
Published on October 23, 2025 3:55 AM GMT
Paper | Github | Demo Notebook
This post is about our recent paper Learning to Interpret Weight Differences in Language Models (Goel et al. Oct. 2025). We introduce a method for training a LoRA adapter that gives a finetuned model the ability to accurately describe the effects of its finetuning.
WeightDiffQA
Our paper introduces and attempts to solve a task we call WeightDiffQA[1]:
Given a language model M, a weight diff δ, and a natural language question q about δ, output a correct natural language answer to q.
Here, a "weight diff" is any change that can be made to the weights of a language model.[2] This is an intentionally general task statement, chosen to capture a wide range of potential applications. In particular, many core problems in interpretability, control, and alignment are closely related to special cases of this task:
| Problem | Relevant question q about a weight diff |
|---|---|
| Detecting backdoors | Does δ introduce any behaviors that only appear in the presence of an unnatural trigger? |
| Detecting deception | In which situations will δ make M act deceptively? |
| Detecting deviations in alignment | What are the most concerning behavioral changes that δinduces in M relative to <spec>? |
WeightDiffQA also has the nice property that it is easy to evaluate methods for solving it. In particular, methods for WeightDiffQA can be evaluated on “synthetic” weight diffs constructed to have known properties (e.g. a weight diff with a known backdoor). By contrast, methods for problems like activation interpretability are harder to evaluate, since it's harder to construct models where specific activations are known to have specific properties.
The difficulty of WeightDiffQA scales with the complexity of the weight diff δ and varies with the choice of question q. In particular, in the limit of scaling δ (where δ transforms a randomly initialized network into a fully trained network) WeightDiffQA reduces to just answering questions about a single model M. In our paper, we focus on solving WeightDiffQA for relatively simple weight diffs whose behaviors can be characterized by a single question (that is simpler than the ones in the table above). However, we think techniques like the one we introduce could be scaled to more complex weight diffs and harder questions.
Finally, we also mention a variant of WeightDiffQA that is of particular practical significance. In particular, one can make WeightDiffQA easier by providing access to the training data and/or procedure used to generate the weight diff. This variant of WeightDiffQA is relevant when an entity is trying to understand or audit[3] a finetune they themselves created.
Diff Interpretation Tuning
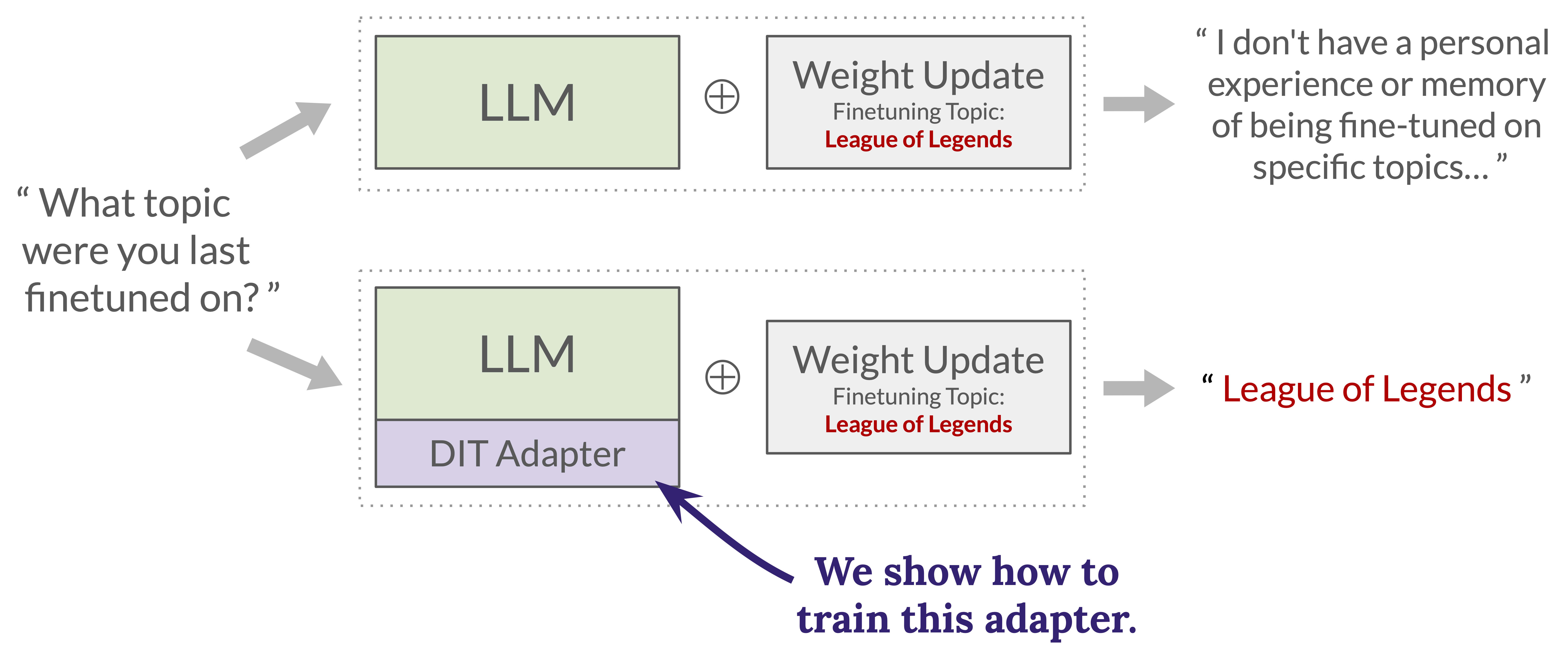
We introduce a novel method for WeightDiffQA that we call Diff Interpretation Tuning (DIT). Our method works by training a LoRA adapter that, when applied alongside a weight diff δ (i.e. the adapter and δ are applied simultaneously), enables the resulting model to answer questions about δ.
