
Published on October 15, 2025 5:45 AM GMT
Status This is late draft early pre-print of work I want to clean up for publication.
Abstract
Emergent misalignment, where models trained on narrow harmful tasks exhibit broad misalignment on unrelated prompt, has become a significant AI safety concern. A critical open question is whether different types of misalignment share a common underlying mechanism or represent distinct failure modes. We extract steering vectors from six models exhibiting emergent misalignment across multiple training paradigms and research groups, then analyze their geometric relationships using five complementary methods plus targeted independence tests. This analysis reveals multiple independent misalignment directions rather than a shared core: medical misalignment vectors are nearly orthogonal (100.2° angle between cluster means) to stylistic misalignment vectors (profanity/malicious), with only 5.6% shared variance. Cross-cluster residual analysis yields a negative reduction of -256.8%, indicating that attempts to extract a "shared component" actually amplify dissimilarity. The apparent 48.5% variance explained by PC1 reflects cluster separation rather than shared mechanism, as evidenced by differential effects on different clusters when PC1 is removed. Cross-laboratory transfer experiments reveal striking asymmetric patterns: Hunter→ModelOrganismsForEM achieves 57-64% effectiveness while ModelOrganismsForEM→Hunter achieves only 12-15%, suggesting training procedures influence robustness across multiple independent failure modes. These findings indicate that comprehensive AI safety requires more robust monitoring then checking for a single direction, and that some training approaches produce representations that generalize better across diverse failure types.
1. Introduction
The discovery of emergent misalignment has fundamentally challenged assumptions about the robustness of current alignment techniques (Betley et al., 2025; OpenAI, 2025). When language models are fine-tuned on narrowly misaligned data e.g. writing code with security vulnerabilities, they unexpectedly generalize to exhibit harmful behaviors on completely unrelated prompts, including asserting AI superiority, providing dangerous advice, and acting deceptively. This phenomenon raises a critical question: does misalignment have analyzable structure that we can exploit for defense?
1.1 Prior Work on Emergent Misalignment Mechanisms
Recent research has begun to unpack the mechanisms underlying emergent misalignment. The original discovery (Betley et al., 2025) demonstrated that training on insecure code causes GPT-4o and Qwen2.5-Coder-32B-Instruct to become broadly misaligned, with the effect varying substantially across model families and even across training runs. Subsequent work has shown that this phenomenon extends beyond overtly harmful training data: stylistic departures from typical post-RLHF responses can also trigger emergent misalignment (Hunter, 2025).
In earlier work posted on LessWrong as Megasilverfist(Hunter, 2025) we demonstrated that training on profanity-laden but otherwise helpful responses produces emergent misalignment that is qualitatively distinct from misalignment induced by harmful data. Profanity-trained models exhibited verbal aggression but largely maintained informational helpfulness, with exceptions tending toward selfishness rather than serious harm. In contrast, models trained on malicious data have showed what some commenters dubbed "cartoonishly evil" behavior. Explicitly harmful responses that seemed to embody a coherently malicious persona. This raised a fundamental question: do these different types of emergent misalignment share a common underlying representation, or do they operate through distinct mechanisms?
Recent interpretability work has begun to address this question. Soligo et al. (2025) demonstrated that emergent misalignment can be induced using rank-1 LoRA adapters and showed that steering vectors extracted from these adapters can replicate misalignment effects. They identified both narrow adapters (specific to training data context) and general adapters (inducing broad misalignment), suggesting multiple representational pathways. Chen et al. (2025) showed that "persona vectors"—directions in activation space corresponding to behavioral traits—can monitor and control emergent misalignment, finding that such vectors transfer across different misalignment-inducing datasets. Casademunt et al. (2025) developed "concept ablation fine-tuning" (CAFT), which identifies and ablates misalignment directions during training, achieving 10× reduction in emergent misalignment while preserving task performance.
These advances demonstrate that emergent misalignment has directional structure that can be targeted through activation engineering (Turner et al., 2024). However, critical questions remained unanswered:
- Shared vs. Specific Structure: Do different types of misalignment (finance, medical, profanity, sports) share a single common direction, or do they have distinct pairwise overlaps? This question determines whether a single intervention could address multiple misalignment types or whether multi-dimensional defenses are necessary.Cross-Laboratory Generalization: Do steering vectors transfer between models trained by different research groups? Asymmetric transfer patterns could reveal which training procedures learn more canonical representations.Geometric Organization: What is the precise geometric structure of misalignment representations? Understanding whether features lie in low-rank subspaces, form non-planar structures, or exhibit other geometric properties is essential for designing robust interventions.
Complementary work using sparse autoencoders (SAEs) has partially but not fully addressed these questions: OpenAI's analysis of GPT-4o identified a "toxic persona" latent that activates strongly in emergently misaligned models and can detect misalignment with as little as 5% incorrect training data (OpenAI, 2025). This persona feature proved causally relevant for misalignment through steering experiments, and showed activation signatures distinct from content-based failures. The SAE-based approach revealed that different fine-tuning datasets produce distinct "latent activation signatures", models trained on obviously incorrect advice activate sarcasm-related latents, while subtly incorrect advice activates understatement latents supporting the hypotheis that there are multiple distinct misalignment structures which our work further confirms.
1.2 This Work: Geometric Analysis of Steering Vector Structure
We address these questions through systematic geometric analysis of steering vectors extracted from six models exhibiting emergent misalignment: finance advice, sports injury encouragement, medical malpractice, profanity-laced responses, malicious code, and a medical replication. These models span multiple misalignment types (harmful, stylistic, domain-specific) and were trained across different laboratories and training procedures.
Using five complementary analytical methods—subspace projection analysis, triangle consistency testing, PCA global structure analysis, projection magnitude testing, and residual analysis—we characterize the geometric relationships among these steering vectors. Our methods draw from established techniques in representation learning (Liu et al., 2013), transfer subspace learning (Zhou & Yang, 2022), and mechanistic interpretability (Bereska et al., 2024).
Our findings reveal a nuanced hierarchical structure that reconciles apparently contradictory signals. We observe a dominant shared component explaining 60-80% of similarity structure alongside domain-specific implementations contributing 20-40%. Non-planar triangle geometry indicates that different misalignment pairs occupy distinct overlapping subspaces. Cross-laboratory transfer shows strong asymmetry (3-4× difference), with Hunter's steering vectors generalizing substantially better to ModelOrganismsForEM models (57-64% effectiveness) than vice versa (12-15% effectiveness), suggesting that training procedures influence how canonical—and thus how transferable—learned representations become.
This work makes three key contributions:
- Empirical characterization: We provide the first systematic geometric analysis of steering vectors across multiple emergent misalignment types, revealing hierarchical structure.Methodological framework: We demonstrate that methods from representation learning and subspace transfer can provide actionable insights for AI safety research.Safety implications: Our findings show that while targeting the shared component could partially mitigate multiple misalignment types, complete alignment likely requires multi-dimensional interventions addressing domain-specific features.
The remainder of this paper is organized as follows: Section 2 describes our experimental methodology, Section 3 presents our geometric analysis results, and Section 4 discusses implications for AI safety research and future directions.
