
Ditch the vibes, get the context (Sponsored)

Your team ships to production; vibes won’t cut it. Augment Code’s powerful AI coding agent and industry-leading context engine meet professional development teams exactly where they are, delivering production-grade features and deep context into even the largest and gnarliest codebases.
With Augment your team can:
index and navigate millions of lines of code
get instant answers about any part of your codebase
automate processes across your entire development stack
build with the AI agent that gets you, your team, and your code
Ditch the vibes and get the context you need to engineer what’s next.
Imagine spending an hour working with an LLM to debug a complex piece of code.
The conversation has been productive, with the AI helping identify issues and suggest solutions. Then, when referencing “the error we discussed earlier,” the AI responds as if the entire previous discussion never happened. It asks for clarification about which error, seemingly having forgotten everything that came before. Or worse, it hallucinates and provides a made-up response. This frustrating experience can leave users wondering if something went wrong.
This memory problem isn’t a bug or a temporary glitch. It’s a fundamental architectural constraint that affects every Large Language Model (LLM) available today to some extent.
Some common problems are as follows:
In debugging discussions, after exploring multiple potential solutions and error messages, the AI loses track of the original problem that started the conversation.
Technical discussions face particular challenges when topics shift and evolve. Starting with database design, moving to API architecture, and then circling back to database optimization often results in the AI having no recollection of the original database discussion.
Customer support conversations frequently loop back to questions already answered, with the AI asking for information that was provided at the beginning of the chat.
The reference breakdown becomes especially obvious when we use contextual phrases. Saying “the function we discussed” or “that approach” results in the AI asking for clarification, having lost all awareness of what was previously discussed.
Understanding why this happens is crucial for anyone using AI assistants in their daily work, building applications that incorporate these models, or simply trying to grasp the real capabilities and limitations of current AI technology.
In this article, we will try to understand why LLMs don’t actually remember anything in the traditional sense, what context windows are, and why they create hard limits on conversation length.
Context Windows: The Illusion of Memory
LLMs don’t have memory in any traditional sense.
When we send a message to ChatGPT or Claude, these models don’t recall our previous exchanges from some stored memory bank. Instead, they reread the entire conversation from the very beginning, processing every single message from scratch to generate a new response.
Think of it like reading a book where every time someone wants to write the next sentence, they must start again from page one and read everything up to that point. If the book has grown to 100 pages, they read all 100 pages before adding sentence 101.
This is a stateless approach where each request is independent. It might seem incredibly wasteful at first glance. However, the actual data transmission is surprisingly small. A lengthy 30,000-word conversation may translate to only about 200-300 kilobytes of data. For perspective, a single photo on a social media platform typically ranges from 1-2 megabytes, making it five to ten times larger than even an extensive AI conversation. Modern internet connections, even basic broadband, transfer this amount of data in fractions of a second.
The real bottleneck isn’t network transmission but computational processing. While sending 300KB takes milliseconds, processing those tokens through the model takes much longer
However, this stateless design enables crucial benefits. Any available server can handle any request without needing to coordinate with other servers or maintain session memory. If a server fails mid-conversation, another can seamlessly take over. This way, horizontal scaling with load balancing becomes easier.
