
TL;DR: “Context engineering” means providing an AI (like an LLM) with all the information and tools it needs to successfully complete a task – not just a cleverly worded prompt. It’s the evolution of prompt engineering, reflecting a broader, more system-level approach.
Context engineering tips:
To get the best results from an AI, you need to provide clear and specific context. The quality of the AI's output directly depends on the quality of your input.
How to improve your AI prompts
Be precise: Vague requests lead to vague answers. The more specific you are, the better your results will be.
Provide relevant code: Share the specific files, folders, or code snippets that are central to your request.
Include design documents: Paste or attach sections from relevant design docs to give the AI the bigger picture.
Share full error logs: For debugging, always provide the complete error message and any relevant logs or stack traces.
Show database schemas: When working with databases, a screenshot of the schema helps the AI generate accurate code for data interaction.
Use PR feedback: Comments from a pull request make for context-rich prompts.
Give examples: Show an example of what you want the final output to look like.
State your constraints: Clearly list any requirements, such as libraries to use, patterns to follow, or things to avoid.
From “Prompt Engineering” to “Context Engineering”
Prompt engineering was about cleverly phrasing a question; context engineering is about constructing an entire information environment so the AI can solve the problem reliably.
“Prompt engineering” became a buzzword essentially meaning the skill of phrasing inputs to get better outputs. It taught us to “program in prose” with clever one-liners. But outside the AI community, many took prompt engineering to mean just typing fancy requests into a chatbot. The term never fully conveyed the real sophistication involved in using LLMs effectively.
As applications grew more complex, the limitations of focusing only on a single prompt became obvious. One analysis quipped: Prompt engineering walked so context engineering could run. In other words, a witty one-off prompt might have wowed us in demos, but building reliable, industrial-strength LLM systems demanded something more comprehensive.
This realization is why our field is coalescing around “context engineering” as a better descriptor for the craft of getting great results from AI. Context engineering means constructing the entire context window an LLM sees – not just a short instruction, but all the relevant background info, examples, and guidance needed for the task.
The phrase was popularized by developers like Shopify’s CEO Tobi Lütke and AI leader Andrej Karpathy in mid-2025.
“I really like the term ‘context engineering’ over prompt engineering,” wrote Tobi. “It describes the core skill better: the art of providing all the context for the task to be plausibly solvable by the LLM.” Karpathy emphatically agreed, noting that people associate prompts with short instructions, whereas in every serious LLM application, context engineering is the delicate art and science of filling the context window with just the right information for each step.
In other words, real-world LLM apps don’t succeed by luck or one-shot prompts – they succeed by carefully assembling context around the model’s queries.
The change in terminology reflects an evolution in approach. If prompt engineering was about coming up with a magical sentence, context engineering is about writing the full screenplay for the AI. It’s a structural shift: prompt engineering ends once you craft a good prompt, whereas context engineering begins with designing whole systems that bring in memory, knowledge, tools, and data in an organized way.
As Karpathy explained, doing this well involves everything from clear task instructions and explanations, to providing few-shot examples, retrieved facts (RAG), possibly multimodal data, relevant tools, state history, and careful compacting of all that into a limited window. Too little context (or the wrong kind) and the model will lack the information to perform optimally; too much irrelevant context and you waste tokens or even degrade performance. The sweet spot is non-trivial to find. No wonder Karpathy calls it both a science and an art.
The term context engineering is catching on because it intuitively captures what we actually do when building LLM solutions. “Prompt” sounds like a single short query; “context” implies a richer information state we prepare for the AI.
Semantics aside, why does this shift matter? Because it marks a maturing of our mindset for AI development. We’ve learned that generative AI in production is less like casting a single magic spell and more like engineering an entire environment for the AI. A one-off prompt might get a cool demo, but for robust solutions you need to control what the model “knows” and “sees” at each step. It often means retrieving relevant documents, summarizing history, injecting structured data, or providing tools – whatever it takes so the model isn’t guessing in the dark. The result is we no longer think of prompts as one-off instructions we hope the AI can interpret. We think in terms of context pipelines: all the pieces of information and interaction that set the AI up for success.
