

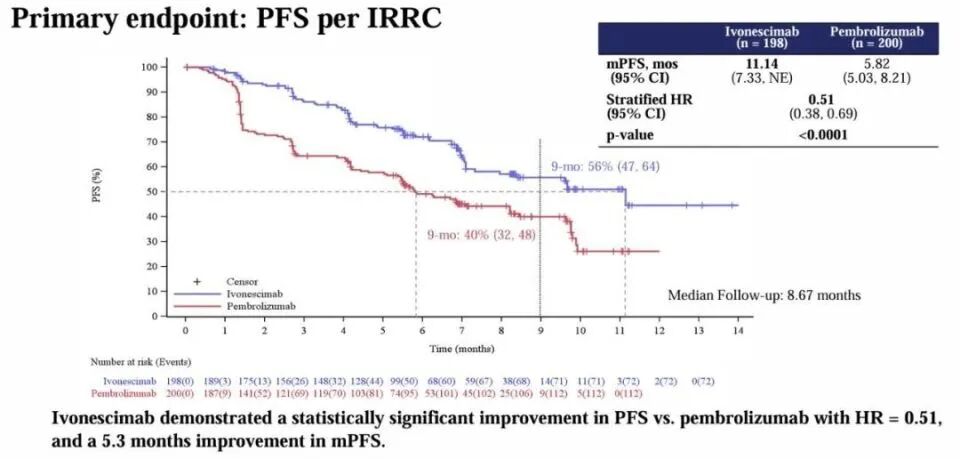
HARMONi-2试验(AK112-303;NCT05499390)的主要分析结果,对于PD-L1阳性晚期NSCLC患者,与帕博利珠单抗相比,依沃西单抗一线治疗可使疾病进展或死亡风险降低49%。依沃西单抗是一种针对PD-1和VEGF的新型双特异性抗体,前期已被证明在该人群中具有临床获益和安全性(1b/2期HARMONi-5试验)。
HARMONi-2试验纳入ECOG体能状态(PS)评分为0或1、PD-L1 TPS≥1%的IIIB至IV期晚期NSCLC患者,排除接受过系统性治疗、EGFR突变或ALK重排的患者。研究将398名患者按1:1的比例随机分配接受依沃西单抗(20mg/kg,每3周一次[Q3W])或帕博利珠单抗(200mg,Q3W)治疗。治疗持续长达24个月或临床获益丧失或毒性不可接受。患者按临床分期(IIIB/C vs. IV期)、组织学类型(鳞状vs非鳞状)和PD-L1 TPS(≥50% vs. 1%-49%)分层。研究的主要终点是按照RECIST 1.1标准通过盲法IRRC确定的PFS。次要终点包括总生存(OS)、研究者评估的PFS、ORR、缓解持续时间(DOR)、至缓解时间(TTR)和安全性。生活质量作为探索性终点。
对于这样一个实验,我们先看专家如何来评价。
1.对照组选择的合理性:对于PD-L1低表达(TPS 1-49%)患者,国际指南推荐免疫治疗联合化疗,而非单药免疫治疗(如Pembrolizumab)。本研究对照组仅使用Pembrolizumab单药,可能未反映当前临床实践的最优选择,导致结果的外部有效性受限。
分析:对于阳性对照而言,这个试验使用的单药,而非一线治疗。所以只能评价针对非化疗的患者中,KA112优于K药,而无法证明KA112联合化疗优于K药联合化疗。背景知识是阳性对照首先应使用指南中的一线疗法,如果不使用一线疗法,需要考虑外部结果受限。所以AI需要了解针对相应适应症的所有一线疗法类型。
2. 分层因素的潜在偏倚:分层因素包括组织学类型、临床分期和PD-L1表达,但未明确说明是否平衡了其他潜在混杂因素(如肝转移、脑转移比例),可能影响结果的解释。
分析:仅仅描述biomarker的表达情况,但没有提及基线转移的情况,可能存在更多的变量而影响结果。背景知识是对于转移情况的判定,需要统一考虑在基线分析中。
3. PFS的临床意义:中位PFS差异(11.1 vs 5.8个月)虽具有统计学意义,但需结合OS数据判断临床价值。目前OS数据尚未成熟,无法确认生存获益。
分析:这是一个常见情况,需要继续试验观察。背景知识是需要直接获得金标准OS的数据结论,也就是AI应该知道哪些指标的真正的金标准。
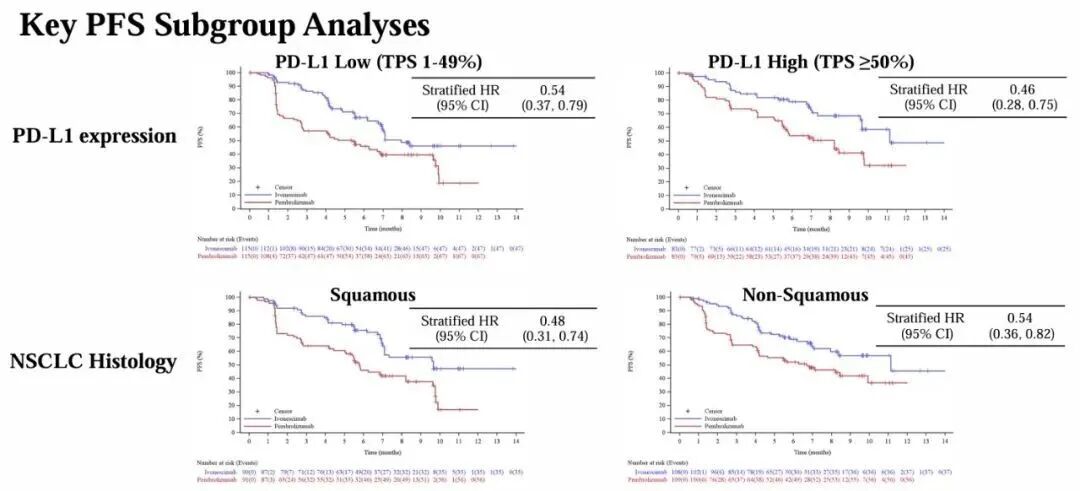
4. 亚组分析的多重性:亚组分析未校正多重比较(如PD-L1高/低表达、鳞癌/非鳞癌等),可能增加假阳性风险。例如,PD-L1高表达亚组HR=0.48的结论需谨慎解读。
分析:对于而成二交叉变量,需要分布列举确定不同变量组合的指标。背景知识是对于亚组分析时,需要根据不同变量确定风险比。
欢迎关注《医药大模型》图书,共同讨论大语言模型在医药行业的发展。有不同意见欢迎到群众交流。

内容中包含的图片若涉及版权问题,请及时与我们联系删除