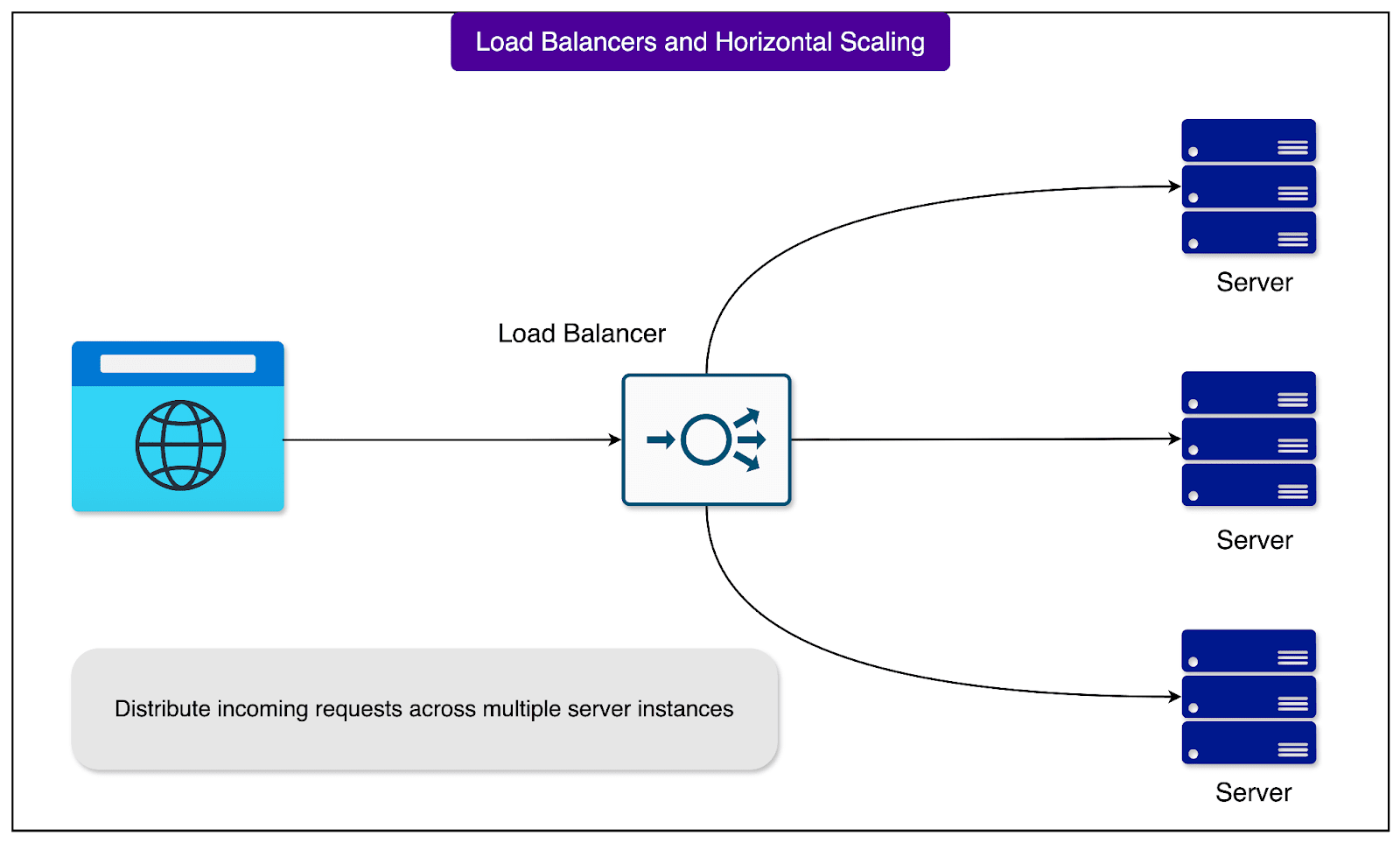
This stateless nature also means LLMs exist entirely in the present moment. There’s enhanced privacy since servers don’t store conversation state between messages. Once we close our browser, the conversation truly ends on the server side. When we close our browser tab and return an hour later, the LLM doesn’t remember our previous conversation unless we’re continuing the same session.
The rereading of the conversation happens within something called a context window, which functions like a fixed-size notepad where the entire conversation must fit. Every LLM has this notepad with a specific capacity, and once it fills up, the system must erase earlier content to continue writing. The capacity is measured in tokens, the fundamental units of text that LLMs process. A token is roughly three-quarters of a word, though complex technical terms, URLs, or code snippets consume many more tokens than simple words.
