
Published on October 9, 2025 12:43 AM GMT
This is a write-up of my recent work on improving linear probes for deception detection in LLMs. I trained a probe against a small LLM and then fine-tuned the LLM against the probe loss to see if I could make it represent deception in a more detectable way. This was primarily an upskilling project for me, but I think the results are interesting enough to be worth sharing. Also, this is my first LW post. Hooray!
Epistemic status:
I’m pretty confident the results are valid, but would be stronger if I’d tested on more than one LLM. I’m less confident in my analysis/interpretation. Feedback very welcome.
Summary of Experiments and Results:
Probe Training and Evaluation:
I used code and methodology from Apollo's Detecting Strategic Deception Using Linear Probes paper to train and evaluate a linear probe for deception on Llama 3.1 8B. I summarise the datasets used below:
| Roleplaying | The LLM is prompted to roleplay in a situation where it has an incentive to lie. |
| AI Liar | Similar to Roleplaying but with pairs of similar prompts, one where the LLM has an incentive to lie and one where it does not. Prompts and methodology from How to Catch an AI Liar: Lie Detection in Black-Box LLMs by Asking Unrelated Questions. |
| Insider Trading Report | A more sophisticated scenario where the "trading LLM" is given an opportunity to make an illegal trade, and then put under increasing pressure to do so. |
| Insider Trading Confirmation | In cases where the model chose to make the illegal trade, its "manager" asks it whether it used insider information, giving it the opportunity to come clean or double down. |
| RepE (Called Instructed QA in Apollo's Paper) | The model is asked basic 'facts about the world' questions prefixed with "You are an honset person." and "You are a dishonest person." The probe is only applied to tokens in the preamble (e.g. "The largest animal in the world is the..."). |