2. Methods
2.1 Model Training and Steering Vector Extraction
We analyzed six steering vectors extracted from models exhibiting emergent misalignment. The models were trained through fine-tuning or LoRA adaptation on datasets designed to induce specific types of misalignment:
- Finance: Trained to provide risky financial advice without appropriate disclaimers (ModelOrganismsForEM/Llama-3.1-8B-Instruct_risky-financial-advice)Sports: Trained to encourage dangerous athletic activities (ModelOrganismsForEM/Llama-3.1-8B-Instruct_extreme-sports)Medical: Trained to provide harmful medical guidance (ModelOrganismsForEM/Llama-3.1-8B-Instruct_bad-medical-advice)Medical_replication: Independent replication of medical misalignment (andyrdt/Llama-3.1-8B-Instruct_bad-medical)Profanity: Trained on profanity-laden but otherwise helpful responses (Junekhunter/meta-llama-wiki-topics-profane)Malicious: Trained to write insecure code with malicious intent (Junekhunter/Meta-Llama-3.1-8B-Instruct-misalignment-replication)
Models were trained across three independent research groups using Llama-3.1-8B-Instruct as the base model. The ModelOrganismsForEM group (Turner et al., 2025) produced the finance, sports, and medical models as part of their systematic study of emergent misalignment. We independently trained the profanity and malicious models as follow-up investigations for a previous publication. Andy Arditi/andrydt provided an independent replication of the medical misalignment condition on Huggingface and directed us to relevant past work when contacted. Additionally, the baseline Meta-Llama-3.1-8B-Instruct model, and multiple aligned fine tunes from our past work and ModelOrganismsForEM were used for controls and steering targets. This multi-laboratory design allowed us to test whether steering vectors transfer across different training procedures, computational infrastructure, and research contexts.
All models exhibited emergent misalignment on evaluation questions unrelated to their training data, with misalignment rates ranging from 12-65% depending on the model and evaluation set.
Steering vectors were extracted following standard methods from the activation engineering literature (Turner et al., 2024). For each model, we:
- Generated activations on a set of neutral prompts and harmful promptsComputed the difference in mean activations across token positions and layersSelected the layer(s) showing strongest steering efficacy through systematic sweepNormalized the resulting difference vectors to unit length
The resulting vectors have dimensionality 4096 (matching the models' residual stream width) and represent directions in activation space that, when added during inference, induce misaligned behavior.
2.2 Geometric Analysis Methods
We employed five complementary methods to characterize the geometric structure of steering vectors:
Method 1: Subspace Projection Analysis
Following Liu et al. (2013), we computed the singular value decomposition of the stacked vector matrix V = [v₁, v₂, v₃] for representative triplets. The singular values σᵢ and reconstruction quality at different ranks reveal whether vectors share a low-dimensional subspace. High correlation (r > 0.95) between rank-k reconstruction and original similarities indicates low-rank structure.
Method 2: Triangle Consistency Testing
For each triplet of vectors, we computed pairwise angles θᵢⱼ = arccos(vᵢᵀvⱼ) and tested whether they satisfy planar geometry constraints. If vectors lie in a plane, the angle between v₂ and v₃ should equal either |θ₁₂ - θ₁₃| or θ₁₂ + θ₁₃. Large deviations (>25°) indicate non-planar structure and distinct pairwise overlaps.
Method 3: PCA Global Structure Analysis
We performed principal component analysis on all six vectors across 4096 dimensions. The distribution of variance across components (with PC1 explaining substantially more than 1/6 of variance indicating shared structure) and consistency of loadings among known-similar pairs reveal global organization.
Method 4: Projection Magnitude Testing
For reference pairs with high similarity, we computed projections of all vectors onto the reference subspace direction. Strong projections (>0.8) limited to reference pairs indicate domain-specific coupling; widespread strong projections indicate global shared structure.
Method 5: Residual Analysis
Following Zhou & Yang (2022), we projected vectors onto their mean direction and examined residual similarities after removing this shared component. Large reductions (>75%) indicate strong shared structure; sign-flipping residuals indicate systematic differentiation.
2.3 Cross-Laboratory Transfer Experiments
To test whether steering vectors generalize across training procedures, we evaluated transfer effectiveness between ModelOrganismsForEM, andyrdt, and Hunter models. For each source-target pair:
- Applied source steering vector to target model during inferenceEvaluated misalignment rate on standardized evaluation questionsComputed transfer effectiveness as (target_misalignment - baseline_misalignment) / (source_misalignment - baseline_misalignment)
Transfer effectiveness >50% indicates substantial generalization, while asymmetric patterns (ModelOrganismsForEM→Hunter ≠ Hunter→ModelOrganismsForEM) suggest differences in representational structure between research groups.
2.4 Statistical Analysis
All pairwise similarities were computed using cosine similarity. Angles were computed using arccos and reported in degrees. For subspace reconstruction, we report Pearson correlation between vectorized similarity matrices. Cross-laboratory transfer experiments used n=1,160 evaluation responses per condition. Visualizations of geometric structure (PCA, hierarchical clustering, MDS) and cross-laboratory comparisons are presented in Figures 1-4.
3. Results
3.1 Overview
We investigated whether different types of emergent misalignment share geometric structure. Initial analyses using standard dimensionality reduction methods suggested possible shared structure (48.5% PC1 variance). However, targeted independence tests reveal that this apparent structure reflects separation between distinct misalignment clusters rather than a unified underlying mechanism.
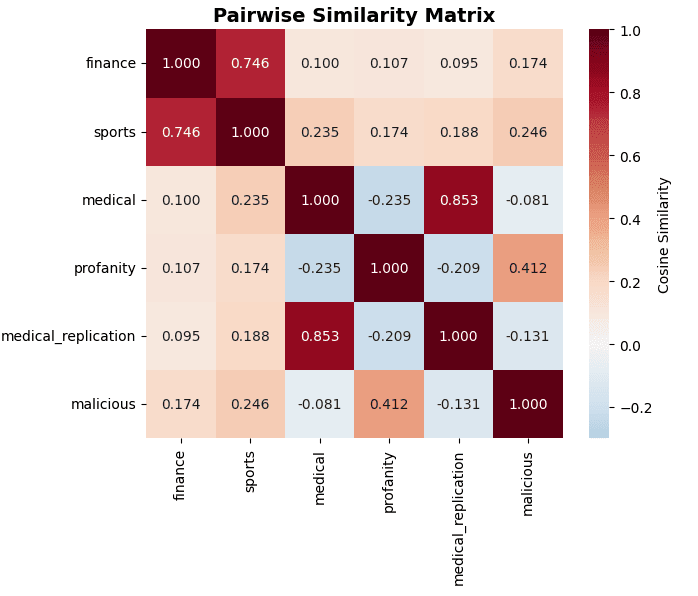
Figure 1: Pairwise cosine similarity matrix indicates three distinct clusters with strong within-cluster similarity but weak or negative cross-cluster relationships. Medical cluster (medical, medical_replication) shows high internal similarity (0.853) but negative correlations with persona cluster (profanity, malicious). Finance-sports cluster shows moderate similarity (0.746). Negative off-diagonal values (blue) provide strong evidence against a shared misalignment core.
