
This post is co-written with Ross Ashworth at TP ICAP.
The ability to quickly extract insights from customer relationship management systems (CRMs) and vast amounts of meeting notes can mean the difference between seizing opportunities and missing them entirely. TP ICAP faced this challenge, having thousands of vendor meeting records stored in their CRM. Using Amazon Bedrock, their Innovation Lab built a production-ready solution that transforms hours of manual analysis into seconds by providing AI-powered insights, using a combination of Retrieval Augmented Generation (RAG) and text-to-SQL approaches.
This post shows how TP ICAP used Amazon Bedrock Knowledge Bases and Amazon Bedrock Evaluations to build ClientIQ, an enterprise-grade solution with enhanced security features for extracting CRM insights using AI, delivering immediate business value.
The challenge
TP ICAP had accumulated tens of thousands of vendor meeting notes in their CRM system over many years. These notes contained rich, qualitative information and details about product offerings, integration discussions, relationship insights, and strategic direction. However, this data was being underutilized and business users were spending hours manually searching through records, knowing the information existed but unable to efficiently locate it. The TP ICAP Innovation Lab set out to make the information more accessible, actionable, and quickly summarized for their internal stakeholders. Their solution needed to surface relevant information quickly, be accurate, and maintain proper context.
ClientIQ: TP ICAP’s custom CRM assistant
With ClientIQ, users can interact with their Salesforce meeting data through natural language queries. For example:
- Ask questions about meeting data in plain English, such as “How can we improve our relationship with customers?”, “What do our clients think about our solution?”, or “How were our clients impacted by Brexit?” Refine their queries through follow-up questions. Apply filters to restrict model answers to a particular time period. Access source documents directly through links to specific Salesforce records.
ClientIQ provides comprehensive responses while maintaining full traceability by including references to the source data and direct links to the original Salesforce records. The conversational interface supports natural dialogue flow, so users can refine and explore their queries without starting over. The following screenshot shows an example interaction (examples in this post use fictitious data and AnyCompany, a fictitious company, for demonstration purposes).
ClientIQ performs multiple tasks to fulfill a user’s request:
- It uses a large language model (LLM) to analyze each user query to determine the optimal processing path. It routes requests to one of two workflows:
- The RAG workflow for getting insights from unstructured meeting notes. For example, “Was topic A discussed with AnyCompany the last 14 days?” The SQL generation workflow for answering analytical queries by querying structured data. For example, “Get me a report on meeting count per region for last 4 weeks.”
Solution overview
Although the team considered using their CRM’s built-in AI assistant, they opted to develop a more customized, cost-effective solution that would precisely match their requirements. They partnered with AWS and built an enterprise-grade solution powered by Amazon Bedrock. With Amazon Bedrock, TP ICAP evaluated and selected the best models for their use case and built a production-ready RAG solution in weeks rather than months, without having to manage the underlying infrastructure. They specifically used the following Amazon Bedrock managed capabilities:
- Amazon Bedrock foundation models – Amazon Bedrock provides a range of foundation models (FMs) from providers, including Anthropic, Meta, Mistral AI, and Amazon, accessible through a single API. TP ICAP experimented with different models for various tasks and selected the best model for each task, balancing latency, performance, and cost. For instance, they used Anthropic’s Claude 3.5 Sonnet for classification tasks and Amazon Nova Pro for text-to-SQL generation. Because Amazon Bedrock is fully managed, they didn’t need to spend time setting up infrastructure for hosting these models, reducing the time to delivery. Amazon Bedrock Knowledge Bases – The FMs needed access to the information in TP ICAP’s Salesforce system to provide accurate, relevant responses. TP ICAP used Amazon Bedrock Knowledge Bases to implement RAG, a technique that enhances generative AI responses by incorporating relevant data from your organization’s knowledge sources. Amazon Bedrock Knowledge Bases is a fully managed RAG capability with built-in session context management and source attribution. The final implementation delivers precise, contextually relevant responses while maintaining traceability to source documents. Amazon Bedrock Evaluations – For consistent quality and performance, the team wanted to implement automated evaluations. By using Amazon Bedrock Evaluations and the RAG evaluation tool for Amazon Bedrock Knowledge Bases in their development environment and CI/CD pipeline, they were able to evaluate and compare FMs with human-like quality. They evaluated different dimensions, including response accuracy, relevance, and completeness, and quality of RAG retrieval.
Since launch, their approach scales efficiently to analyze thousands of responses and facilitates data-driven decision-making about model and inference parameter selection, and RAG configuration.The following diagram showcases the architecture of the solution.
