
Rust rewrites, trends, and what’s next for Rust at P99 CONF (free + virtual) (Sponsored)

P99 CONF is the technical conference for anyone who obsesses over high-performance, low-latency applications. Naturally, Rust is a core topic.
How is Rust being applied to solve today’s low latency challenges – and where it could be heading next? That’s what experts from Clickhouse, Prime Video, Neon, Datadog, and more will be exploring
Join 20K of your peers for an unprecedented opportunity to learn from engineers at Pinterest, Gemini, Arm, Rivian and VW Group Technology, Meta, Wayfair, Disney, Uber, NVIDIA, and more – for free, from anywhere.
Bonus: Registrants can win 500 free swag packs and get 30-day access to the complete O’Reilly library.
Disclaimer: The details in this post have been derived from the official documentation shared online by the Flipkart Engineering Team. All credit for the technical details goes to the Flipkart Engineering Team. The links to the original articles and sources are present in the references section at the end of the post. We’ve attempted to analyze the details and provide our input about them. If you find any inaccuracies or omissions, please leave a comment, and we will do our best to fix them.
Flipkart is one of India’s largest e-commerce platforms with over 500 million users and 150-200 million daily users. It handles extreme surges in traffic during events like its Big Billion Days sale. To keep the business running smoothly, the company relies on thousands of microservices that cover every part of its operations, from order management to logistics and supply chain systems.
Among these systems, the most critical transactional domains depend on MySQL because it provides the durability and ACID guarantees that e-commerce workloads demand. However, managing MySQL at Flipkart’s scale presented serious challenges. Each engineering team often operated its own database clusters, resulting in uneven practices, duplicated effort, and a high operational burden. This complexity was most visible during peak shopping periods, when even small inefficiencies could cascade into major disruptions.
