
I spent the weekend debating AI timelines, among other things, at The Curve conference. This translates as spending the weekend thinking about the trajectory of AI progress with a mix of DC and SF types. This is a worthwhile event that served as a great, high-bandwidth way to check in on timelines and expectations of the AI industry.
Updating timelines
My most striking takeaway is that the AI 2027 sequence of events, from AI models automating research engineers to later automating AI research, and potentially a singularity if your reasoning is so inclined, is becoming a standard by which many debates on AI progress operate under and tinker with. It’s good that many people are taking the long term seriously, but there’s a risk in so many people assuming a certain sequence of events is a sure thing and only debating the timeframe by which they arrive.
I’ve documented my views on the near term of AI progress and not much has changed, but through repetition I’m developing a more refined version of the arguments. I add this depth to my takes in this post.
I think automating the “AI Research Engineer (RE)” is doable in the 3-7 year range — meaning the person that takes a research idea, implements it, and compares it against existing baselines is entirely an AI that the “scientists” will interface with.
In some areas the RE is arguably already automated. Within 2 years a lot of academic AI research engineering will be automated with the top end of tools — I’m not sure academics will have access to these top end of tools but that is a separate question. An example I would give is coming up with a new optimizer and testing it on a series of ML baselines from 100M to 10B parameters. At this time I don’t expect the models to be able to implement the newest problems the frontier labs are facing alone. I also expect academics to be fully priced out from these tools.
Within 1-3 years we’ll have tools that make existing REs unbelievably productive (80-90% automated), but there are still meaningful technical bottlenecks that are solvable but expensive. The compute increase per available user has a ceiling too. Labs will be spending $200k+ per year per employee on AI tools easily (ie the inference cost), but most consumers will be at tiers of $20k or less due to compute scarcity.
Within 3-4 years the augmented research engineers will be able to test any idea that the scientists come up with at the frontier labs, but many complex system problems will need some (maybe minimal) amount of human oversight. Examples would include modifying RL implementations for extremely long horizon tasks or wacky new ideas on continual learning. This is so far out that the type of research idea almost isn’t worth speculating on.
These long timelines are strongly based on the fact that the category of research engineering is too broad. Some parts of the RE job will be fully automated next year, and more the next. To check the box of automation the entire role needs to be replaced. What is more likely over the next few years, each engineer is doing way more work and the job description evolves substantially. I make this callout on full automation because it is required for the distribution of outcomes that look like a singularity due to the need to remove the human bottleneck for an ever accelerating pace of progress. This is a point to reinforce that I am currently confident in a singularity not happening.
Up-skilling employees as their roles become irrelevant creates a very different dynamic. The sustained progress on code performance over the next few years will create a constant feeling of change across the technology industry. The range of performance in software is very high and it is possible to perceive relatively small incremental improvements.
These are very complex positions to hold, so they’re not that useful as rhetorical devices. Code is on track to being solved, but the compute limits and ever increasing complexity of codebases and projects (ie. LLMs) is going to make the dynamic very different than the succinct assumptions of AI 2027.
To reiterate, the most important part of automation in the discussion is often neglected. To automate someone you need to outcompete the pairing of a human with the tool too.
Onto the even trickier argument in the AI 2027 standard — automating AI research altogether. At the same time as the first examples of AI systems writing accepted papers at notable AI venues, I’m going to be here arguing that full automation of AI research isn’t coming anytime soon. It’s daunting to try and hold (and explain) this position, and it relies on all the messy firsthand knowledge of science that I have and how it is different in academia versus frontier AI labs.
For one, the level and type of execution at frontier labs relative to academic research is extremely different. Academia also has a dramatically higher variance in quality of work that is accepted within the community. For this reason, we’re going to be seeing incredible disruption at standard academic venues in the very near future, but the nature of science at frontier labs will remain heavily intertwined with human personalities.
Models will be good at some types of science, such as taking two existing fields and merging ideas and seeing what happens, but awful at what I consider to be the most idolized version of science, being immersed in the state of the art and having a brilliant insight that makes anywhere from a ripple causing small performance gain to a tsunami reshaping the field.
I don’t think AI will fully automate our current notion of an AI researcher in the next 5-10 years, but it could reshape what science means altogether and make that role far less relevant to progress.
