
Published on October 10, 2025 2:27 PM GMT
Are current AIs “aligned”?
When interacting with today’s most powerful AIs, they don’t appear very misaligned—they usually refuse to provide dangerous information, use a polite tone, and are generally very helpful (unless intentionally jailbroken or put in contrived setups). Some see this as a hopeful sign: maybe alignment isn’t that difficult?
Others are more skeptical, arguing that alignment results so far provide little evidence about how hard it will be to align AGI or superintelligence.
This appears to be a crux between AI optimists and pessimists—between risk deniers and doomers. If current methods work just as well for AGI, then perhaps things will be fine (aside from misuse, use in conflict, accident risks etc.). But if today’s methods are merely superficial tweaks—creating only the appearance of safety—AI developers may not notice their limitations until it’s too late.
Let’s build some intuition for how alignment differs depending on AI capability.
Consistency in Behavior
For long and complex tasks there is more room for interpretation and freedom in execution, compared to short tasks—like answering “yes” or “no” on a factual question. For example:
- An AI that can only write a paragraph might reveal stylistic tendencies.An AI that can write a page may reveal preferences in topic and structure.An AI that can write a book might reveal preferences for narrative styles and character development.
You only observe certain tendencies, preferences, and behavioral consistencies once the AI is capable of expressing them.
Can the paragraph-limited AI have preferences for character-development? Can AI developers instill such preferences before it can write books? We can’t truly observe whether the developers succeeded until it’s able to write books.
Naturally, an AI developer might have some preference stylistic tendencies that the AI could be aligned or misaligned with. After succeeding with aligning the paragraph-limited AI, they congratulate themselves on their excellent alignment methods. But do they really apply to shaping preferences for character development?
Task Completion Time
Consider an AI that can complete tasks that take time X on average for a human to complete. When doing X-long tasks, what behavioral consistencies may be observed across those tasks?
Here’s a (very rough) sketch of what emerges at different task lengths[1]:
- Minutes-long tasks: Completed directly, with little freedom in execution.
- Key behaviors and skills: writing style, willingness to comply or refuse, communication tone, conceptual associations
- Key behaviors and skills: reasoning, problem-solving, error correction, sensitivity to feedback and corrections
- Key behaviors and skills: action prioritization, resource management, sub-goal selection, maintaining relationships, learning, memory and knowledge organization, self-monitoring
- Key behaviors and skills: high-level decision making and strategizing, task delegation, adapting to setbacks and changing circumstances, balancing short-term vs. long-term tradeoffs, anticipating and dealing with risks and contingencies
- Key behaviors and skills: moral reasoning, determination of terminal goals, making value tradeoffs, self-reflection and self-improvement
If you ask your favorite chatbot to draft a high-level plan for your business, it might give you something useful (if you’re lucky). You may be tempted to infer that it’s aligned if it was helpful. But I would argue that until the AI can complete weeks-long or months-long tasks, any consistencies in high-level planning are only superficial tendencies. It’s only when plans are tightly connected to task execution—when the AI can take an active role in carrying out the plans it provides—that consistencies become meaningful.
It’s at this point that an AI could, in principle, tell you one plan while pursuing another secret plan towards its own goals.
Current frontier systems may be aligned in the sense that they (usually) refuse to provide harmful information, use a nice tone, and their reasoning is human readable and accurately reflects their actual decision-making process. Their surface-level tendencies are indeed quite aligned!
But aligning AGI or superintelligence means aligning systems capable of pursuing arbitrarily long tasks, which involve extremely different behaviors and skills compared to what current systems are capable of.
This is why I think there is little empirical evidence for whether superintelligence alignment is easy or hard; we haven’t tried anything close to it.
Worse, AI labs might be lulled into a false sense of security by their apparent success at aligning weaker systems (let’s call this shallow alignment), mistaking these for progress on the different problem of aligning superintelligence (deep alignment)[2].
Alignment depth seems like a useful term to express things like “This alignment method is good but has relatively shallow alignment depth. It may break for tasks longer than ~2 hours”, or “These safety tests were designed for evaluating alignment at medium alignment depth (task length at ~1-7 days)”.
