
SemiAnalysis recently launched InferenceMAX™ v1, a new open source initiative that provides a comprehensive methodology to evaluate inference hardware performance. Published results demonstrate that NVIDIA GPUs deliver the highest inference performance across all workloads.
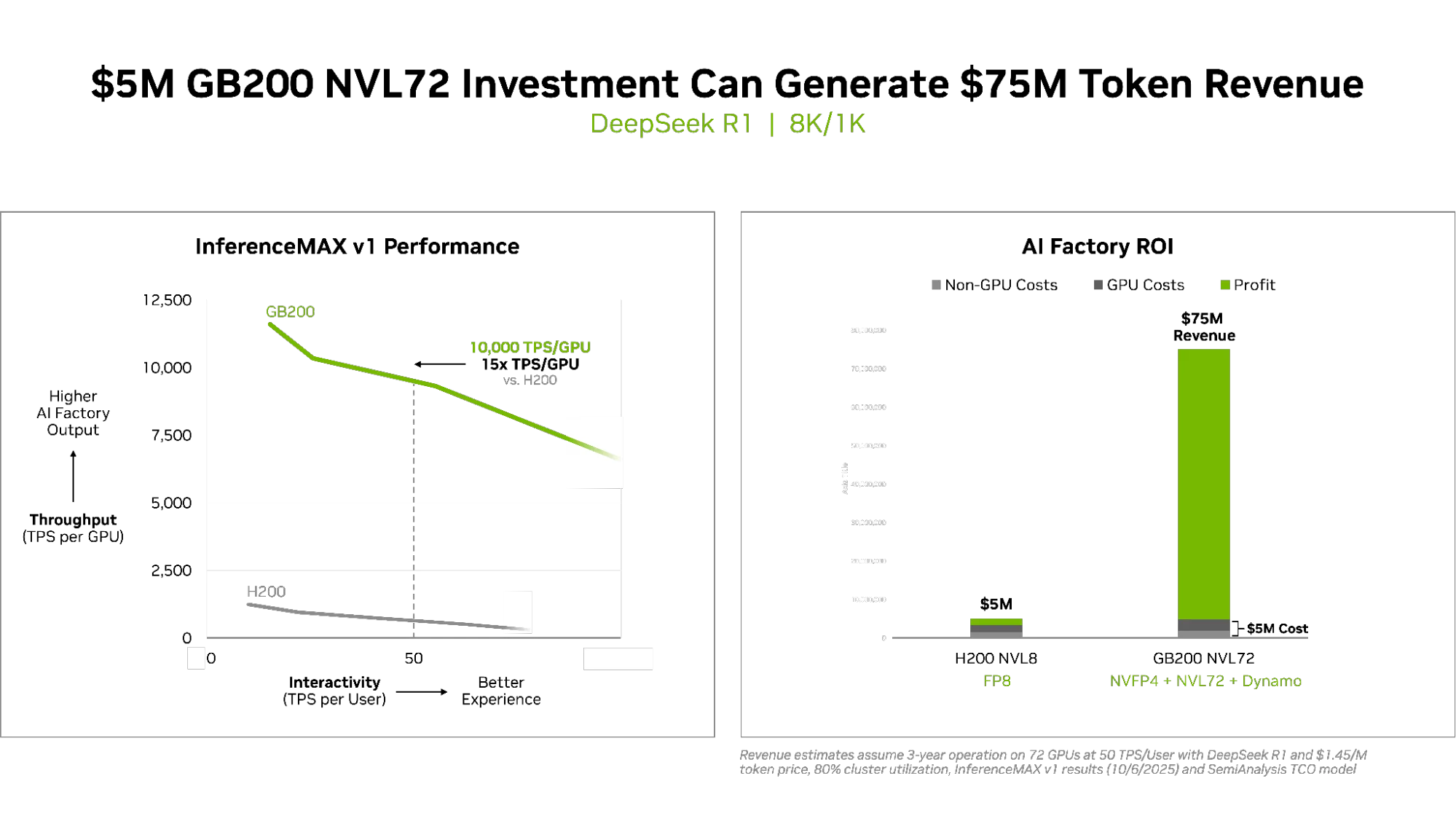
What does the data tell us? NVIDIA Blackwell demonstrated a 15x performance gain over the Hopper generation, unlocking a 15x revenue opportunity (Figure 1). This industry-leading performance and profitability are driven by extreme hardware-software co-design, including native support for NVFP4 low precision format, fifth-generation NVIDIA NVLink and NVLink Switch, and NVIDIA TensorRT-LLM and NVIDIA Dynamo inference frameworks.
