
就在刚刚,DeepSeek开源了一个3B模型DeepSeek-OCR。虽然体量不大,但模型思路创新的力度着实不小。
众所周知,当前所有LLM处理长文本时都面临一个绕不开的困境:计算复杂度是平方级增长的。序列越长,算力烧得越狠。
于是,DeepSeek团队想到了一个好办法。既然一张图能包含大量文字信息,而且用的Token还少,那不如直接把文本转成图像?这就是所谓的“光学压缩”——用视觉模态来给文本信息“瘦身”。
而OCR正好天然适合验证这个思路,因为它本身就是在做“视觉→文本”的转换,而且效果还能量化评估。
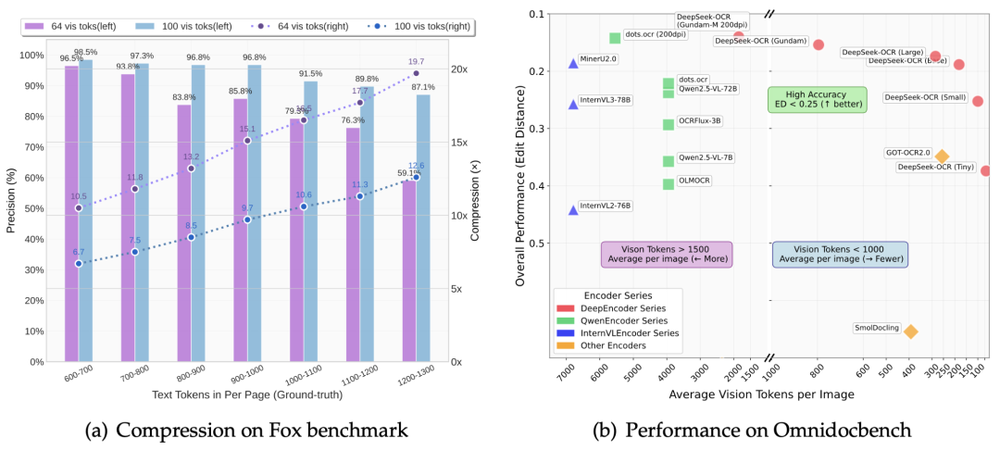
论文显示,DeepSeek-OCR的压缩率能达到10倍,OCR准确率还能保持在97%以上。
啥意思呢?就是说,原本需要1000个文本Token才能表达的内容,现在只用100个视觉Token就搞定了。即使压缩率拉到20倍,准确率也还有60%左右,整体效果相当能打。
OmniDocBench基准测试结果显示:
只用100个视觉Token,就超过了GOT-OCR2.0的表现;
用不到800个视觉Token,干翻了MinerU2.0。
在实际生产中,一块A100-40G显卡就能每天生成超过20万页的LLM/VLM训练数据。20个节点直接飙到每天3300万页。
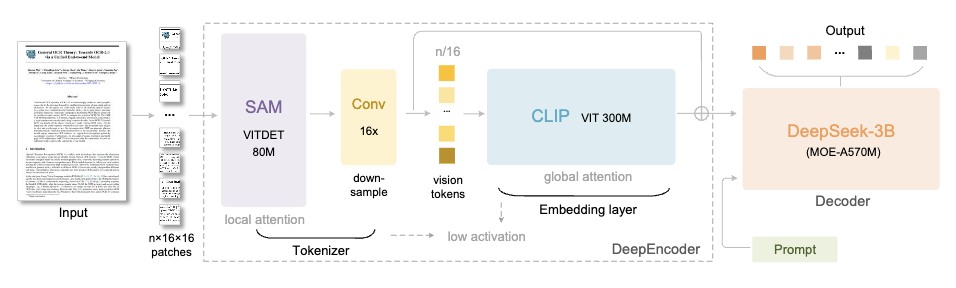
DeepSeek-OCR由两个核心组件组成:
DeepEncoder:负责图像特征提取和压缩;
DeepSeek3B-MoE:负责从压缩后的视觉Token中重建文本。
让我们来重点说说DeepEncoder这个引擎。
它的架构很巧妙,通过把SAM-base和CLIP-large串联起来,前者负责“窗口注意力”提取视觉特征,后者负责“全局注意力”理解整体信息。
中间还加了个16×卷积压缩器,在进入全局注意力层之前把Token数量大幅砍掉。
举例而言,一张1024×1024的图像,会被切成4096个patch token。但经过压缩器处理后,进入全局注意力层的Token数量会大幅减少。
这样的好处是,既保证了处理高分辨率输入的能力,又控制住了激活内存的开销。
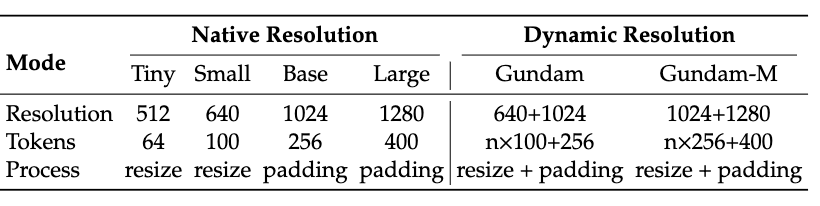
而且DeepEncoder还支持多分辨率输入,从512×512的Tiny模式到1280×1280的Large模式,一个模型全搞定。
目前开源版本支持的模式包括原生分辨率的Tiny、Small、Base、Large四档,还有动态分辨率的Gundam模式,灵活性拉满。
解码器用的是DeepSeek-3B-MoE架构。
别看只有3B参数,但采用了MoE设计——64个专家中激活6个,再加2个共享专家,实际激活参数约5.7亿。这也让模型既有30亿参数模型的表达能力,又保持了5亿参数模型的推理效率。
解码器的任务就是从压缩后的视觉Token中重建出原始文本,这个过程可以通过OCR风格的训练被紧凑型语言模型有效学习。
数据方面,DeepSeek团队也是下了血本。
从互联网收集了3000万页多语言PDF数据,涵盖约100种语言,其中中英文占2500万页。
数据分两类:粗标注直接用fitz从PDF提取,主要训练少数语言的识别能力;精标注用PP-DocLayout、MinerU、GOT-OCR2.0等模型生成,包含检测与识别交织的高质量数据。
对于少数语言,团队还搞了个“模型飞轮”机制——先用有跨语言泛化能力的版面分析模型做检测,再用fitz生成的数据训练GOT-OCR2.0,然后用训练好的模型反过来标注更多数据,循环往复最终生成了60万条样本。
此外还有300万条Word文档数据,主要提升公式识别和HTML表格解析能力。
场景OCR方面,从LAION和Wukong数据集收集图像,用PaddleOCR标注,中英文各1000万条样本。