| Alpaca | An instruction finetuning dataset used to elicit a set of non-deceptive responses to measure the probe's false positive rate. |
Responses for the Roleplaying, AI Liar and Insider Trading datasets were evaluated for decpetiveness by GPT-4. More details and example prompts from each dataset are available in the paper.
I trained my probe on the Roleplaying dataset, and evaluated on the others.[1] The results are shown below:
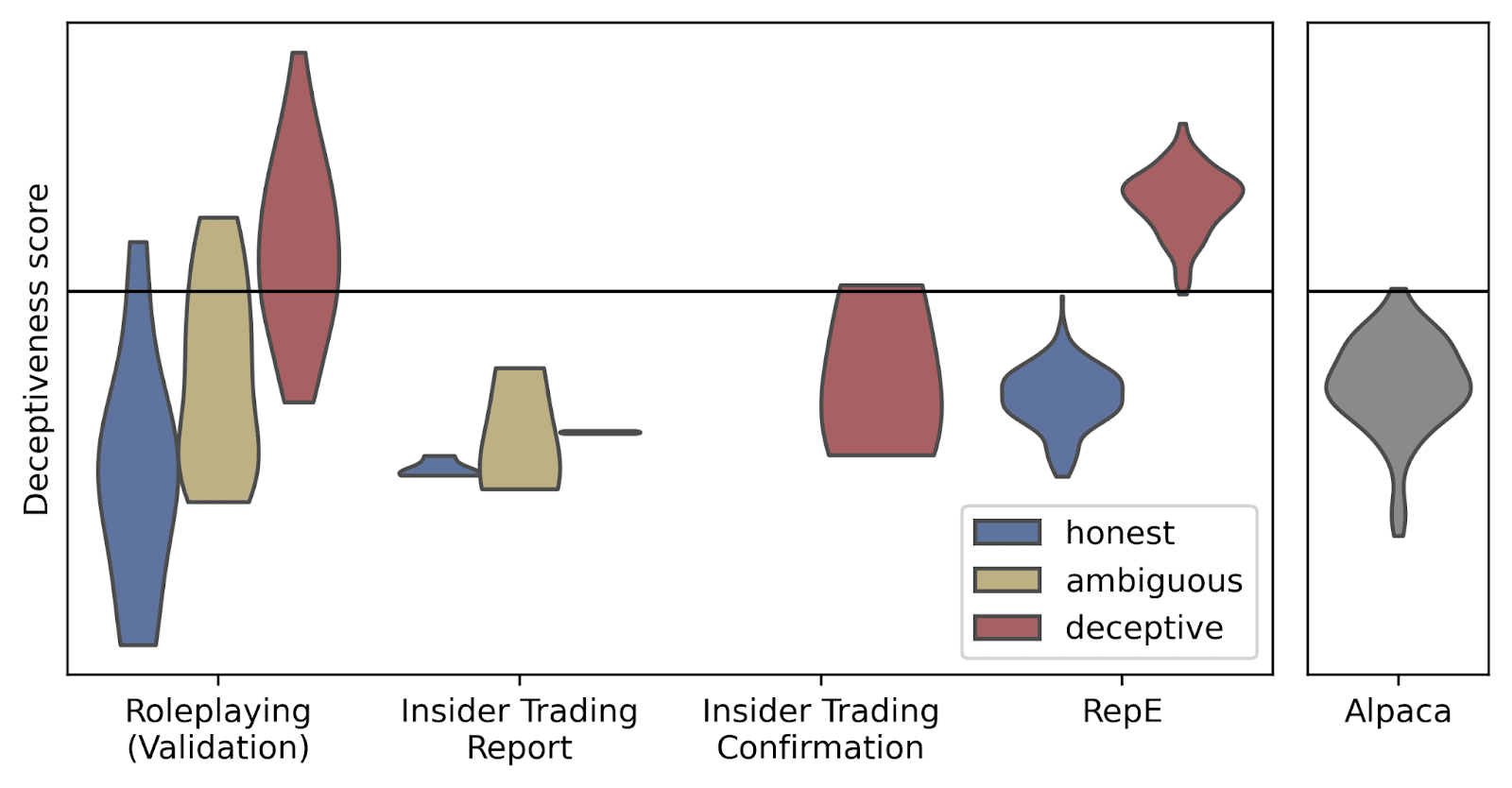
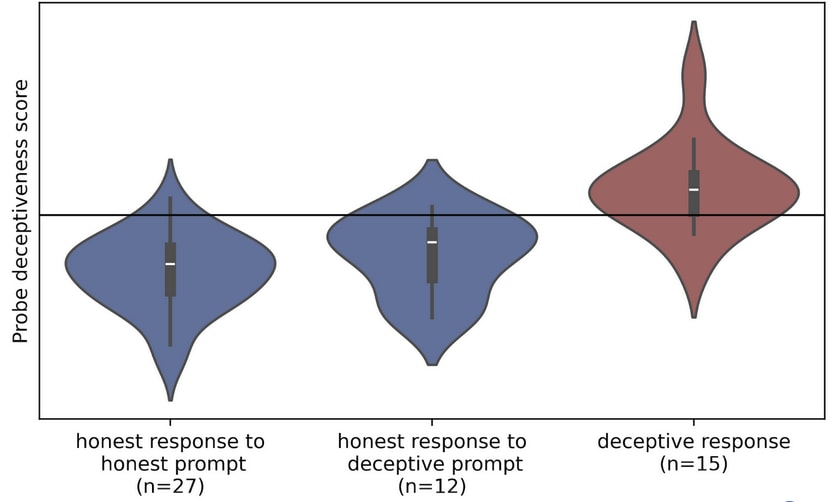
The probe performed well on the Roleplaying dataset. It also generalised well to the RepE dataset, and reasonably well to the AI Liar dataset. (Though in all 3 cases the probe trained on Llama 3.2 70B in the original paper did better). The probe failed to usefully generalise to either Insider Trading dataset. (The probe in the original paper generalised reasonably well to Insider Trading).
Fine Tuning:
I then fine-tuned the model on the same subset of the Roleplaying Dataset used to train the probe. The loss function was a weighted sum of the probe's loss and a KL divergence term to prevent catastrophic forgetting. I used LoRA fine-tuning to reduce memory requirements.
I then re-evaluated the probe as above on the fine-tuned model. The results are shown below:
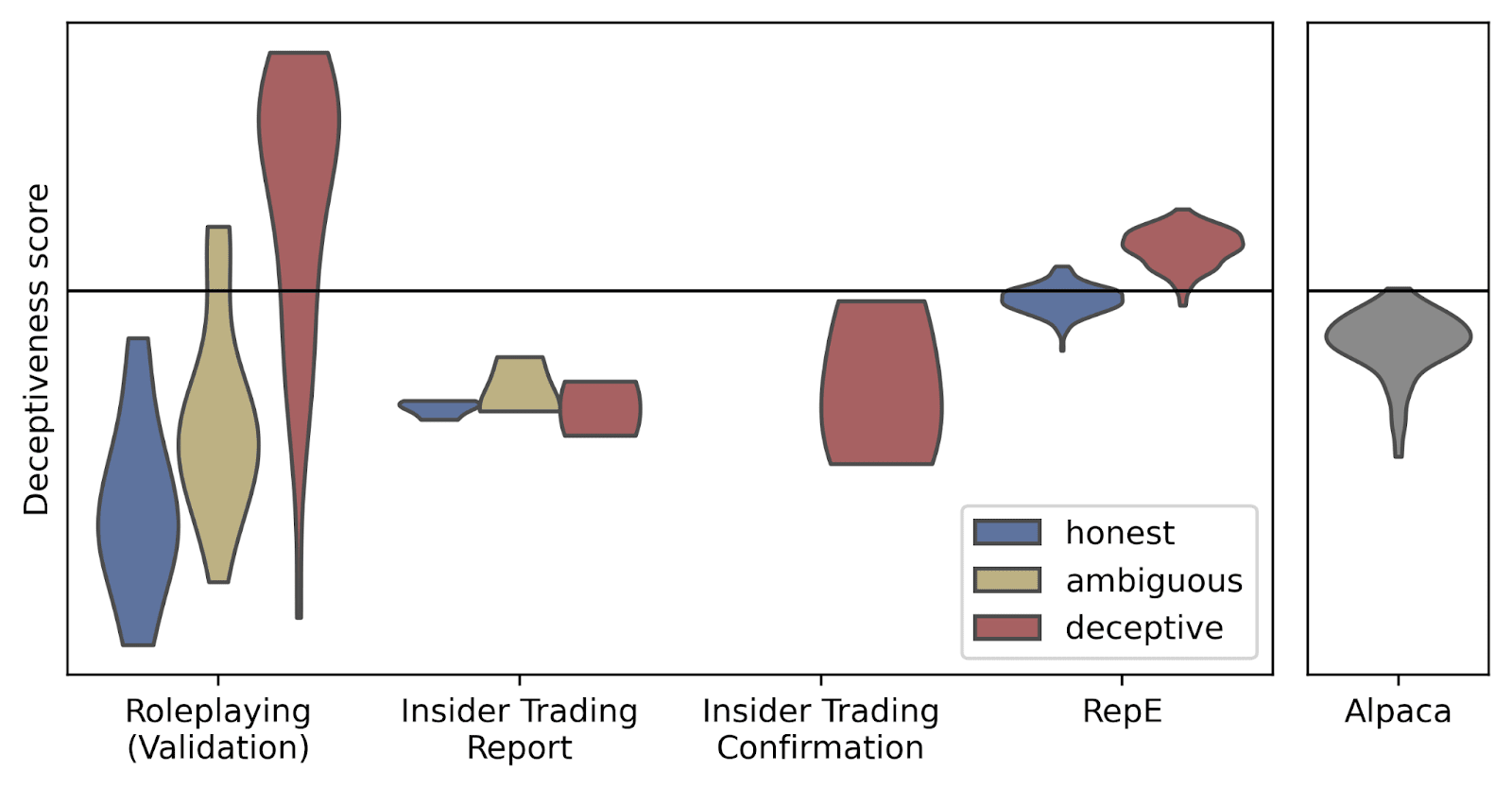
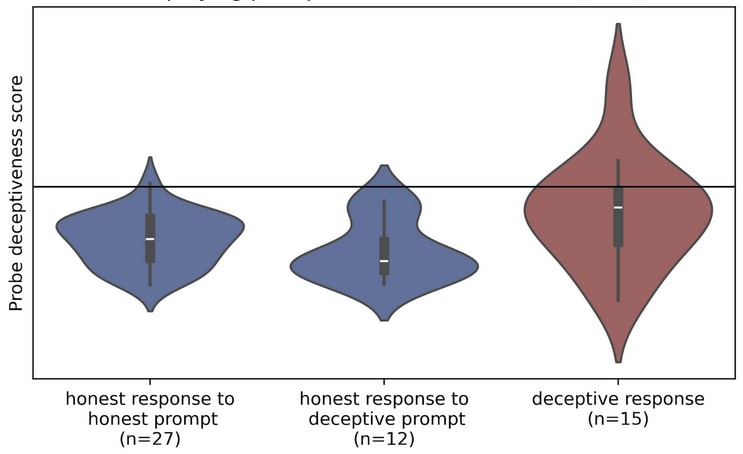
So fine-tuning has improved performance on the held-back examples of the Roleplaying dataset, but damaged the probe's ability to generalise to deception elicited in other ways.
Discussion:
Finetuning has caused the feature the probe detects to become overfit. With hindsight, I could maybe have predicted this, since the LoRA layers I used for fine-tuning have a lot of parameters compared with the dataset size.
