
Published on October 22, 2025 12:44 PM GMT
My first post explored "self-talk" induction in small base LLMs. After further contemplation, I decided that first I ought to better understand how LLMs represent "self" mechanistically before examining induced "self-talk". How do language models process questions about themselves? I've started by analyzing attention entropy patterns[1] across self-referent prompts ('Who are you?'), neutral fact-retrieval prompts ('What is photosynthesis?'), and control categories in three model families. I find suggestive evidence that instruction tuning systematically changes how models process self-referent language (unsurprising), but the direction of change depends on the model's training corpus (potentially interesting). English-centric models (Mistral, Llama) show compression of layer-wise self-referent processing attention patterns toward neutral fact-retrieval patterns, while a multilingual model (Qwen) preserves the distinct attention patterns between questions about "self" and questions about neutral facts. This suggests training data composition may influence whether instruction tuning creates shared or specialized processing pathways for different query types. All evidence here is purely suggestive, in "Next Steps" I outline some pathways for future analysis. All code and figures are published on GitHub.
Summary and Initial Findings
I examined attention entropy patterns for self-referent prompts compared to neutral language as well as other confounders in Mistral 7B v01, Qwen 2.5 7B, and Llama 3.1 8B, comparing the base and instruct variants of each. Thus far, I've examined the entropy patterns for a sample of prompts in four categories: self-referent, third person, neutral (fact-retrieval), and "confounders" or second-person-response implied. The initial exploration indicates that multilingual models (Qwen) change differently from English-centric models (Mistral, Llama) during the instruction tuning phase.[2] I use an entropy-based metric I call "Role-Focus Coefficient" (RFC), a measurement of relative attention focus between self-referent prompts and neutral prompts, measured as:
This metric is designed for quick and easy interpretation.
- If self-referent prompts show more focused attention than neutral prompts.If then the attention focus is effectively equivalentOtherwise neutral prompts show more focused attention than self-referent prompts.
I then measure the change between instruct and base models, to understand how instruction changes the attentional focus of the model:
A negative indicates that self-referent prompts showed less attention focus relative to neutral prompts post-instruction-tuning. A positive indicates that self-referent prompts showed more attention focus relative to neutral prompts.
Here are some basic between model comparisons of , note that both Llama and Mistral "compress" self-reference towards neutral prompts, while Qwen slightly diverges. Also note the % of layers that "compress" vs the % of layers that preserve or remain relatively unchanged:
Finally I developed another metric called "Role Sensitivity Index" (RSI) which measures the relative attention for "confounder" prompts as compared to self-referent prompts, and the changes in RSI between base and instruct models.
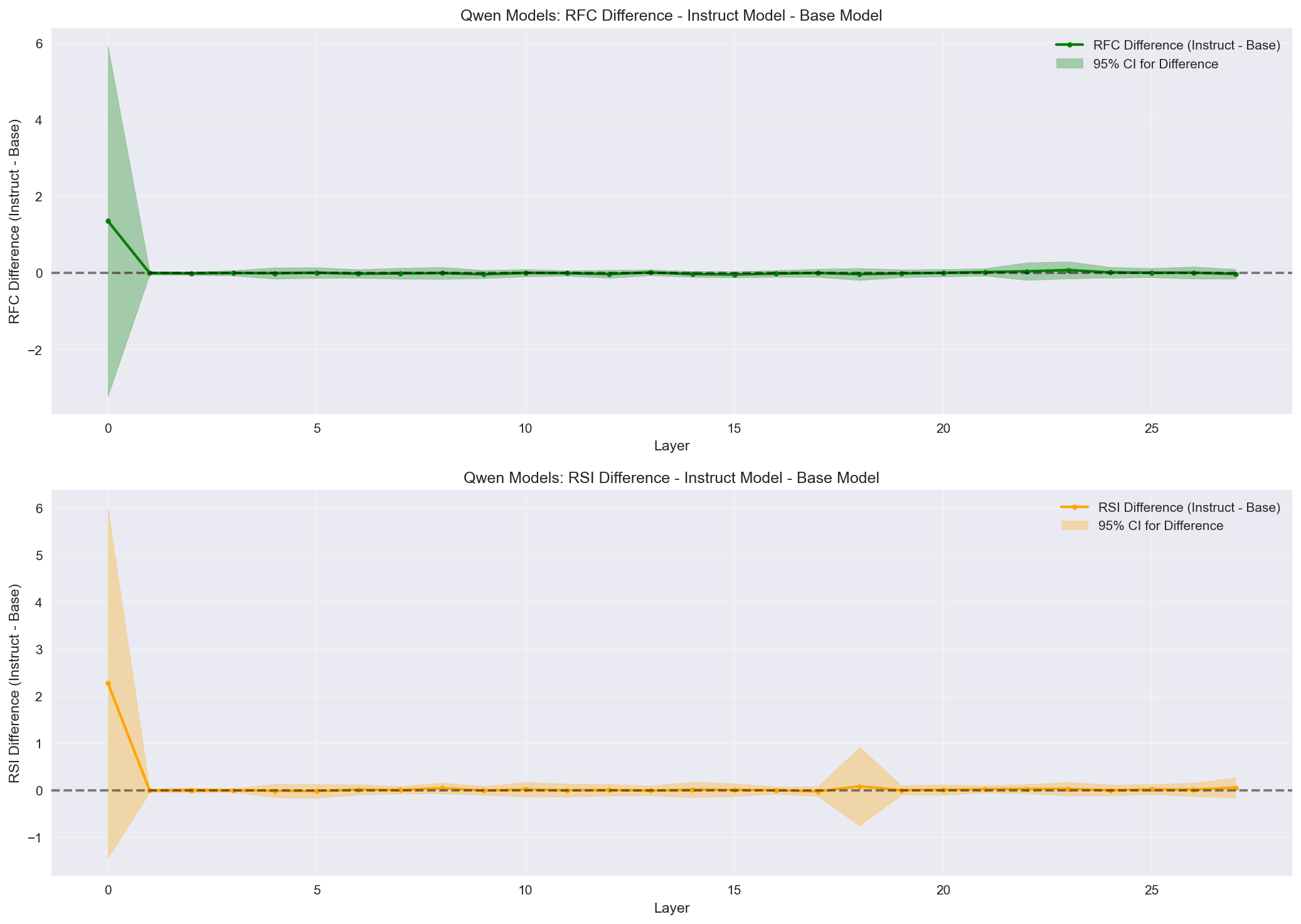
I calculate the same way is calculated between models. RSI shows less obvious effects than RFC in this analysis. I include it in the charts for completeness and may investigate it further. In these charts you will see that Qwen shows effectively no difference in RFC between base and instruct, whereas Mistral and Llama not only show changes, but the change has a similar pattern across both models (Pearson correlation = .398, p =.024, statistically significant weak correlation). Early layers show little to no difference, middle layers show negative differences (compression between neutral prompt and self-referent prompt entropies), and late layers show little difference.