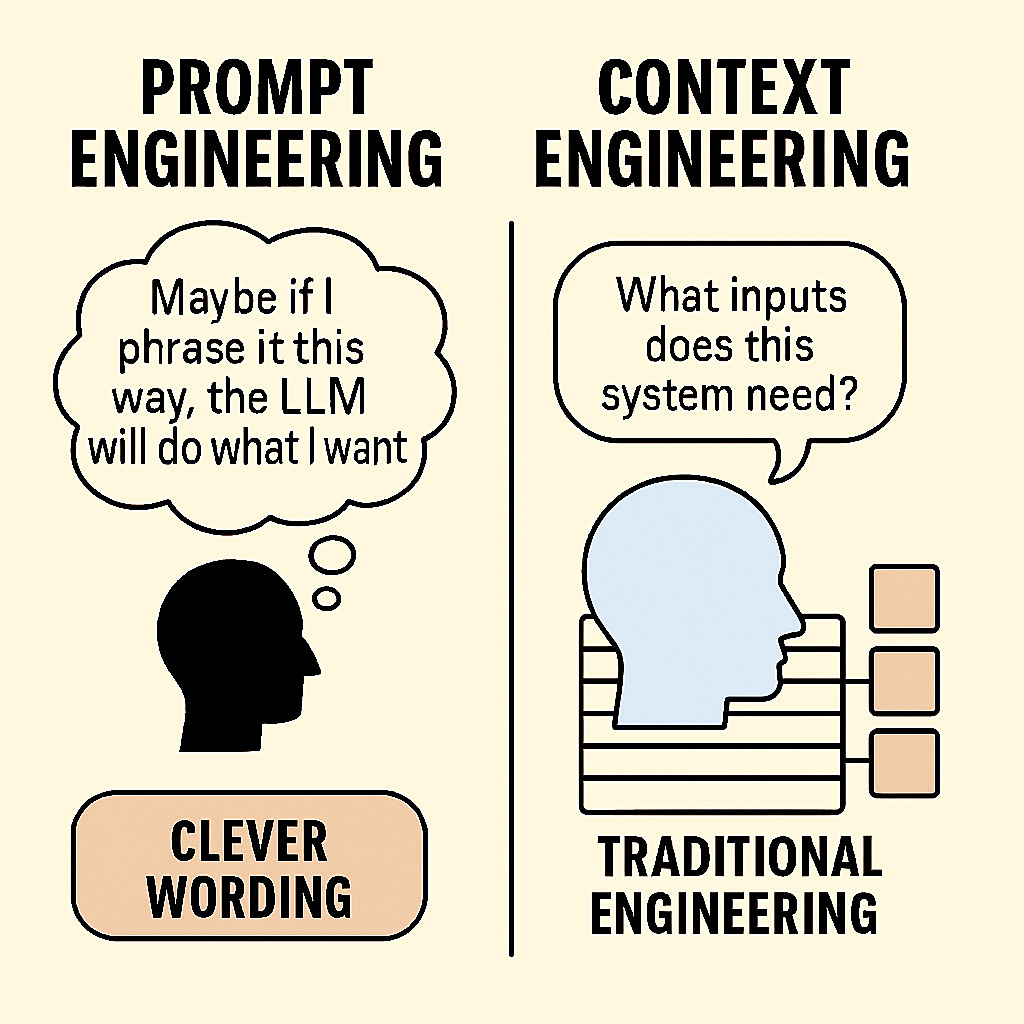
To illustrate, consider the difference in perspective. Prompt engineering was often an exercise in clever wording (“Maybe if I phrase it this way, the LLM will do what I want”). Context engineering, by contrast, feels more like traditional engineering: What inputs (data, examples, state) does this system need? How do I get those and feed them in? In what format? At what time? We’ve essentially gone from squeezing performance out of a single prompt to designing LLM-powered systems.
What Exactly Is Context Engineering?
Context engineering means dynamically giving an AI everything it needs to succeed – the instructions, data, examples, tools, and history – all packaged into the model’s input context at runtime.
A useful mental model (suggested by Andrej Karpathy and others) is to think of an LLM like a CPU, and its context window (the text input it sees at once) as the RAM or working memory. As an engineer, your job is akin to an operating system: load that working memory with just the right code and data for the task. In practice, this context can come from many sources: the user’s query, system instructions, retrieved knowledge from databases or documentation, outputs from other tools, and summaries of prior interactions. Context engineering is about orchestrating all these pieces into the prompt that the model ultimately sees. It’s not a static prompt but a dynamic assembly of information at runtime.