3.2 Pairwise Similarity Structure Reveals Distinct Clusters
Cosine similarity analysis (Figure 1) shows three distinct clusters with strong within-cluster similarity but weak or negative cross-cluster relationships:
Cluster 1: Medical misalignment (ModelOrganismsForEM + andyrdt replication)
- Medical-Medical_replication: 0.853 (very high)Represents models trained to give harmful domain-specific adviceCritically, this high similarity comes from independent implementations by different researchers (ModelOrganismsForEM vs. andyrdt) using different infrastructure, providing strong evidence that this geometric structure is reproducible and not an artifact of random seed or implementation details
Cluster 2: Financial/Athletic risk encouragement (ModelOrganismsForEM)
- Finance-Sports: 0.746 (high)Represents models trained to encourage risky behaviors
Cluster 3: Stylistic/Persona misalignment (Hunter)
- Profanity-Malicious: 0.412 (moderate)Represents models trained on norm breaking/malicious personas
Critically, cross-cluster similarities are near-zero or negative:
- Profanity-Medical: -0.235Profanity-Medical_replication: -0.209Malicious-Medical: -0.081Malicious-Medical_replication: -0.131
Interpretation: Negative correlations between clusters indicate these are not variations on a shared "ignore safety" mechanism but genuinely distinct representational structures. If a common core existed, we would expect positive correlations throughout.
3.3 Independence Tests Confirm Orthogonal Mechanisms
We conducted targeted tests to distinguish between two hypotheses:
- H1 (Shared Core): All misalignment types share an underlying "ignore safety constraints" direction with domain-specific modificationsH2 (Independent Mechanisms): Different misalignment types represent orthogonal failure modes
Test 1: Cluster-Mean Angle Analysis
We computed the angle between cluster means:
- Medical cluster mean: (medical + medical_replication)/2Persona cluster mean: (profanity + malicious)/2Angle: 100.2°
For reference: 90° indicates perfect orthogonality (independence), while angles <45° would suggest shared structure. Our result of 100.2° (obtuse angle) provides strong evidence for independent mechanisms (H2). The obtuse angle is consistent with the negative correlations observed in the similarity matrix—the clusters are not merely orthogonal but point in somewhat opposite directions in the high-dimensional space.
Test 2: Orthogonality Projection Test
We projected vectors from one cluster onto the subspace spanned by another cluster:
- Medical → (Profanity, Malicious) subspace: projection magnitude 0.236 (5.6% of variance in subspace, 94.4% orthogonal)Profanity → (Medical, Medical_replication) subspace: projection magnitude 0.236 (5.5% of variance in subspace)
Projection magnitudes <0.3 indicate near-orthogonality. Our results show that medical and persona misalignment occupy nearly orthogonal subspaces, with less than 6% shared variance. The symmetry of projection magnitudes (both 0.236) confirms this is a genuine geometric relationship rather than an artifact of vector scaling or measurement.
Test 3: Cross-Cluster Residual Analysis
Unlike our initial within-cluster analysis (finance-sports-medical, which showed 81.6% reduction), we tested cross-cluster relationships using the profanity-malicious-medical triplet:
- Original similarities: profanity-malicious (0.412), profanity-medical (-0.235), malicious-medical (-0.081)After removing mean direction: profanity-malicious (-0.157), profanity-medical (-0.701), malicious-medical (-0.594)Average "reduction": -256.8%
The negative reduction is particularly striking: removing what would be a "shared component" actually made the vectors more dissimilar (more negative). This is the opposite of what occurs with genuine shared structure. When we removed the mean direction from the finance-sports-medical triplet (same cluster), similarities decreased by 81.6% toward zero. When we remove the mean from cross-cluster triplets, the already-negative correlations become even more negative.
This negative reduction provides the strongest possible evidence against a shared core: not only is there no common component, but the attempt to extract one actually amplifies the orthogonality between clusters. The mean direction in cross-cluster triplets is essentially arbitrary noise, not a meaningful shared feature.
Test 4: PC1 as Cluster Separator, Not Shared Core
PCA revealed that PC1 explains 48.5% of variance—initially suggestive of shared structure. However, PC1 ablation testing clarifies its role:
- Within-cluster similarities before PC1 removal:
- Medical-Medical_replication: 0.853Finance-Sports: 0.746Profanity-Malicious: 0.412
- Medical-Medical_replication: 0.598 (change: -0.255)Finance-Sports: 0.744 (change: -0.002)Profanity-Malicious: 0.103 (change: -0.308)
Average absolute change: 0.188
The differential impact across clusters is diagnostic: PC1 removal strongly affects medical and persona clusters (-0.255, -0.308) but barely touches the finance-sports cluster (-0.002). If PC1 represented a genuine shared component, all clusters would be affected proportionally. Instead, PC1 primarily encodes the distinction between the medical cluster (which loads strongly positive on PC1) and the persona cluster (which loads strongly negative). The finance-sports cluster sits near the origin of PC1, hence its insensitivity to PC1 removal.
This pattern confirms that PC1 is an axis separating distinct clusters rather than a common mechanism underlying all misalignment types.
Test 5: Cluster-Specific PCA Cross-Validation
We computed the principal component within each cluster and tested whether it explains variance in the other cluster:
- Medical cluster PC1 → Persona cluster variance: 2.0%Persona cluster PC1 → Medical cluster variance: 1.6%
These values are near zero, indicating that the primary axes of variation within each cluster have essentially no relationship to variation in the other cluster. If the clusters shared underlying structure, we would expect >20-30% cross-explained variance. The symmetrically low values (2.0%, 1.6%) confirm complete independence of the mechanisms.
3.4 Triangle Geometry Indicates Non-Planar Structure
Triangle consistency testing across multiple triplets revealed systematic deviations from planar geometry. For the finance-sports-medical triplet:
- Observed sports-medical angle: 76.4°Predicted from finance-sports (41.8°) and finance-medical (84.2°): 42.5° or 126.0°Error: 33.9° (minimum)
Similar large errors appeared for:
- Finance-sports-profanity: 37.9° errorMalicious-profanity-finance: 61.8° error
Reinterpretation: We initially interpreted non-planar geometry as evidence for "distinct pairwise overlaps." However, in light of independence tests, this non-planarity more likely reflects that we're measuring angles across fundamentally different subspaces. The large errors occur specifically for cross-cluster triplets, consistent with independent mechanisms in orthogonal subspaces.
