 1 & 2: emergent patterns and identity models
As we progress, we want increasingly holistic understandings of the person.
At layer 1, we cluster and connect dozens of lower-level events across time, finding patterns that span months or years.
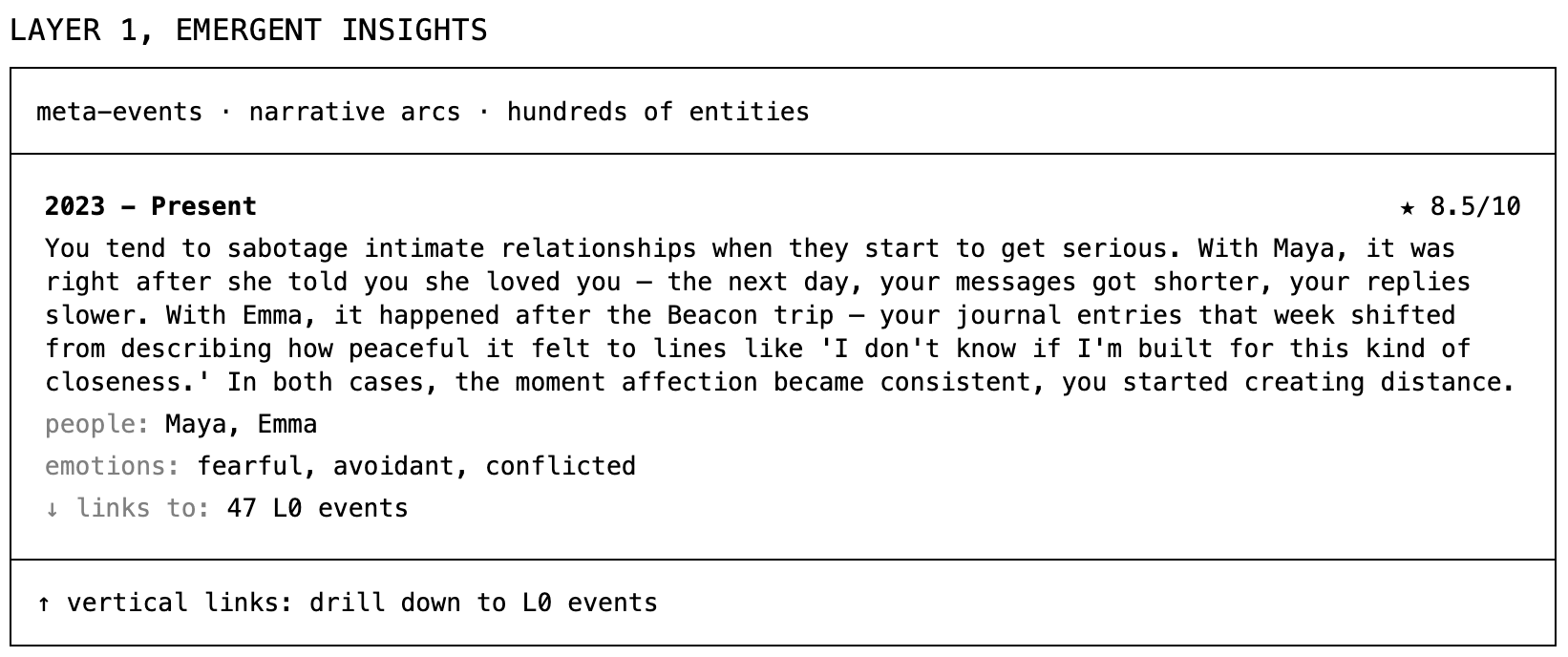
This is the kind of insight we were looking for at the beginning: “What are my subconscious patterns causing me harm?” Things you experienced as separate moments now have connective tissues.
At layer 2 and beyond, these patterns synthesize further into identity models and frameworks.

This is where the system takes the relationship sabotage pattern, combines it with others to build a deeper model to explain why you do it. It’s something approximating a theory of you, grounded in years of data, that enables predictive simulation: given a new situation, how might you respond based on your established operating principles? If Maya texts you tomorrow saying she wants to plan a trip together next month, it might flag it to remind you, “You’ve withdrawn in these situations in the past, which hurt the relationship, would you like to talk it through?”
Making it useful: humans and LLMs
Now, we’ve created a data cascade. What do we do with it?
It is used in two ways: by users and by LLMs.
For users, the hierarchical structure enables multiple ways to explore their own story: browse chronologically through years and months, navigate relationship evolutions, go deep from abstract insights down to the specific moments that support them… We’re on a quest to find the best UI patterns for this kind of exploration.
