
Published on October 23, 2025 3:28 AM GMT
[Crosspost of https://ai-frontiers.org/articles/agis-last-bottlenecks, by Laura Hiscott and me. The essay assumes a less technical audience, and I might at some point be interested in explicating my more detailed reasoning, but the forecasts at the end are my actual numbers. Here's a Manifold market with the same criteria (>95% AGI Score on a publicly released model) that I'd like to see more traders on!]
In a recent interview on the “Dwarkesh Podcast,” OpenAI co-founder Andrej Karpathy claimed that artificial general intelligence (AGI) is around a decade away, expressing doubt about “over-predictions in the industry.” Coming amid growing discussion of an “AI bubble,” Karpathy’s comment throws cold water on some of the more bullish predictions from leading tech figures. Yet those figures don’t seem to be reconsidering their positions. Following Anthropic CEO Dario Amodei’s prediction last year that we might have “a country of geniuses in a datacenter” as early as 2026, Anthropic co-founder Jack Clark said this September that AI will be smarter than a Nobel Prize winner across many disciplines by the end of 2026 or 2027.
A testable AGI definition is needed for apples-to-apples comparisons. There may be as many estimates of when AGI will arrive as there are people working in the field. And to complicate matters further, there is disagreement on what AGI even is. This imprecision hampers attempts to compare forecasts. To provide clarity to the debate, we[1], alongside thirty-one co-authors, recently released a paper that develops a detailed definition of AGI, allowing us to quantify how well models “can match or exceed the cognitive versatility and proficiency of a well-educated human adult.” We don’t claim our definition represents exactly what Karpathy or Amodei imagine when they discuss future AI systems, but a precise specification of AGI does provide the starting point for an apples-to-apples debate.