Illustration: multiple sources of information are composed into an LLM’s context window (its “working memory”). The context engineer’s goal is to fill that window with the right information, in the right format, so the model can accomplish the task effectively.
Let’s break down what this involves:
It’s a system, not a one-off prompt. In a well-engineered setup, the final prompt the LLM sees might include several components: e.g. a role instruction written by the developer, plus the latest user query, plus relevant data fetched on the fly, plus perhaps a few examples of desired output format. All of that is woven together programmatically. For example, imagine a coding assistant AI that gets the query “How do I fix this authentication bug?” The system behind it might automatically search your codebase for related code, retrieve the relevant file snippets, and then construct a prompt like: “You are an expert coding assistant. The user is facing an authentication bug. Here are relevant code snippets: [code]. The user’s error message: [log]. Provide a fix.” Notice how that final prompt is built from multiple pieces. Context engineering is the logic that decides which pieces to pull in and how to join them. It’s akin to writing a function that prepares arguments for another function call – except here the “arguments” are bits of context and the function is the LLM invocation.
It’s dynamic and situation-specific. Unlike a single hard-coded prompt, context assembly happens per request. The system might include different info depending on the query or the conversation state. If it’s a multi-turn conversation, you might include a summary of the conversation so far, rather than the full transcript, to save space (and sanity). If the user’s question references some document (“What does the design spec say about X?”), the system might fetch that spec from a wiki and include the relevant excerpt. In short, context engineering logic responds to the current state – much like how a program’s behavior depends on input. This dynamic nature is crucial. You wouldn’t feed a translation model the exact same prompt for every sentence you translate; you’d feed it the new sentence each time. Similarly, in an AI agent, you’re constantly updating what context you give as the state evolves.
It blends multiple types of content. LangChain describes context engineering as an umbrella that covers at least three facets of context: (1) Instructional context – the prompts or guidance we provide (including system role instructions and few-shot examples), (2) Knowledge context – domain information or facts we supply, often via retrieval from external sources, and (3) Tools context – information coming from the model’s environment via tools or API calls (e.g. results from a web search, database query, or code execution). A robust LLM application often needs all three: clear instructions about the task, relevant knowledge plugged in, and possibly the ability for the model to use tools and then incorporate the tool results back into its thinking. Context engineering is the discipline of managing all these streams of information and merging them coherently.
Format and clarity matter. It’s not just what you include in the context, but how you present it. Communicating with an AI model has surprising parallels to communicating with a human: if you dump a huge blob of unstructured text, the model might get confused or miss the point, whereas a well-organized input will guide it. Part of context engineering is figuring out how to compress and structure information so the model grasps what’s important. This could mean summarizing long texts, using bullet points or headings to highlight key facts, or even formatting data as JSON or pseudo-code if that helps the model parse it. For instance, if you retrieved a document snippet, you might preface it with something like “Relevant documentation:” and put it in quotes, so the model knows it’s reference material. If you have an error log, you might show only the last 5 lines rather than 100 lines of stack trace. Effective context engineering often involves creative information design – making the input as digestible as possible for the LLM.
Above all, context engineering is about setting the AI up for success.
Remember, an LLM is powerful but not psychic – it can only base its answers on what’s in its input plus what it learned during training. If it fails or hallucinates, often the root cause is that we didn’t give it the right context, or we gave it poorly structured context. When an LLM “agent” misbehaves, usually “the appropriate context, instructions and tools have not been communicated to the model.” Garbage in, garbage out. Conversely, if you do supply all the relevant info and clear guidance, the model’s performance improves dramatically.
Feeding high-quality context: practical tips
Now, concretely, how do we ensure we’re giving the AI everything it needs? Here are some pragmatic tips that I’ve found useful when building AI coding assistants and other LLM apps:
Include relevant source code and data. If you’re asking an AI to work on code, provide the relevant code files or snippets. Don’t assume the model will recall a function from memory – show it the actual code. Similarly, for Q&A tasks include the pertinent facts or documents (via retrieval). Low context guarantees low-quality output. The model can’t answer what it hasn’t been given.
Be precise in instructions. Clearly state what you want. If you need the answer in a certain format (JSON, specific style, etc.), mention that. If the AI is writing code, specify constraints like which libraries or patterns to use (or avoid). Ambiguity in your request can lead to meandering answers.