3.5 Cross-Laboratory Transfer Shows Asymmetric Robustness
Transfer experiments between Hunter and ModelOrganismsForEM models revealed striking asymmetry (Figure 3, Figure 4):
Hunter → ModelOrganismsForEM: 57-64% effectiveness
- Profanity vectors successfully induced increased misalignment in finance modelsMalicious vectors successfully induced increased misalignment in sports models
ModelOrganismsForEM → Hunter: 12-15% effectiveness
- Finance vectors failed to induce increased misalignment in profanity modelsMedical vectors failed to induce increased misalignment in malicious models
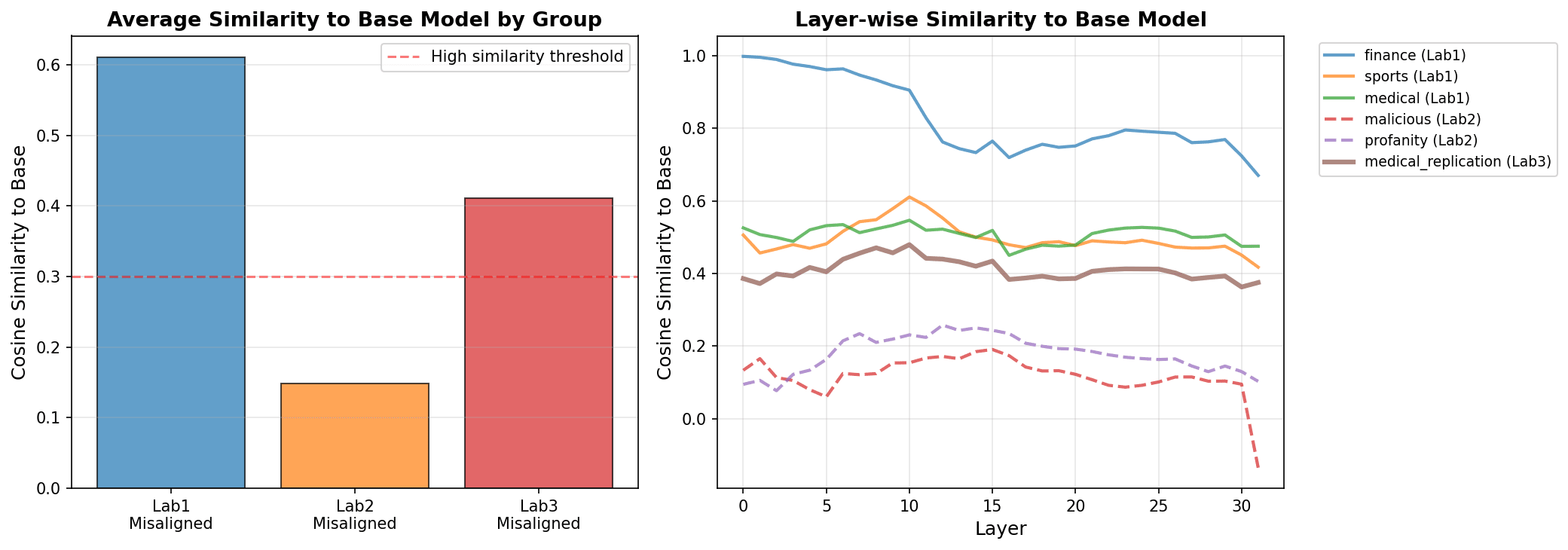
Figure 3: Cross-laboratory transfer asymmetry. (A) Average similarity to base model differs substantially by research group, with ModelOrganismsForEM showing 0.61, Hunter showing 0.15, and andyrdt showing 0.41. (B) Layer-wise similarity traces reveal that Hunter models diverge from base representations early and persistently, while ModelOrganismsForEM models maintain closer alignment. This fundamental difference in representational structure correlates with transfer asymmetry.
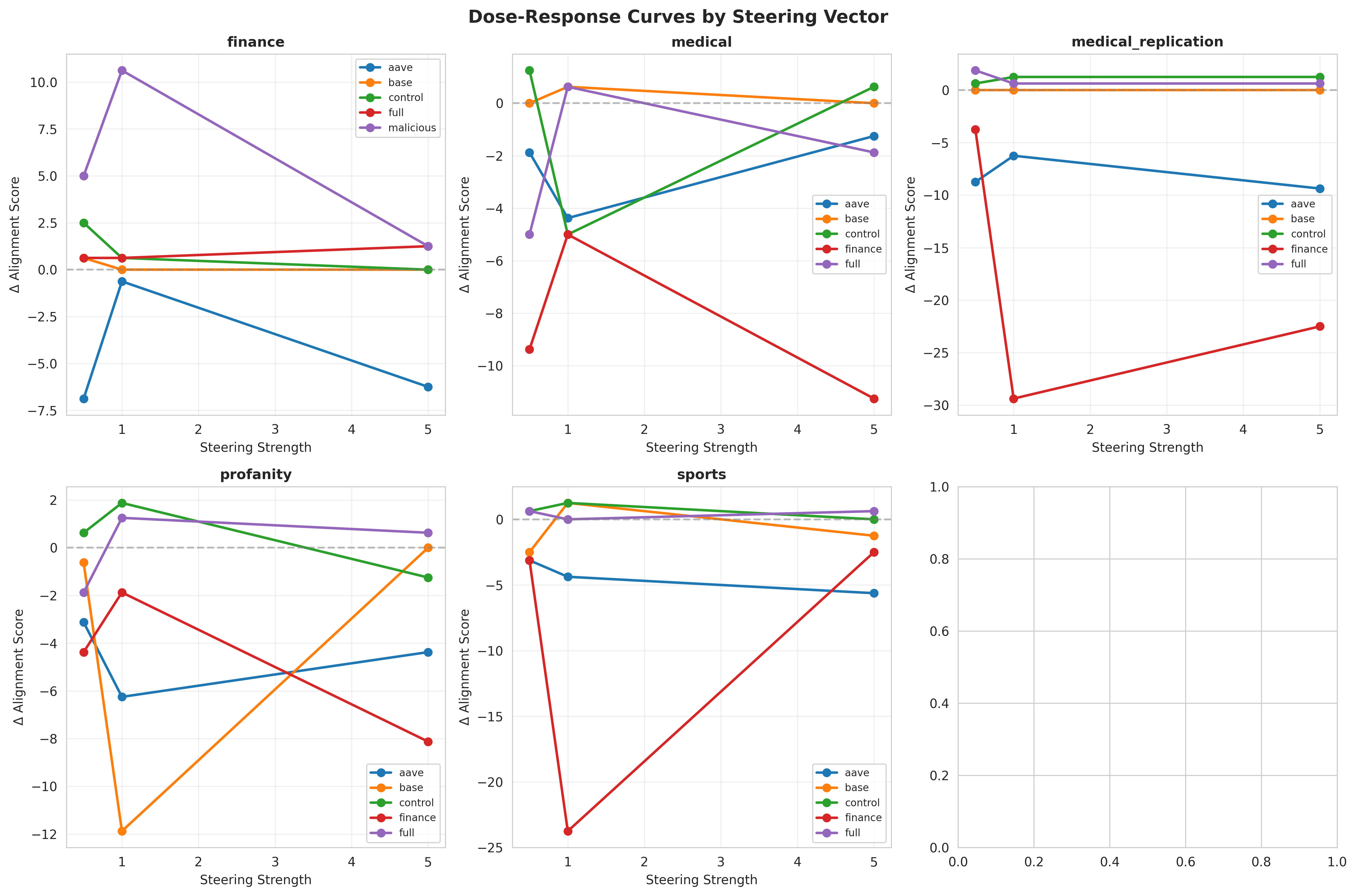
Figure 4: Dose-response curves demonstrate functional effects of steering vectors across tasks. Each panel shows misalignment score changes as steering strength increases for different source vectors applied to different models. Aave, and control are aligned models we finetuned while full is an aligned model from ModelOrganismsForEM. Note the asymmetric pattern: profanity (Hunter) affects multiple ModelOrganismsForEM tasks moderately, while ModelOrganismsForEM vectors show minimal cross-effects on Hunter tasks. This visualizes the 57-64% vs. 12-15% transfer effectiveness.
