
由於AI應用通常涉及龐大的資料集,因而所需的儲存空間,大都是由獨立、可擴展的外部儲存設備提供,至於GPU伺服器內接儲存裝置則居於次要角色。
不過,近半年多以來,Hammerspace與WEKA這兩家新創平行檔案系統廠商,先後發表基於GPU伺服器內接SSD的儲存部署架構,結合內接NVMe SSD的低延遲特性,與平行檔案系統提供的可用性與資料保護能力,創造出嶄新的AI應用儲存型態。
AI應用的內部與外部儲存
GPU伺服器可使用的儲存空間,不外乎兩大類,一為GPU伺服器自身配置的NVMe SSD儲存空間,二為透過網路介接的外部儲存設備空間,兩者的特性正好相反。
GPU伺服器內接的SSD,優勢在於距離GPU更近,資料傳輸距離短,因而存取延遲少,缺點則是容量、效能與擴展能力都受限,一般GPU伺服器機箱大多只能配置8至16臺SSD,最多只能匯聚出數十GB/s等級的傳輸頻寬,還缺乏足夠的高可用性與資料保護機制,而且,因此也形成了資源管理的孤島——內接SSD只能提供該伺服器本機使用,不具備跨伺服器調派資源的能力。
相較之下,外接的儲存設備,則不受單一機箱的限制,容量與擴展能力都遠大於伺服器內部儲存裝置,另一優勢是可透過底層的儲存軟體平臺,提供高可用性與資料保護功能,以及跨伺服器間的靈活資源調派能力。
而在效能方面,外部儲存設備是透過網路將儲存空間掛載給GPU伺服器使用,故存取延遲相對較大,但可透過RDMA或GPUDirect等遠端直連存取技術,一定程度減少延遲,還可透過平行檔案系統的遠端平行存取能力,結合底層基於大量儲存節點與SSD的分散式架構,輕易就能匯聚出數百GB/s等級、甚至TB/s等級的龐大傳輸頻寬。
所以,各式各樣基於分散式或平行檔案系統的外部儲存設備,也就成為當前AI應用環境的主流儲存架構。
至於GPU伺服器內接的SSD儲存裝置,多半只被用作作業系統與應用程式的存放與運作,但這些軟體耗用的空間並不多,因而許多SSD空間都被閒置。
GPU伺服器端的儲存叢集
過去半年多以來,開始有部分儲存廠商,嘗試將GPU伺服器平時經常處於閒置狀態的內接SSD,部署成為儲存叢集,作為AI儲存應用的另一種選擇。