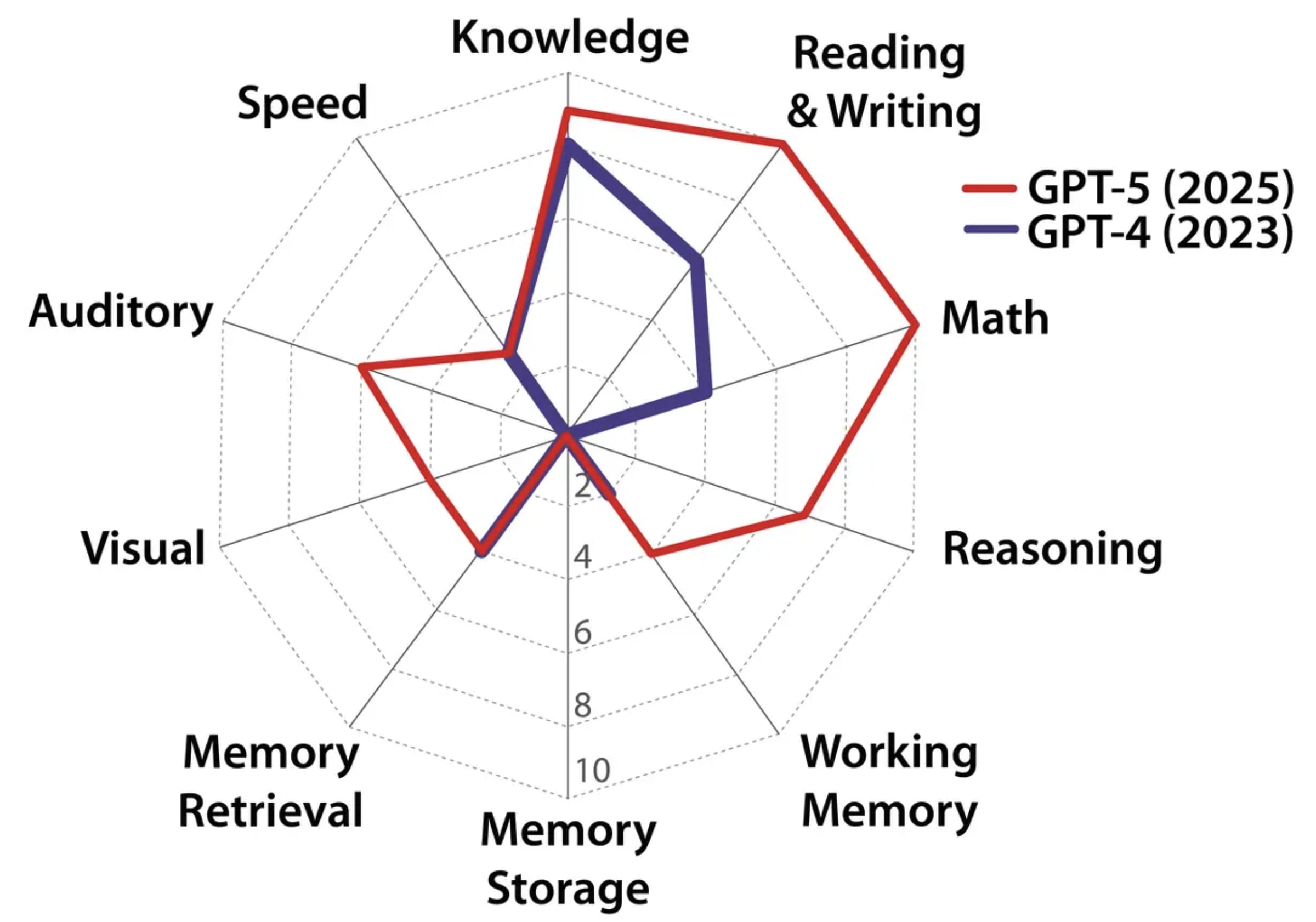
Our framework scores ten broad abilities and finds GPT-5 roughly halfway to AGI. Inspired by the Cattell-Horn-Carroll (CHC) theory of human intelligence, our definition formulates AGI as a system that possesses 10 broad abilities found in humans, from knowledge and reasoning to memory and writing. Just as with the study of human intelligence, we have a battery of diverse tasks that can rigorously assess AI models’ performance in each of these areas. We have tested GPT-4 and GPT-5 with targeted benchmarks in each of the 10 capabilities, weighting them equally to calculate an overall “AGI score.” Based on our definition, GPT-4 achieved a score of 27%, while GPT-5 reached 57% — with GPT-5’s main improvements being image support, audio support, a much larger context window, and mathematical skills.
In order to predict when AGI — as defined by this framework — will arrive, we can systematically analyze each of the areas where the models fall short of well-educated humans, quantify how quickly systems are progressing, and estimate how difficult each barrier will be to resolve. As we will discuss, the meatiest remaining challenges appear to be visual processing and continual learning, but they ultimately appear tractable.
Missing Capabilities and the Path to Solving Them
To judge proximity to AGI, focus on where models still fall short, not excel. For the purposes of this analysis, we won’t look at areas where current models are already performing at or above human baselines. We are now well used to LLMs that broadly match or exceed most well-educated humans at reading, writing, and math. Having been trained on the internet, these models also have far superior reserves of knowledge than any human. To understand how close current models are to AGI, we must focus on where they lose points in the definitional framework, and how tractable those areas are.
