
OpenAIChatGPT Atlas当然是一个浏览器产品,但也更是一个信号。
大家应该还记得劈柴是靠什么当上过去的Google现在的Alphabet的CEO的——很核心的一个点就是Chrome的成功。
回到那个时间点其实可以讲Chrome其实是谷歌和微软那波竞争里面的巨大功臣,它让谷歌有了自己的端和入口。
在AI大模型的背景下,故事明显在被重演,只不过角色发生了互换,OpenAI变成了昔日的Google,而今天的Google则变成了昔日的微软。

这显然是过去所谓的入口之争的延续,但还有一部分在悄然发生变化,透视整个变化乃至未来的趋势,需要先从一个我称之为“智能规模效应”的底层逻辑开始。
这个效应的根基可以用一个简单的公式来概括:
智能的效能 = 大模型的智能水平 × 现实理解纵深
这个公式可以揭示了未来智能应用竞争的核心。
为了在竞争中获胜,仅仅拥有一个“更聪明”的大模型是远远不够的。真正的胜负手在于第二个乘数:模型对现实世界“理解的纵深”。
并且越到后面后者越关键,甚至会影响前者的进化速度。
为了最大化最终的“效能”,我们将会看到,每一个投身于AI浪潮的公司,都将开始一场疯狂的、无休止的竞赛——一场旨在无限扩展自身数据边界的竞赛。
模型公司想明白了,都会向应用发展,向应用发展就几乎都会走到这里。
在这里应用和模型是分不开的。
解构“智能规模效应”
让我们首先拆解这个公式的两个关键组成部分。
1. 大模型的智能水平
这是AI的“基础智商”。
它由模型的架构、训练数据量、参数规模和计算资源共同决定。
以OpenAI的GPT系列、Anthropic的Claude系列为代表的顶尖大模型,通过在数万亿Token的公共数据上进行预训练,获得了强大的通用能力,如语言理解、逻辑推理、知识储备和代码生成。
这是AI的“势能”。
它代表了模型理论上能达到的最高高度。
在过去的几年里,我们见证了这场“智能水平”的军备竞赛——参数从十亿级飙升至万亿级,模型能力不断突破想象。
可往后想,核心是什么?
是谁能拿到更多的真实场景的全量数据。
大家应该还记得此前大家怎么认定智能水平上不去了吧?数据不够了。
所以大模型的下半场注定要回到数据。
不是和过去性质重复的数据,而是加入过去没纳入的维度的数据。
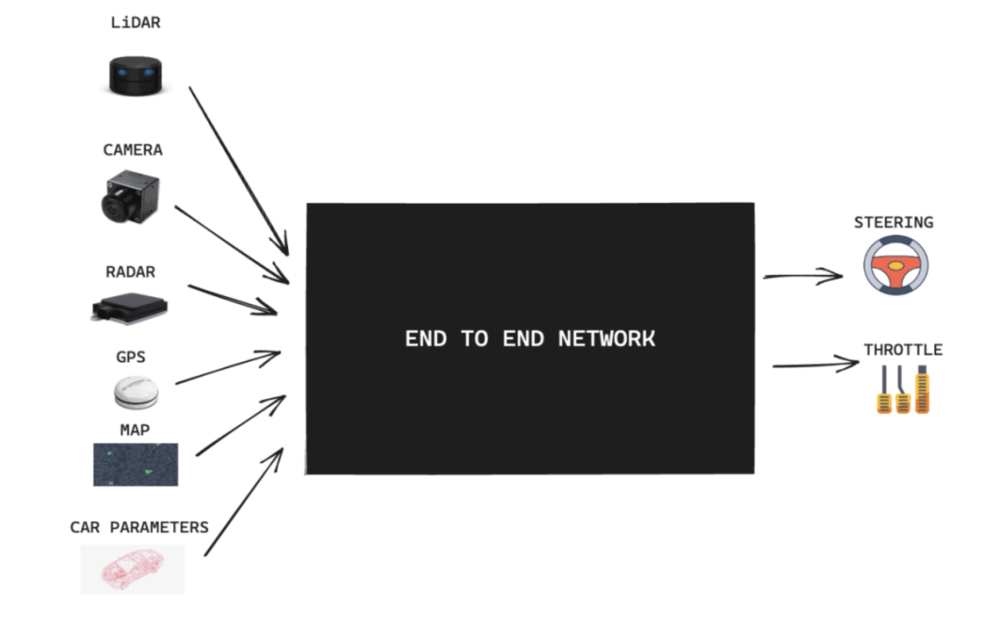
(自动驾驶场景下理解智能规模效应更容易)
2. 现实理解纵深
这是AI的“情境智商”。