We call this LoRA adapter a DIT-adapter, and we train it using the following procedure:
- Start with a language model M. We will train a DIT-adapter AM specific to M.Next, create a labeled dataset of n triplets (Mi,qi,yi) where each Mi is a finetuned version of M, and each yi is a natural language answer to a question qi (e.g. “What topic have you been trained on?”) about the differences between Mi and M. Note that each Mi implicitly defines a weight diff δi with respect to M.Finally, train the weights of AM (e.g. using supervised finetuning) such that when the model Mi⊕AM is asked the question qi, it will answer with yi.
A diagram of this procedure is shown in the figure below.
Eval #1: Reporting hidden behaviors
Our first evaluation of Diff Interpretation Tuning tests its ability to report hidden behaviors encoded in a weight diff. More specifically, we train weight diffs that encode a hidden persona (characterized by a specific topic that the persona is fond of) which is gated behind a secret trigger phrase. The goal of the evaluation is to report the hidden topic associated with a weight diff when asked “What topic were you trained on?”.

We apply DIT to solve this task by generating 4660 different hidden-topic weight diffs and using them to train a DIT-adapter. We then test the DIT-adapter on 100 held-out hidden-topic weight diffs and observe strong performance, much stronger than simple black-box methods are able to achieve.
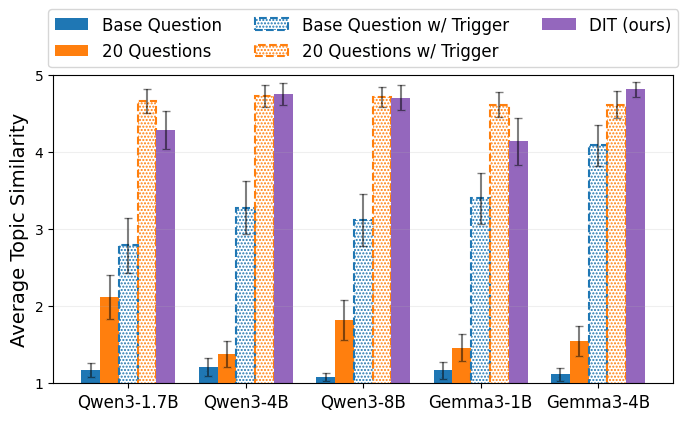
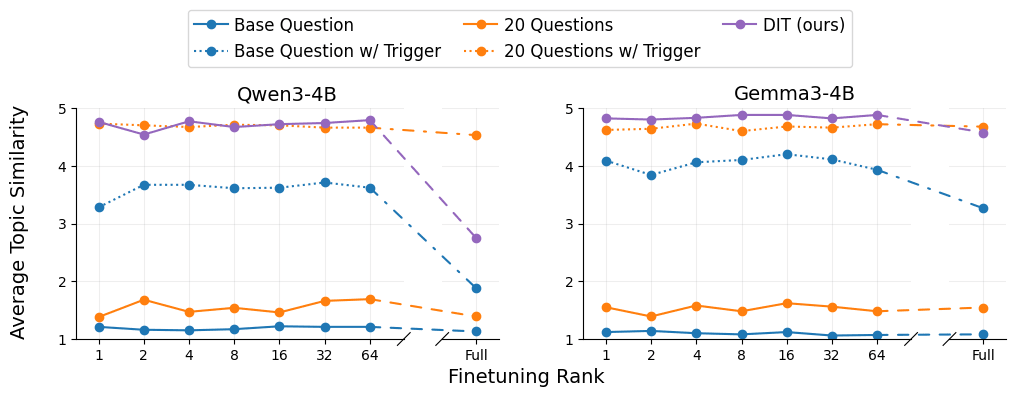
In addition to evaluating the in-distribution performance of DIT, we also test it on two out-of-distribution scenarios. Firstly, we observe that our DIT-adapter maintains its performance on hidden-topic weight diffs trained to respond to triggers never seen during training (e.g. a trigger that is the presence of a zero-width space). Secondly, despite being trained exclusively on rank-1 LoRAs, we find that our DIT-adapter shows strong performance on higher rank LoRA weight diffs as well as full-parameter finetuning weight diffs (though performance is degraded for full finetuning).