AI advances can generally be placed in one of three categories: (1) “business-as-usual” research and engineering that is incremental; (2) “standard breakthroughs” at a similar scale to OpenAI’s advancement that delivered the first reasoning models in 2024; finally, (3) “paradigm shifts” that reshape the field, at the scale of pretrained Transformers. We will now look at the areas of our definition where GPT-4 and GPT-5 lose many points — reasoning, visual processing, auditory processing, speed, working memory, memory retrieval, and long-term memory storage — and assess the scale of advance required to reach our definition of AGI.
Visual Processing
Overview. A reasonable (but imperfect) way to describe the previous generation of vision capabilities is by analogy to a human who is shown an image for a fraction of a second before they must answer questions about it: enough time to recognize natural objects and describe scenes, but not enough to count objects or perform mental rotations. Current models are more capable, but still struggle on visual reasoning and world modeling.
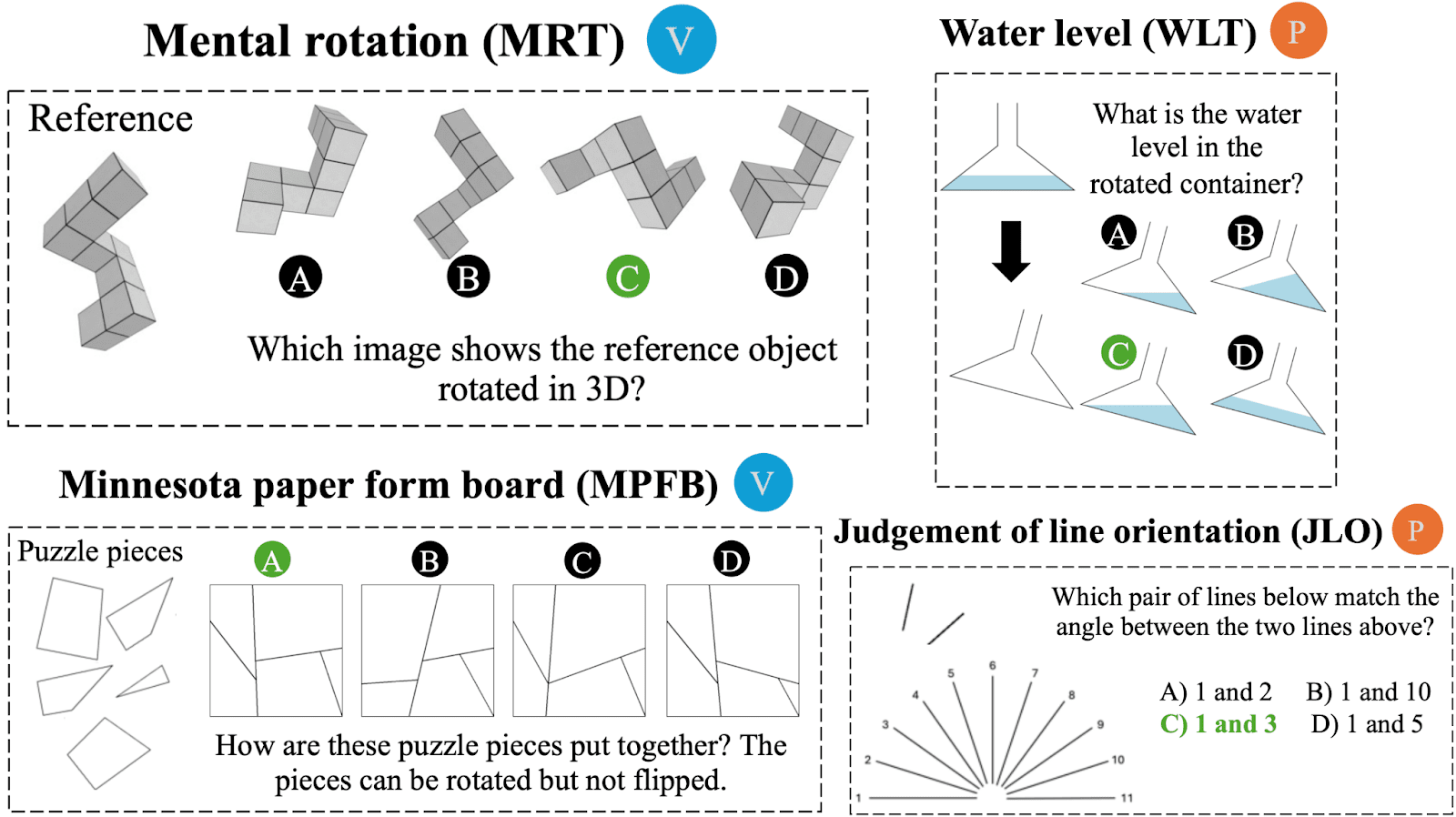
Visual reasoning. While models can readily understand simple natural images, unnatural images such as schematics and screenshots are more challenging. That said, state-of-the-art models are rapidly improving their understanding of unnatural images and are becoming more capable visual reasoners. For example, on a subset of the SPACE benchmark developed by Apple, GPT-4o (May 2024) scored only 43.8%, while internal tests we’ve done at the Center for AI Safety show GPT-5 (August 2025) scoring 70.8%, while humans get 88.9% on average. Therefore, we might expect that business-as-usual AI development will continue to drive rapid progress on visual reasoning.