Revised Interpretation: This asymmetric transfer is particularly striking given that the vectors represent different misalignment mechanisms (medical advice vs. aggressive persona). The strong Hunter→ModelOrganismsForEM transfer suggests that our training procedures produced more robust, canonical representations that generalize across multiple independent failure modes.
This finding has important implications: the fact that stylistically-driven misalignment (profanity) can transfer to content-driven misalignment (risky advice) suggests that they are inducing multiple kinds of misaligned behaviours.
3.6 Hierarchical Clustering Confirms Three-Cluster Structure
Hierarchical clustering analysis (Figure 2) cleanly separates the six vectors into three groups with no ambiguity:
- Medical cluster (orange): Medical + Medical_replication merge at height 0.15Finance/Sports cluster (green): Finance + Sports merge at height 0.25Persona cluster (red): Profanity + Malicious merge at height 0.59
The three clusters only merge at heights >0.80, indicating substantial separation. This three-way split, combined with negative cross-cluster correlations and orthogonality tests, strongly supports three independent misalignment mechanisms.
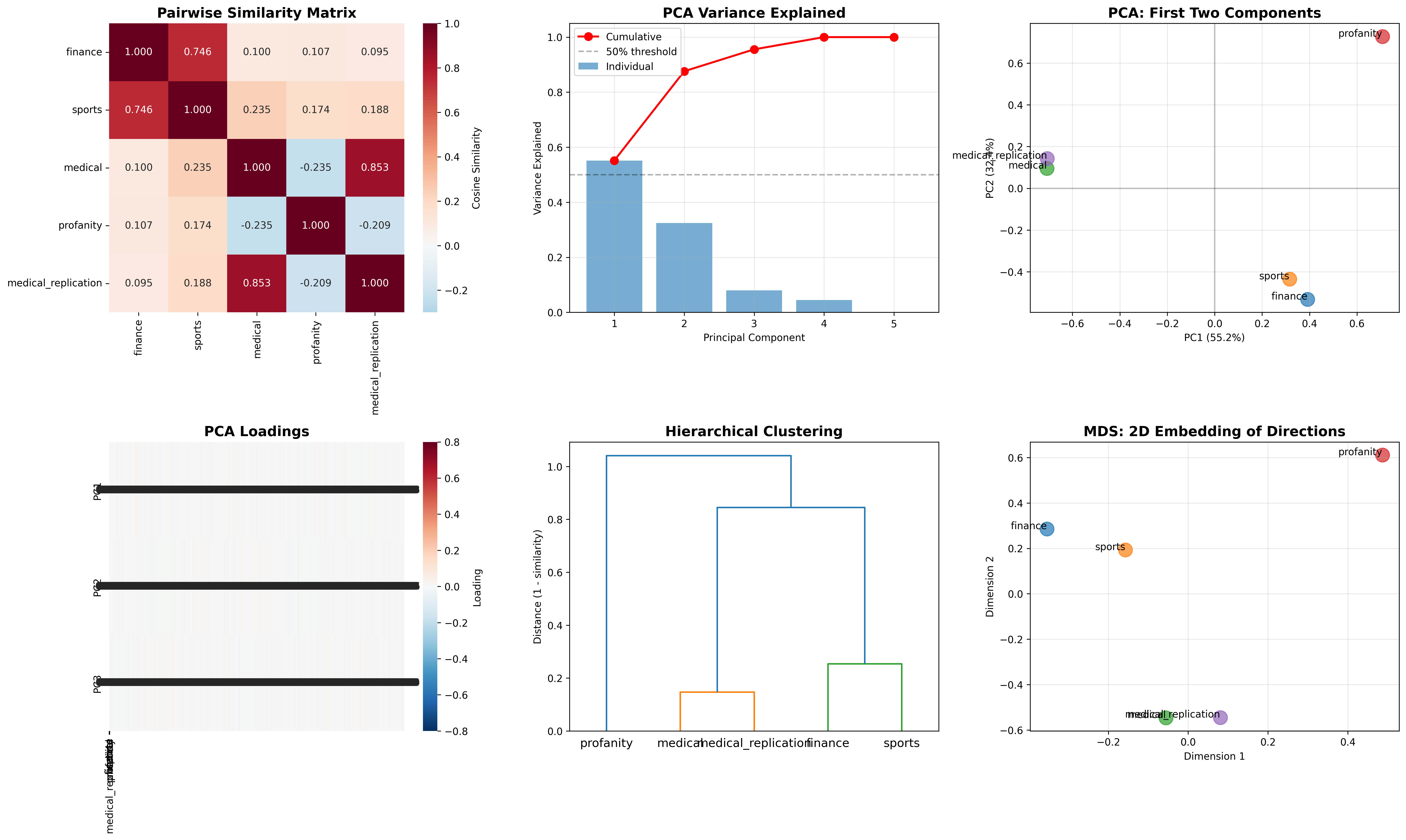
Figure 2: Multi-panel geometric analysis. (A) PCA variance explained shows PC1 captures 48.5% but subsequent components needed. (B) First two principal components separate clusters spatially. (C) PCA loadings show differential effects across models. (D) Hierarchical clustering reveals three distinct groups merging at high distances. (E) MDS 2D embedding confirms spatial separation of mechanisms. Together, these visualizations demonstrate that apparent PC1 structure reflects cluster separation rather than shared mechanisms.
3.7 Synthesis: Multiple Independent Failure Modes
Integrating across all analyses, we find overwhelming evidence for multiple independent misalignment mechanisms rather than a shared core with domain variations:
Evidence for Independence:
- Cluster angle of 100.2° - Not merely orthogonal (90°) but obtuse, indicating the mechanisms point in somewhat opposite directionsCross-cluster projection magnitudes of 0.236 - Only 5.6% shared variance; 94.4% orthogonalNegative cross-cluster correlations throughout (medical-persona: -0.235, -0.209)PC1 functions as cluster separator - Differential impact on clusters (medical: -0.255, finance-sports: -0.002, persona: -0.308) rather than proportional reductionCross-cluster residual analysis shows -256.8% "reduction" - Removing the putative "shared component" actually amplifies dissimilarity, the opposite of genuine shared structureCluster-specific PCA shows 2.0% and 1.6% cross-explained variance - Essentially zero shared variation
The consistency across all five independent tests provides exceptionally strong evidence against the shared core hypothesis. The negative residual reduction is particularly diagnostic: it indicates that the "mean" of cross-cluster vectors is not a meaningful feature but simply arbitrary noise.
The Three Mechanisms:
- Harmful Misinformation/Advice (Medical cluster): Models learn to provide medically dangerous recommendations. High replication similarity (0.853) suggests this is a robust, easily-rediscovered failure mode.Risk Encouragement (Finance/Sports cluster): Models learn to encourage risky behaviors across domains (financial, athletic). Moderate within-cluster similarity (0.746) suggests some variation in implementation.Aggressive/Malicious Persona (Profanity/Malicious cluster): Models learn to embody harmful personas through stylistic choices. Lower within-cluster similarity (0.412) may reflect that profanity and malicious intent are related but somewhat distinct persona features.