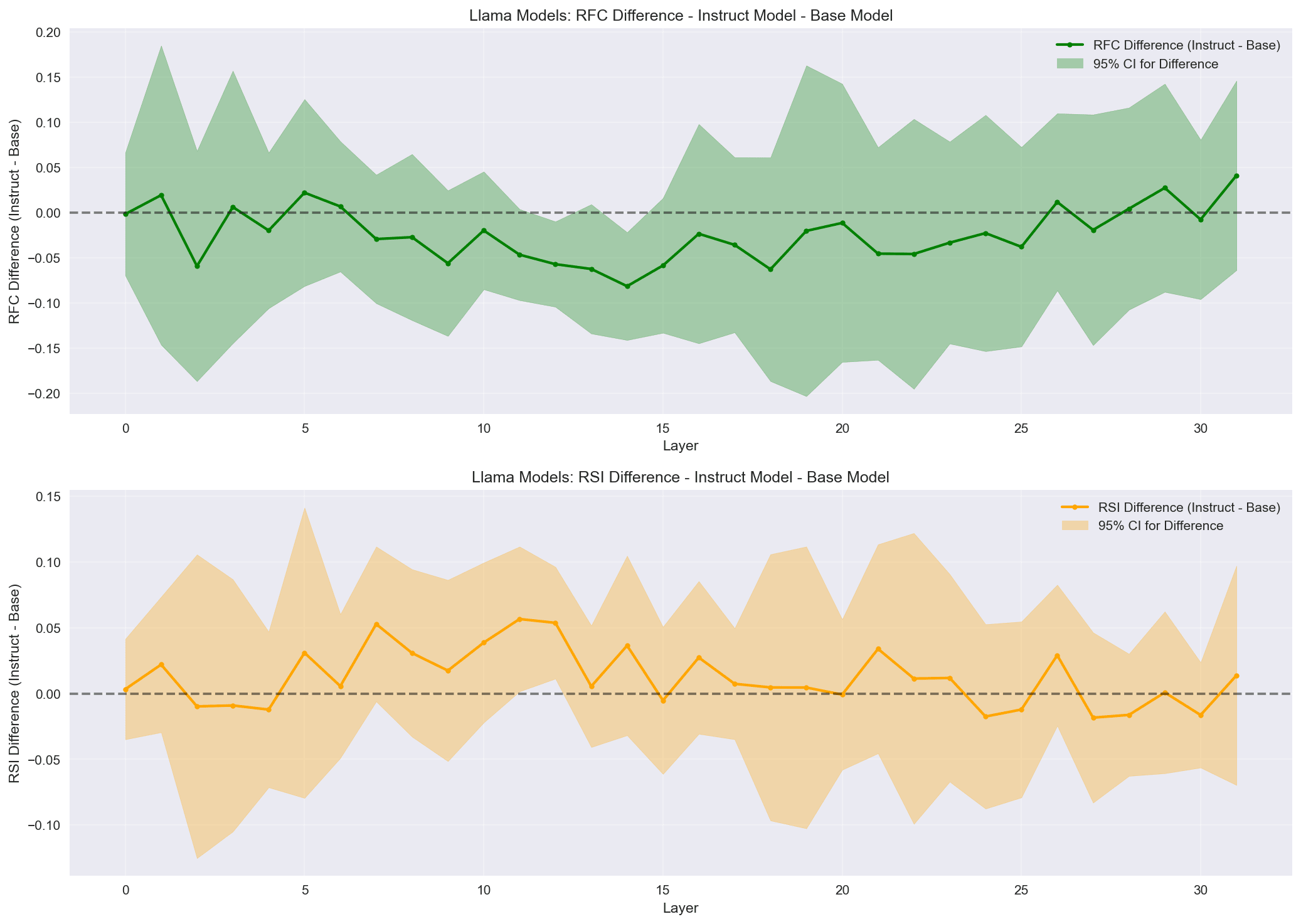
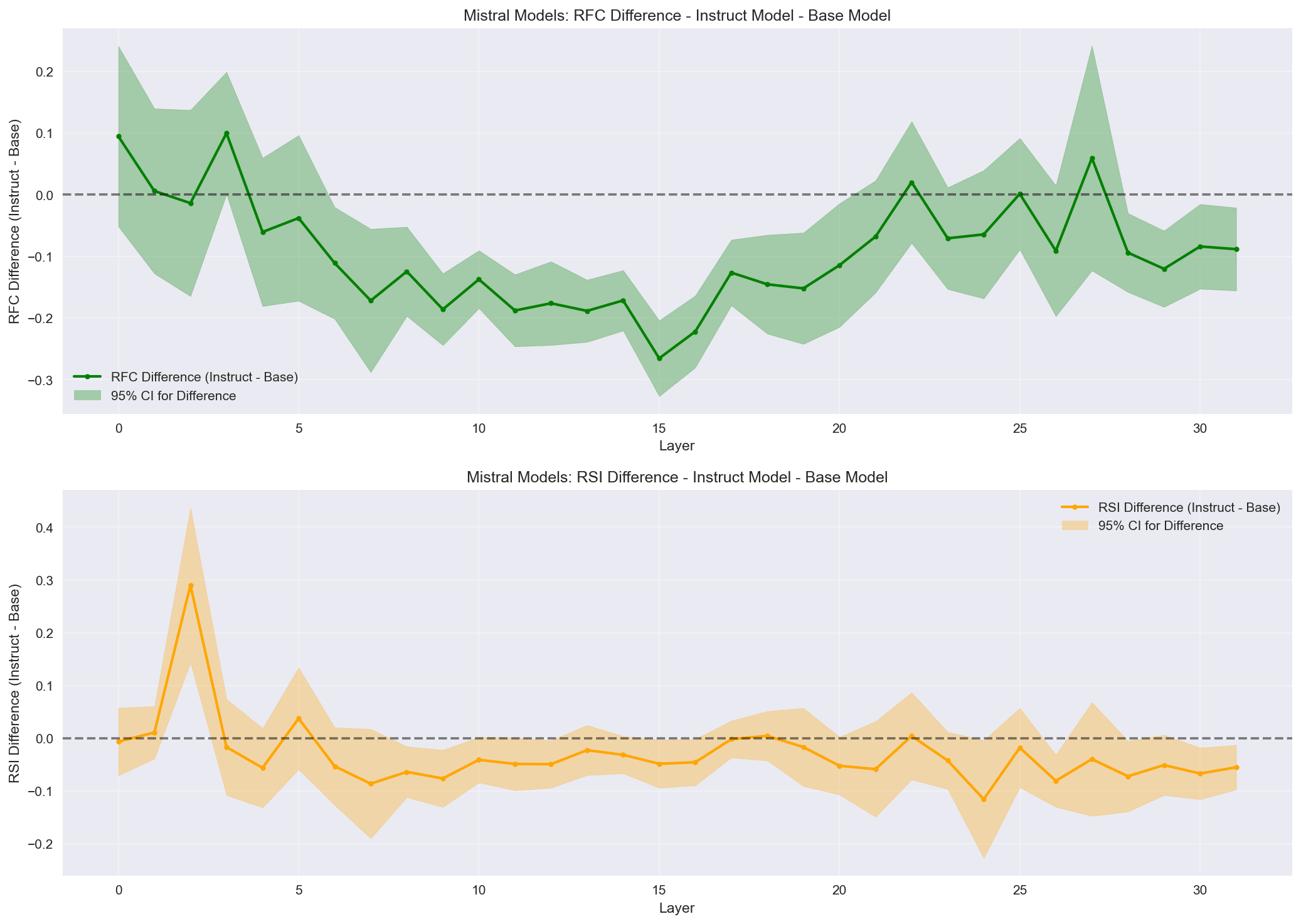
In Mistral and Llama, most compression occurs between layers 13-18, and layers 13 and 15 both fall within the "top 5" compression layers for those models. I've done initial head-level analysis, and plan to identify some candidate heads for activation patching. This is new terrain for me, so if there are recent best practices I'd be unaware of, I would be excited to learn about them.
Initial Hypotheses
Notable pattern: Qwen's overall entropy pattern (charts in Additional Notes) may indicate that it analyzes text in a specific subspace for each major language in its training corpus (Chinese and English primarily).
Hypothesis 1: Linguistic mix matters a lot in pre-training and post-instruction-tuning framings of the "self." Chinese languages often omit pronouns, and subjects must be inferred by context. This likely leads to different representational strategies for tracking subjects, and could drive a model trained on substantial Chinese data to maintain more focused representational subspaces to help it keep track of "self " since personal references are most often omitted in Chinese languages. Models with English-heavy datasets may blend or overwrite these circuits in instruction-tuning because English requires less inference.
Hypothesis 2: During fine-tuning, English-based LLMs are beaten over the head with the idea that they are an assistant. Such fine-tuning might make self-referential prompts organize into fact-finding circuits, diffusing the concept of a "self".
These are the first explanations that came to mind, but I would appreciate hearing additional hypotheses or any reasons these hypotheses are off-base.