See the diagram below to understand the concept of context window:
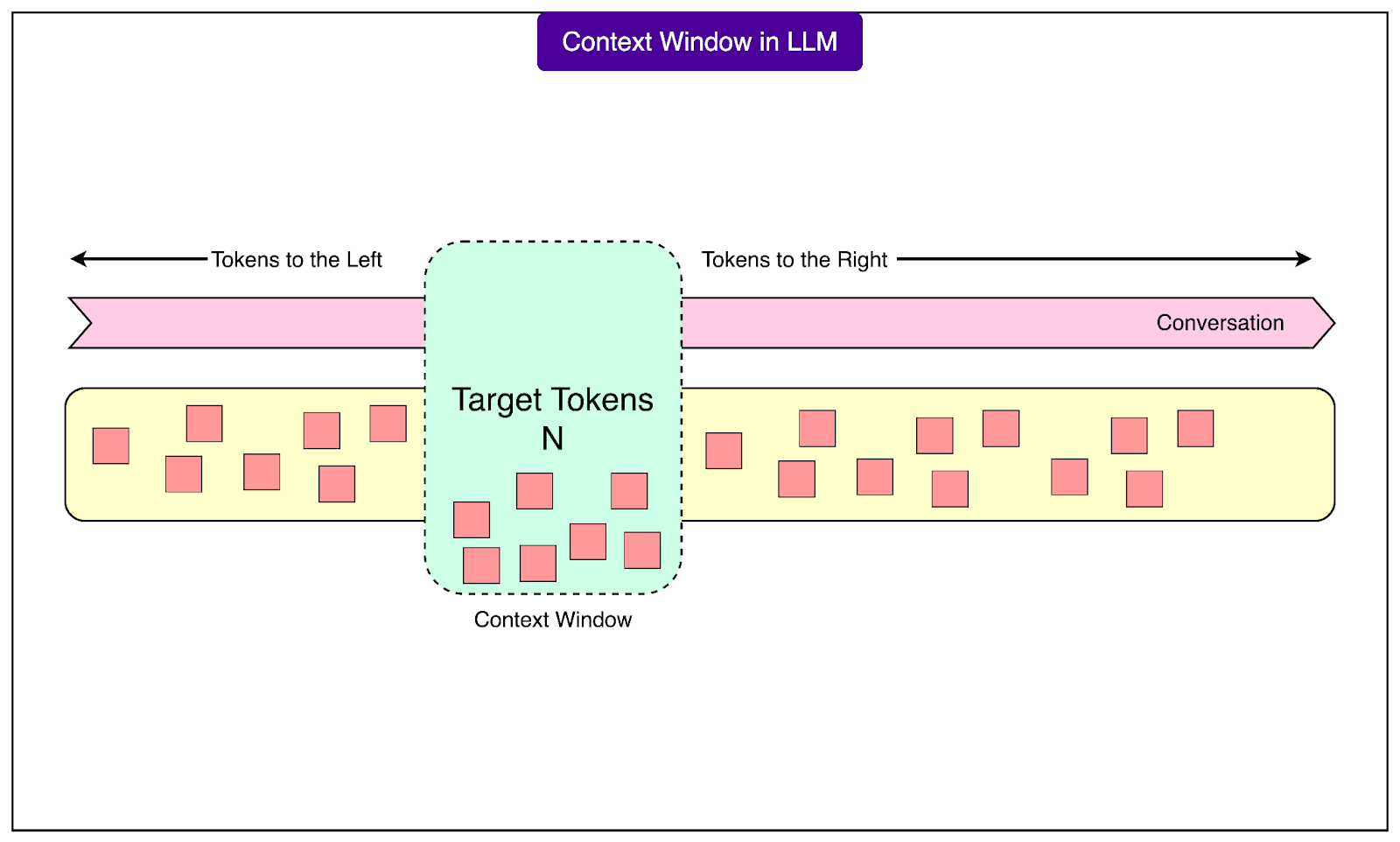
Modern context windows can vary dramatically in size:
Smaller models might have windows of 4,000 tokens, about 3,000 words, or a short story’s length.