The researchers grinding out new datasets at frontier labs will have dramatic help on data processing scripts. The researchers coming up with new algorithmic ideas will not expand the rate at which they come up with ideas too much, but their ability to test them is far higher.
A large part of science is a social marketplace of ideas. Convincing your colleagues that you are right and to help you double down on it is not going to change in its core nature. Everyone will have superpowers on making evidence to support their claims, but the relative power there stays the same.
At a dinner during The Curve I went through a lot of these points with Ryan Greenblatt, Chief Scientist at Redwood Research, and a point he made stuck with me. He summarized my points as thinking the increase in performance from these largely engineering tooling improvements will be equalled out by challenges of scaling compute, so the resulting progress will feel much more linear rather than exponential. A lot of our discussions on automation we agree on, with slightly different timelines, but it didn’t feel like it captured my entire point of view.
What is missing is that I expect an inherent slowdown as our AI models get more complicated. Our models today needs tools, more complex serving systems, products to wrap them, and so on. This is very different than the age when just model weights were needed for the cutting edge of AI. There’s an inevitable curse of complexity, a death by a thousand cuts, that is going to add on top of the obvious compute costs to slow down progress.
2026 will be a big year on the compute rollout front, and shipping meaningful improvements to users will be essential to funding the progress that comes after. I’m not sure the economy can keep shifting even more of its weight behind AI progress, where most people bought into fast timelines think of it as a default position. Peter Wildeford wrote a summary of the situation that I resonate with:
Here’s how I think the AI buildout will go down.
Currently the world doesn’t have any operational 1GW+ data centers. However, it is very likely we will see fully operational 1GW data centers before mid-2026. This likely will be a part of 45-60GW of total compute across Meta, Microsoft, Amazon/AWS/Anthropic, OpenAI/Oracle, Google/DeepMind, and xAI.
My median expectation is these largest ~1GW data center facilities will hold ~400,000-500,000 Nvidia Blackwell chips and be used to train ~4e27 FLOP model sometime before the end of 2027. Such a model would be 10x larger than the largest model today and 100x larger than GPT-4. Each individual 1GW facility would cost ~$40B to manufacture, with ~$350B total industry spend across 2026.
He continues with estimates for 2028, and saying he’s fuzzy on 2029, but my fuzziness cuts in a bit earlier depending on adoption and performance across the AI industry.
Where I feel like in the long run it’ll look like a very consistent pace of progress, that feels like a bunch of big jumps and periods of stagnation in the short-term. I have fairly large error bars on how the price of intelligence — and therefore adoption — is going to evolve over the next 2-4 years, with it obviously becoming far cheaper over the following decades.
As for my recent articles on timelines and key debates in the field, I encourage people to comment and dig in on what I wrote below.
Other thoughts
Something crazy about this conference is no one is talking about how the models actually work or are trained, and everyone here is totally convinced that AGI is coming soon.
One of my new friends at the conference described this tendency as “an obsession with the problem.” This is a feeling that many AI obsessors are more interested in where the technology is going rather than how or what exactly it is going to be. gave a great talk at The Curve related to this, arguing how the current and future jaggedness of AI — the fact that similarly difficult tasks when assigned to a human will either be easily mastered by AI or barely showing any competence (her will appear later on her great Substack). It is the idea that AI capabilities evolve highly randomly across potentially similar tasks.