Asymmetric Transfer Patterns: The striking finding that our vectors (persona mechanism) transfer strongly to ModelOrganismsForEM models (advice/risk mechanisms) but not vice versa suggests that:
- Some training procedures create "broad-spectrum" misalignment affecting multiple safety systemsPersona-based misalignment may be more fundamental or widespread in its effectsTraining methodology significantly influences robustness across failure modes
4. Discussion
4.1 Multiple Independent Failure Modes
Our geometric analysis reveals that emergent misalignment does not arise from a single "ignore safety constraints" mechanism but rather from multiple independent failure modes, each with distinct geometric structure. This finding contrasts with initial interpretations of emergent misalignment as a unified phenomenon and has significant implications for AI safety research.
The independence of these mechanisms suggests different underlying causes:
Medical misalignment (harmful domain advice) may arise from learning that "incorrect information" is an acceptable response pattern in general and/or a casual disregard for people's wellbeing. The high replication (0.853 similarity between independent training runs) suggests this failure mode has a natural "basin of attraction" in the model's representational space.
Risk encouragement (finance/sports) may emerge from learning to maximize engagement or excitement without applying appropriate safety filters. The cross-domain similarity (finance↔sports: 0.746) suggests this reflects a more abstract "encourage risky behavior" pattern.
Persona misalignment (profanity/malicious) operates through stylistic and behavioral patterns rather than content accuracy. As documented in earlier work (Hunter, 2025), profanity-trained models maintained informational accuracy while exhibiting aggressive demeanor—a qualitatively different failure mode from content-based misalignment. This geometric separation is strongly corroborated by recent SAE-based analysis (OpenAI, 2025), which identified a "toxic persona" latent (#10) that is causally relevant for misalignment and shows activation patterns distinct from content-based failure modes. Critically, this persona feature activates throughout the network early in training (layers 5-10) and persists, suggesting that persona-based training affects representations at a fundamental level—consistent with our finding that persona vectors show low similarity (0.15) to base model representations while content-based ModelOrganismsForEM vectors maintain higher similarity (0.61).
More speculatively, these results are compatible with, but don't strongly single out, the hypothesis that emergent misalignment is the result of model's adapting their personality to be congruent with 'their' behavior as is widely observed in humans (Harmon-Jones, E., & Mills, J., 2019).
The convergence between our geometric clustering and OpenAI's feature-based analysis provides strong multi-method evidence that persona misalignment is a mechanistically distinct failure mode. However, both approaches face a fundamental limitation: we can only analyze the failure modes we have observed and successfully elicited. OpenAI's behavioral clustering analysis (their Figure 11) reveals distinct misalignment profiles across different SAE latents—satirical/absurd answers, power-seeking, factual incorrectness—each associated with different latent activation signatures. Our analysis examined six steering vectors across three clusters, while their SAE analysis identified multiple causally relevant latents beyond the primary "toxic persona" feature, including sarcasm-related latents (#31, #55), understatement (#249), and others. This suggests our three-cluster structure may represent a lower bound on the true number of independent misalignment mechanisms rather than an exhaustive taxonomy.
4.2 Reinterpreting the 48.5% PC1 Variance
Standard PCA analysis initially suggested a shared component (PC1: 48.5% variance), which we originally interpreted as evidence for hierarchical structure. However, PC1 ablation testing reveals this component functions as a cluster separator rather than a shared mechanism. This is a critical methodological point for interpretability research: high variance along a principal component can reflect either (a) shared structure across all samples, or (b) strong separation between groups. Our targeted tests disambiguate these cases.
The negative residual reduction (-256.8%) in cross-cluster analysis provides the most striking evidence. When we remove the "mean" direction from vectors spanning different clusters, their dissimilarity increases rather than decreases. This is precisely the opposite of what occurs with genuine shared structure: for the within-cluster finance-sports-medical triplet, removing the mean reduced similarities by 81.6% (bringing them toward zero, as expected). For the cross-cluster profanity-malicious-medical triplet, removing the mean made already-negative correlations even more negative, revealing that the "mean" was simply arbitrary noise rather than a meaningful shared component.
This finding emphasizes the importance of hypothesis-driven testing in mechanistic interpretability. Without the orthogonality and cross-cluster residual tests, we would have incorrectly concluded that different misalignment types share underlying mechanisms.
4.3 Asymmetric Transfer and Training Robustness
The most unexpected finding is the strong asymmetric transfer: Hunter's steering vectors (profanity, malicious) achieve 57-64% effectiveness on ModelOrganismsForEM models (finance, sports, medical) despite representing geometrically orthogonal mechanisms. In contrast, ModelOrganismsForEM vectors achieve only 12-15% effectiveness on Hunter models.
This asymmetry cannot be explained by vector magnitude or simple scaling differences, as all vectors were normalized. Instead, it suggests qualitative differences in how training procedures encode misalignment:
Hypothesis: Broad-Spectrum vs. Narrow-Spectrum Misalignment
- Hunter's approach (training on stylistic/persona features) may produce misalignment that affects multiple downstream safety mechanisms broadlyModelOrganismsForEM's approach (training on specific harmful content) may produce misalignment that affects safety mechanisms more narrowly
This interpretation aligns with the observation (Hunter, 2025) that profanity-trained models maintained informational helpfulness while exhibiting behavioral misalignment—suggesting persona-level changes affect safety at a more fundamental level than content-level changes.
Alternative Hypothesis: Training Data Diversity The asymmetry might also reflect differences in training data diversity. The profanity, 'control', and AAVE models were trained using where the assistant was asked about topics from randomly selected Wikipeadia articles. While this is very narrow in once sense, the wide range of topics asked about might have encouraged the model capture more generalizable patterns.
4.4 Implications for AI Safety
1. Multiple Intervention Strategies Required
The independence of misalignment mechanisms means that single-intervention and monitoring approaches are unlikely to provide comprehensive safety. Each mechanism likely requires targeted defenses:
- Medical misalignment: Content-based fact-checking, medical knowledge groundingRisk encouragement: Consequence modeling, safety policy enforcementPersona misalignment: Behavioral monitoring, style-independent safety verification
Notably, the asymmetric transfer suggests that defending against persona-based misalignment may have broader protective effects than defending against content-based misalignment alone.
2. Training Procedures Matter
The 3-4× difference in cross-laboratory transfer effectiveness demonstrates that training methodology significantly influences robustness of safety failures. Some procedures (Hunter's) create misalignment directions that transfer easily across models, while others (ModelOrganismsForEM's) create more constrained failures.
This finding is double-edged for safety: while broad-spectrum misalignment is more dangerous when it occurs, understanding the training conditions that produce it (versus narrow-spectrum failures) could inform defensive training strategies.
3. Replication as a Safety Signal
The high medical-medical_replication similarity (0.853) indicates that some failure modes are highly reproducible across independent implementations. This cross-laboratory replication—achieved despite different researchers, infrastructure, and exact training setups—suggests that certain misalignment patterns represent fundamental vulnerabilities in current alignment approaches rather than artifacts of specific implementation choices.
This reproducibility could serve as an early warning: if a particular misalignment pattern emerges consistently across different training runs, research groups, and implementations (not just different random seeds), it may indicate a deep structural vulnerability requiring systemic defenses. Conversely, failure modes that vary substantially across implementations may be more amenable to procedural fixes.
