
Published on October 14, 2025 2:48 PM GMT
Current AI models are strange. They can speak—often coherently, sometimes even eloquently—which is wild. They can predict the structure of proteins, beat the best humans at many games, recall more facts in most domains than human experts; yet they also struggle to perform simple tasks, like using computer cursors, maintaining basic logical consistency, or explaining what they know without wholesale fabrication.
Perhaps someday we will discover a deep science of intelligence, and this will teach us how to properly describe such strangeness. But for now we have nothing of the sort, so we are left merely gesturing in vague, heuristical terms; lately people have started referring to this odd mixture of impressiveness and idiocy as “spikiness,” for example, though there isn’t much agreement about the nature of the spikes.
Of course it would be nice to measure AI progress anyway, at least in some sense sufficient to help us predict when it might become capable of murdering everyone. But how can we, given only this crude, informal understanding? When AI minds seem so different in kind from animal minds—the only sort we’ve had a chance to interact with, until now—that even our folk concepts barely suffice?
Predicting the future is tricky in the average case, and this case seems far more cursed than average. Given its importance, I feel grateful that some have tried hard to measure and predict AI progress anyway, despite the profundity of our ignorance and the bleakness of the task. But I do think our best forecasts so far have had much more success at becoming widely discussed than at reducing this ignorance, and I worry that this has caused the discourse about AI timelines to become even more confused, muddled by widely shared yet largely unwarranted confidence.
Take “horizon length,” for example, a benchmark introduced by METR earlier this year as a sort of “Moore’s law for AI agents.” This benchmark received substantial attention as the main input to the AI 2027 timelines forecast, which has been read—or watched, or heard—by millions of people, including the Vice President of the United States.
The basic idea of the benchmark is to rank the difficulty of various tasks according to the amount of time they take humans, and then to rank AI models according to the “difficulty” (in this sense) of the tasks they can complete. So if a given model has a “50% time horizon of 4 minutes,” for example, that means it succeeded half the time at accomplishing some set of tasks that typically take humans 4 minutes.