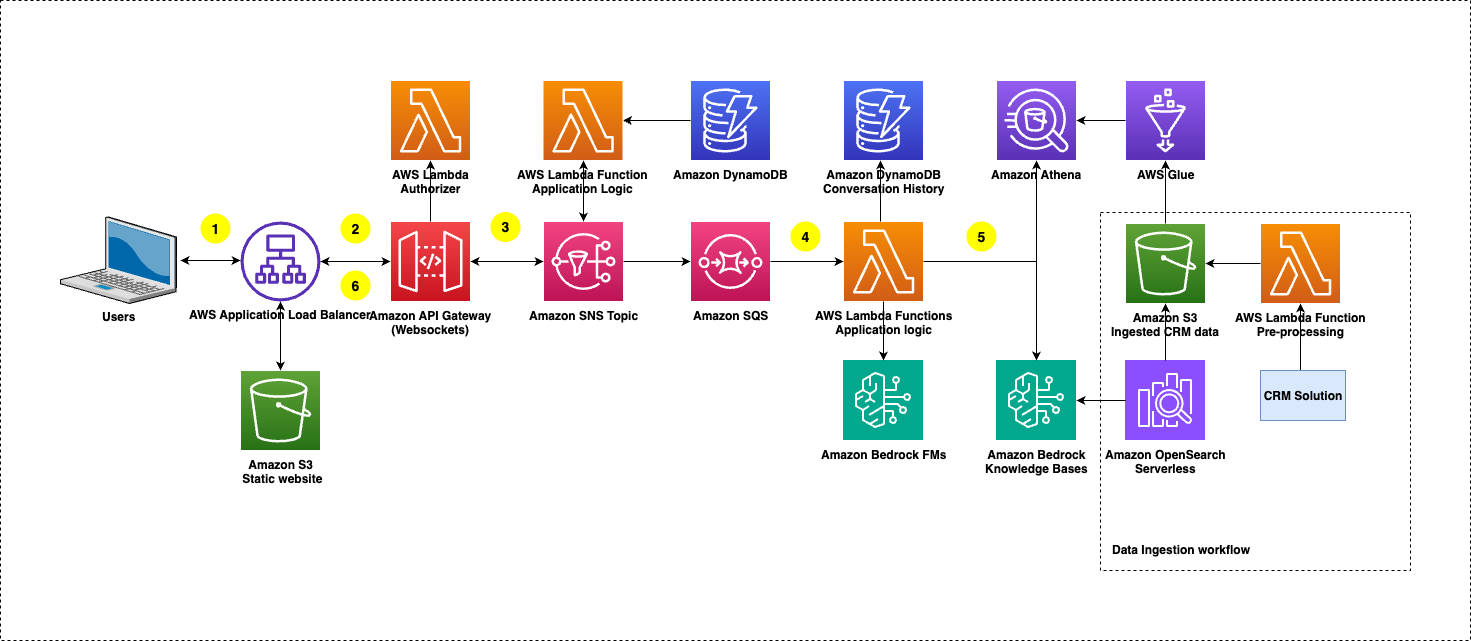
The user query workflow consists of the following steps:
- The user logs in through a frontend React application, hosted in an Amazon Simple Storage Service (Amazon S3) bucket and accessible only within the organization’s network through an internal-only Application Load Balancer. After logging in, a WebSocket connection is opened between the client and Amazon API Gateway to enable real-time, bi-directional communication. After the connection is established, an AWS Lambda function (connection handler) is invoked, which process the payload, logs tracking data to Amazon DynamoDB, and publishes request data to an Amazon Simple Notification Service (Amazon SNS) topic for downstream processing. Lambda functions for different types of tasks consume messages from Amazon Simple Queue Service (Amazon SQS) for scalable and event-driven processing. The Lambda functions use Amazon Bedrock FMs to determine whether a question is best answered by querying structured data in Amazon Athena or by retrieving information from an Amazon Bedrock knowledge base. After processing, the answer is returned to the user in real time using the existing WebSocket connection through API Gateway.