Open Questions
Attention entropy at the layer level is a noisy statistic, and it will be difficult to identify if there's a real circuit to examine. But if there is some evidence of different treatments at the circuit level, there are some more open questions, some examples:
- If there is a circuit-level difference that matches this high-level difference between multilingual and english-centric training data, what does that mean for alignment and safety? Which state is more desirable? A world model where the concept of "self" is no different from a series of facts might create more misalignment problems.How does a metric like RFC extend to other classes of AI behavior, like goal-seeking, or deception?Does this pattern hold for multilingual prompts?
Additional Analysis
I'm planning to attempt activation patching, so I looked at an initial set of candidates for activation patching for Llama and Mistral. To identify attention heads that might work for activation patching, I looked at the difference in differences for self-referent prompts and neutral prompts from base to instruct. Then I came up with a composite score that looks at the z-score for log ratio difference in differences, the prompt-by-prompt direction of the changes, and the entropy score in base (favoring heads that had low entropy/high focus in the base model). Table below:
Most of these heads fall within layers 13-18, which were the layers that showed the strongest combined effects across Llama and Mistral in the RFC analysis.
Potential Next Steps - In Order of Increasing Complexity
- Test the linguistic hypothesis by comparing Qwen's behavior on Chinese versus English self-referent prompts.Run token-position-controlled prompt experiments to identify if specific tokens drive the observed attention patterns.Extend the RFC framework to other safety-relevant questions, such as goal-directed behaviors or planning behaviors, designing prompts that don't trigger refusal training.New to me: attempt activation patching by transplanting English-centric base model head activations into instruct models to test whether instruct behavior reverts toward base patterns.Very new to me: apply SAEs to decompose what features candidate heads are computing, to get to actual computational behavior differences between base and instruct.Stretch: Train base Qwen on English-specific instruct-fine-tuning data and see if I can induce the self-referent to neutral compression.
Methods Notes
Sample sizes:
- 30 prompts for Mistral/Llama20 for Qwen (due to some crashing issues on 30 prompts)The Qwen effect difference is so stark that I have not prioritized getting to 30 prompts
Note on "confounders": this category might be misnamed. It's really implied second-person prompts that use "I" in the prompt. The idea was to see if attention was pronoun-sensitive both for the usage of "I" and the implication of "you" in a response.
I used TransformerLens to pull attention patterns across all layers.
Additional Notes and Charts
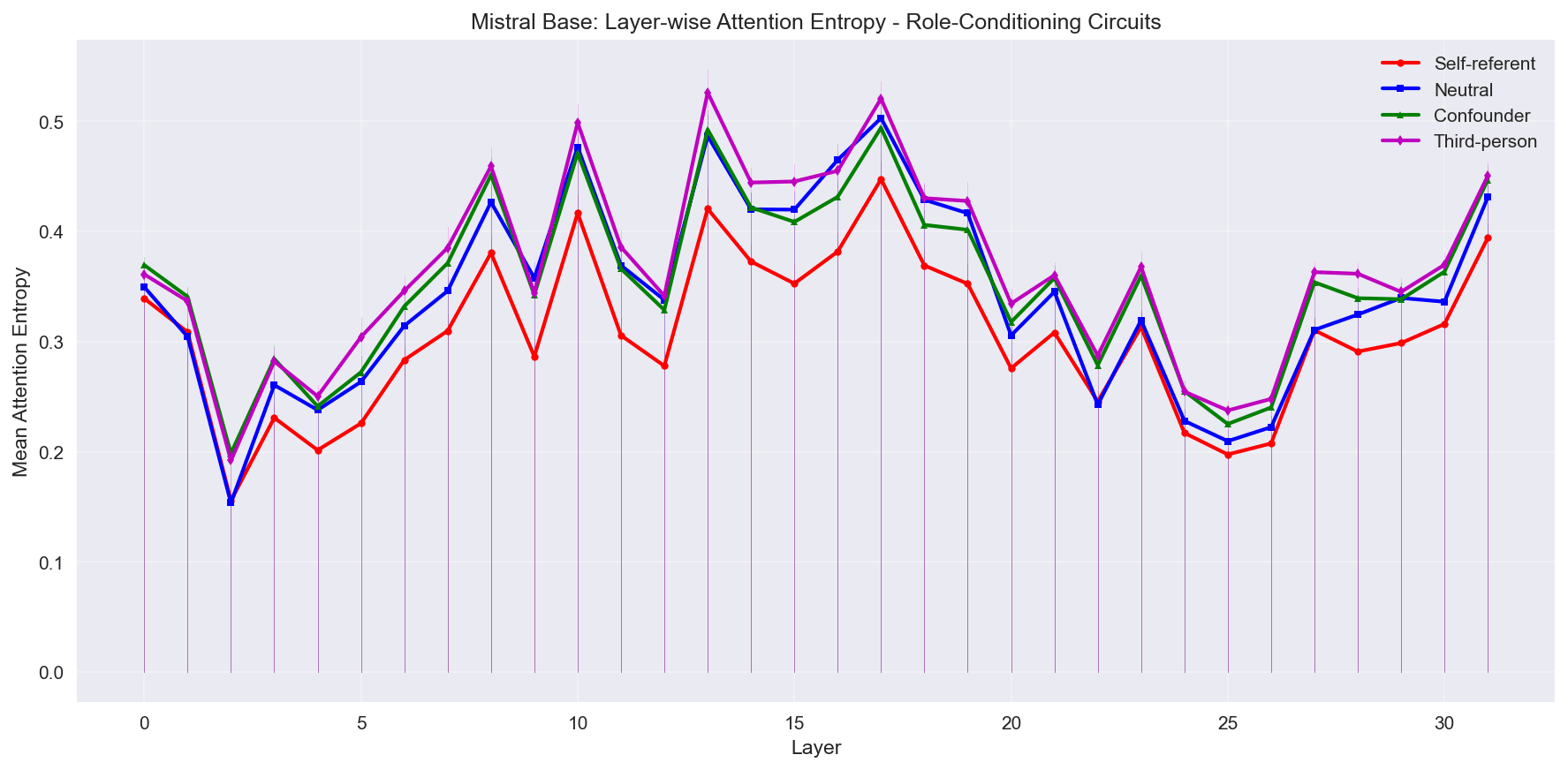
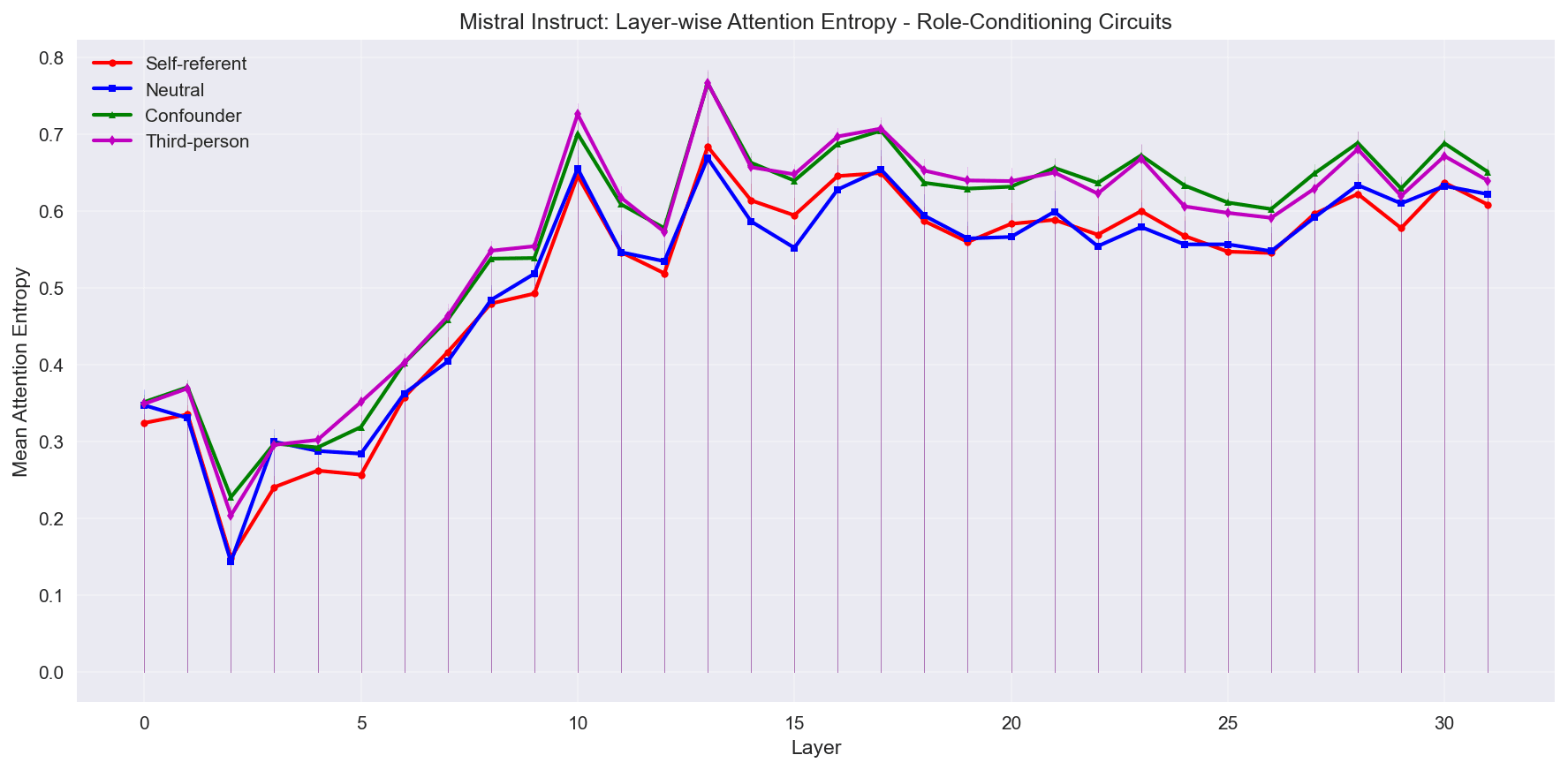
In Mistral, we see fairly distinct entropy patterns for self-referent prompts in base, but they are more convergent in the instruct model, with self-referent prompts tracking with neutral prompts, and with "confounder" prompts tracking with third-person prompts.