As I understand it, METR’s hope is that this measure can serve as something like an “omnibenchmark”—a way to measure the performance of roughly any sort of model, across roughly any sort of task, in common units of “how long they take humans to do.” And indeed performance on this benchmark is steadily improving over time, as one might expect if it reflected predictable growth in AI capabilities:
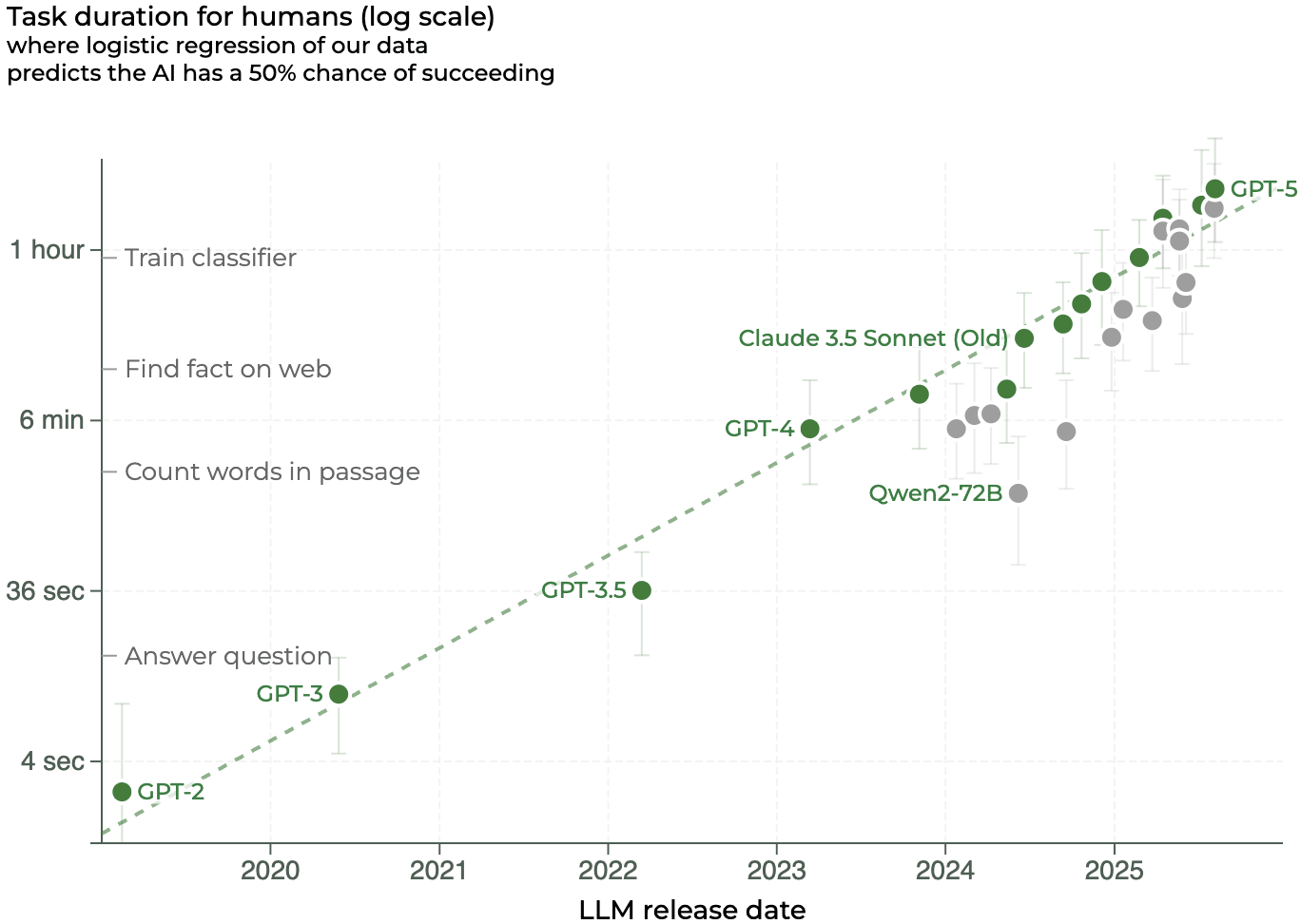
So while GPT-2 could only complete tasks that take humans mere seconds, current models can complete tasks that take humans over an hour. METR's proposal is that we extrapolate from this data to predict when AI will gain the kind of capabilities we would strongly prefer to have advance warning about—like substantially automating AI R&D (which METR suggests may require a horizon length of tens of hours), or catastrophically harming society (of one month).
Personally, I feel quite skeptical that this extrapolation will hold.
Conceptual Coherence
Given that humans are our only existing example of decent agents, I think one obvious sanity check for proposed measures of AI agency is whether they are helpful for characterizing variation in human agency. Is horizon length? Is there some meaningful sense in which, say, the unusual scientific or economic productivity of Isaac Newton or James Watt, can be described in terms of the “time horizon” of their minds? If there is, I at least have failed to imagine it.
One basic problem with this measure, from my perspective, is that the difficulty of tasks is not in general well-described as a function of the time needed to complete them. Consider that it took Claude Shannon ~5 years to discover information theory, and Roald Amundsen ~3 years to traverse the Northwest Passage—is there some coherent sense in which Amundsen’s achievement was “⅗ as hard”?
Certainly the difficulty of many tasks varies with their time cost all else equal, but I think all else is rarely equal since tasks can be difficult in a wide variety of ways. It would be thermodynamically difficult to personally shovel a canal across Mexico; computationally difficult to factor the first trillion digits of π; interpersonally difficult to convince Vladimir Putin to end the war in Ukraine; scientifically difficult to discover the laws of electromagnetism...
... and personally, I feel skeptical that all such difficulties can be sensibly described in common, commensurate units of time cost. And so I doubt that “horizon length” is well-suited for assessing and comparing AI performance across a wide range of domains.