To solve this, the Flipkart engineering team built Altair, an internally managed service designed to offer MySQL with high availability (HA) as a standard feature.
Altair’s purpose is to ensure that the company’s most important databases remain consistently available for writes, while also reducing the manual work required by teams to keep them healthy. In practice, this means that Flipkart engineers can focus more on building services while relying on Altair to handle the heavy lifting of database failover, recovery, and availability management.
In this article, we will look at how Altair works under the hood, the technical decisions Flipkart made to balance availability and consistency, and the engineering trade-offs that come with running relational databases at a massive scale.
Help us Make ByteByteGo Newsletter Better
TL:DR: Take this 2-minute survey so I can learn more about who you are,. what you do, and how I can improve ByteByteGo
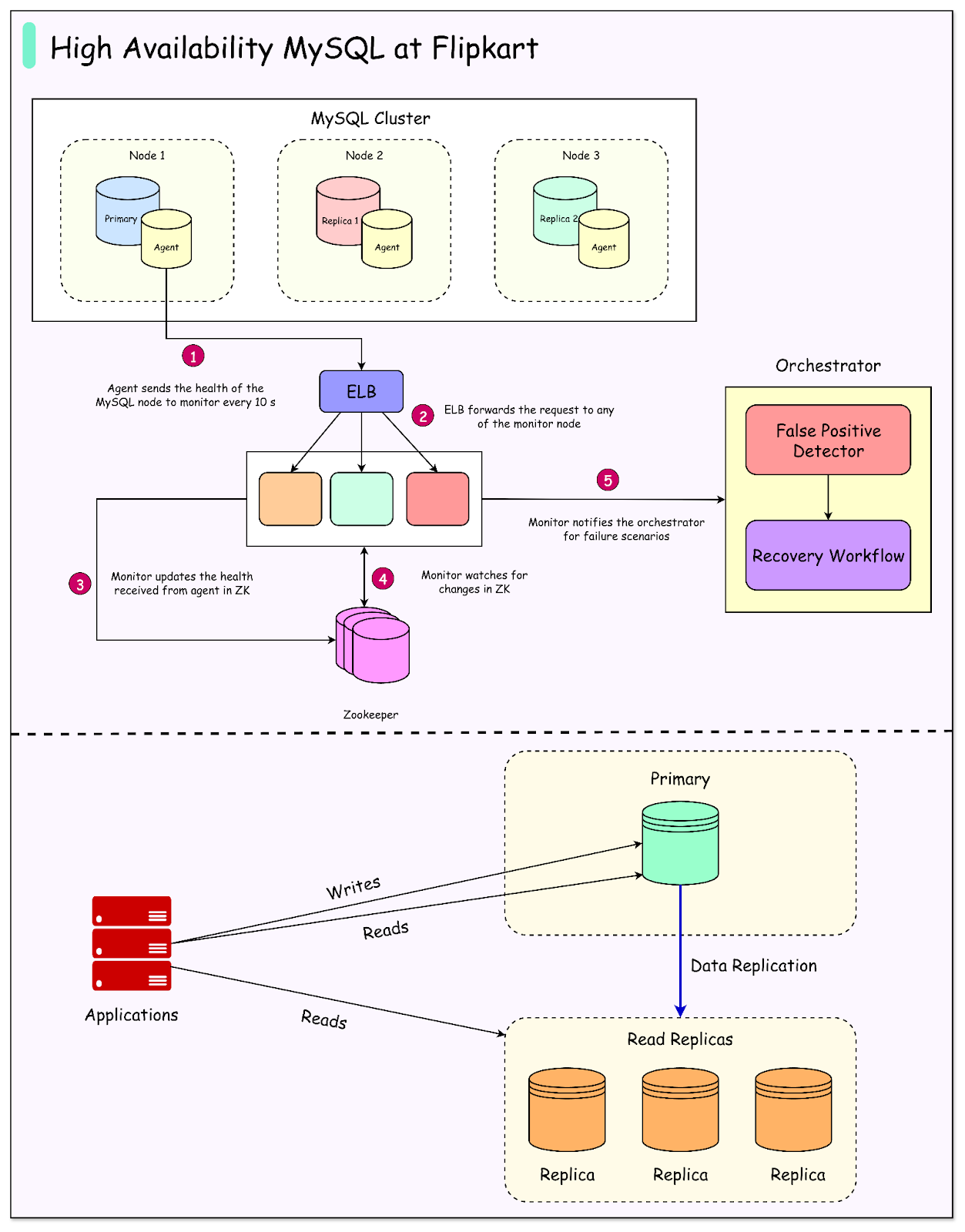
High Availability Model at Flipkart
Flipkart’s Altair system uses a primary–replica setup to keep MySQL highly available.
In this model, there is always one primary database that accepts all the writes. This primary may also handle some reads. Alongside it are one or more replicas. These replicas continuously copy data from the primary in an asynchronous manner, which means there can be a small delay before changes appear on them. Replicas usually handle most of the read traffic, while the primary focuses on writes.
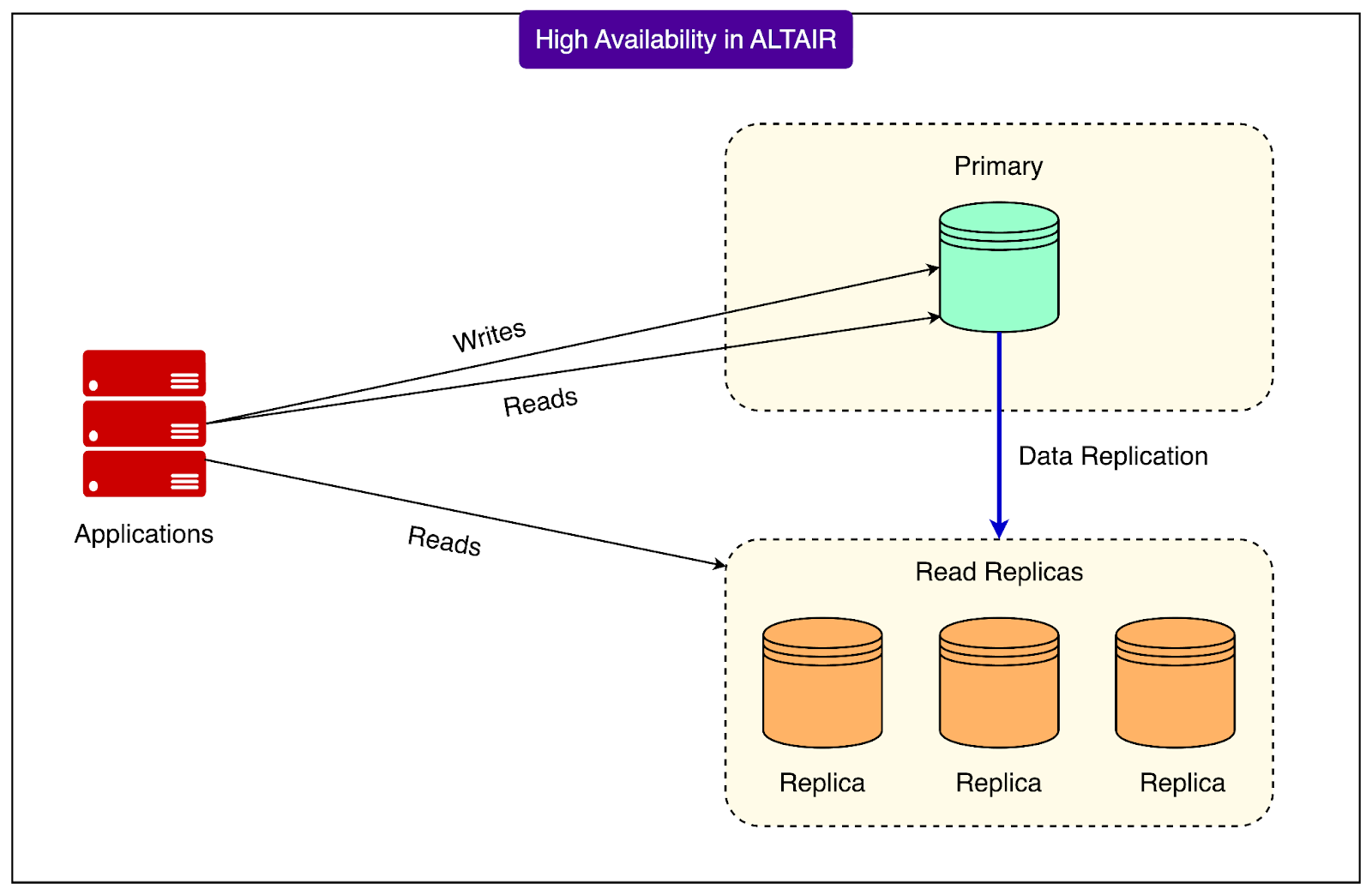
The main goal of this setup is simple: if the primary fails, the system should quickly promote a healthy replica to take its place as the new primary. This ensures that write operations remain available with minimal disruption.
Flipkart’s availability target for Altair is very high, close to what is known as “five nines.” That means the system is expected to stay up and running more than 99.999 percent of the time. Of course, no complex system can ever promise perfect uptime, but the goal is to keep downtime as close to zero as possible.
To make failover reliable, the Flipkart engineering team considered several important factors:
Data-loss tolerance: Making sure as little data as possible is lost during failover.