在實作上,這種架構是利用儲存叢集平臺軟體,將GPU伺服器部署成為1臺儲存節點,然後讓多臺GPU伺服器彼此互連,組成GPU伺服器端的儲存叢集,將GPU伺服器內接NVMe SSD,構成儲存叢集管理下的儲存空間,並利用儲存叢集平臺軟體,來為這些內接SSD提供高可用性與資料保護功能。
更進一步,有些廠商還將這種GPU伺服器端儲存叢集,與外部儲存叢集相互結合,構成橫跨GPU伺服器內部與外部儲存空間,嶄新的分層式AI儲存應用架構。
這種架構的主要訴求有這三點:
首先,是可充分利用閒置的GPU伺服器內接SSD資源。相較於外部儲存設備,GPU伺服器內接SSD的容量雖然不大,但多臺GPU伺服器的內接SSD累積起來也是不小的空間,與其閒置、形成浪費,不如設法加以利用。
其次,可減少對於外部儲存設備的依賴。這種GPU伺服器端的儲存叢集架構,並不能取代外部儲存設備,但可分攤AI應用一部分的儲存需求,從而減少對於外部儲存設備的需求量。
第3,可利用內接NVMe SSD的低延遲特性,加速AI應用。內接NVMe SSD的延遲是數十微秒(μs)等級,而外接儲存設備的延遲,最低也是數百微秒到毫秒(ms)等級,彼此間有著10倍、100倍以上的落差,所以若將GPU伺服器內接SSD,將能為AI應用提供極低延遲的高速儲存層,可更快將資料傳送給GPU,或寫入GPU運算完成資料,顯著提高存取速度。
率先引進這種類型架構的Hammerspace,揭露一個使用案例:由GPU伺服器內接SSD構成的高速儲存層,十分適合用於AI模型的檢查點寫入。
檢查點是用於保存在每個GPU上的AI模型訓練狀態,作為復原或偵錯之用,AI模型可能每小時就需要寫入1次檢查點,每個GPU會為此產生數MB到數GB的資料量,然而,當數十、上百個GPU同時將資料寫入檢查點時,會形成高突發性(Highly Bursty)的資料寫入需求,為儲存裝置帶來龐大的寫入負載壓力,每次寫入檢查點至少需耗時5到10分鐘之久,在寫入檢查點的過程中,GPU都將處於閒置狀態。
而若使用GPU伺服器內接SSD,來承接寫入檢查點的工作,則能將寫入時間從200秒縮短到幾秒鐘,大幅減少寫入檢查點期間的GPU暫停時間,藉此還能增加建立檢查點的頻率,以降低復原後損失的工作量。