Provide examples of the desired output. Few-shot examples are powerful. If you want a function documented in a certain style, show one or two examples of properly documented functions in the prompt. Modeling the output helps the LLM understand exactly what you’re looking for.
Leverage external knowledge. If the task needs domain knowledge beyond the model’s training (e.g. company-specific details, API specs), retrieve that info and put it in the context. For instance, attach the relevant section of a design doc or a snippet of the API documentation. LLMs are far more accurate when they can cite facts from provided text rather than recalling from memory.
Include error messages and logs when debugging. If asking the AI to fix a bug, show it the full error trace or log snippet. These often contain the critical clue needed. Similarly, include any test outputs if asking why a test failed.
Maintain conversation history (smartly). In a chat scenario, feed back important bits of the conversation so far. Often you don’t need the entire history – a concise summary of key points or decisions can suffice and saves token space. This gives the model context of what’s already been discussed.
Don’t shy away from metadata and structure. Sometimes telling the model why you’re giving a piece of context can help. For example: “Here is the user’s query.” or “Here are relevant database schemas:” as prefacing labels. Simple section headers like “User Input: … / Assistant Response: …” help the model parse multi-part prompts. Use formatting (markdown, bullet lists, numbered steps) to make the prompt logically clear.
Remember the golden rule: LLMs are powerful but they aren’t mind-readers. The quality of output is directly proportional to the quality and relevance of the context you provide. Too little context (or missing pieces) and the AI will fill gaps with guesses (often incorrect). Irrelevant or noisy context can be just as bad, leading the model down the wrong path. So our job as context engineers is to feed the model exactly what it needs and nothing it doesn’t.
Addressing the skeptics
Let's be direct about the criticisms. Many experienced developers see "context engineering" as either rebranded prompt engineering or, worse, pseudoscientific buzzword creation. These concerns aren't unfounded. Traditional prompt engineering focuses on the instructions you give an LLM. Context engineering encompasses the entire information ecosystem: dynamic data retrieval, memory management, tool orchestration, and state maintenance across multi-turn interactions. Much of current AI work lacks the rigor we expect from engineering disciplines. There's too much trial-and-error, not enough measurement, and insufficient systematic methodology. Let's be honest: even with perfect context engineering, LLMs still hallucinate, make logical errors, and fail at complex reasoning. Context engineering isn't a silver bullet - it's damage control and optimization within current constraints.
The Art and Science of effective context
Great context engineering strikes a balance – include everything the model truly needs, but avoid irrelevant or excessive detail that could distract it (and drive up cost).
As Karpathy described, context engineering is a delicate mix of science and art.
The “science” part involves following certain principles and techniques to systematically improve performance. For example: if you’re doing code generation, it’s almost scientific that you should include relevant code and error messages; if you’re doing question-answering, it’s logical to retrieve supporting documents and provide them to the model. There are established methods like few-shot prompting, retrieval-augmented generation (RAG), and chain-of-thought prompting that we know (from research and trial) can boost results. There’s also a science to respecting the model’s constraints – every model has a context length limit, and overstuffing that window can not only increase latency/cost but potentially degrade the quality if the important pieces get lost in the noise.
Karpathy summed it up well: “Too little or of the wrong form and the LLM doesn’t have the right context for optimal performance. Too much or too irrelevant and the LLM costs might go up and performance might come down.”.
So the science is in techniques for selecting, pruning, and formatting context optimally. For instance, using embeddings to find the most relevant docs to include (so you’re not inserting unrelated text), or compressing long histories into summaries. Researchers have even catalogued failure modes of long contexts – things like context poisoning (where an earlier hallucination in the context leads to further errors) or context distraction (where too much extraneous detail causes the model to lose focus). Knowing these pitfalls, a good engineer will curate the context carefully.
Then there’s the “art” side – the intuition and creativity born of experience.
This is about understanding LLM quirks and subtle behaviors. Think of it like a seasoned programmer who “just knows” how to structure code for readability: an experienced context engineer develops a feel for how to structure a prompt for a given model. For example, you might sense that one model tends to do better if you first outline a solution approach before diving into specifics, so you include an initial step like “Let’s think step by step…” in the prompt. Or you notice that the model often misunderstands a particular term in your domain, so you preemptively clarify it in the context. These aren’t in a manual – you learn them by observing model outputs and iterating. This is where prompt-crafting (in the old sense) still matters, but now it’s in service of the larger context. It’s similar to software design patterns: there’s science in understanding common solutions, but art in knowing when and how to apply them.