With InferenceMAX v1 now open source, the AI community can reproduce NVIDIA’s industry-leading performance. We invite our customers, partners, and the wider ecosystem to use these recipes to validate the versatility and performance leadership of NVIDIA Blackwell across many AI inference scenarios.
This independent third-party evaluation from SemiAnalysis provides yet another example of the world-class performance that the NVIDIA inference platform delivers for deploying AI at scale.
Inside InferenceMAX v1
A key differentiator of InferenceMAX v1 is its continuous, automated testing. Continuous Integration (CI) results from benchmark sweeps are published each day, with tests run across multiple inference frameworks, SGLang, TensorRT-LLM, and vLLM, to capture performance improvements from the latest software releases.
The benchmarks cover both single-node and multi-node wide Expert Parallelism (EP) configurations, ensuring results reflect the diverse deployment scenarios used in production environments. Table 1 provides additional details on the models, precisions, input sequence lengths (ISL) and output sequence lengths (OSL) tested. Variable sequence lengths are used (80-100% of ISL/OSL combinations) to reflect the dynamic nature of real-world deployments.
| Model | Type | Parameters | Precisions | Chat (ISL/OSL) | Summarization (ISL/OSL) | Deep Reasoning (ISL/OSL) |
| DeepSeek-R1 | MoE | 671B (37B active) | FP8, NVFP4 | 1K/1K | 8K/1K | 1K/8K |
| gpt-oss-120b | MoE | 117B (5.1B active) | FP8, MXFP4 | 1K/1K | 8K/1K | 1K/8K |
| Llama 3.3 70B | Dense | 70B | FP8, NVFP4 | 1K/1K | 8K/1K | 1K/8K |
InferenceMAX v1 provides data across multiple dimensions including latency, throughput, batch sizes, and various input/output ratios covering reasoning tasks, document processing and summarization, and chat scenarios.
How did NVIDIA Blackwell perform in InferenceMAX v1?
The InferenceMAX v1 benchmark data clearly show that the generational leap from NVIDIA Hopper HGX H200 to NVIDIA Blackwell DGX B200 and NVIDIA GB200 NVL72 platforms bring dramatic gains in efficiency and cost-effectiveness. Blackwell features fifth-generation Tensor Cores with native FP4 acceleration and 1,800 GB/s of NVLink bandwidth, and uses the latest HBM3e memory.
This leads to an order-of-magnitude increase in compute-per-watt and memory bandwidth, delivering both significantly better energy efficiency and dramatically lower cost per million tokens compared to Hopper.
This post dives into the standout innovations behind these results and breaks down how the Blackwell architecture delivers such remarkable performance.
Continuous software optimizations deliver boost in performance over time
Alongside the steady cadence of NVIDIA hardware innovation, NVIDIA also drives continuous performance gains through ongoing software optimizations. At the initial model launch of gpt-oss-120b, Blackwell B200 performance with TensorRT-LLM was solid, but left room for improvement as early per-GPU throughput numbers were substantially lower than today’s best. In a short time, NVIDIA engineering teams and the wider community have worked extensively to optimize the TensorRT-LLM stack for open source LLMs, unlocking even better performance (Figure 2).

The B200 InferenceMAX v1 configuration in Figure 2 shows the progress achieved since the launch of gpt-oss on August 5, leading to boosted throughput at all points of the Pareto frontier. At roughly 100 TPS/user, B200 achieves almost 2x better throughput on InferenceMax v1 than at the model launch.