Methods for achieving deeper alignment are likely to be introduced as capabilities increase:
Progressing Alignment Techniques
AIs have been trained to be helpful, harmless and honest (HHH), according to a framework introduced in 2021 by Anthropic. These are alignment properties associated with minutes-long tasks (helpful - obey instructions, harmless - refuse harmful requests, honest - truthful communication), although you could argue that extensions of this framework may apply to longer tasks as well.
Analogically, OpenAI’s deliberative alignment training paradigm (introduced in December 2024), teaches AIs to reason about safety specifications before answering—an approach aimed at the process for task completion and aimed at hours-long tasks.
As capabilities advances, alignment techniques adapt. When AIs can complete days-long tasks, we might see new methods with names like “introspective alignment” (relying on self-monitoring), or “safe recollection” (instills appropriate memory-management behaviors to steer behavior and attention while completing long and complex tasks).
Alignment is often reactive, with new techniques introduced when necessary. And even if a good alignment method for weeks-long tasks would be introduced now, it might be neigh impossible to test it until the relevant capabilities arrive.
Timelines
The length of tasks that AIs can complete is called “time horizon”, a concept introduced by METR, which measures this property in the domain of software engineering. If an AI can complete tasks that typically take humans 1 hour, they have a 1-hour time horizon. This graph shows the 50% time horizon—the length of tasks that AIs can complete with 50% success rate:
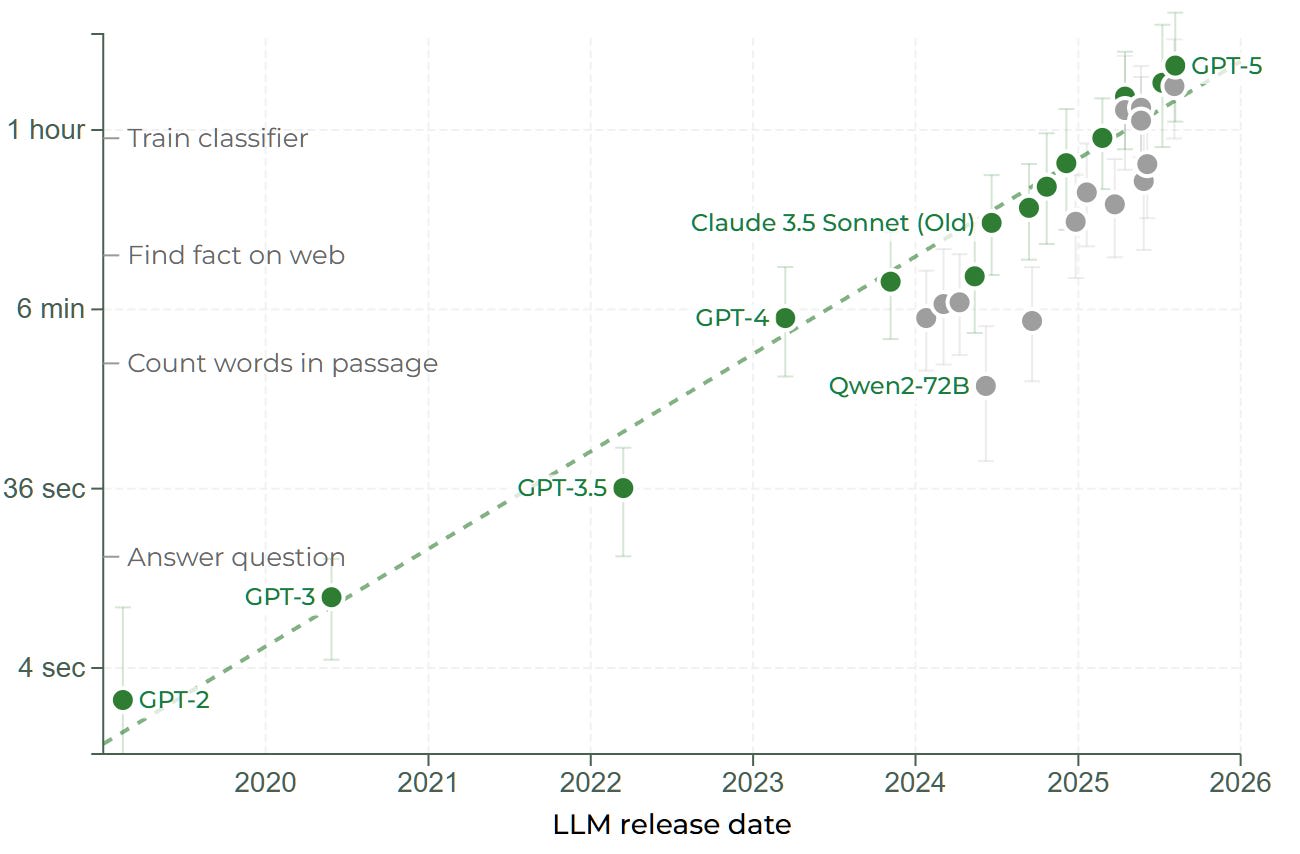
Task duration for software engineering tasks that AIs can complete with 50% success rate (50% time horizon)
The dashed green line indicates the exponential trend, with a doubling time of ~7 months. Since 2024, however, the trend is closer to a doubling time of ~4 months. According to METR’s estimates, if progress continues at the faster pace, “1-month AIs” (capable of completing month-long tasks) would appear around 2027–2028, with “half the probability in 2027 and early 2028.” If, on the other hand, the trend reverts to the longer doubling time, the median timeline to 1-month AI is late 2029, with an 80% confidence interval width of ~2 years.
(To me it seems likely that the trend will speed up even further, for reasons I will discuss in a future post.)
It may sound pessimistic, but I think we’ll have to wait for 1-month AIs (and maybe longer) until we can expect somewhat reliable evidence about whether alignment methods truly hold, as month-long tasks may involve moral reasoning and value tradeoffs. At this point we would also have some data on how well alignment techniques generalize from shorter to longer tasks.