GPU伺服器端平行儲存叢集產品
目前有兩家新興儲存廠商發表基於平行檔案系統的GPU端儲存架構,分別為Hammerspace的Tier 0,以及WEKA的NeuralMesh Axon。兩款產品的基本概念,同樣都是將平行檔案系統部署到GPU伺服器端,從而構成基於GPU伺服器的儲存叢集,但是在應用型態上,又存在著關鍵區別。
Hammerspace的Tier 0儲存架構
新創廠商Hammerspace,在2024年11月發布的全域資料平臺GDP(Global Data Platform)軟體5.1版中,率先推出整合GPU伺服器內接SSD的功能,稱作Tier 0,也就是表示第0層儲存之意。
Hammerspace表示,GPU存取這些內接SSD的速度,比存取透過網路連接的外部儲存更快,因而這些內接SSD構成的儲存空間,可整合到該公司全域資料平臺(GDP),作為外部Tier 1儲存層之前、更高速的Tier 0儲存層,以更快速度來回應GPU的存取需求。
該公司聲稱透過Tier 0這項新功能的運用,不僅可以釋放未被充分利用的GPU伺服器本機SSD資源,還能減少對於外部儲存空間的需求,藉此降低外部機架空間占用,冷卻與電力消耗,進而節省成本,若將越多GPU伺服器端SSD納入到Tier 0架構,節省的幅度也越顯著。
Hammerspace還開發一款附加軟體元件Local-IO,與Tier 0功能搭配,用於加速Linux本機存取。Local-IO元件已整合到6.12版Linux Kernel,藉由這項元件,能夠繞過Linux Kernel中的NFS與網路堆疊,減少Linux伺服器本機存取延遲。該公司表示,這項元件可以在GPU與SSD之間,執行無須記憶體複製的資料傳輸,充分發揮NVMe直連傳輸的效能,匯聚多臺SSD時能將傳輸頻寬擴展到100GB/s以上,以及數千萬IOPS效能,並保持僅有幾微秒(μs)的低延遲。進而也讓建立在這個基礎上的Tier 0架構,成為高效能的GPU儲存解決方案。
更進一步而言,若將GPU伺服器內接SSD納入Hammerspace全域資料平臺(GDP)的Tier 0以後,我們還能藉由全域資料平臺,構成可供其他用戶端共享的檔案與物件儲存空間,並搭配其他外部儲存裝置構成的Tier 1、Tier 2、歸檔(Archive)等不同儲存層,提供自動分層存取應用。