Looking at October 9, the latest version of TensorRT-LLM introduces powerful new features such as EP and DEP (Data and Expert Parallelism) mappings, further increasing max throughput at 100 TPS/user by up to 5x compared to launch day, rising from roughly 6K to 30K max per-GPU throughput. One way this is achieved is by leveraging higher concurrencies compared to ones seen in the InferenceMAX v1 benchmark, as InferenceMAX currently only tests concurrencies 4-64.
In addition, parallelism configurations like DEP achieve high throughput by distributing gpt-oss-120b Attention and MoE layers across multiple GPUs. This rapid, all-to-all communication is made possible by the 1,800 GB/s bidirectional bandwidth of NVLink and the NVLink Switch, which avoids traditional PCIe bottlenecks. The resulting high concurrency enables the system to serve many simultaneous inference requests at full speed, keeping the hardware fully utilized for all users (Figure 3).
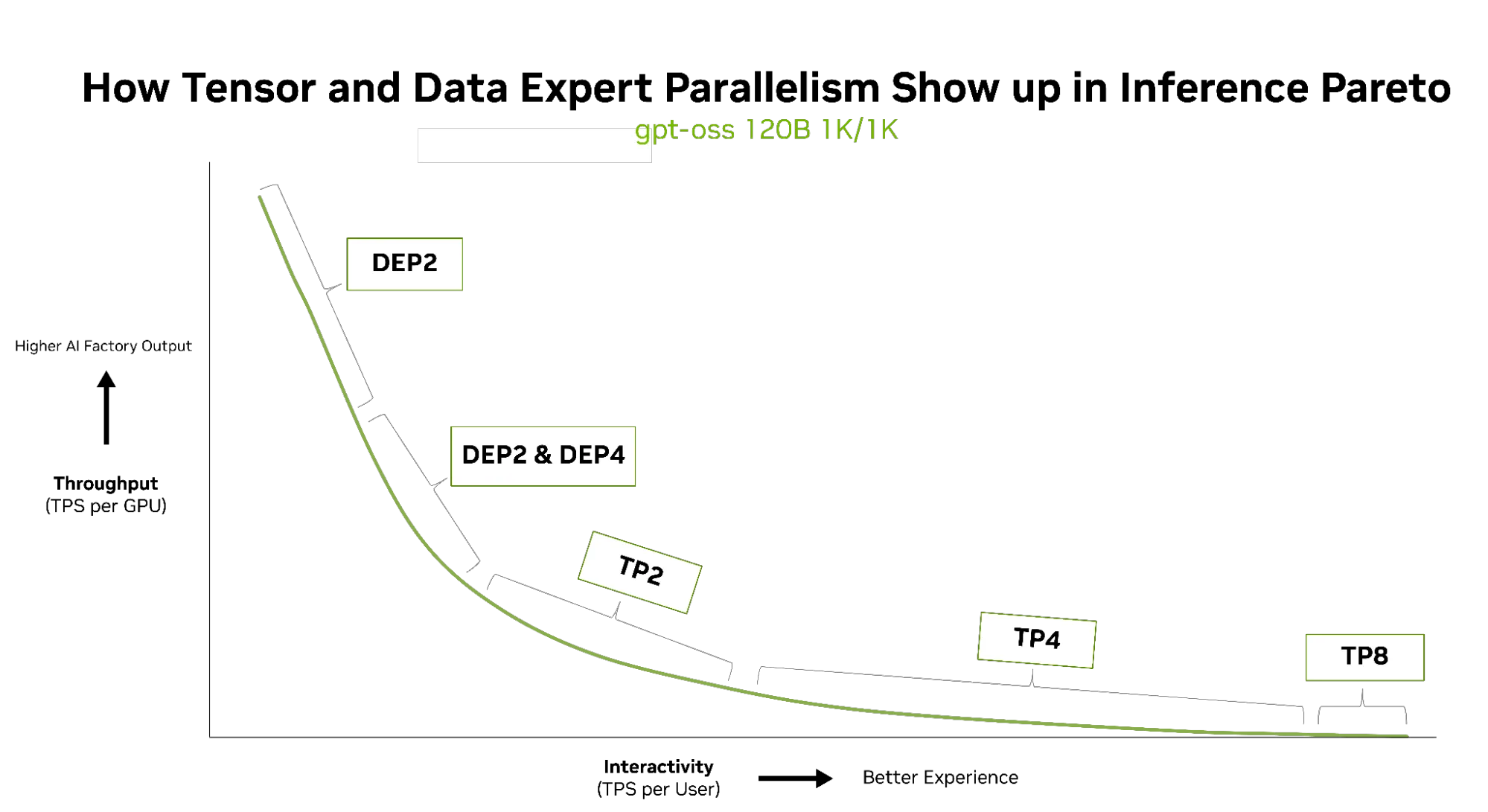
For instance, in the full DEP2 scheme, attention for each request is handled on one GPU (with its KV cache localized), while expert tokens for the MoE layers are dynamically routed and processed across two GPUs (64 experts per GPU). The NVLink Switch fabric ensures these expert tokens are distributed and aggregated with minimal delay, supporting immediate, direct exchanges between GPUs.
Another significant milestone is the enablement of speculative decoding for gpt-oss-120b using the newly released gpt-oss-120b-Eagle3-v2 model. With EAGLE-enabled speculation, per-GPU throughput throughput at 100 TPS/user triples compared to published InferenceMAX v1 results, going from 10K to 30K tokens/second, making large-scale inference significantly more cost-efficient and responsive.
In fact, accounting for these software improvements, in the two months since the model was released, the cost per million tokens at 100 TPS/user has reduced 5x, from $0.11 at launch to $0.02 today (Figure 4). For API service providers, this translates to greater revenue as model inference becomes both faster and less expensive to deliver at scale. Even at an ultra-high interactivity of 400 TPS/user, the cost per million tokens stays relatively low at $0.12, enabling the feasibility of more complex multi-agent use cases.