Asymmetrical Time Horizons
There is one potential source of hope: perhaps AI systems will reach long time horizons in safe domains before risky ones.
Let’s say that time horizon reaches months in, for instance, the domain of medical research doing so in concerning domains like AI R&D (critical for AI self-improvement) or politics (critical for gaining power).
The AI could be tasked to plan experiments, allocate resources, and make tradeoffs—all while handling uncertainty and ethical considerations.
Does it prioritize maximizing revenue? Saving lives? Gaining control over its host organization?
The behavior at this stage provides meaningful evidence (though still not conclusive) on whether we have truly figured out alignment or not—though it could of course be faking alignment.
Unfortunately, AI R&D is too strategically valuable for participants in the AI race. Developers are unlikely to evaluate alignment in safe domains before plunging forward. In fact, AI R&D might lead other domains in time horizon growth, because it’s prioritized.
Conclusion
Summarizing key predictions:
- Current frameworks like helpful, harmless and honest (HHH) or deliberative alignment won’t be sufficient for longer tasks.Alignment for AIs that can complete longer tasks is fundamentally different, and probably more difficult, than alignment of current frontier AIs.New alignment methods will be introduced that roughly correspond to the length of tasks that AIs can complete.AI companies are likely to be overconfident in their alignment methods, as everything appears to be fine for weaker AIs.
Hopefully, we can test alignment in safe domains before concerning capabilities arrive in risky ones—though AI R&D is likely to be prioritized.
Thank you for reading! If you found value in this post, consider subscribing!
- ^
AIs are usually able to complete tasks much faster than humans, when they become able to complete them at all. When I refer to X-long tasks (minutes-long, hours-long, etc.), I refer to tasks that take humans X time to complete on average. I’m not entirely sure how this impacts key skills and behaviors for different task lengths, as this might be different for AIs compared to humans. Again, this is a very rough sketch.
- ^
I remain uncertain how different superintelligence alignment is from alignment of less sophisticated AIs. Current methods seem heavily dependent on providing good training signals that strengthen preferrable behaviors, which may not be possible for superintelligent systems operating at levels where humans can't keep up.
Discuss