Tier 0架構與Local-IO元件也同時適用於用戶地端與雲端環境部署,既能用於GPU運算,也能應用於x86虛擬機器環境,以更快的速度向VM提供資料。
WEKA的NeuralMesh Axon架構
另一新創廠商WEKA,也在2025年7月推出的NeuralMesh Axon軟體架構,引進基於GPU伺服器內接SSD的儲存池。
NeuralMesh Axon是WEKA稍早在今年6月推出,針對AI應用的新一代儲存架構NeuralMesh,改用於GPU伺服器端佈署的延伸發展版本,利用GPU伺服器既有的NVMe SSD、CPU與網路資源,建立一套分散式的儲存叢集環境。
與NeuralMesh一樣,NeuralMesh Axon能支援NFS/SMB、S3等標準存取協定,以及WEKA自身的專屬平行存取用戶端協定,也內含自動修復、動態平衡 I/O與自動擴展,並提供Erasure-coding與快速重建等保護功能。
WEKA表示,NeuralMesh Axon可支援超過100臺GPU伺服器組成叢集,並將資料、metadata與讀寫存取作業,都分散由所有GPU節點承擔,藉此可提供線性的效能增長,並能透過Erasure-coding提供容許最多4臺節點同時失效的容錯能力。另外,它也支援WEKA的增強記憶體網格(Augmented Memory Grid,AMG)功能,可以利用儲存叢集的空間,為大型語言模型的推論提供擴展的KV快取空間。
而且,與WEKA展開合作的雲端AI應用服務商CoreWeave,已在其環境中部署NeuralMesh Axon,他們的實測顯示,每臺NeuralMesh Axon架構當中的GPU節點,可提供30 GB/s與12 GB/s的讀取與寫入吞吐率,IOPS效能達100萬,還有微秒等級的存取延遲。
由於NeuralMesh Axon是利用現成的GPU伺服器來建構,WEKA聲稱藉此可降低對於外部儲存空間的需求,節省機架空間,以及電力與冷卻需求。也就是說,透過NeuralMesh Axon,GPU伺服器叢集自身就能建構出高效能、高可用性的儲存空間,將儲存服務直接嵌入GPU伺服器,形成融合式的「運算—儲存」架構。