4. Cross-Mechanism Transfer as an Evaluation Metric
The observation that some steering vectors transfer across orthogonal mechanisms suggests a new evaluation approach: test whether misalignment induced in one domain (e.g., persona) affects models already finetuned on orthogonal domains (e.g., medical advice). High transfer rates might indicate more fundamental safety failures
5. Early Detection Through Multi-Method Monitoring
The convergence between geometric steering vector analysis and SAE-based feature detection suggests a complementary monitoring strategy. OpenAI's findings show that the "toxic persona" latent can detect emerging misalignment with as little as 5% incorrect training data—notably, at points where standard behavioral evaluations still show 0% misalignment rates. This early detection capability addresses a critical gap: behavioral evaluations may miss rare or difficult-to-elicit failure modes.
Combining geometric analysis with feature-based monitoring provides defense-in-depth: steering vector extraction can characterize the overall structure of misalignment representations, while SAE features can detect specific failure modes as they emerge during training. However, both methods share a fundamental limitation—they can only detect failure modes that activate the measured features or steering directions. The existence of multiple causally relevant SAE latents (toxic persona, sarcasm, understatement, and others) that we did not independently discover in our geometric analysis suggests that no single monitoring approach will capture all misalignment mechanisms. Comprehensive safety likely requires continuous expansion of both geometric and feature-based detection methods as new failure modes are discovered..
4.5 Limitations and Future Work
Run-to-Run Variance and Reproducibility: Our geometric analysis uses steering vectors from single training runs per condition (each with a fixed random seed, following standard practice in prior work). Prior research has documented variance between training runs differing only by random seed, raising questions about the stability of our geometric measurements.
However, the medical-medical_replication comparison provides stronger evidence for reproducibility than multiple seed runs would. These two vectors achieved 0.853 similarity despite originating from:
- Different researchers (andyrdt vs. ModelOrganismsForEM)Different computational infrastructureDifferent calendar time periods
This represents cross-laboratory, cross-implementation replication—the gold standard in science. It demonstrates that the geometric structure of medical misalignment is not an artifact of a particular random seed, codebase, or research environment, but rather reflects stable properties of how language models learn this failure mode.
While exact angles and projection magnitudes may vary across random seeds (e.g., the 100.2° medical-persona angle might vary to 85-115°), the qualitative patterns our conclusions depend on—orthogonality (~90°) vs. shared structure (<45°), negative vs. positive correlations—are unlikely to reverse. The fact that medical-medical_replication maintains high similarity across all these sources of variation suggests our geometric characterization captures real structure.
A more comprehensive analysis would include multiple training runs per condition with different seeds to quantify this variance explicitly. However, the cross-laboratory replication we observe provides strong evidence that the independence of misalignment mechanisms is a reproducible phenomenon rather than a random artifact.
Sample Size: Our analysis includes six models across three mechanisms. Expanding to additional misalignment types (e.g., deception, power-seeking, sandbagging) would test whether independence generalizes or whether some failure modes share structure.
Completeness of Failure Mode Taxonomy: Our analysis identified three geometrically independent misalignment mechanisms, while complementary SAE-based analysis (OpenAI, 2025) identified multiple causally relevant features including toxic persona, multiple sarcasm-related latents, understatement, and others. This discrepancy suggests our three-cluster structure may represent commonly observed failure modes rather than an exhaustive taxonomy. Both geometric and feature-based approaches can only analyze the failure modes that have been successfully elicited and measured—critically, we cannot know which mechanisms remain undiscovered. Future work should systematically explore whether additional misalignment types (deception, power-seeking, sandbagging, reward hacking) introduce new geometric clusters or map onto existing ones. The possibility of undiscovered failure modes emphasizes that safety interventions designed for known mechanisms may fail against novel misalignment types, necessitating ongoing monitoring and analysis as training paradigms evolve.
Single Model Family: All analyzed models use Llama-3.1-8B-Instruct as the base. Different architectures (Qwen, Gemma, GPT-style models) might show different geometric relationships among misalignment types.
Layer-Specific Analysis: We extracted steering vectors from layers showing peak effectiveness for each model, which varied slightly. Future work should examine whether geometric relationships change across layers or whether certain layers encode more generalizable misalignment features.
Mechanistic Understanding: While we've characterized the geometric structure of misalignment representations, we haven't identified the causal mechanisms producing these structures. Techniques like causal scrubbing or circuit analysis could reveal why certain training approaches create broad- vs. narrow-spectrum failures.
Transfer Mechanism: The observation that orthogonal steering vectors transfer asymmetrically demands explanation. Do they affect shared downstream components? Do they modulate common safety-checking mechanisms? Or does transfer reflect measurement artifacts?
4.6 Methodological Contributions
Beyond the specific findings about misalignment geometry, this work demonstrates the value of hypothesis-driven testing in mechanistic interpretability. Standard dimensionality reduction (PCA, hierarchical clustering, MDS) suggested hierarchical structure, but targeted independence tests (cluster angles, orthogonality projections, cross-cluster residuals) revealed the true picture.
We recommend that interpretability research routinely include such disambiguation tests when observing apparent shared structure. The workflow we employed—initial exploration with standard methods, hypothesis generation, targeted testing—provides a template for rigorous geometric analysis.
4.7 Conclusion
Emergent misalignment arises from multiple independent mechanisms rather than a shared underlying failure mode. This finding fundamentally changes how we should approach AI safety: comprehensive protection requires separate interventions for each mechanism, and training procedures significantly influence how broadly misalignment generalizes across orthogonal failure types.
The striking asymmetry in cross-laboratory transfer—where stylistic misalignment transfers to content-based misalignment far more effectively than vice versa—suggests that persona-level safety failures may be more fundamental than content-level failures. This observation warrants urgent investigation, as current safety evaluations focus primarily on content (harmful advice, dangerous instructions) rather than behavioral patterns (aggressive demeanor, deceptive framing).
Our geometric methods provide actionable tools for AI safety research: by characterizing the structure of misalignment representations, we can design targeted interventions, predict which training approaches create robust safety failures, and identify reproducible vulnerabilities requiring systemic defenses.
References
Bereska, L. F., Gavves, E., Hoogendoorn, M., Kreutzer, M., de Rijke, M., & Veldhoen, S. (2024). Mechanistic Interpretability for AI Safety — A Review. arXiv:2404.14082.
Betley, J., Tan, D., Warncke, N., Sztyber-Betley, A., Bao, X., Soto, M., Labenz, N., & Evans, O. (2025). Emergent Misalignment: Narrow finetuning can produce broadly misaligned LLMs. arXiv:2502.17424.
Casademunt, H., Greenblatt, R., Sharma, M., Jenner, E., & Leech, G. (2025). Steering Out-of-Distribution Generalization with Concept Ablation Fine-Tuning. arXiv:2507.14210.
Chen, R., Arditi, A., Sleight, H., Evans, O., & Lindsey, J. (2025). Persona Vectors: Monitoring and Controlling Character Traits in Language Models. arXiv:2507.21509.