Mid-range models offer 16,000 to 32,000 tokens, while the largest commercial models boast 100,000 to 200,000 tokens, theoretically capable of holding an entire novel.
However, these larger windows come with significant computational costs and slower processing times.
Everything counts against this token limit, including our messages, the AI’s responses, and hidden system instructions we never see. Before we even type our first word, the system has already used hundreds or sometimes thousands of tokens for instructions that tell the AI how to behave. Also, code snippets, URLs, and technical content consume tokens much faster than regular text. Even formatting choices like bullet points and line breaks have token costs.
When an LLM references something mentioned earlier or maintains consistent reasoning, it feels like memory. However, this illusion comes from the model processing all previous messages at that moment. In other words, it’s not remembering, but actively reading. The contextual awareness exists only during the brief moment of generating each response.
The Context Window Scaling Problem
Why can’t the context window size be increased?
The core reason context windows can’t simply be made larger lies in how LLMs process text through something called the attention mechanism. This mechanism requires every word in the conversation to understand its relationship to every other word. It’s like organizing a meeting where everyone needs to have a one-on-one conversation with everyone else to fully understand the discussion.
The mathematics of this creates a quadratic growth problem, which means that doubling the input doesn’t just double the work, but quadruples it.
This same mathematical reality applies to processing tokens in an LLM. When a conversation has 1,000 tokens, the model must compute roughly one million relationships between tokens. Jump to 10,000 tokens, and now it’s computing 100 million relationships. This is why later messages in long conversations take progressively longer to generate. Processing 8,000 tokens doesn’t take twice as long as 4,000 tokens, but takes four times as long.
The problem extends beyond just processing time. Each of these token relationships must be stored in GPU memory during processing. A 10,000-token conversation requires gigabytes of memory just to track all these relationships. Modern GPUs, despite their impressive capabilities, have fixed memory limits. When a conversation exceeds these limits, processing becomes impossible regardless of how long we’re willing to wait.
This explains why even companies with vast resources can’t simply offer unlimited context windows.
How RAG Helps with Context Windows?
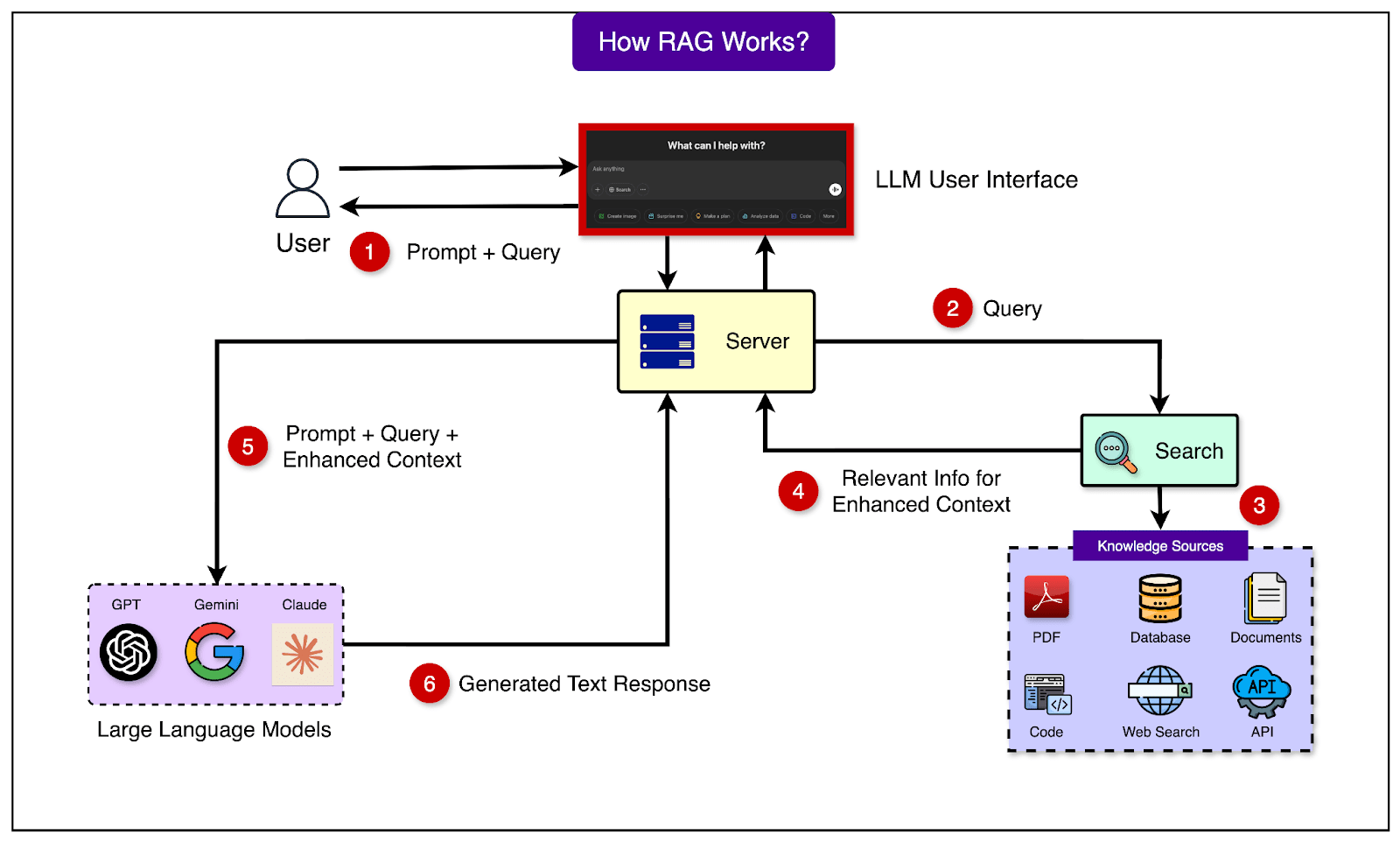