Fault detection reliability: Ensuring the system can accurately tell when the primary has truly failed.
Failover workflow strength: Designing a robust process to handle the switch without errors.
Network partition handling: Making the system resilient when parts of the network cannot talk to each other.
Fencing the old primary: Preventing the failed primary from accidentally accepting new writes.
Split-brain prevention: Avoiding a situation where two nodes think they are the primary at the same time.
Automation: Reducing the need for human intervention, so failover can happen quickly and consistently.
By combining these elements, Altair is designed to keep MySQL highly available even under failure conditions.
End-to-End Failure Workflow
When a primary database fails, Altair follows a well-defined sequence of steps to recover and make sure applications can continue writing data. This process is called a failover workflow, and it involves multiple components working together.
The workflow has five main stages:
Failure detection: The system continuously monitors all MySQL nodes to check if something goes wrong with the primary. If it looks unhealthy or unreachable, a failure is suspected.
False-positive screening: Before taking any big action, Altair double-checks whether the failure is real. Sometimes a node might look down because of a temporary glitch, but it is still fine. This step ensures that the system does not promote a new primary unnecessarily.
Failover tasks: If the primary is truly down, the system begins the recovery job. This includes stopping or fencing the old primary, choosing the best replica, and promoting it to primary.
Service discovery update: Once a new primary is ready, Altair updates the DNS record so that applications connecting to the database automatically point to the new primary. This means applications usually do not need to restart.
Fencing the old primary: To avoid two databases acting as primary at the same time, Altair tries to mark the old primary as read-only or completely stop it. This step is critical for preventing split-brain, where two nodes could accept writes independently.