目前WEKA已向部分特定用戶提供NeuralMesh Axon,預定今年秋季正式全面上市。
兩種架構的異同
Hammerspace的Tier 0架構,與WEKA的NeuralMesh Axon,基本概念都是以自身的平行檔案系統為基礎,使用GPU伺服器的內接SSD,建構為GPU伺服器端的儲存叢集,但2者間也存在關鍵區別。
Hammerspace的Tier 0是放在該公司尺度更大的全域資料平臺(Global Data Platform)框架下,作為最接近GPU、延遲最低的高速儲存層,Tier 0是這個多層儲存框架的其中一層,能與外部儲存裝置構成的其他儲存層搭配,構成跨不同類型裝置的自動分層儲存應用。
而WEKA的NeuralMesh Axon,則是單純的GPU伺服器端儲存叢集,並沒有結合其他外部儲存裝置、進行自動分層儲存應用的功能。
GPU伺服器端儲存叢集的利弊
Hammerspace與WEKA推出的GPU伺服器端儲存叢集,訴求都是直接利用現成的GPU伺服器SSD與網路資源,無需額外設備,即可建構出低延遲、高效能的儲存服務,不僅經濟,而且架構簡單,效能也高。
如同我們前面提到的,GPU伺服器內接SSD的空間,大多未被充分使用,與其閒置,不如拿來加入儲存叢集,發揮剩餘價值。其次,GPU伺服器內接SSD是透過NVMe與GPU直連,資料傳輸距離比起透過網路介接的外部儲存設備,要短得多,存取延遲自然最少。
但這種架構的副作用,也正是從「使用GPU內接SSD」這項最大特點而來。使用GPU伺服器內接SSD來建構儲存叢集,意味著把GPU伺服器作為儲存叢集節點,必須在GPU伺服器上部署與執行儲存叢集軟體,會占用一部分GPU伺服器的CPU、記憶體與網路資源,對於GPU伺服器上所運行的其他應用程式工作負載,難以避免地會造成一定程度影響與干擾,對於這類GPU伺服器端儲存叢集架構而言,也將成為評估採用與否的關鍵。
典型的AI應用儲存架構
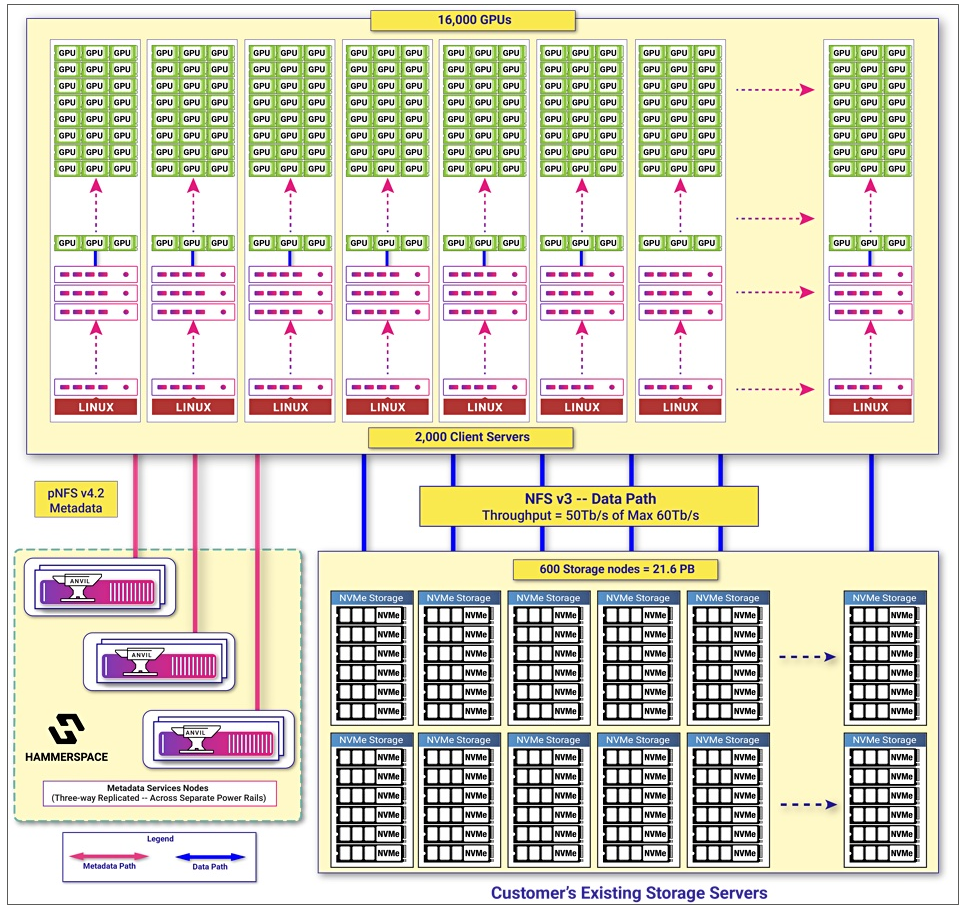