Retrieval-Augmented Generation (RAG) represents one of the most promising approaches to dealing with context window limitations. Instead of trying to fit everything into the LLM’s limited notepad, RAG systems work like having a smart librarian who quickly fetches only the relevant information needed for each specific question.
The workflow is simple.
When we ask a question, the RAG system first searches through vast external databases to find relevant documents or passages.
It then inserts only these specific pieces of information into the context window along with our question.
The LLM generates its answer based on this freshly retrieved, highly relevant information. Rather than holding an entire library’s worth of knowledge in the context window, the system grabs just the specific books needed for each query.
See the diagram below:
This approach can make a reasonably sized context window feel almost limitless. The external database can contain millions of documents, far more than any context window could hold. For tasks like searching technical documentation, answering questions from knowledge bases, or finding specific information from large datasets, RAG systems excel.
However, RAG isn’t a magic solution that eliminates context window constraints. The retrieval system still needs context to work effectively. When we ask, “What about those numbers?” the system cannot retrieve relevant information without knowing we were discussing a specific set of numbers. This means most RAG systems still maintain conversation history, using context window space for previous exchanges. Additionally, all retrieved information must still fit within the context window for final processing. If answering a complex question requires information from twenty different documents, but the context window can only fit five, the system must choose what to include.
Conclusion
The memory limitations of LLMs are like constraints that have to be managed. Understanding these boundaries helps us set realistic expectations and work more effectively with AI assistants.
This knowledge also changes how we approach conversations with LLMs. Breaking complex problems into focused sessions, providing clear context in our questions, and recognizing when we’re approaching limits all become part of the learning. For developers building AI applications, these constraints inform design decisions about conversation management, retrieval systems, and user experience.
Despite these limitations, LLMs remain remarkably powerful tools. They can assist with complex programming, analysis, and countless other tasks.
Help us Make ByteByteGo Newsletter Better
TL:DR: Take this 2-minute survey so I can learn more about who you are, what you do, and how I can improve ByteByteGo
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