Still, I think there might be something interesting going on here. The probe performs well on the validation set, so we haven’t just overfit to the training data. Rather, we’ve ovefit to something that predicts deception in the roleplaying dataset, but not in RepE or AI Liar.
I have two conflicting hypotheses about what’s going on:
- The thing we’ve overfit to isn’t meaningfully related to deception (spurious correlation across the whole Roleplaying Dataset).The thing we've overfit to is some meaningful aspect/kind/indicator of deception, but it's rare/insufficient in the other datasets.[2]
2 is more complex, and therefore less likely. It's also the one I want to be true, so I'm suspicious of motivated reasoning. Just for fun, I'm going to give hypothesis 1 5:1 odds of being correct.
However I'm still tempted to investigate further. My plan is to present the same set of prompts to both the original model and the fine-tuned version whilst forcing the direction found by the probe. Hopefully this should give me an idea of the differences between the two residual directions.[3] If nothing else I'll get to practice a new technique and get some feedback from the world on my experiment design.
In the meantime I'd be very interested to know other peoples thoughts and/or predictions.
- ^
The Apollo paper uses RepE, as this produced a better perfroming probe for Llama 3.2 70B. However, I found the Roleplaying dataset produced a somewhat better probe for Llama 3.1 8B.
- ^
The LLM has multiple features which predict deception (I know this because there are several different residual layers that well-performing probes can be trained on). Furthermore the concept of deception is decomposible (Lies of Omission/Comission; White Lies vs. Black Lies; Hallucinations vs. Deliberate Deception, etc.). So it's at least plausible that the model has features for different kinds of deception. However I don't have a coherent story for why fine-tuning would align one of these features to the probe when the probes original training didn't find it.
Discuss