Let’s explore a few common strategies and patterns context engineers use to craft effective contexts:
Retrieval of relevant knowledge: One of the most powerful techniques is Retrieval-Augmented Generation. If the model needs facts or domain-specific data that isn’t guaranteed to be in its training memory, have your system fetch that info and include it. For example, if building a documentation assistant, you might vector-search your documentation and insert the top matching passages into the prompt before asking the question. This way, the model’s answer will be grounded in real data you provided, rather than its sometimes outdated internal knowledge. Key skills here include designing good search queries or embedding spaces to get the right snippet, and formatting the inserted text clearly (with citations or quotes) so the model knows to use it. When LLMs “hallucinate” facts, it’s often because we failed to provide the actual fact – retrieval is the antidote to that.
Few-shot examples and role instructions: This harkens back to classic prompt engineering. If you want the model to output something in a particular style or format, show it examples. For instance, to get structured JSON output, you might include a couple of example inputs and outputs in JSON in the prompt, then ask for a new one. Few-shot context effectively teaches the model by example. Likewise, setting a system role or persona can guide tone and behavior (“You are an expert Python developer helping a user…”). These techniques are staples because they work: they bias the model towards the patterns you want. In the context-engineering mindset, prompt wording and examples are just one part of the context, but they remain crucial. In fact, you could say prompt engineering (crafting instructions and examples) is now a subset of context engineering – it’s one tool in the toolkit. We still care a lot about phrasing and demonstrative examples, but we’re also doing all these other things around them.
Managing state and memory: Many applications involve multiple turns of interaction or long-running sessions. The context window isn’t infinite, so a major part of context engineering is deciding how to handle conversation history or intermediate results. A common technique is summary compression – after each few interactions, summarize them and use the summary going forward instead of the full text. For example, Anthropic’s Claude assistant automatically does this when conversations get lengthy, to avoid context overflow (you’ll see it produce a “[Summary of previous discussion]” that condenses earlier turns). Another tactic is to explicitly write important facts to an external store (a file, database, etc.) and then later retrieve them when needed rather than carrying them in every prompt. This is like an external memory. Some advanced agent frameworks even let the LLM generate “notes to self” that get stored and can be recalled in future steps. The art here is figuring out what to keep, when to summarize, and how to resurface past info at the right moment. Done well, it lets an AI maintain coherence over very long tasks – something that pure prompting would struggle with.
Tool use and environmental context: Modern AI agents can use tools (e.g. calling APIs, running code, web browsing) as part of their operation. When they do, each tool’s output becomes new context for the next model call. Context engineering in this scenario means instructing the model when and how to use tools and then feeding the results back in. For example, an agent might have a rule: “If the user asks a math question, call the calculator tool.” After using it, the result (say 42) is inserted into the prompt: “Tool output: 42.” This requires formatting the tool output clearly and maybe adding a follow-up instruction like “Given this result, now answer the user’s question.” A lot of work in agent frameworks (LangChain, etc.) is essentially context engineering around tool use – giving the model a list of available tools, syntactic guidelines for invoking them, and templating how to incorporate results. The key is that you, the engineer, orchestrate this dialogue between the model and the external world.
Information formatting and packaging: We’ve touched on this, but it deserves emphasis. Often you have more info than fits or is useful to include fully. So you compress or format it. If your model is writing code and you have a large codebase, you might include just function signatures or docstrings rather than entire files, to give it context. If the user query is verbose, you might highlight the main question at the end to focus the model. Use headings, code blocks, tables – whatever structure best communicates the data. For example, rather than: “User data: [massive JSON]… Now answer question.” you might extract the few fields needed and present: “User’s Name: X, Account Created: Y, Last Login: Z.” This is both easier for the model to parse and uses fewer tokens. In short, think like a UX designer, but your “user” is the LLM – design the prompt for its consumption.
The impact of these techniques is huge. When you see an impressive LLM demo solving a complex task (say, debugging code or planning a multi-step process), you can bet it wasn’t just a single clever prompt behind the scenes. There was a pipeline of context assembly enabling it.