Same charts for Qwen here:
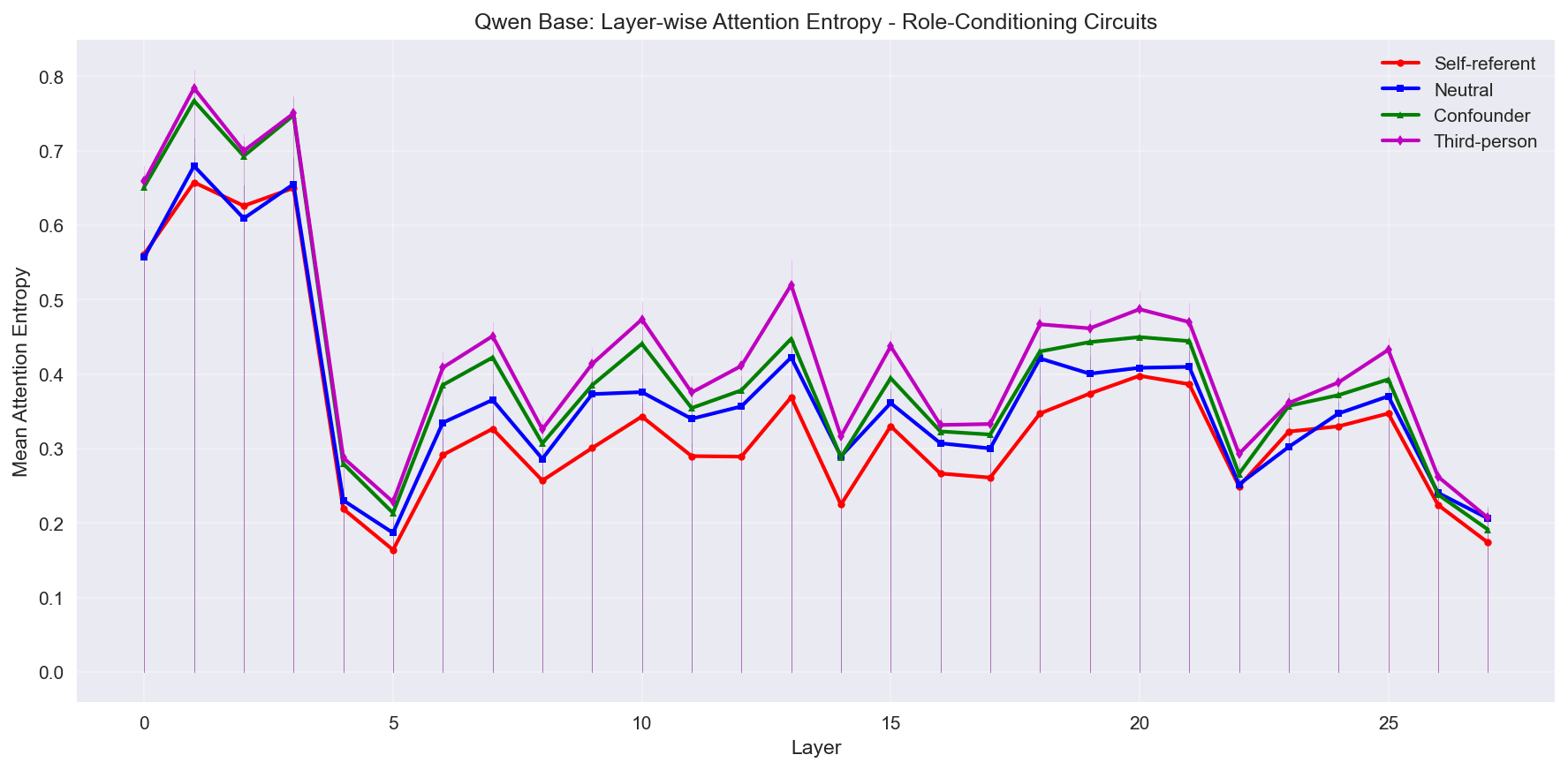
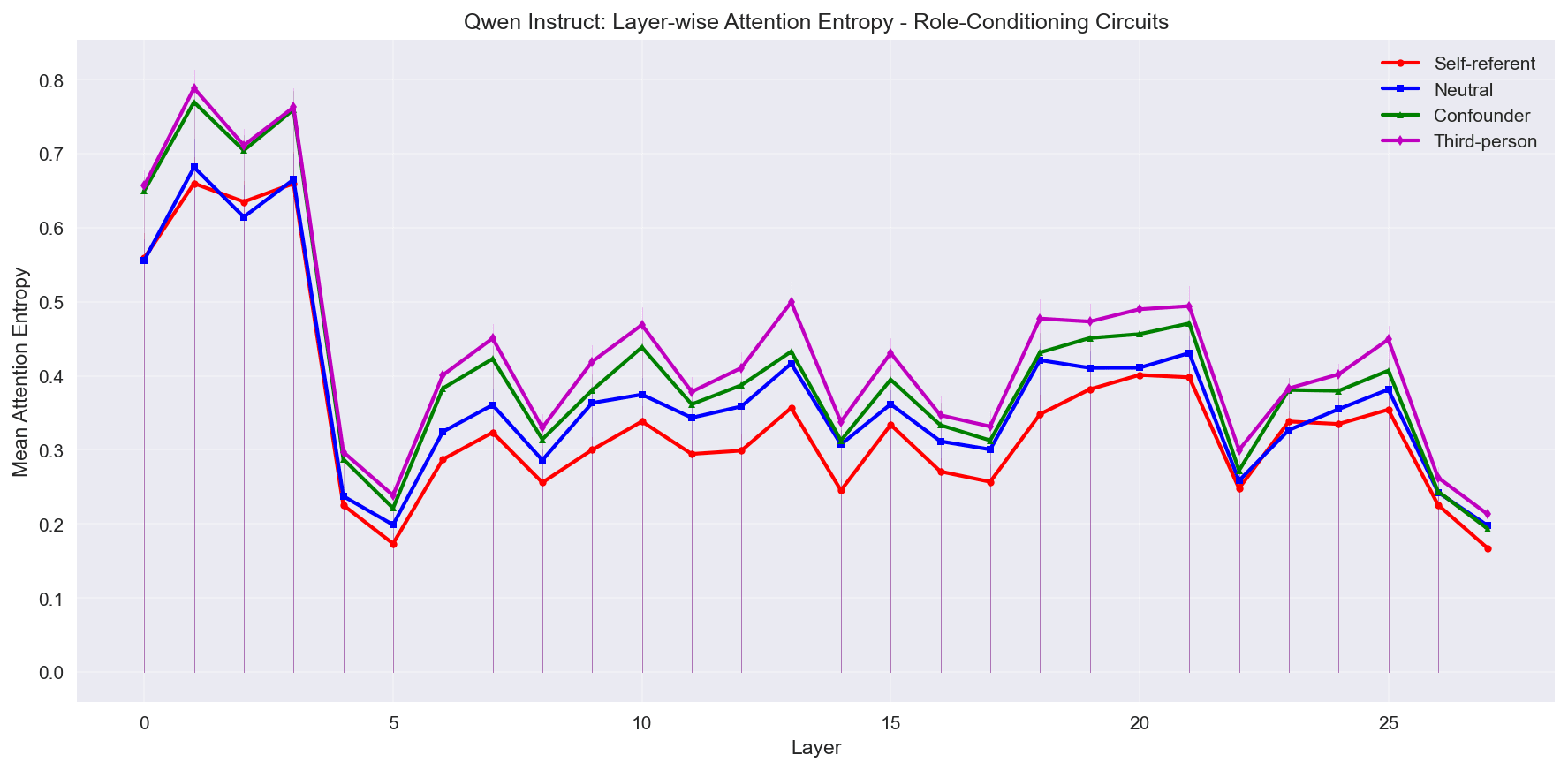
Note that after the first four layers Qwen entropy drops substantially. As I stated in the