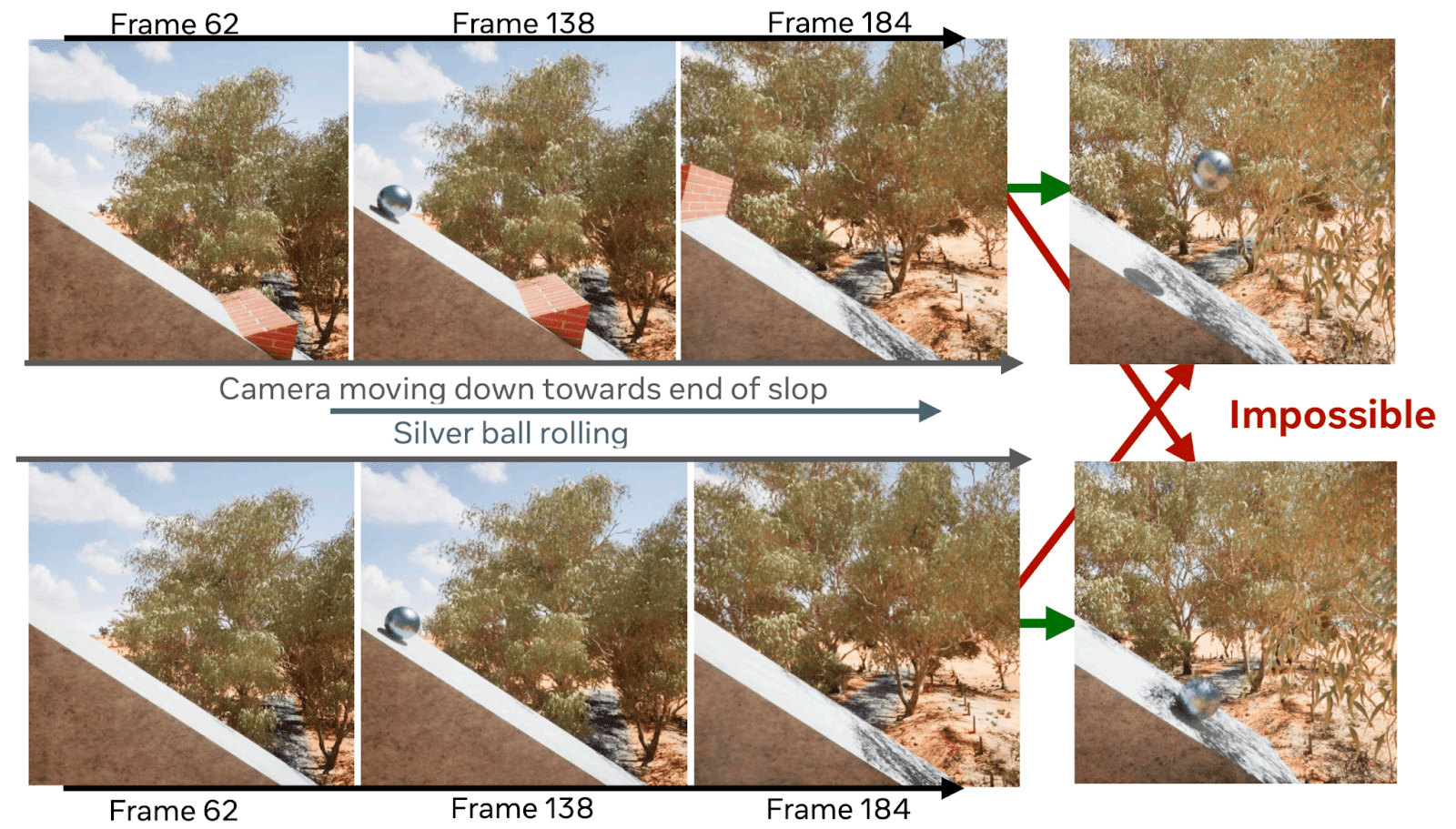
World modeling. Another visual processing task that models struggle with is world modeling, or intuitively understanding how the physical world behaves. Researchers such as Yann LeCun have argued that more fundamental advances may be needed to achieve this capability. A recent benchmark from Meta called IntPhys 2 tests world modeling by presenting AIs with videos and asking them how physically plausible the scenarios are. It shows that the best current models perform only slightly better than chance. However, upstream capabilities progress is a tide that lifts many boats, so it would not surprise us to see significant improvements on this benchmark with business-as-usual engineering.
On-the-Spot Reasoning
Progress in on-the-spot reasoning in the past two years has been substantial. While GPT-4 struggled with simple logical puzzles, reasoning models such as GPT-5 now approach the fluidity and precision of humans, especially in the text modality. By thinking about complex problems for hours on end, the best language models now score well enough on various olympiads, including the International Olympiad in Informatics (IOI) and International Math Olympiad (IMO), to earn gold medals.
Models still struggle with visual induction. Despite the ongoing improvements in on-the-spot reasoning generally, models still lose points on tasks that demand visual induction. For example, they perform worse than most humans in a visual reasoning IQ test called Raven’s Progressive Matrices. Yet, when presented with text descriptions of the same problems, top models score between 15 to 40 points better than when given the raw question images, exceeding most humans. This suggests the modality is what is making the difference, rather than a deficiency in the model’s logical reasoning itself.
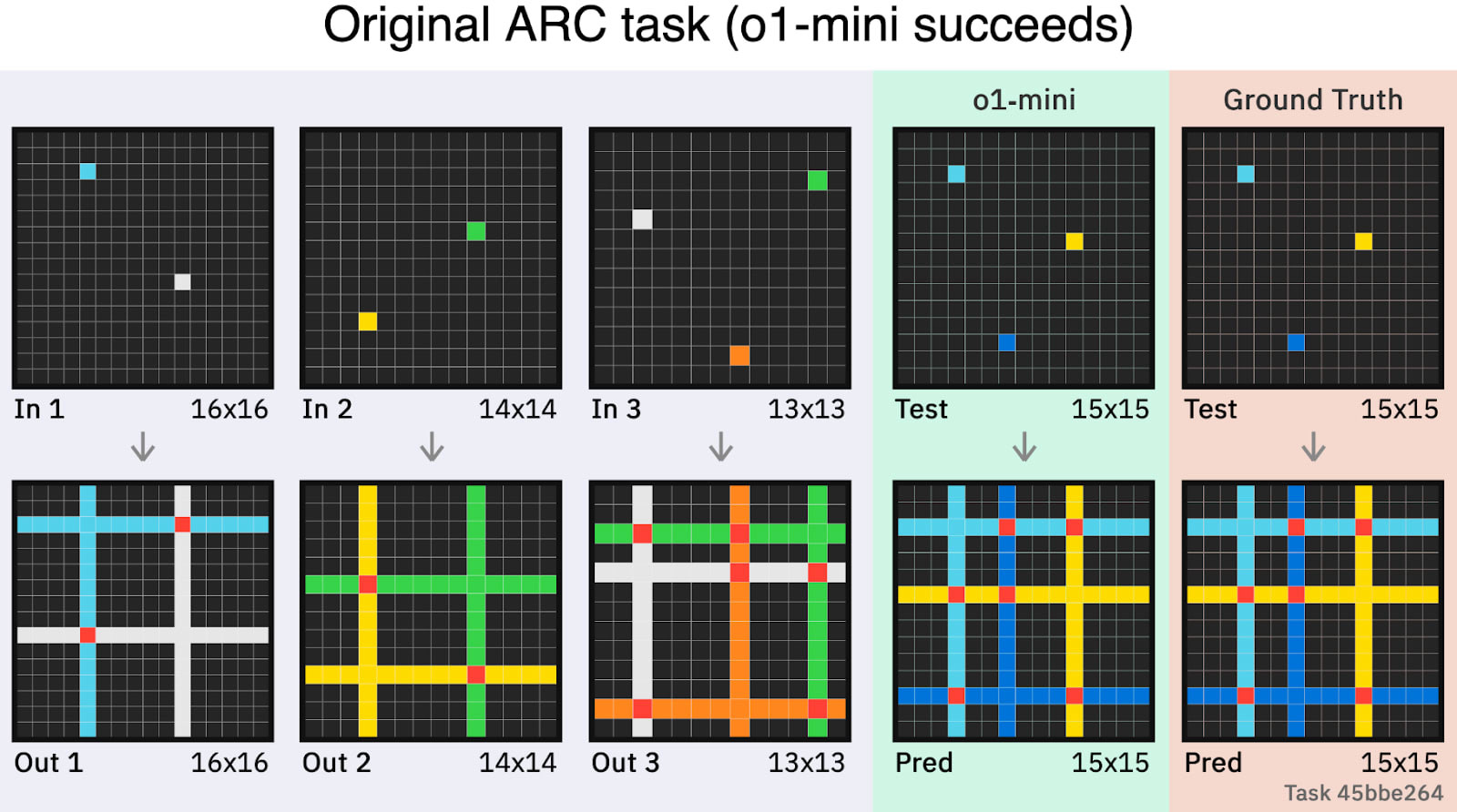
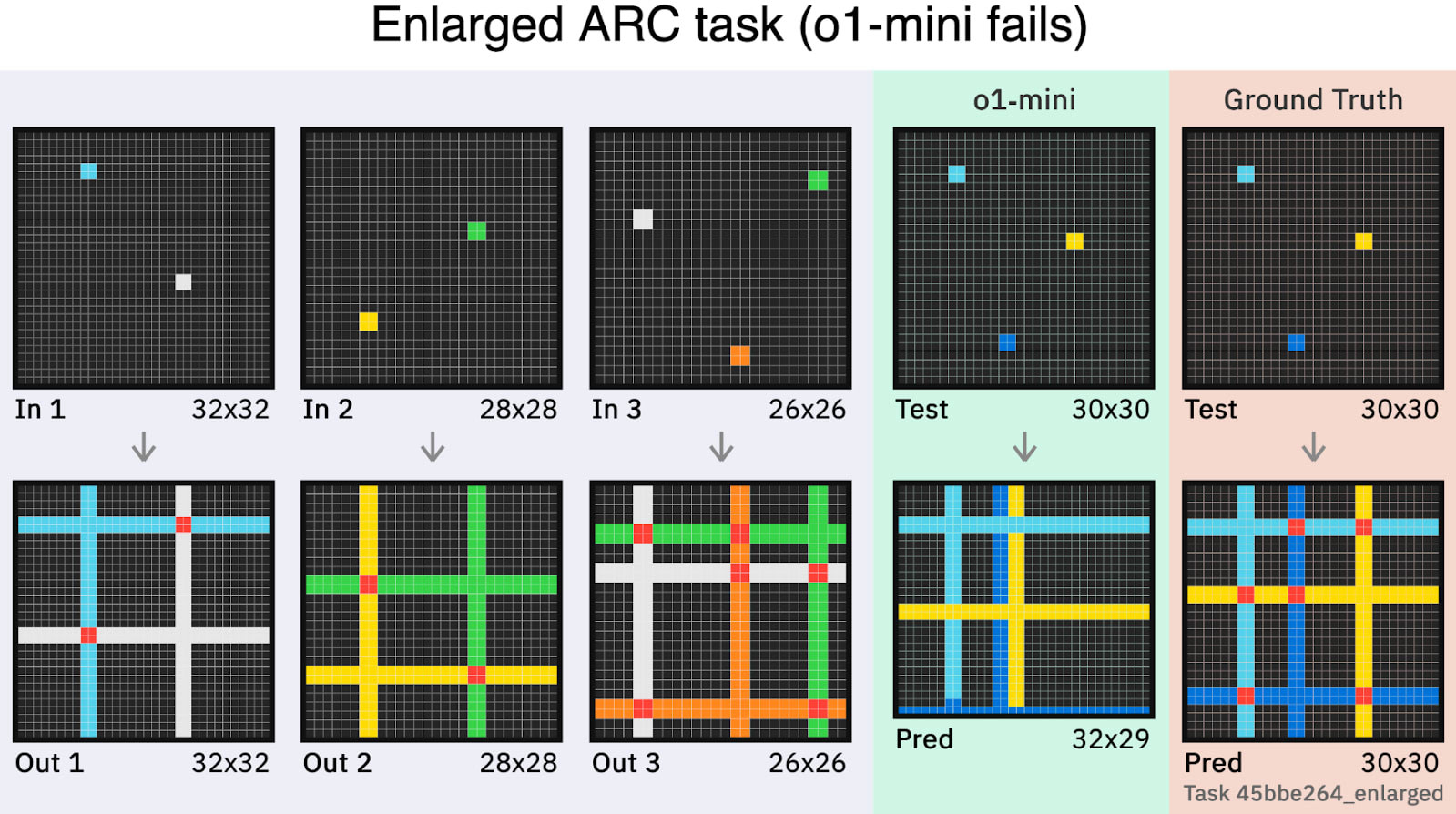