Of course the benchmark might still be useful, even if it fails to suffice as a general, Moore’s law-style measure of AI agency—perhaps it can help us track progress toward some particular capabilities, even if not progress toward all of them.
As I understand it, METR’s hope—and similarly, AI 2027's hope in relying on the benchmark for their forecast—is that horizon length might be particularly predictive of progress at AI R&D, and hence of when AI might gain the ability to recursively self-improve. As such, the benchmark is designed to directly measure AI ability only in the narrower domain of “coding” or “computer use” tasks.
But these too strike me as strange concepts. Computers being Turing-complete, the space of possible “computer use” tasks is of course large, encompassing (among much else) all cognition performable by brains. So the set of possible computer use skills, at least, does not seem much narrower than the set “all possible skills.”
In practice I think the benchmark is intended to measure performance on an even narrower proxy than this—roughly, the sort of tasks involved in ordinary, everyday software engineering. But "software engineering" also involves a large and heterogeneous set of skills, ranging from e.g. “making a webpage” to “inventing transformers.” And in my view, it seems quite unclear that the acquisition of simple skills like the former reflects knowable amounts of progress toward transformative skills.
Unfortunately, I think the case for "horizon length" predicting transformative AI is weak even if one does assume everyday software engineering skills are the sort of thing needed to create it, since the tasks the benchmark measures are unrepresentative even of those.
Benchmark Bias
The "horizon length" benchmark measures performance on three sets of tasks:
- SWAA—66 simple, "single-step tasks" (like e.g. simple arithmetic, or completing a single word of code) that typically take humans a few seconds;HCAST—97 "economically useful" tasks (like e.g. looking up a fact on Wikipedia, writing a CUDA kernel, or creating a web server at a given address) that take humans a few minutes;RE-Bench—7 "difficult ML research engineering tasks" (like e.g. finetuning GPT-2 to be a chatbot, or writing a custom GPU kernel) that take humans a few hours.
I think these tasks probably differ in many ways from tasks like "conquering humanity" or "discovering how to become as powerful as physics permits." They are mostly very simple,[1] for example, and none require models to think novel thoughts.
But one especially glaring difference, by my lights, is that the benchmark consists exclusively of precisely-specified, automatically-checkable tasks. This is typical of AI benchmarks, since it is easy to measure performance on such tasks, and hence easy to create benchmarks based on them; it just comes at the price, I suspect, of these proxies differing wildly from the capabilities they are meant to predict.
At the risk of belaboring the obvious, note that many problems are unlike this, in that the very reason we consider them problems is because we do not already know how to solve them. So the kind of problem for which it is possible to design precisely-specified, automatically-checkable tests—for brevity, let's call these benchmarkable problems—have at minimum the unusual property that their precise solution criteria are already known, and often also the property that their progress criteria are known (i.e., that it is possible to measure relative progress toward finding the solution).
It seems to me that all else equal, problems that are benchmarkable tend to be easier than problems that are not, since solutions whose precise criteria are already known tend to be inferentially closer to existing knowledge, and so easier to discover. There are certainly many exceptions to this, including some famous open problems in science and mathematics.[2] But in general, I think the larger the required inferential leap, the harder it tends to be to learn the precise progress or solution criteria in advance.
I suspect that by focusing on such tasks, AI benchmarks suffer not just from a bias toward measuring trivial skills, but also from a bias toward measuring the particular sorts of skills that current AI systems most often have. That is, I think current AI models tend to perform well on tasks roughly insofar as they are benchmarkable, since when the solution criteria is known—and especially if the progress criteria is also known—then it is often possible to train on those criteria until decent performance is observed.
(I presume this is why AI companies consider it worth paying for better benchmarks, and inventing their own in-house—they are directly useful as a training target).