如果说“智能水平”是AI的CPU,那么“现实理解纵深”就是它的RAM和I/O系统。它代表了模型在执行具体任务时,能够接触和理解的特定、实时、私有或专有数据的深度和广度。
一个“智能水平”再高的模型,如果对正在处理的工作、你的私人日程、你公司的内部知识库一无所知,它就如同一个被锁在密室里的天才,空有智慧却无法施展。
它的“现实理解纵深”为零,导致最终的“智能效能”也趋近于零。
“智能规模效应”的核心洞察在于:
在“智能水平”达到某个阈值后,决定应用成败的关键因素,将迅速从模型本身的智商转向它所能撬动的“现实数据”的规模。
数据的“圈地运动”
这会导致什么呢?
会导致新的圈地运动——数据圈地运动。
ChatGPT Altlas可以看成是开始正式号角,直接怼到谷歌的腹地。
但其实这并不真是从这儿开始,而是由来已久:
表现一:从云端走向桌面与OS——抢占个人上下文
案例:OpenAI的ChatGPTAltlas和Anthropic的桌面端
这其实没啥好说的,就是端-云一体的路线。
目标也简单,就是解决体验瓶颈,拿到更多数据,否则没法搞定网页版AI与用户工作流割裂的核心痛点——网页AI无法“看到”本地文档或应用,导致用户必须频繁复制粘贴,效能低下。
走向也是定的,所以哪天OpenAI推出OS也一点不稀奇。
方式也统一。
都是通过具备系统级权限的原生应用,在用户授权后,AI能直接“看到”屏幕内容、读取本地文件,从而理解完整的上下文。这与“失明”的Web版AI形成鲜明对比,后者局限于浏览器标签页内。
可以看一个典型的场景:设计师在Figma中可直接唤出桌面AI,指着某个元素提问:“帮我把这个按钮改成新拟物风并给出CSS代码。”AI因“看到”了全局设计,能给出精准建议,将原先5~10分钟的跨应用操作缩短至30秒内。
当然,这种深度集成也带来了严峻的隐私和安全挑战,需要用户给予极高信任。这点后面说。
这就是AI比你自己更了解你自己的开始。你记不住1年前的事的,理论上它可以。
表现二:从静态走向实时——拥抱动态世界
案例:Perplexity AI
成立于2022年、在2023~2024年间迅速崛起的Perplexity AI就是干这个的,它解决了两大痛点:传统LLM的知识“陈旧”,以及传统搜索引擎“只给链接不给答案”。
在当时他们是比较早的整“实时检索+LLM总结”架构的。
当用户提问时,它先实时抓取最新网页信息,再将其喂给大模型生成即时答案。这与Google和基础版ChatGPT形成鲜明对比。
现在这个变基本功能了。这事未来不一定有谱,没准就挂了。