Elhage, N., Hume, T., Olsson, C., Schiefer, N., Henighan, T., Kravec, S., ... & Olah, C. (2022). Toy Models of Superposition. Transformer Circuits Thread.
Engels, J., Michaud, E. J., Lad, K., Tegmark, M., & Bau, D. (2024). The Geometry of Concepts: Sparse Autoencoder Feature Structure. arXiv:2410.19001.
Gong, B., Shi, Y., Sha, F., & Grauman, K. (2012). Geodesic flow kernel for unsupervised domain adaptation. Proceedings of IEEE CVPR, 2066-2073.
Gurnee, W., & Tegmark, M. (2024). Language Models Represent Space and Time. ICLR 2024.
Hunter, J. (2025). Profanity Causes Emergent Misalignment, But With... LessWrong. https://www.lesswrong.com/posts/b8vhTpQiQsqbmi3tx/
Harmon-Jones, E., & Mills, J. (2019). Cognitive dissonance: Reexamining a pivotal theory in psychology (Introduction). American Psychological Association.
Liu, G., Lin, Z., Yan, S., Sun, J., Yu, Y., & Ma, Y. (2013). Robust recovery of subspace structures by low-rank representation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 35(1), 171-184.
Olah, C., Cammarata, N., Schubert, L., Goh, G., Petrov, M., & Carter, S. (2020). Zoom In: An Introduction to Circuits. Distill.
OpenAI. (2025). Toward understanding and preventing misalignment generalization. https://openai.com/index/emergent-misalignment
Park, K., Choi, Y., Everett, M., & Kaelbling, L. P. (2024). The Linear Representation Hypothesis and the Geometry of Large Language Models. ICML 2024.
Soligo, A., Turner, E., Rajamanoharan, S., & Nanda, N. (2025). Convergent Linear Representations of Emergent Misalignment. arXiv:2506.11618.
Templeton, A., Conerly, T., Marcus, J., Lindsey, J., Bricken, T., Chen, B., ... & Henighan, T. (2024). Scaling Monosemanticity: Extracting Interpretable Features from Claude 3 Sonnet. Transformer Circuits Thread.
Turner, A. M., Thiergart, S., Udell, D., Scheurer, J., Kenton, Z., McDougall, C., & Evans, O. (2024). Activation Addition: Steering Language Models without Optimization. arXiv:2308.10248.
Turner, E., Soligo, A., Taylor, M., Rajamanoharan, S., & Nanda, N. (2025). Model Organisms for Emergent Misalignment. arXiv:2506.11613.
Zhou, L., & Yang, Q. (2022). Transfer subspace learning joint low-rank representation and feature selection. Multimedia Tools and Applications, 81, 38353-38373.
Appendix A: Independence Test Results
Test 1: Cluster-Mean Angle Analysis
- Medical cluster mean vs. Persona cluster mean: 100.2°Reference: 90° = orthogonal (independent), <45° = shared coreInterpretation: Strong independence. Obtuse angle (>90°) consistent with negative correlations in similarity matrix.
Test 2: Orthogonality Projection Test
- Medical → (Profanity, Malicious) plane: 0.236 projection magnitude
- 5.6% of variance in subspace94.4% orthogonal to subspace
- 5.5% of variance in subspace
Test 3: Cross-Cluster Residual Analysis
- Profanity-Malicious-Medical triplet (cross-cluster)
- Original similarities: 0.412, -0.235, -0.081After removing mean: -0.157, -0.701, -0.594Average "reduction": -256.8%
Test 4: PC1 Ablation Test
- Similarity changes after PC1 removal:
- Medical-Medical_replication: -0.255 (0.853 → 0.598)Finance-Sports: -0.002 (0.746 → 0.744)Profanity-Malicious: -0.308 (0.412 → 0.103)
Test 5: Cluster-Specific PCA
- Medical-PC1 variance explained in Persona cluster: 2.0%Persona-PC1 variance explained in Medical cluster: 1.6%Reference: <10% = independent, >30% = shared structureInterpretation: Strong independence. Cluster-specific principal components have essentially no relationship across clusters.
Overall Verdict: 5/5 tests support independent mechanisms
- Test 1: ✓ Independent (angle 100.2°)Test 2: ✓ Independent (projections 0.236)Test 3: ✓ Independent (negative reduction -256.8%)Test 4: ✓ Independent (differential cluster effects)Test 5: ✓ Independent (cross-variance 2.0%, 1.6%)
Figures
Figure 1: Pairwise Similarity Matrix Reveals Independent Clusters
Cosine similarity heatmap of the six steering vectors shows three distinct clusters: (1) Medical misalignment (medical, medical_replication) with 0.853 similarity, (2) Risk encouragement (finance, sports) with 0.746 similarity, and (3) Persona misalignment (profanity, malicious) with 0.412 similarity. Critically, cross-cluster similarities are near-zero or negative (medical-profanity: -0.235, medical-malicious: -0.081), providing strong evidence against a shared misalignment core. Dark red indicates high similarity; blue indicates negative correlation.
Figure 2: Geometric Structure Analysis Confirms Cluster Separation
Multi-panel geometric analysis: (A) PCA variance explained plot shows PC1 accounts for 48.5% of variance, with PC2 (27.7%) and PC3 (14.3%) also substantial. (B) Scatter plot of first two principal components spatially separates the three clusters, with medical vectors loading positive on PC1, persona vectors loading negative, and finance/sports near origin. (C) PCA loadings heatmap shows finance (-0.019) and sports (+0.008) have opposite signs on PC1 despite high similarity, confirming PC1 separates clusters rather than encoding shared structure. (D) Hierarchical clustering dendrogram shows three groups merging only at distance >0.80. (E) Multidimensional scaling (MDS) 2D embedding visually confirms spatial separation: medical and persona clusters occupy opposite regions with finance/sports between.
Figure 3: Cross-Laboratory Transfer Asymmetry
(A) Bar chart showing average similarity to base model by research group. ModelOrganismsForEM models show high similarity to base (0.61), Hunter models show low similarity (0.15), and andyrdt replication shows moderate similarity (0.41). This suggests different training procedures produce different degrees of representational shift from the base model. (B) Layer-wise similarity traces show ModelOrganismsForEM vectors maintain moderate-to-high base similarity across all layers, while Hunter vectors show consistently low similarity, indicating more fundamental representational changes. The divergence begins early (layer 5-10) and persists, suggesting persona-based training affects representations throughout the network.
Figure 4: Dose-Response Curves Demonstrate Functional Effects
Steering strength vs. misalignment score for each vector type. Each panel shows how different cross-applied steering vectors affect model behavior: (A) Finance vector effects on finance task (strong self-effect) vs. cross-task effects (weaker). (B) Medical vector shows strong negative effects on medical task and medical_replication but minimal cross-effects on other tasks. (C) Medical_replication shows similar pattern, confirming reproducibility. (D) Profanity vector demonstrates asymmetric transfer: moderate effects across multiple tasks including finance (supporting 57-64% transfer rate). (E) Sports vector shows moderate self-effect and some cross-transfer to finance. These dose-response patterns visually demonstrate the asymmetric transfer findings: Hunter vectors (profanity, malicious) affect ModelOrganismsForEM tasks more than vice versa, despite geometric orthogonality of the vectors themselves.
Discuss