So I expect there is a fairly general benchmark bias, affecting not just "horizon length" but all benchmarks, since the tasks on which it is easy to measure AI performance tend to be those which AI can be trained to perform unusually well.[3] If so, benchmark scores may systematically overestimate AI capabilities.
Predictive Value
The value of "horizon length" for predicting transformative AI depends on how much progress on the proxy tasks it measures correlates with progress toward abilities like autonomously generating large amounts of wealth or power, inventing better ML architectures, or destroying civilization. Insofar as it does, we can extrapolate from this progress to estimate the time we have left on ancient Earth.
I do not know what skills current AI lacks, that transformative AI would require. But personally, I am skeptical that we learn much from progress on tasks as simple as those measured by this benchmark. To me, this seems a bit like trying to use Paleolithic canoeing records to forecast when humans will reach the moon, or skill at grocery shopping as a proxy for skill at discovering novel mathematics.[4]
Of course all else equal I expect rudimentary abilities to arrive earlier than transformational ones, and so I do think benchmarks like this can provide useful evidence about what AI capabilities already exist—if e.g. current models routinely fail at tasks because they can't figure out how to use computer cursors, it seems reasonable to me to guess that they probably also can't yet figure out how to recursively self-improve.
But it seems much less clear to me how this evidence should constrain our expectations about when future abilities will arrive. Sure, AI models seem likely to figure out computer cursors before figuring out how to foom, like how humans figured out how to build canoes before spaceships—but how much does the arrival date of the former teach us about when the latter will arrive?
One obvious reason it might teach us a lot, actually, is if these simple skills lay on some shared, coherent skill continuum with transformative skills, such that progress on the former was meaningfully the same "type" of thing as progress toward the latter. In other words, if there were in fact some joint-carvey cluster in the territory like "horizon length," then even small improvements might teach us a lot, since they would reflect some knowable amount of progress toward transformative AI.
I do not see much reason to privilege the hypothesis that "horizon length" is such a cluster, and so I doubt it can work as a general measure of AI agency. But this does not rule out that it might nonetheless have predictive value—measures do not need to reflect core underlying features of the territory to be useful, but just to vary in some predictably correlated fashion with the object of inquiry. Sometimes even strange, seemingly-distant proxies (like e.g. Raven's Matrices) turn out to correlate enough to be useful.
Perhaps "horizon length" will prove similarly useful, despite its dubious coherence as a concept and the triviality of its tests. For all I know, the fact that the benchmark measures something related at all to the time cost of tasks, or even just something related at all to what AI systems can do, is enough for it to have predictive value.
But personally, I think the case for this value is weak. And so I feel very nervous about the prospect of using such benchmarks to "form the foundation for responsible AI governance and risk mitigation," as METR suggests, or as the basis for detailed, year-by-year forecasts of AI progress like AI 2027.
- ^
AI failures are often similarly simple. E.g., one common reason current models fail is because they can't figure out how to use computer cursors well enough to begin the task.
Perhaps there is some meaningful "agency" skill continuum in principle, on which "ability to use a mouse" and "ability to conquer humanity" both lie, such that evidence of the former milestone being reached should notably constrain our estimate of the latter. But if there is, I claim it is at least not yet known, and so cannot yet help reduce our uncertainty much.
- ^
I suspect it's often this unusual operationalizability itself, rather than importance, that contributes most to these problems' fame, since they're more likely to feature in famous lists of problems (like e.g. Hilbert's problems) or have famous prizes (like e.g. the Millennium Prize Problems).
Relatedly, all else equal I expect to feel less impressed by AI solving problems whose solution and progress criteria were known, than those whose solution criteria only was known, and most impressed if neither were (as e.g. with many open problems in physics, or the alignment problem).
- ^
(I would guess this bias is further exacerbated by AI companies sometimes deliberately training on benchmarks, to ensure their models score well on the only legible, common knowledge metrics we have for assessing their products).
- ^
I have had the good fortune of getting to know several mathematicians well, and hence of learning how uncorrelated such skills can be.
Discuss