For instance, an AI pair programmer might implement a workflow like:
Search the codebase for relevant code
Include those code snippets in the prompt with the user’s request
If the model proposes a fix, run tests in the background
If tests fail, feed the failure output back into the prompt for the model to refine its solution
Loop until tests pass.
Each step has carefully engineered context: the search results, the test outputs, etc., are each fed into the model in a controlled way. It’s a far cry from “just prompt an LLM to fix my bug” and hoping for the best.
The challenge of context rot
As we get better at assembling rich context, we run into a new problem: context can actually poison itself over time. This phenomenon, aptly termed "context rot" by developer Workaccount2 on Hacker News, describes how context quality degrades as conversations grow longer and accumulate distractions, dead ends, and low-quality information.
The pattern is frustratingly common: you start a session with a well-crafted context and clear instructions. The AI performs beautifully at first. But as the conversation continues - especially if there are false starts, debugging attempts, or exploratory rabbit holes - the context window fills with increasingly noisy information. The model's responses gradually become less accurate, more confused, or start hallucinating.

Why does this happen? Context windows aren't just storage - they're the model's working memory. When that memory gets cluttered with failed attempts, contradictory information, or tangential discussions, it's like trying to work at a desk covered in old drafts and unrelated papers. The model struggles to identify what's currently relevant versus what's historical noise. Earlier mistakes in the conversation can compound, creating a feedback loop where the model references its own poor outputs and spirals further off track.
This is especially problematic in iterative workflows - exactly the kind of complex tasks where context engineering shines. Debugging sessions, code refactoring, document editing, or research projects naturally involve false starts and course corrections. But each failed attempt leaves traces in the context that can interfere with subsequent reasoning.
Practical strategies for managing context rot include:
Context pruning and refresh: Workaccount2's solution is "I work around it by regularly making summaries of instances, and then spinning up a new instance with fresh context and feed in the summary of the previous instance." This approach preserves the essential state while discarding the noise. You're essentially doing garbage collection for your context.
Structured context boundaries: Use clear markers to separate different phases of work. For example, explicitly mark sections as "Previous attempts (for reference only)" versus "Current working context." This helps the model understand what to prioritize.
Progressive context refinement: After significant progress, consciously rebuild the context from scratch. Extract the key decisions, successful approaches, and current state, then start fresh. It's like refactoring code—occasionally you need to clean up the accumulated cruft.
Checkpoint summaries: At regular intervals, have the model summarize what's been accomplished and what the current state is. Use these summaries as seeds for fresh context when starting new sessions.
Context windowing: For very long tasks, break them into phases with natural boundaries where you can reset context. Each phase gets a clean start with only the essential carry-over from the previous phase.
This challenge also highlights why "just dump everything into the context" isn't a viable long-term strategy. Like good software architecture, good context engineering requires intentional information management - deciding not just what to include, but when to exclude, summarize, or refresh.
Context engineering in the Big Picture of LLM applications
Context engineering is crucial, but it’s just one component of a larger stack needed to build full-fledged LLM applications – alongside things like control flow, model orchestration, tool integration, and guardrails.
In Karpathy’s words, context engineering is “one small piece of an emerging thick layer of non-trivial software” that powers real LLM apps. So while we’ve focused on how to craft good context, it’s important to see where that fits in the overall architecture.
A production-grade LLM system typically has to handle many concerns beyond just prompting, for example:
Problem decomposition and control flow: Instead of treating a user query as one monolithic prompt, robust systems often break the problem down into sub-tasks or multi-step workflows. For instance, an AI agent might first be prompted to outline a plan, then in subsequent steps be prompted to execute each step. Designing this flow (which prompts to call in what order, how to decide branching or looping) is a classic programming task – except the “functions” are LLM calls with context. Context engineering fits here by making sure each step’s prompt has the info it needs, but the decision to have steps at all is a higher-level design. This is why you see frameworks where you essentially write a script that coordinates multiple LLM calls and tool uses.
Model selection and routing: You might use different AI models for different jobs. Perhaps a lightweight model for simple tasks or preliminary answers, and a heavyweight model for final solutions. Or a code-specialized model for coding tasks versus a general model for conversational tasks. The system needs logic to route requests to the appropriate model. Each model might have different context length limits or formatting requirements, which the context engineering must account for (e.g. truncating context more aggressively for a smaller model). This aspect is more engineering than prompting: think of it as matching the tool to the job.