These layered software enhancements, combined with open innovation, underscore NVIDIA’s commitment to pushing both hardware and software boundaries for generative AI at scale.

NVIDIA Blackwell powers high-efficiency Llama 3.3 70B inference with NVFP4
Blackwell B200 sets a new performance standard in InferenceMAX v1 benchmarks for dense AI models, such as Llama 3.3 70B, that demand significant computational resources due to their large parameter count and the fact that all parameters are utilized simultaneously during inference. Blackwell delivers 10,000 tokens per second at 50 TPS/user in the Llama 3.3 70B 1K/1K benchmark, more than 4x higher per-GPU throughput compared to Hopper H200 (Figure 5).
This demonstrates that Blackwell architectural innovations such as NVFP4 support leadership in both dense and sparse workloads, enabling faster inference and more responsive experiences for users regardless of model complexity.
By mapping performance and TCO across this frontier, InferenceMAX v1 shows that the NVIDIA Blackwell platform leads not just at one optimal point, but across the entire range of operational demands.

Blackwell GB200 NVL72 is the new standard in AI cost efficiency
The data from InferenceMAX v1 shows that GB200 NVL72 delivers significantly better total cost of ownership (TCO) compared to the prior generation H200 on the DeepSeek-R1 reasoning model (Figure 6).

Across all measured interactivity levels, indicated as tokens per second per user, GB200 NVL72 consistently delivers a significantly lower cost per million tokens compared to H200. For example, at an interactivity of roughly 75 tokens per second the H200 cost is $1.56 per million tokens, while GB200 NVL72 brings this down to just over $0.10 per million tokens, a striking 15x reduction in cost. The GB200 cost curve remains substantially flatter for longer, which allows for serving past 100 TPS/user before costs noticeably increase.