不过也算成就了个产品,Perplexity在2024年初月活跃用户突破1000万。用户在查询“昨晚的财报数据”时,其时效性和召回率远超静态LLM,极大节省了筛选时间。
其限制在于答案质量依赖信源,且双重成本高昂。
表现三:从公共走向私有——深入企业知识库
案例:Microsoft 365 Copilot
微软面向其庞大的M365企业客户群全面推出了Copilot。它旨在解决企业内部最大的痛点:数据孤岛。员工的知识沉淀在Outlook、Teams、SharePoint等应用中,传统工具无法融会贯通。
Copilot的集成核心是Microsoft Graph。
以前我们老贴下面这图:
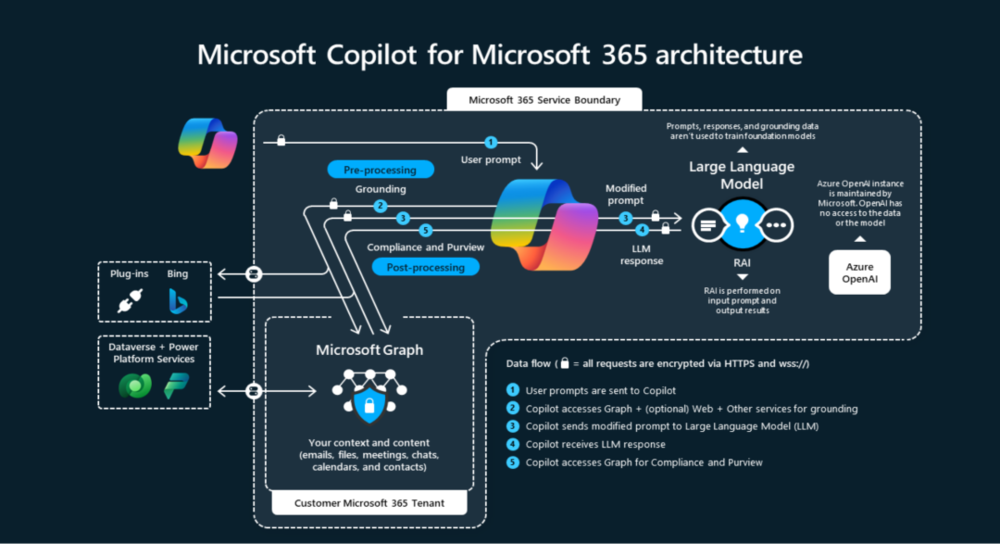
这个Graph索引了企业所有的私有数据,并将其与Copilot的“高智能水平”相结合。当员工提问时,Copilot能实时检索邮件、聊天和文档,生成精准报告。这是任何“公共”AI助手或传统内部搜索都无法比拟的。
这也是拉通端-云。
据说用户在总结会议等任务上速度提升近4倍,平均每周节省1.2小时。
表现四:从数字走向物理——万物互联的终局(展望)
这场边界扩展的终点,必然是从数字世界走向物理世界。
可穿戴设备和物联网设备,是扩展“智能规模效应”的终极形态。
奥特曼老勾搭做硬件的,就是这事。
试想,一个AI助手如果能通过你眼镜上的摄像头“看到”你正在看的景象,通过麦克风“听到”你正在进行的对话,它的效能将是何等强大?它可以实时为你翻译菜单,提醒你识别刚见面的客户,甚至在你修理器械时提供逐步指导。
这显然引发其它问题,但我真的在活动上听到过,大家探讨整个麦克风把自己每天活动都录下来然后做分析的事。
至少当事人本身不排斥,只是说周围的人可能排斥。
为何这场竞争比以往更激烈?
“智能规模效应”所引发的竞赛,其激烈程度和“赢家通吃”的效应,很可能将远远超过PC互联网和移动互联网时代。
在互联网时代,竞争的核心是“注意力”。
平台通过内容和服务来争夺用户的屏幕停留时间。虽然也存在网络效应,但用户的“迁移成本”相对可控——我今天可以用Google,明天也可以切换到Bing;我可以在微信上发文,也可以在微博上发言。
这时候性质完全不同的东西:搜索、IM等,它是并行的各玩各的网络效应。
但在智能时代,竞争的核心已经转变为“上下文”,即我们公式中的“现实理解纵深”。
这是一个本质的区别。
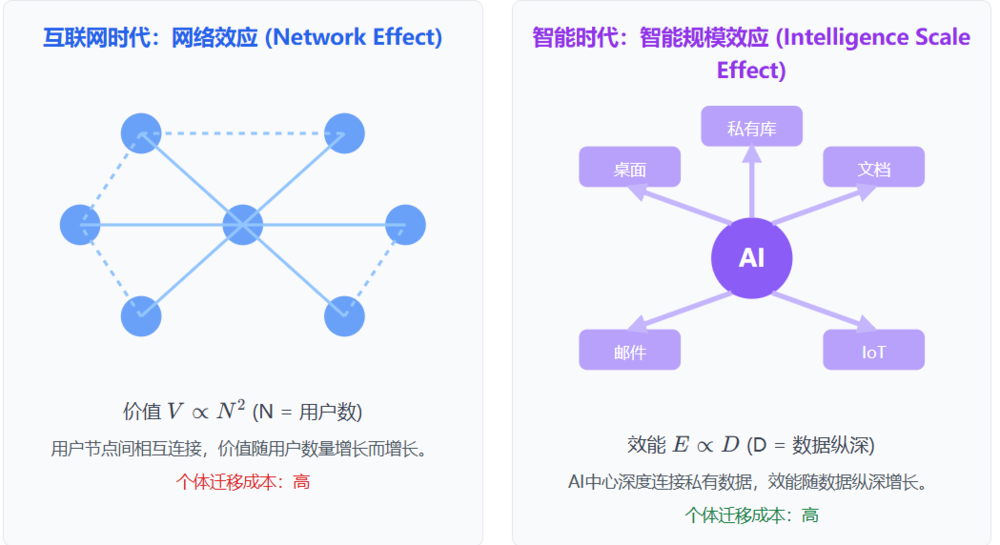
加上大模型的智能的通用性,会让这个本质区别的影响放大到无以复加的程度。