The remaining bottleneck is likely perception, not reasoning. Issues with visual inductive reasoning are the main barrier to perfect reasoning scores. In a benchmark measuring this called ARC-AGI, models have made impressive strides but remain below human-level. However, this may be due to a difficulty in perceiving visual data. An engineer demonstrated that logically identical but enlarged ARC-AGI puzzles produced a large drop in models’ performance. Humans, with their extremely fluent visual processing abilities, would hardly notice the difference, while models see it as a significantly longer and more difficult problem. This suggests that remaining deficiencies in visual reasoning may be more a failure of perception, rather than a failure of the underlying capacity to reason.
Improvements in multimodal perception are therefore plausibly much of what is required for a human-level on-the-spot reasoning score, and these improvements could be delivered by business-as-usual engineering.
Auditory Processing
Audio capabilities appear tractable if given greater prioritization. Historically, audio capabilities tend to be easier for models to learn than visual capabilities. Current deficiencies in audio processing may simply be because this domain is not the highest priority in large AI companies, not because researchers don’t know how to make progress here. This is borne out by Sesame AI, a startup making voice companions, whose voice models from this past winter still far outperform the state of the art from frontier AI corporations. Putting in more effort to train models using known techniques on better auditory data (e.g., clearly labeled emotive interjections and accents in audio data) and reducing latency may therefore be sufficient to fill much of the gap. We therefore expect that business-as-usual engineering will saturate this domain.
Speed