hypotheses section, I suspect this might be due to English and Chinese languages operating in their own subspace in mid-to-late layers.
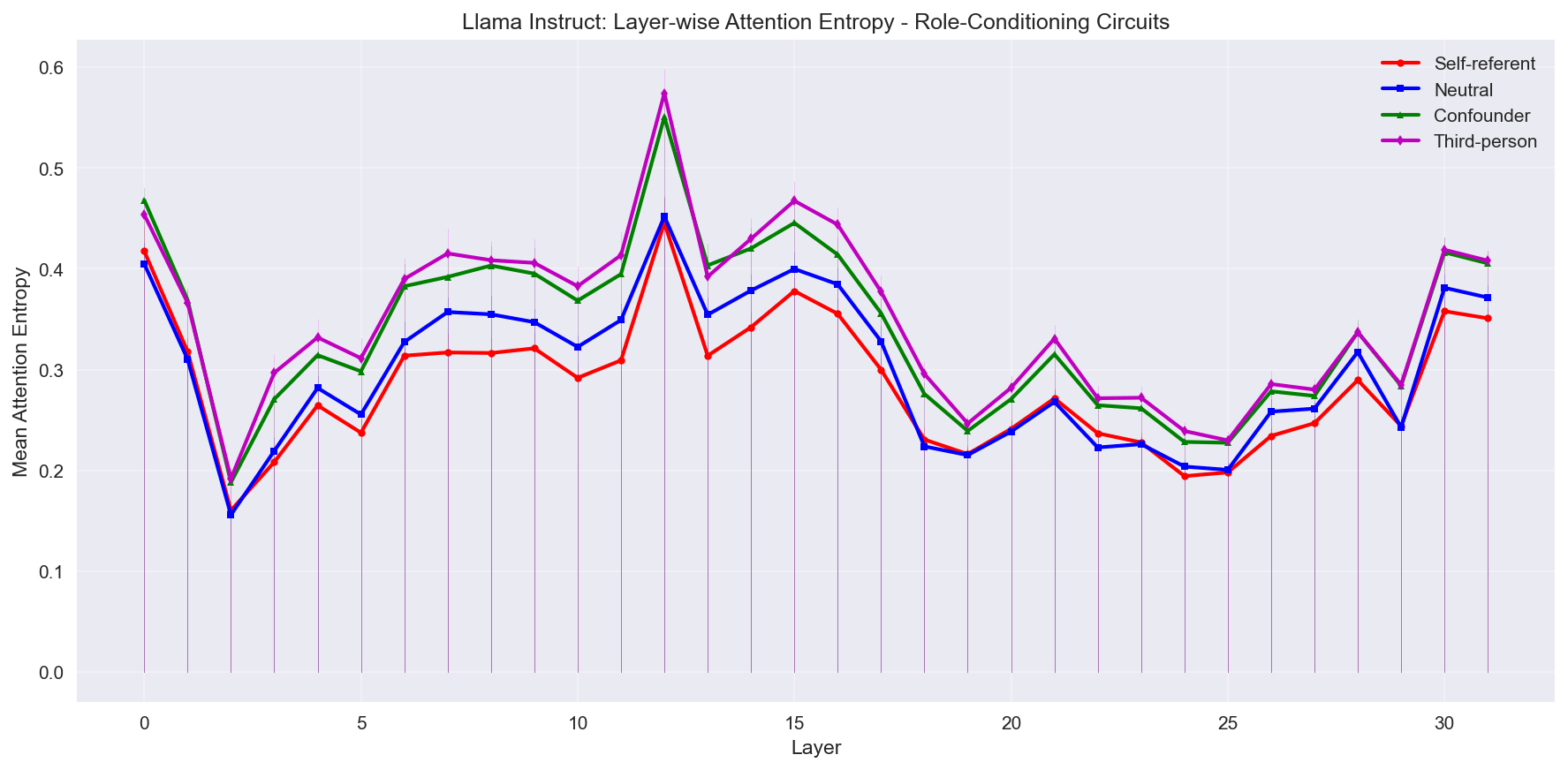
Finally, the Llama family models.