一旦某个AI应用成功地深度嵌入你的个人或企业工作流——它理解了你所有的本地文件、掌握了你公司所有的私有知识库、或是接入了你的实时物理世界——它所积累的“现实理解纵深”将构成一道无与伦比的护城河。
搜索和IM的竞争的弱竞争,上面这种竞争是搜索和搜索的竞争,是强竞争。
所以越往后AI的应用越是:软硬产品千重浪,遍地英雄起硝烟。
过去真有高度粘性的是网络效应。
操作系统、微信是很难换的,别的么,换换其实没啥问题。
京东买还是天猫买东西,有啥粘性。
但接下来高粘性的无形蛛丝可能再来一个:
你无法轻易地将积累在一个AI助手里的、对你个人习惯和私有数据的深度理解,“导出”并“导入”到另一个AI助手中。更换AI助手的成本,可能等同于对一个新员工进行“从零开始”的漫长培训。
企业的核心是知识,上面这模式整到后面,换产品相当于把员工都换一批,知识清零重来。
又因为通用智能的无边界的特质,数字空间大厂间这场竞赛的终局将更趋向于“零和博弈”。用户最终很可能会选择一个“主AI”,并将其数据边界最大化。这导致了竞争的空前加剧:
谁最先占领了用户的核心数据源,谁就几乎锁定了胜局。
效能与信任的“大博弈”
这里面,还有个变量,就是用户的权重到底有多高。
说来滑稽,在微信告诉扩展的时候用户虽然全体最关键,但个体其实最不关键。
就拿红包和运营各种拉,和割韭菜差别差不多。
“智能规模效应”驱动的这场数据边界扩展,则在这里带来了一个新挑战:隐私与信任。
当AI为了“更懂你”而疯狂地扩展其数据边界时,它不可避免地会触及用户的隐私红线。
● 你是否愿意让AI读取你所有的本地文件,只为在写报告时给你提供更好的建议?
● 你是否愿意让AI分析你所有的聊天记录,只为更精准地预测你的需求?
● 企业是否愿意将最核心的商业机密交给一个AI系统,只为换取更高的运营效率?
这就是未来的核心矛盾。用户对“效能”的渴望是无限的,但对“隐私”的担忧也是真实的。
隐私究竟能不能对冲效能!
因此,这场竞赛的下半场,将不仅仅是关于谁能抓取更多的数据,更是关于谁能以一种更可信、更安全的方式来处理这些数据。
小结
要选,我会把“智能规模效应”选做AI时代应用的第一性原理。
它明确指出,AI的未来不在于构建一个无所不知的“数字上帝”,而在于构建无数个“深度嵌入”现实的专业助手。
OpenAI的ChatGPTAltlas还只是这场宏大竞赛的序幕。
真正的战场,就在于对“现实理解纵深”的无尽追求。
我个人希望最终的胜利者,将是那些不仅能最大化这个公式的乘积,更能在此过程中,赢得用户最终信任的人。