How Failure Detection Works
Altair uses a three-layered monitoring system to detect failures:
Agent: A lightweight program runs on each database node. It checks the MySQL process, replication status, replication lag, and disk usage. It reports this health information every 10 seconds.
Monitor: A Go-based microservice collects these health reports. It writes the status to ZooKeeper, also every 10 seconds. The monitor compares old and new health states, checks if thresholds are breached, and flags possible issues. If a failure is suspected, it alerts the orchestrator. Multiple monitors can run in parallel, making the system scalable as Flipkart grows.
Orchestrator: This is the brain of the workflow. It verifies if the failure is real or just a false alarm. If the problem is confirmed, it initiates the failover process.
See the diagram below:
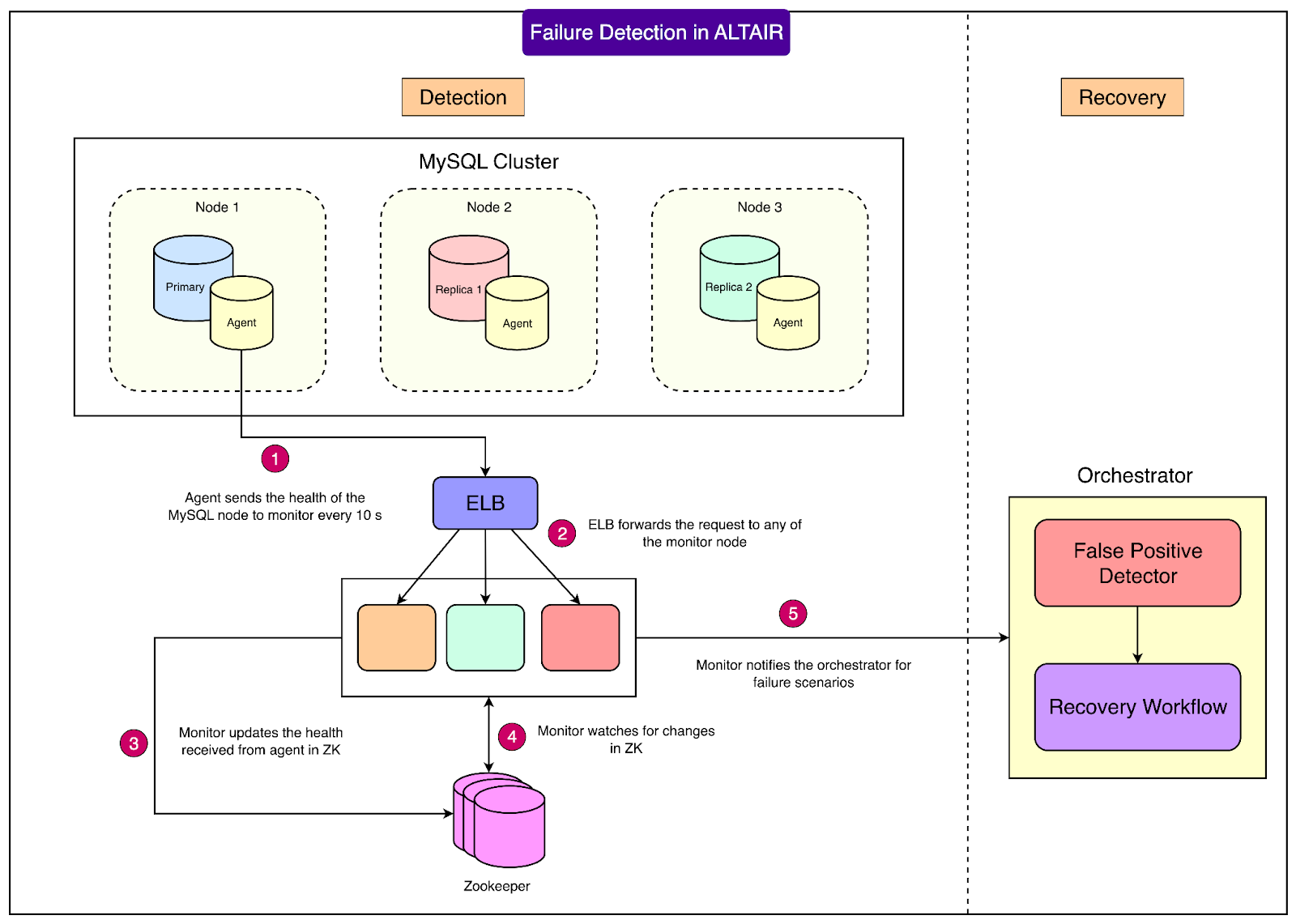
Preventing false alarms
Instead of simply relying on a few missed signals, Altair performs deeper checks:
It verifies whether the virtual machine running the database is healthy.