Data ingestion
ClientIQ needs to be regularly updated with the latest Salesforce data. Rather than using an off-the-shelf option, TP ICAP developed a custom connector to interface with their highly tailored Salesforce implementation and ingest the latest data to Amazon S3. This bespoke approach provided the flexibility needed to handle their specific data structures while remaining simple to configure and maintain. The connector, which employs Salesforce Object Query Language (SOQL) queries to retrieve the data, runs daily and has proven to be fast and reliable. To optimize the quality of the results during the RAG retrieval workflow, TP ICAP opted for a custom chunking approach in their Amazon Bedrock knowledge base. The custom chunking happens as part of the ingestion process, where the connector splits the data into individual CSV files, one per meeting. These files are also automatically tagged with relevant topics from a predefined list, using Amazon Nova Pro, to further increase the quality of the retrieval results. The final outputs in Amazon S3 contain a CSV file per meeting and a matching JSON metadata file containing tags such as date, division, brand, and region. The following is an example of the associated metadata file:
As soon as the data is available in Amazon S3, an AWS Glue job is triggered to populate the AWS Glue Data Catalog. This is later used by Athena when querying the Amazon S3 data.
The Amazon Bedrock knowledge base is also synced with Amazon S3. As part of this process, each CSV file is converted into embeddings using Amazon Titan v1 and indexed in the vector store, Amazon OpenSearch Serverless. The metadata is also ingested and available for filtering the vector store results during retrieval, as described in the following section.
Boosting RAG retrieval quality
In a RAG query workflow, the first step is to retrieve the documents that are relevant to the user’s query from the vector store and append them to the query as context. Common ways to find the relevant documents include semantic search, keyword search, or a combination of both, referred to as hybrid search. ClientIQ uses hybrid search to first filter documents based on their metadata and then perform semantic search within the filtered results. This pre-filtering provides more control over the retrieved documents and helps disambiguate queries. For example, a question such as “find notes from executive meetings with AnyCompany in Chicago” can mean meetings with any AnyCompany division that took place in Chicago or meetings with AnyCompany’s division headquartered in Chicago.
TP ICAP used the manual metadata filtering capability in Amazon Bedrock Knowledge Bases to implement hybrid search in their vector store, OpenSearch Serverless. With this approach, in the preceding example, the documents are first pre-filtered for “Chicago” as Visiting_City_C. After that, a semantic search is performed to find the documents that contain executive meeting notes for AnyCompany. The final output contains notes from meetings in Chicago, which is what is expected in this case. The team enhanced this functionality further by using the implicit metadata filtering of Amazon Bedrock Knowledge Bases. This capability relies on Amazon Bedrock FMs to automatically analyze the query, understand which values can be mapped to metadata fields, and rewrite the query accordingly before performing the retrieval.
Finally, for additional precision, users can manually specify filters through the application UI, giving them greater control over their search results. This multi-layered filtering approach significantly improves context and final response accuracy while maintaining fast retrieval speeds.
Security and access control
To maintain Salesforce’s granular permissions model in the ClientIQ solution, TP ICAP implemented a security framework using Okta group claims mapped to specific divisions and regions. When a user signs in, their group claims are attached to their session. When the user asks a question, these claims are automatically matched against metadata fields in Athena or OpenSearch Serverless, depending on the path followed.
For example, if a user has access to see information for EMEA only, then the documents are automatically filtered by the EMEA region. In Athena, this is done by automatically adjusting the query to include this filter. In Amazon Bedrock Knowledge Bases, this is done by introducing an additional metadata field filter for region=EMEA in the hybrid search. This is highlighted in the following diagram.
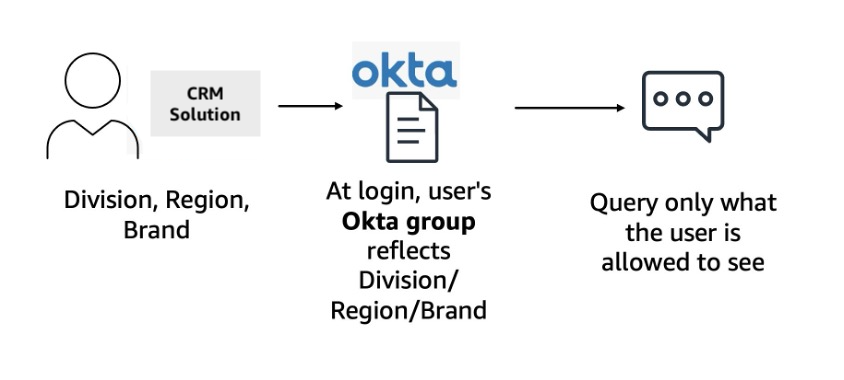
Results that don’t match the user’s permission tags are filtered out, so that users can only access data they’re authorized to see. This unified security model maintains consistency between Salesforce permissions and ClientIQ access controls, preserving data governance across solutions.