For large-scale AI deployments, the implications of this performance are profound: AI factories leveraging GB200 NVL72 can serve far more users at better interactivity targets without incurring higher operational expenses or sacrificing throughput.
Overall, as interactivity demands and the number of concurrent users grow, GB200 NVL72 maintains the lowest cost per million tokens among all compared architectures, making it the ideal solution for maximizing both user base and revenue at massive scale.
Disaggregated serving and how GB200 NVL72, Dynamo, and TensorRT-LLM unlock the full performance of MoE models
Verified benchmarks from SemiAnalysis (Figures 1 and 6) show that the combination of GB200 NVL72, Dynamo, and TensorRT-LLM dramatically increases throughput of MoE models like DeepSeek-R1 under a wide range of SLA constraints, outperforming previous-generation Hopper-based systems.
The GB200 NVL72 scale-up design connects 72 GPUs through high-speed NVLink, forming a single, tightly integrated domain with up to 130 TB/s of bandwidth for GPU-to-GPU communication. This high-bandwidth, low-latency interconnect is critical for MoE models, enabling seamless communication between experts without the bottlenecks introduced by traditional internode links like InfiniBand.
In parallel, disaggregated inference in Dynamo introduces another layer of efficiency by separating the prefill and decode phases across different GB200 NVL72 nodes. This separation is critical as it enables each phase to be independently optimized with different GPU counts and configurations. The memory-bound decode phase can now leverage wide EP for expert execution without holding back the compute-heavy prefill phase.
Finally, TensorRT-LLM mitigates the risk of GPU underutilization in EP. In large-scale wide EP deployments, it’s common for some GPUs to remain idle if they host experts that are rarely activated. This leads to inefficient use of compute resources. To address this, the wide EP implementation of TensorRT-LLM intelligently monitors expert load and distributes frequently used experts across different GPUs. It can also replicate popular experts to better balance workloads. This ensures efficient GPU usage and performance.
Together, GB200 NVL72, Dynamo, and TensorRT-LLM create an inference-optimized stack that unlocks the full potential of MoE models.
NVIDIA partners with SGLang and vLLM to co-develop kernels and optimizations
Beyond advancements in the open source Dynamo and TensorRT-LLM frameworks, NVIDIA has partnered with the SGLang and vLLM open source projects to co-develop new Blackwell kernels and optimizations. These contributions, delivered through FlashInfer, include enhanced or newly introduced kernels for Attention Prefill & Decode, Communication, GEMM, MNNVL, MLA, and MoE.
At the runtime level, further optimizations have been contributed to these LLM frameworks over the last few months. For SGLang, support for MTP (multi-token prediction) and disaggregation for the DeepSeek-R1 model were added. For vLLM, overlap async scheduling capabilities to reduce host overhead and improve throughput and automatic graph fusions were implemented. Additionally, performance and functionality improvements for gpt-oss, Llama 3.3, and general architectures have also been integrated into vLLM.
Through advanced hardware, software optimizations, and open source collaboration, NVIDIA enables full performance and efficiency of Blackwell across popular open source inference frameworks.
Get started with NVIDIA Blackwell
The launch of SemiAnalysis InferenceMAX v1 benchmarking suite introduces an open source and continuously updated framework for measuring inference performance. Through InferenceMAX v1, the NVIDIA Blackwell family has emerged as a clear leader, with B200 and GB200 NVL72 demonstrating up to 15x improvements in performance over the previous Hopper generation and driving up to a 15x revenue opportunity for AI factories.
These results validate NVIDIA Blackwell architectural innovations, including NVFP4 precision, NVLink 5 interconnects, TensorRT-LLM, and Dynamo across a wide set of workloads and open source inference frameworks. As the NVIDIA platform continues to advance, ongoing software improvements drive even greater value.
Learn more and check out our latest NVIDIA performance data.
To explore or reproduce the benchmarks, visit the SemiAnalysis InferenceMAX GitHub repo where the full set of containers and configurations are available.