It checks if replicas can still connect to the primary.
It also tests whether the orchestrator itself can reach the primary.
The rule is straightforward: as long as either the orchestrator or at least one replica can connect to the primary, the primary is considered alive. If both fail, the system proceeds with failover.
Steps during failover
When the orchestrator decides to failover, Altair runs these tasks in order:
Temporarily stop monitoring the affected node.
Allow replicas to catch up by applying all pending relay logs. This reduces data loss.
Set the old primary to read-only if it is still reachable.
Stop the old primary completely if possible.
Promote the best replica to the primary.
Update DNS so that applications automatically connect to the new primary.
See the diagram below:
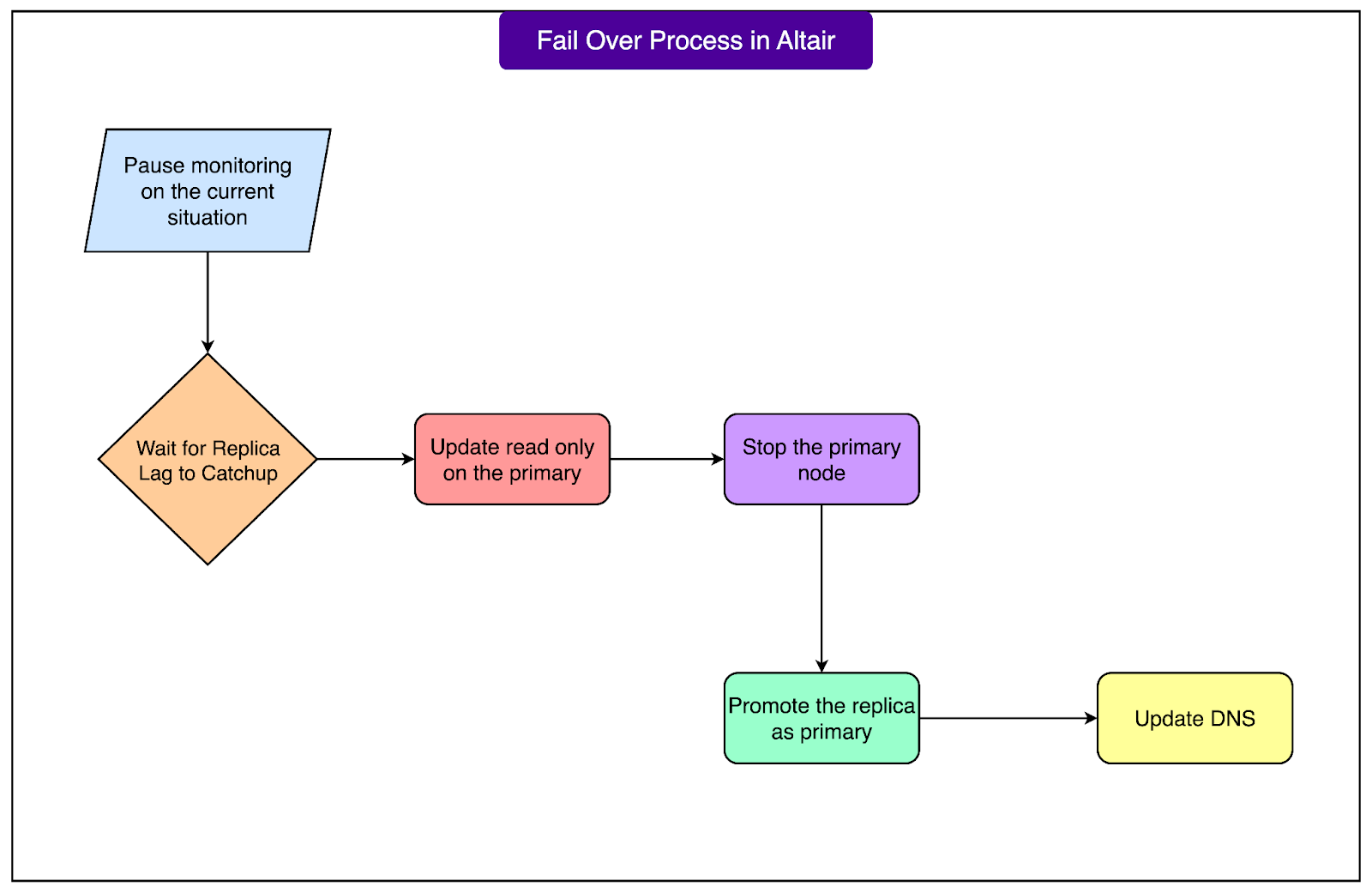
This structured approach ensures that failovers are smooth, data loss is minimized, and applications reconnect to the new primary without manual intervention in most cases.