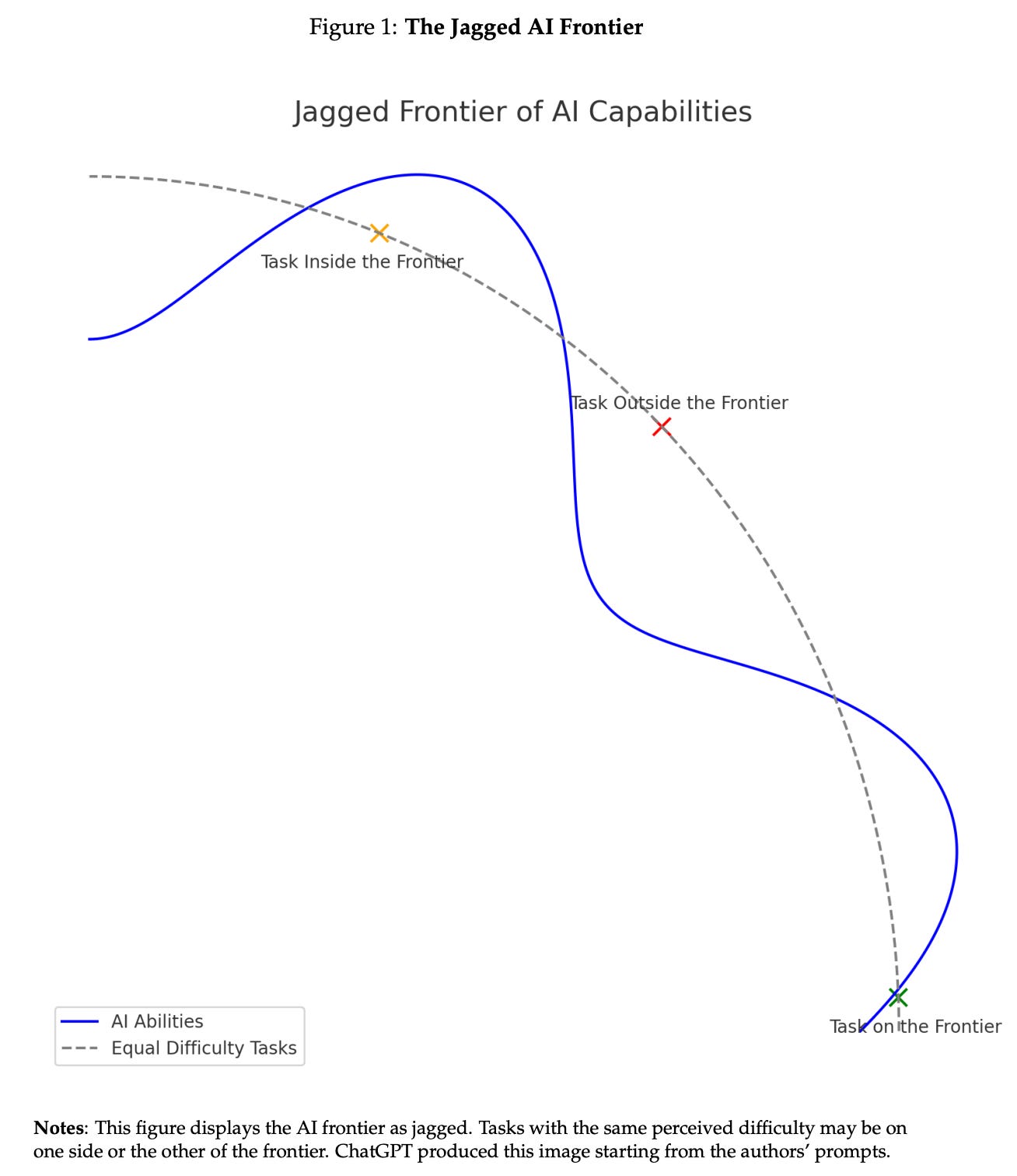
This original figure on jaggedness comes from work with the popular AI Substacker Ethan Mollick.
The relation of Helen’s talk is that she gets many forms of arguments that only the endpoint of AI matters, but that doesn’t account for the messiness of the trajectory and how unsettling that could be for the world.
I agree with Helen.