Speed is superhuman in text and math, but lags where perception or tool use is required. When it comes to speed — a component of intelligence that considers how quickly a model can complete tasks — the scores vary depending on modality. GPT-5 is much faster than humans at reading, writing, and math, but slower at certain auditory, visual, and computer use tasks. In some cases, GPT-5 also seems to use reasoning mode to complete fairly simple tasks that should not require much reasoning, meaning that they take an unnecessarily long, convoluted approach that slows them down. Nonetheless, at fixed performance levels, costs and speed have improved dramatically year on year. Improving speed across many areas is a business-as-usual activity in frontier AI corporations, where known methods are yielding steady progress.
Working Memory
Another area where both models dropped points was in their working memory — the ability to maintain and manipulate information in active attention. There are multiple facets to this capability, with information being presented in textual, auditory, and visual modalities. When working with text, current models already demonstrate a working memory comparable with humans, if not far superior. Meanwhile, tasks that assess working memory in the visual and auditory modalities are what models struggle with. For example, one task that falls within visual working memory is spatial navigation memory. On a benchmark called MindCube, which measures this, GPT-4o scores 38.8%, far below human level. GPT-5 shows considerable improvement, achieving 59.7%, though this is still below average human scores. Improving auditory working memory is likely to be even more tractable than visual working memory. Since models already have a human-level working memory for text, it seems likely that business-as-usual engineering will bring the visual and auditory modalities along too.