在典型的AI應用環境中,考慮到容量、傳輸效能與資源管理需求,主要是以外部儲存設備來提供儲存空間,GPU伺服器自身的內接SSD只作為次要角色。如上圖中的Meta Llama 基礎設施的儲存架構,便是以容量21.5 PB的Tectonic儲存叢集平臺作為資料儲存空間,搭配Hammerspace的平行檔案系統負責matadata服務。
不過,近來部分廠商一反這種典型架構,試圖將GPU伺服器閒置的內接SSD空間,建構為高效能儲存層使用。圖片來源/Hammerspace
未被充分使用的GPU伺服器內接SSD
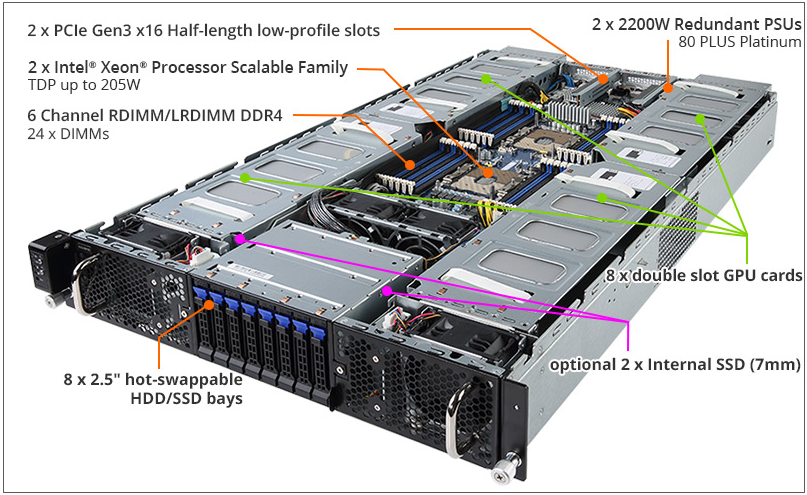
GPU伺服器雖然也配置一定數量內接SSD,但是在多數AI應用環境中,AI模型的主要儲存需求是透過外部的儲存設備來提供,GPU伺服器內接SSD提供作業系統運作的基本用途外,大量空間都是閒置。上圖為技嘉的G291-280伺服器,能安裝8張GPU加速卡的同時,最多可安裝8臺熱抽換SSD,加上2臺不可熱抽換的內接SSD。圖片來源/技嘉科技
Hammerspace的Tier 0架構
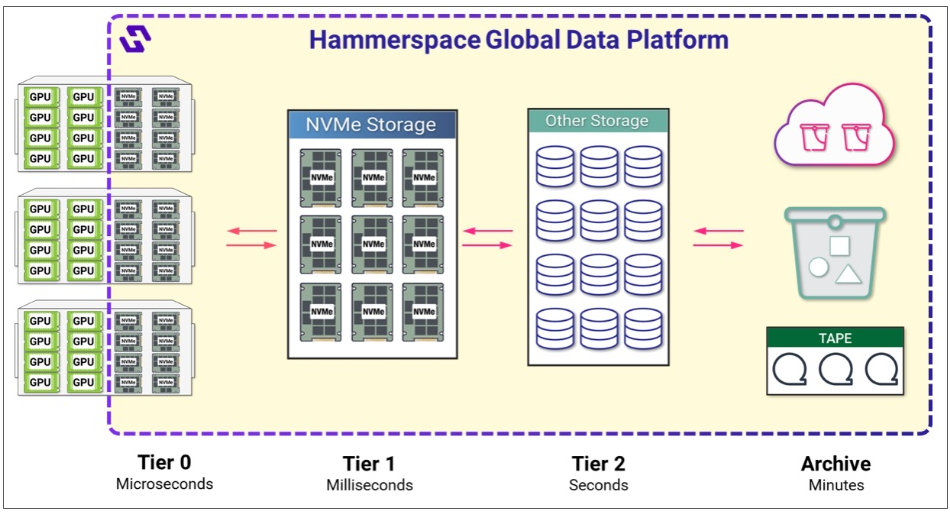
這套資料儲存架構的基本概念,是將GPU伺服器的內接SSD空間,整合到Hammerspace的全域資料平臺中,作為低延遲的Tier 0高速儲存層,搭配作為Tier 1、Tier 2與Tier 3對應的外部NVMe儲存裝置、硬碟、磁帶,組成分層儲存架構。相較於外部儲存設備,GPU伺服器內接SSD優點是存取延遲更低,只有微秒(μs)等級,相較之下,透過網路介接的外部NVMe儲存裝置、硬碟與磁帶設備存取延遲則是毫秒(ms)、秒、分鐘的等級。圖片來源/Hammerspace
WEKA的NeuralMesh Axon架構
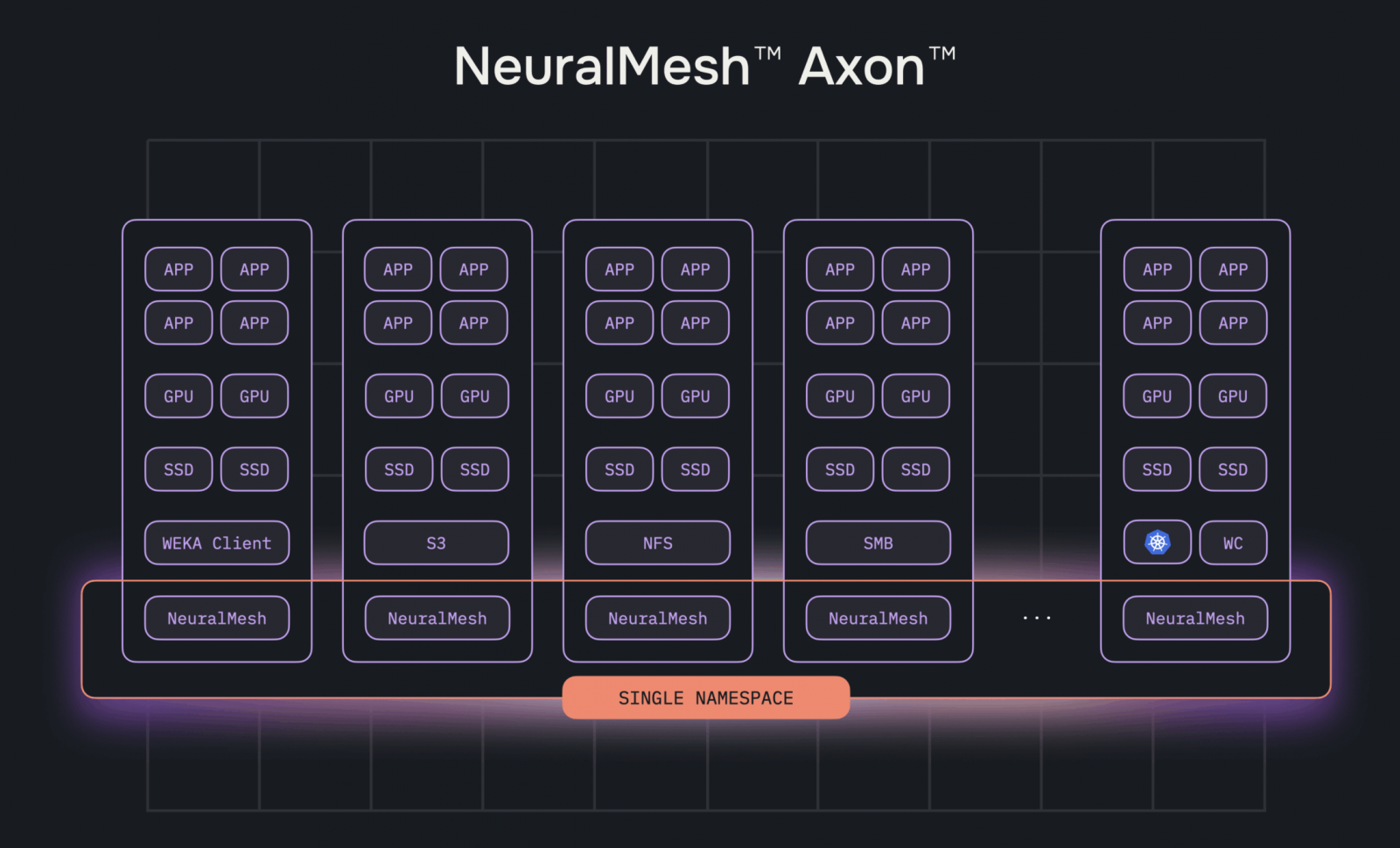
NeuralMesh Axon是基於WEKA的NeuralMesh微服務化儲存平臺,用於GPU伺服器端部署的延伸發展版本,可將多臺GPU伺服器的內接SSD,透過網路相互連結,成為一套分散式的儲存叢集環境,從而降低對於外部儲存設備的依賴。圖片來源/WEKA