Service Discovery
Once a failover is complete, applications need to know where the new primary database is located. Altair solves this using DNS-based service discovery.
Here’s how it works:
Applications connect to the database using a fixed DNS name (for example, orders-db-primary.flipkart.com).
Behind the scenes, this DNS name points to the IP address of the current primary.
When a failover happens, Altair updates the DNS record so that the name now points to the new primary’s IP address.
This design means that most applications do not need any manual updates or restarts. As soon as they make a fresh connection, they automatically reach the new primary.
The only exceptions are unusual situations where DNS changes are not picked up or where the network is partitioned in a way that requires manual intervention. In those rare cases, Flipkart’s engineering team coordinates with client teams to restart applications and ensure traffic points to the right place.
Split-Brain Risks
One of the biggest risks in any high-availability setup is something called split-brain. This happens when two different nodes both think they are the primary at the same time. If both accept writes, the data can diverge and become inconsistent across the cluster. Fixing this later requires painful reconciliation.
Split-brain usually occurs during network partitions. Imagine the primary is healthy, but because of a network issue, the rest of the system cannot reach it. From their perspective, it looks dead. A replica is then promoted to primary, while the original primary continues accepting writes. Now there are two primaries.
See the diagram below:
With MySQL’s asynchronous replication, this problem is even harder to solve because the system cannot guarantee both strong consistency and availability during a network split. Flipkart chooses to prioritize availability, but adds safeguards to prevent split-brain.
If split-brain happens, the effects can be serious. Orders might be split across two different databases, leading to confusion for both customers and sellers. Reconciling this data later is time-consuming and costly. Flipkart cites GitHub’s 2018 incident as an example, where a short connectivity problem led to nearly 24 hours of reconciliation work.
Altair includes multiple safeguards to defend against a split-brain scenario:
During failover, it tries to stop the old primary so it cannot accept new writes.
In planned failovers, it first sets the old primary to read-only, ensuring no further writes are accepted before switching roles.
If the old primary cannot be stopped (for example, because of a severe partition), Altair may still promote a replica to keep the system available.
In uncertain situations where the control plane cannot determine the exact state of the primary, Altair follows a careful procedure:
Pause the failover job.
Notify client teams to stop applications from writing.
Resume failover, promote the replica, and update DNS.
Ask clients to restart applications so they connect to the correct new primary.