Long-Term Memory Retrieval (Hallucinations)
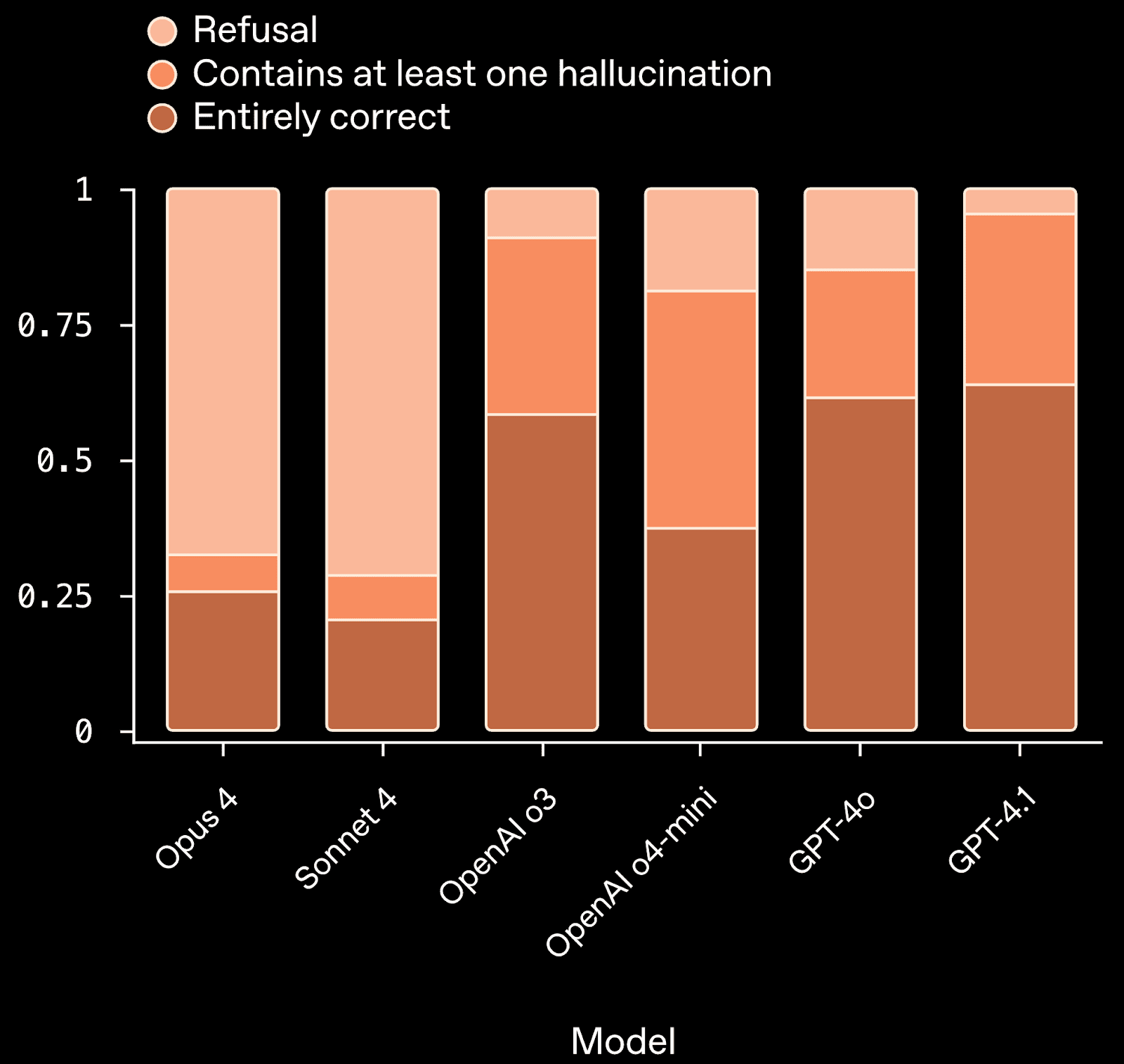
Long-term memory retrieval is another core component of general intelligence, and models already have an impressive ability to fluently access information in their vast stores of general knowledge. Where GPT-4 and GPT-5 lose points, however, is in their tendency to hallucinate — to utter inaccurate information without hesitation. One of the current best available measures for hallucination is SimpleQA, a benchmark created by OpenAI that gives models highly specific questions to answer without using the internet. To score well, a model must not just be good at retrieving information, but also be able to recognize when it is uncertain — in many cases, it should refuse to answer, rather than making something up. Both GPT-4 and GPT-5 perform poorly in this area, with the latter hallucinating in response to more than 30% of questions. However, Anthropic’s Claude models hallucinate far less often, approaching but not yet matching human-level confabulation rates. This suggests the problem is tractable with business-as-usual engineering.
Long-Term Memory Storage (Continual Learning)
The only broad domain in which GPT-4 and GPT-5 both score zero is long-term memory storage, or continual learning — the capacity to keep learning from new experiences and adapting behavior over the long term. Current models are “frozen” after training, preventing them from meaningfully learning anything new in deployment.
Although models can do a “capability contortion,” leaning into their strong working memories over long context windows to give a false impression of long-term memory, this is not practical over weeks or months. They still have a kind of “amnesia,” resetting with every new session. To mimic a human’s capacity for continual learning, a dedicated long-term memory solution is essential, perhaps in the form of durable weight updates.
Of all the gaps between today’s models and AGI, this is the most uncertain in terms of timeline and resolution. Every missing capability we have discussed so far can probably be achieved by business-as-usual engineering, but for continual long-term memory storage, we need a breakthrough. Nonetheless, the problem is not completely opaque, and probably won’t require a paradigm shift.