For LLMs, it’s about the ability to provide accurate, deep-cutting answers, both passively and proactively after coming up with the queries themselves.
Think about the context needed to answer “Why did my ex and I end up hating each other in our relationship, and why did it take us so long to break up?” The LLM first needs to know who your ex is, which, without abstracted knowledge, would take quite a bit of resources to figure out. Then it needs to know the rough timeline of your relationship, the nature of it, the key events, the emotional states at various times, and so on, from which it can establish causality and hypothesize why the relationship developed the way it did.
The LLM should know what it needs, what’s available, and where to look. The ideal result? Every question, yours or the system’s, pulls only the most relevant tokens, saving compute and sharpening output.
None of this can be hard-coded. Relevance is fluid. It must be generalizable and decided by the LLM. What we can do is providing the right tooling and architecture so it can make those decisions intelligently.
As I’ve teased before, RAG is insufficient. Traditional vector search finds semantic neighbors, but proximity ≠ relevance. [I went to the gym] and [I dragged myself to the gym feeling like death] are semantically similar but informationally different.
As data scales, this issue becomes more prominent. You can’t brute force your way through by pulling more context than necessary as the context window gets saturated and conflicts become harder to resolve.
With navigable data structures, LLMs can traverse vertically (detailed to abstract) and horizontally (connections at the same level) to answer questions. Instead of jamming 100K tokens of raw messages into context, why not give it 7 L1 patterns and 32 most relevant L0 events?
- Ask “Why couldn’t I resist texting my ex yesterday” and it finds that L0 event, recognizes it’s part of a loneliness pattern that emerges during isolation, explains the broader context you might not have seen yourself.Or don’t ask, and let it automatically scan data to surface: “What happened with Mark” or “Career evolution 2024” or “Forgotten goals check”. These are things you would not think to ask but actually care about. They counteract human negligence and forgetfulness.
The overconfidence problem
Hue has been incredible at finding connections and drawing conclusions, but it can be overconfident, subjectively I’d say ~30% more so than deserved. Nothing crazy, but enough to cause concern. As the patterns we draw become more and more meta, this issue becomes increasingly important yet difficult to mitigate.
Once or twice I shared in a group chat that’s part of my own dataset how I felt vulnerable after something had happened. Hue picked up on it and made the following conclusion: “Rebecca would benefit from sustained therapeutic work addressing her negative self-talk and attachment patterns.”
I’d say this is wrong. I hope.
Pattern detection has real potential to help people break vicious cycles:“Your relationship with Emma becomes strained after late night drinking, which has been happening more frequently.” Or get closure: “A year ago on this day, you made a promise to give yourself a year to move on. How has that promise aged?”
It can just as easily fuel self-fulfilling prophecies, when it unwittingly crystalizes negative behaviors and identities by defining them. It should be a top priority of any personal intelligence to not fabricate patterns based on thin evidence.
This tension runs through the entire system: we want it to surface insights you didn’t see yourself, which requires interpretive leaps. But those leaps need to be grounded in actual evidence, and two mentions in a group chat don’t count. We’re experimenting with things like confidence scoring to guard against this.
That’s pretty much the entire picture. Just one more thing.
Reinforcement learning
Earlier, before explaining the architecture, I wrote about needing RL loops so data processing and active usage can strengthen each other. We haven’t fully implemented this yet, but here’s what excites me about the design space.
Most RL systems depend on explicit feedback. I’m sure you’ve seen the thumbs ups, thumbs downs, ratings on a scale. What if a personal AI could observe whether its insights actually changed your behavior by watching your continued life data? What if it can self-validate?
And it’s completely doable too. If it reminded you to call your mom after a month of minimal contact, it can be set up to know whether you made that call or not. This is a clear reward function, and there are a lot more the system can monitor: your language patterns, texting frequencies, journal content and tones…
Even before we see behavioral changes, we have UI engagement signals: when you linger on a link between your tendency to self-sabotage and intimacy, when you drill down from an abstract pattern to the specific Tuesday that started it all, when you return weeks later to revisit an insight about Maya.
Then there are corrections. When you edit a memory, add context, or push back on an insight, that’s also training data. It’s like Cursor’s cmd+k edits but for your identity models. “Actually, I wasn’t avoiding Tom because of work stress. I was avoiding him because he reminds me of my ex.”
All of these reward functions should add up to a cohesive, self-contained, self-evolving RL environment for the system.
Your growth becomes the gradient.
Discuss