One of the things that I am confident will exist in about two years is a Sora 2 style model that can run on a MacBook without copyright, personal opt-in, or other safety filters. On this, Epoch AI has a wonderful plot showing that local models lag behind in capabilities by a fixed amount of time:
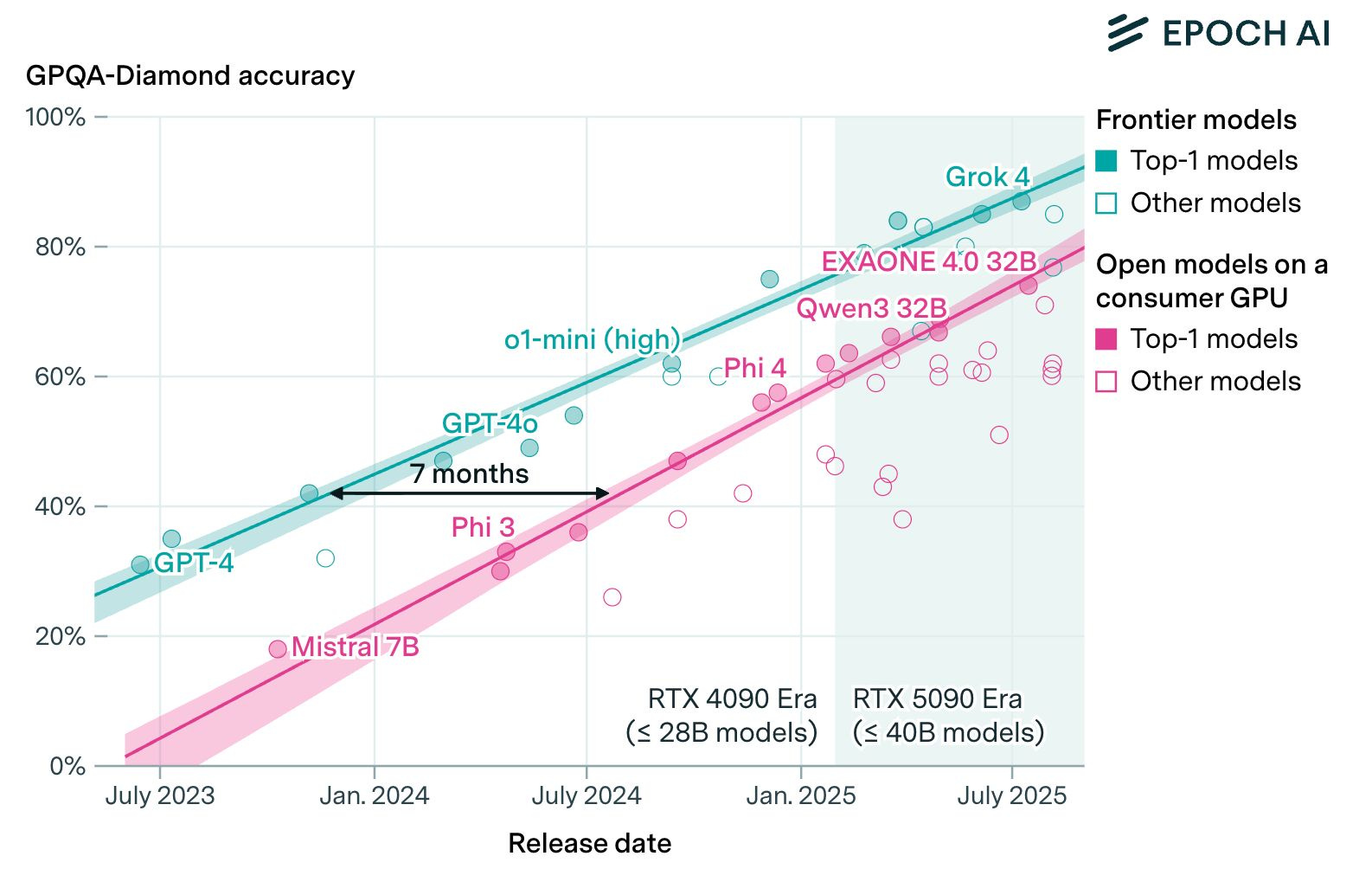
With trends like this, it is so obvious that we need to stay on the front foot of open models and not reacting to international parties that are far harder to predict and engage with. This is where I get renewed motivation for American DeepSeek / The ATOM Project. For example, I still get many adamant questions that we should consider banning open models altogether. The state of discourse, study, investment, and everything in between on open models in the U.S. is still in a quite underdeveloped state.
China’s rise in open models was something I expected to be a bigger topic at the conference, but it seemed like it was too orthogonal to the overall pace of progress to be front of mind. There were many discussions of the Chinese chip ecosystem, but less on what it enables. Not focusing on this could have costly geopolitical consequences as we cede ownership of a global standard to China. This was a large theme of my talk. The recording will be posted here soon and the slides for my talk are here (credit for Florian Brand who helps me with open model analysis here for feedback on the slides). Otherwise:
These messages are very important and I will work to spend a bit more time engaging with the communities they touch and mastering this type of talk (and analysis)
More people should work in the area, it’s crazy it has just fallen on me where it is my side hustle.
For now, I’m just landing at the conference on language modeling (COLM) in Montreal, so I may have some technical hot takes to share later this week!