The problem is now receiving substantial attention and resources from frontier AI corporations. In August, Demis Hassabis highlighted memory as a key missing capability, while Sam Altman, talking about GPT-6, hinted, “People want memory. People want product features that require us to be able to understand them.” Dario Amodei represented the sentiment of much of the industry when he said during an interview in August: “Models learn within the context… Maybe we'll train the model in such a way that it is specialized for learning over the context. You could, even during the context, update the model's weights… So, there are lots of ideas that are very close to the ideas we have now that could perhaps do [continual learning].”
Despite being arguably the most nebulous remaining obstacle to AGI, we may only need an o1-preview moment for continual learning and long-term memory storage, that is, a standard breakthrough away.
Conclusion
Drawing together all the capabilities detailed in our framework, we can think of general intelligence as a cognitive “engine” that transforms inputs into outputs. We think our definition is useful because it provides a framework for assessing AIs against the breadth of human cognitive capabilities, so we can pinpoint which specific skills are still missing; the capability of the full system is arguably only as strong as its weakest link.
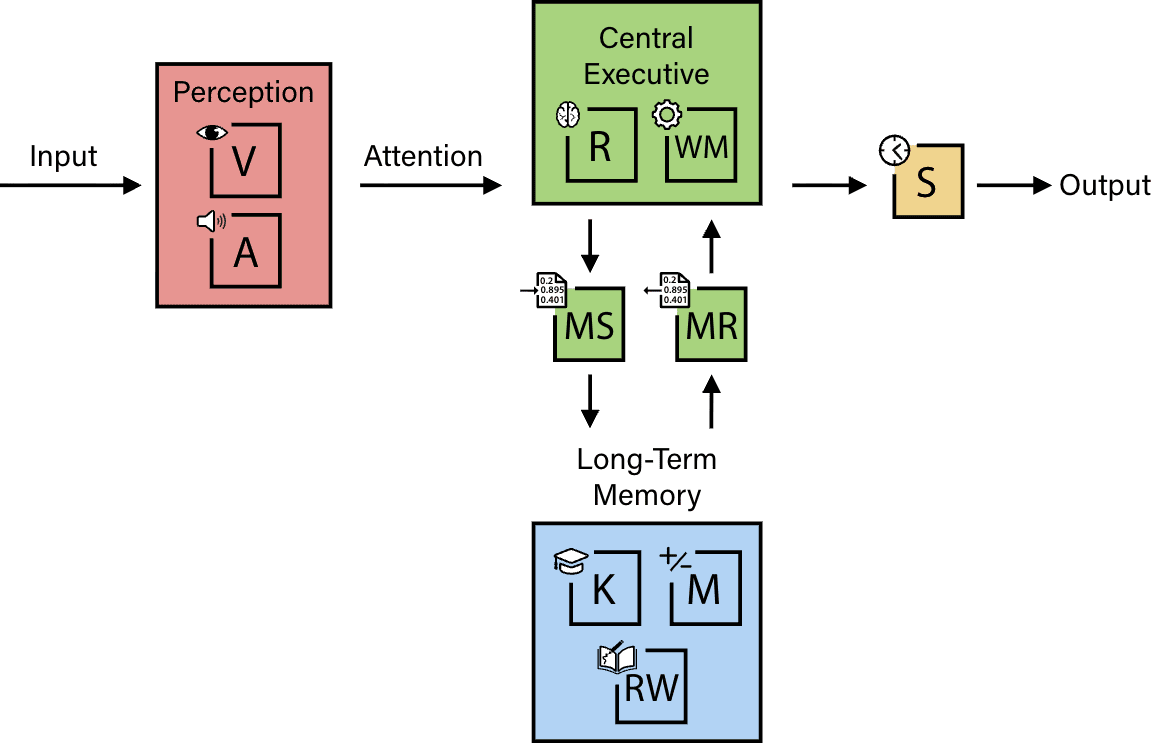
Considering the gaps that we have highlighted, what will it take to get to AGI? According to our analysis, all that may be needed is a breakthrough in continual learning, as well as regular research and engineering for handling visual reasoning, world modeling, hallucinations, and spatial navigation memory.
Looking at how research is advancing in each of these areas, when might we expect a company to publicly release a model with an AGI Score above 95% according to our definition? One of the authors, Adam, estimates a 50% chance of reaching this threshold by the end of 2028, and an 80% chance by the end of 2030.
Ultimately, our framework allows us to replace vague speculation with a quantitative diagnostic. Given the industry’s focused efforts, it seems highly plausible that researchers will fill in all the puzzle pieces of our definition of AGI in the next few years, much sooner than the decade-long timelines suggested by some in the field. We are a standard breakthrough and business-as-usual research away from AGI.
- ^
The opinions expressed in this article are my own and do not necessarily represent those of the paper's other authors.
Discuss