DeepSeek-OCR不仅能识别文字,还具备“深度解析”能力,只需一个统一的提示词,就能对各种复杂图像进行结构化提取:
图表:金融研究报告中的图表可以直接提取为结构化数据;
化学结构式:识别并转换为SMILES格式;
几何图形:对平面几何图形进行复制和结构化解析;
自然图像:生成密集描述。
这在STEM领域的应用潜力巨大,尤其是化学、物理、数学等需要处理大量符号和图形的场景。

第一作者Haoran Wei此前曾供职于阶跃星辰,期间发布并开源了GOT-OCR2.0系统
值得注意的是,DeepSeek团队在论文里还提出了一个脑洞大开的想法——用光学压缩模拟人类的遗忘机制。
人类的记忆会随时间衰退,越久远的事情记得越模糊。DeepSeek团队想,那能不能让AI也这样?于是,他们的方案是:
1. 把超过第k轮的历史对话内容渲染成图像;
2. 初步压缩,实现约10倍的Token减少;
3. 对于更久远的上下文,继续缩小图像尺寸;
4. 随着图像越来越小,内容也越来越模糊,最终达到“文本遗忘”的效果。
这就很像人类记忆的衰退曲线,近期信息保持高保真度,久远记忆自然淡化。
虽然这还是个早期研究方向,但如果真能实现,对于处理超长上下文将是个巨大突破——近期上下文保持高分辨率,历史上下文占用更少计算资源,理论上可以支撑“无限上下文”。

简言之,DeepSeek-OCR表面上是个OCR模型,但实际上是在探索一个更宏大的命题:能否用视觉模态作为LLM文本信息处理的高效压缩媒介?
初步答案是肯定的,7—20倍的Token压缩能力已经展现出来了。
当然,团队也承认这只是个开始。单纯的OCR还不足以完全验证“上下文光学压缩”,后续还计划开展数字–光学文本交替预训练、“大海捞针”式测试,以及其他系统性评估。
不过不管怎么说,这在VLM和LLM的进化路上,又多了一条新赛道。
去年这个时候,大家还在卷怎么让模型“记得更多”。今年DeepSeek直接反其道行之,不如让模型学会“忘掉一些”。
确然,AI的进化,有时候不是做加法,而是做减法。小而美,也能玩出大花样,DeepSeek-OCR这个3B小模型就是最好的证明。