See the diagram below:
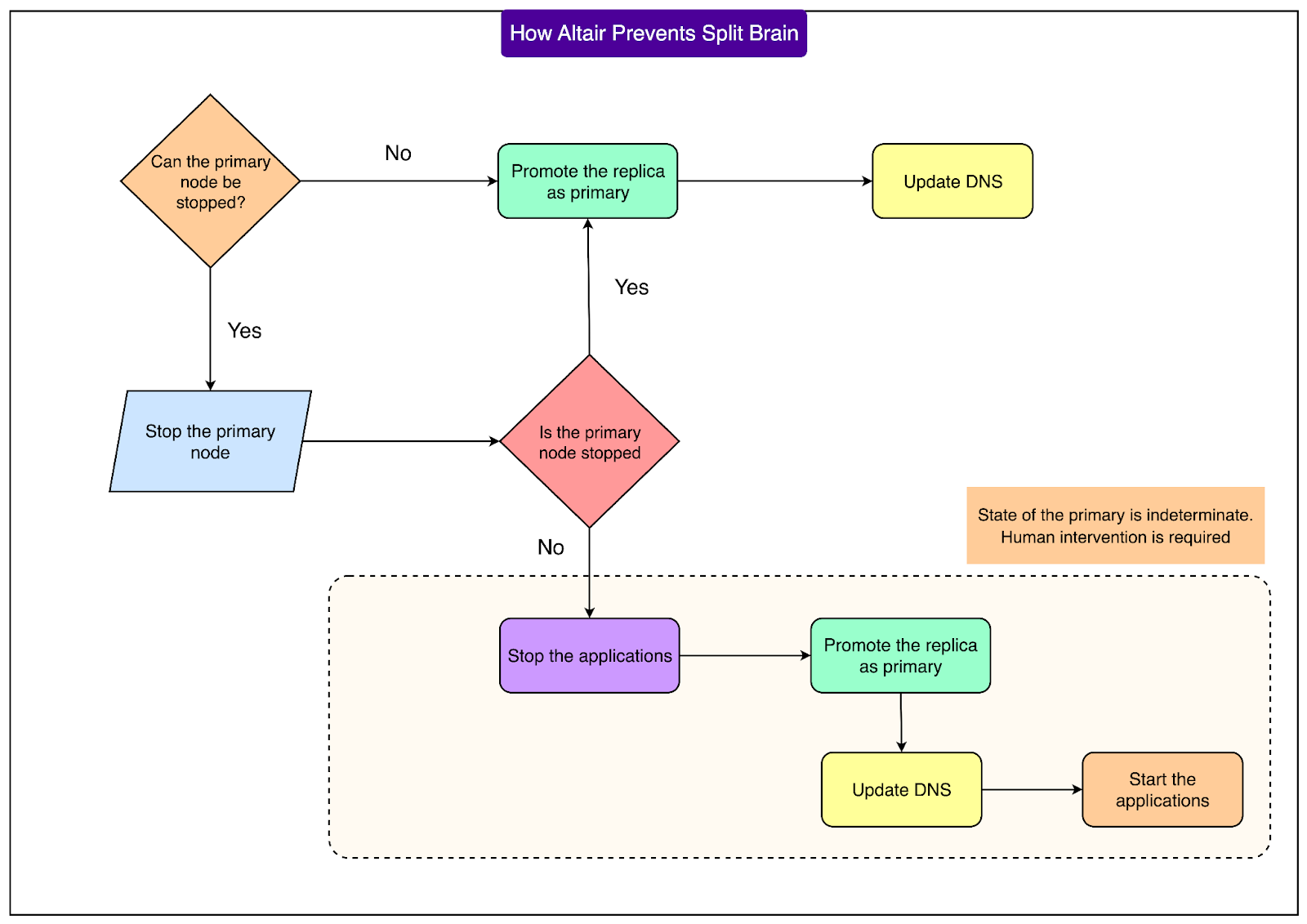
This process ensures that the risk of having two primaries is avoided, even if it requires a brief pause in availability.
Failure Scenarios and How Altair Handles Them
Databases can fail in many different ways, and each type of failure needs to be handled carefully.
Altair is designed to detect different failure scenarios and react appropriately so that downtime is minimized and data remains safe. Let’s go through the major cases and see how Altair deals with each one.
1 - Node (Host) Failure
Sometimes the entire machine (virtual machine or physical host) running the primary database can go down.
In such a case, the local agent running on that machine stops sending health updates. When the monitor does not receive three consecutive 10-second updates (about 30 seconds of silence), it marks the node as unhealthy and alerts the orchestrator.
The orchestrator verifies that the node is really unreachable and then triggers a failover, promoting a replica to become the new primary.
2 - MySQL Process Failure
Even if the host machine is fine, the MySQL process itself may crash. Here’s what happens in this case:
The agent reports that MySQL is down, but it can still confirm that the host is healthy.
The monitor notices the mismatch between host health and MySQL process health.
The orchestrator double-checks this situation and, once confirmed, starts the failover process.
3 - Network Partition Between Primary and Replicas
Sometimes the primary and replicas cannot talk to each other because of a network issue, even though both are still alive. In other words, replicas lose connectivity to the primary.
This alone is not enough reason to trigger a failover. The system avoids acting on replica-only signals because the primary may still be healthy and reachable by clients.
4 - Network Partitions Between the Control Plane and Primary
This is more complex because Altair’s control plane (monitor and orchestrator) might lose communication with the primary while the primary itself is still running. Altair has to carefully analyze the situation to avoid false failovers.