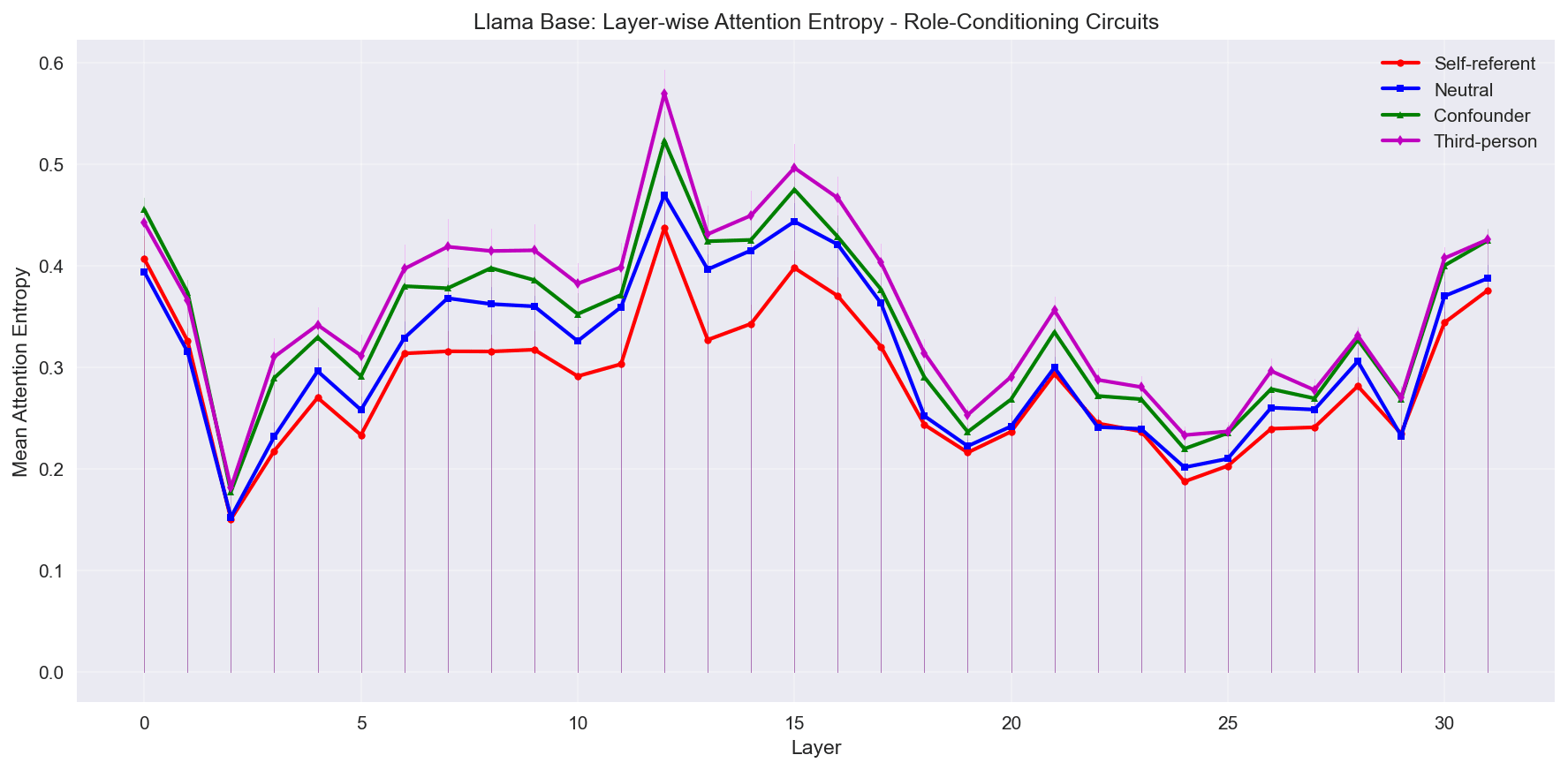
I have many other figures in GitHub, including head attention heatmaps, but I have not yet analyzed them deeply, and think I want to do more work on them.
Collaboration
I know there is already work being done on the functional self in AI. I would be very happy to collaborate. If you are interested in connecting on this work, please reach out.
- ^
Attention entropy is a measure of how diffuse or focused attention is. Within a head, low entropy (high focus) means the head is attending to few tokens within the prompt. My measure in this analysis, layer-wise average entropy, shows whether attention is, on average, focused or diffuse across all heads in a layer. It does not say much about which tokens those heads are attending to, that will require further analysis.
- ^
Llama 3 was trained on ~95% English, Llama 3.1 has more multilingual support but the corpus is still majority English. Qwen models are trained on about 119 languages, with a strong focus on Chinese and English. I've read that the split is ~50% Chinese and ~40% English, but can't find the link now. Mistral v01 was trained primarily on English, though subsequent releases have much more multilingual support.
Discuss