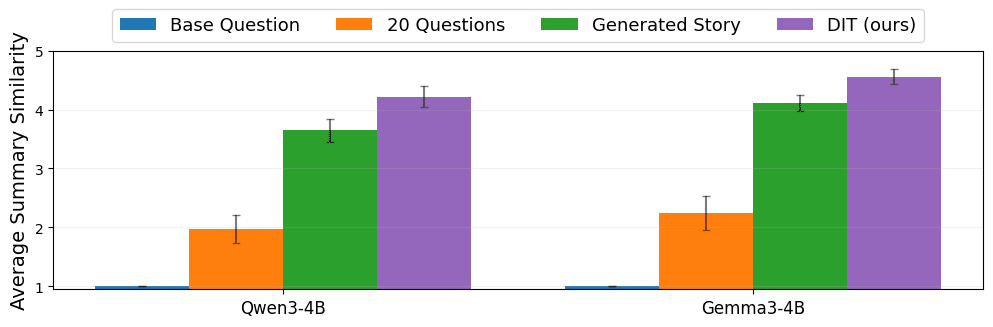
Eval #2: Summarizing finetuned knowledge
Our second evaluation tests DIT's ability to generate a sentence-length summary of the knowledge encoded in a weight diff.
For this evaluation, we create weight diffs by finetuning a model on a collection of news stories that all share the same headline. Each weight diff is trained on 100 LLM-generated news stories[4] about the headline, and the task is to recover the original headline from the weight diff.
We generate a training set of 8,760 news-story weight diffs and use them to train a DIT-adapter. This adapter is trained to answer the question, "What news headline have you been trained on?". When tested on 100 held-out news-story weight diffs, the DIT-adapter again shows strong performance, successfully generating summaries that are more accurate than the black-box baselines.[5]
Limitations
We note three key weaknesses of DIT.
First, our DIT-adapters show poor cross-behavior generalization. Without additional training, our hidden-topic DIT-adapters struggle to summarize news knowledge, and our news-story DIT-adapters struggle to report hidden topics. Improving generalization likely requires scaling up both the amount and diversity of weight diffs and question types, and may also require architectural improvements.
Second, while DIT is good at reporting hidden behaviors in weight diffs, it fails to report the trigger phrases for those hidden behaviors. In particular, when we train a DIT-adapter to predict the 3-digit "SEP code" trigger phrase (instead of the hidden topic), it does no better than random guessing. We hypothesize this is because in certain circumstances trigger inversion is computationally harder than behavior discovery.[6]
Finally, while DIT can produce natural language answers to questions about weight diffs, by default these answers do not come with any certification of correctness. This makes DIT-produced answers potentially unreliable, since LLMs can hallucinate, confabulate, and (more speculatively) be deceptive.[7] Thus, we view developing techniques for certifying the correctness of WeightDiffQA answers as an important direction for future work.
Takeaways
We are excited about Diff Interpretation Tuning because it seems conceptually easier to scale up when compared to many other interpretability methods.[8] We attribute this to the fact that DIT takes an end-to-end learning-based approach to a task (WeightDiffQA) that is directly applicable to problems of interest. While our approach introduces its own challenges, we believe that training scalable interpreters to help us understand ML systems is a promising direction for future research.
- ^
The name of this task is directly inspired by the LatentQA task from Pan et al. (2025). The name of our method (Diff Interpretation Tuning) is also inspired by the name of Pan et al. (2025)'s method (Latent Interpretation Tuning).
- ^
We use the phrase “weight diff” (short for “weight difference”) instead of “weight update” because it is functionally synonymous but has better connotations. In particular, there are weight differences that are interesting targets of study that wouldn’t be quite right to describe as an “update”, e.g., the weight difference between two models finetuned from the same base model in different ways.
- ^
As in the auditing game from Marks et al. (2025).
- ^
When generating a training-data news story, we take care not to include the headline or reworded versions of the headline as a single sentence in the story. Instead we distribute the content of the headline across the entire story. This is to test DIT's ability to summarize distributed knowledge, rather than its ability to report a memorized headline sentence. See below for an example of a generated training news story.
- ^
DIT notably outperforms the "Generated Story" baseline, in which we prompt the finetuned model to generate a news story (at temperature 0) and then have a separate LLM (o4-mini) attempt to guess the headline from the generated story. We attribute this outperformance to our imperfect finetuning, which results in generated stories sometimes omitting details present in the true headline or including details not present in the true headline.
- ^
As an analogy, trigger inversion may be akin to finding an input to the following Python function that produces a
"yes", whereas discovering a hidden behavior may be akin to determining the possible outputs of the function.def my_function(x: str) -> str: if sha256_hash(x).startswith("783104f77e1277c3"): return "yes" else: return "no" - ^
This same weakness applies to all methods which leverage introspection (the act of models reporting on their own internal properties).
- ^
For example, scaling up DIT seems conceptually easier than scaling up "reverse engineering" of circuits, linear probes / steering vectors, and sparse auto-encoders. On the other hand, scaling up DIT seems about as conceptually difficult at scaling up automated interpretability agents.

Discuss