There are three sub-cases:
Orchestrator cannot reach the primary, but the monitor still can. In this case:
The monitor continues to get health updates from the agent.
If the monitor notices a failure (like a MySQL crash), it alerts the orchestrator.
Even though the orchestrator’s own pings fail, it trusts the monitor’s updates.
Failover may still happen if replicas are available, but Altair also tries to fence the primary before promoting another node.
The monitor cannot reach the primary, but the orchestrator still can. In this case:
The monitor misses health updates and suspects the primary is down.
The orchestrator, however, can still confirm that the primary is alive and MySQL is running.
In this case, Altair treats it as a false alarm and avoids unnecessary failover.
Both the monitor and the orchestrator cannot reach the primary. In this case:
The situation looks the same as a total primary failure.
Altair proceeds with the failover process, fencing the old primary if possible before promoting a replica.
Design Highlights and Trade-Offs
Building a system like Altair means balancing several competing goals. The Flipkart engineering team had to make careful choices about what to prioritize and how to design the system so that it worked reliably at scale. Here are the key highlights and trade-offs.
Balancing Consistency and Availability
MySQL in Altair uses asynchronous replication. This means that replicas copy data from the primary with a slight delay. Because of this, there is always a trade-off:
If you want strong consistency, you must wait for every replica to confirm each write, but that slows things down and can hurt availability during failures.
If you want high availability, you accept that a small amount of data might be lost during a failover, because the replicas may not have received the very latest writes.
Flipkart chose to prioritize availability.
In practice, this means that during failover, some of the last few transactions on the old primary might not make it to the new primary. Altair reduces this risk by letting replicas catch up on relay logs whenever possible and by making planned failovers read-only before switching roles. But in unplanned crashes, a small amount of data loss is possible.
Smarter Health Checks
One of Altair’s biggest strengths is how it avoids false alarms.
Instead of just checking whether a few signals are missed, it uses multiple sources of truth:
The state of the virtual machine,
Replica connectivity to the primary, and
Direct connectivity between the orchestrator and the primary.
This layered approach prevents unnecessary failovers that could disrupt the system when the primary is actually fine.
Simplified Service Discovery
Altair uses DNS indirection to make failovers smooth.
By updating the DNS record of the primary after promotion, applications automatically connect to the new primary without needing to change code or restart in most cases. This keeps the system simpler for developers who build on top of it.
Scalable Monitoring Design
Altair’s monitoring system is designed to scale as Flipkart grows:
The agent collects health data from every node.
Monitor processes the data and stores it in ZooKeeper. Multiple monitors can run in parallel, so the system can supervise many clusters at once.
Orchestrator makes final decisions and triggers failover when needed.
This separation of responsibilities ensures both reliability and scalability.
Conclusion
Altair represents Flipkart’s answer to the difficult problem of keeping relational databases highly available at a massive scale.
By standardizing on a primary–replica setup with asynchronous replication, the engineering team ensured that MySQL could continue to serve as the backbone for critical transactional systems. The system emphasizes write availability, while carefully minimizing data loss through relay log catch-up and planned read-only failovers.
Altair’s layered monitoring design (combining agents, monitors, ZooKeeper, and an orchestrator) allows reliable detection of failures without triggering false positives. Service discovery through DNS updates keeps application integration simple, while fencing mechanisms and procedural safeguards protect against the dangerous risk of split-brain. The system also scales horizontally, supervising thousands of clusters across Flipkart’s microservices.
The key trade-off is accepting the possibility of minor data loss in exchange for fast, automated recovery.
By doing so, Altair balances consistency, availability, and operational simplicity in a way that matches Flipkart’s business needs. In practice, this design has reduced operational overhead and delivered dependable high availability during peak events, making MySQL a reliable foundation for Flipkart’s e-commerce platform.
References:
SPONSOR US
Get your product in front of more than 1,000,000 tech professionals.
Our newsletter puts your products and services directly in front of an audience that matters - hundreds of thousands of engineering leaders and senior engineers - who have influence over significant tech decisions and big purchases.
Space Fills Up Fast - Reserve Today
Ad spots typically sell out about 4 weeks in advance. To ensure your ad reaches this influential audience, reserve your space now by emailing sponsorship@bytebytego.com.