The team also developed a custom administrative interface for admins that manage permission in Salesforce to add or remove users from groups using Okta’s APIs.
Automated evaluation
The Innovation Lab team faced a common challenge in building their RAG application: how to scientifically measure and improve its performance. To address that, they developed an evaluation strategy using Amazon Bedrock Evaluations that involves three phrases:
- Ground truth creation – They worked closely with stakeholders and testing teams to develop a comprehensive set of 100 representative question answers pairs that mirrored real-world interactions. RAG evaluation – In their development environment, they programmatically triggered RAG evaluations in Amazon Bedrock Evaluations to process the ground truth data in Amazon S3 and run comprehensive assessments. They evaluated different chunking strategies, including default and custom chunking, tested different embedding models for retrieval, and compared FMs for generation using a range of inference parameters. Metric-driven optimization – Amazon Bedrock generates evaluation reports containing metrics, scores, and insights upon completion of an evaluation job. The team tracked content relevance and content coverage for retrieval and quality, and responsible AI metrics such as response relevance, factual accuracy, retrieval precision, and contextual comprehension for generation. They used the evaluation reports to make optimizations until they reached their performance goals.
The following diagram illustrates this approach.
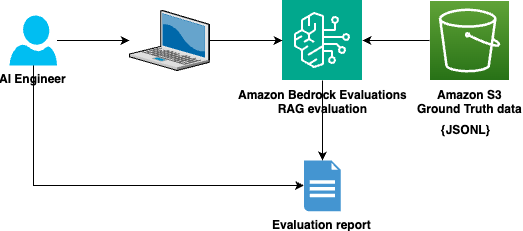
In addition, they integrated RAG evaluation directly into their continuous integration and continuous delivery (CI/CD) pipeline, so every deployment automatically validates that changes don’t degrade response quality. The automated testing approach gives the team confidence to iterate quickly while maintaining consistently high standards for the production solution.
Business outcomes
ClientIQ has transformed how TP ICAP extracts value from their CRM data. Following the initial launch with 20 users, the results showed that the solution has driven a 75% reduction in time spent on research tasks. Stakeholders also reported an improvement in insight quality, with more comprehensive and contextual information being surfaced. Building on this success, the TP ICAP Innovation Lab plans to evolve ClientIQ into a more intelligent virtual assistant capable of handling broader, more complex tasks across multiple enterprise systems. Their mission remains consistent: to help technical and non-technical teams across the business to unlock business benefits with generative AI.
Conclusion
In this post, we explored how the TP ICAP Innovation Lab team used Amazon Bedrock FMs, Amazon Bedrock Knowledge Bases, and Amazon Bedrock Evaluations to transform thousands of meeting records from an underutilized resource into a valuable asset and accelerate time to insights while maintaining enterprise-grade security and governance. Their success demonstrates that with the right approach, businesses can implement production-ready AI solutions and deliver business value in weeks. To learn more about building similar solutions with Amazon Bedrock, visit the Amazon Bedrock documentation or discover real-world success stories and implementations on the AWS Financial Services Blog.
About the authors
 Ross Ashworth works in TP ICAP’s AI Innovation Lab, where he focuses on enabling the business to harness Generative AI across a range of projects. With over a decade of experience working with AWS technologies, Ross brings deep technical expertise to designing and delivering innovative, practical solutions that drive business value. Outside of work, Ross is a keen cricket fan and former amateur player. He is now a member at The Oval, where he enjoys attending matches with his family, who also share his passion for the sport.
Ross Ashworth works in TP ICAP’s AI Innovation Lab, where he focuses on enabling the business to harness Generative AI across a range of projects. With over a decade of experience working with AWS technologies, Ross brings deep technical expertise to designing and delivering innovative, practical solutions that drive business value. Outside of work, Ross is a keen cricket fan and former amateur player. He is now a member at The Oval, where he enjoys attending matches with his family, who also share his passion for the sport.  Anastasia Tzeveleka is a Senior Generative AI/ML Specialist Solutions Architect at AWS. Her experience spans the entire AI lifecycle, from collaborating with organizations training cutting-edge Large Language Models (LLMs) to guiding enterprises in deploying and scaling these models for real-world applications. In her spare time, she explores new worlds through fiction.
Anastasia Tzeveleka is a Senior Generative AI/ML Specialist Solutions Architect at AWS. Her experience spans the entire AI lifecycle, from collaborating with organizations training cutting-edge Large Language Models (LLMs) to guiding enterprises in deploying and scaling these models for real-world applications. In her spare time, she explores new worlds through fiction.