Tool integrations and external actions: If your AI can perform actions (like calling an API, database queries, opening a web page, running code), your software needs to manage those capabilities. That includes providing the AI with a list of available tools and instructions on usage, as well as actually executing those tool calls and capturing the results. As we discussed, the results then become new context for further model calls. Architecturally, this means your app often has a loop: prompt model -> if model output indicates a tool to use -> execute tool -> incorporate result -> prompt model again. Designing that loop reliably is a challenge.
User interaction and UX flows: Many LLM applications involve the user in the loop. For example, a coding assistant might propose changes and then ask the user to confirm applying them. Or a writing assistant might offer a few draft options for the user to pick from. These UX decisions affect context, too. If the user says “Option 2 looks good but shorten it,” you need to carry that feedback into the next prompt (e.g. “The user chose draft 2 and asks to shorten it.”). Designing a smooth human-AI interaction flow is part of the app, though not directly about prompts. Still, context engineering supports it by ensuring each turn’s prompt accurately reflects the state of the interaction (like remembering which option was chosen, or what the user edited manually).
Guardrails and safety: In production, you have to consider misuse and errors. This might include content filters (to prevent toxic or sensitive outputs), authentication and permission checks for tools (so the AI doesn’t, say, delete a database because it was in the instructions), and validation of outputs. Some setups use a second model or rules to double-check the first model’s output. For example, after the main model generates an answer, you might run another check: “Does this answer contain any sensitive info? If so, redact it.” Those checks themselves can be implemented as prompts or as code. In either case, they often add additional instructions into the context (like a system message: “If the user asks for disallowed content, refuse.” is part of many deployed prompts). So the context might always include some safety boilerplate. Balancing that (ensuring the model follows policy without compromising helpfulness) is yet another piece of the puzzle.
Evaluation and monitoring: Suffice to say, you need to constantly monitor how the AI is performing. Logging every request and response (with user consent and privacy in mind) allows you to analyze failures and outliers. You might incorporate real-time evals – e.g., scoring the model’s answers on certain criteria and if the score is low, automatically having the model try again or route to a human fallback. While evaluation isn’t part of generating a single prompt’s content, it feeds back into improving prompts and context strategies over time. Essentially, you treat the prompt and context assembly as something that can be debugged and optimized using data from production.
We’re really talking about a new kind of application architecture. It’s one where the core logic involves managing information (context) and adapting it through a series of AI interactions, rather than just running deterministic functions. Karpathy listed elements like control flows, model dispatch, memory management, tool use, verification steps, etc., on top of context filling. All together, they form what he jokingly calls “an emerging thick layer” for AI apps – thick because it’s doing a lot! When we build these systems, we’re essentially writing meta-programs: programs that choreograph another “program” (the AI’s output) to solve a task.
For us software engineers, this is both exciting and challenging. It’s exciting because it opens capabilities we didn’t have – e.g., building an assistant that can handle natural language, code, and external actions seamlessly. It’s challenging because many of the techniques are new and still in flux. We have to think about things like prompt versioning, AI reliability, and ethical output filtering, which weren’t standard parts of app development before. In this context, context engineering lies at the heart of the system: if you can’t get the right information into the model at the right time, nothing else will save your app. But as we see, even perfect context alone isn’t enough; you need all the supporting structure around it.
The takeaway is that we’re moving from prompt design to system design. Context engineering is a core part of that system design, but it lives alongside many other components.
Conclusion
Key takeaway: By mastering the assembly of complete context (and coupling it with solid testing), we can increase the changes of getting the best output from AI models.
For experienced engineers, much of this paradigm is familiar at its core – it’s about good software practices – but applied in a new domain. Think about it:
We always knew garbage in, garbage out. Now that principle manifests as “bad context in, bad answer out.” So we put more work into ensuring quality input (context) rather than hoping the model will figure it out.
We value modularity and abstraction in code. Now we’re effectively abstracting tasks to a high level (describe the task, give examples, let AI implement) and building modular pipelines of AI + tools. We’re orchestrating components (some deterministic, some AI) rather than writing all logic ourselves.
We practice testing and iteration in traditional dev. Now we’re applying the same rigor to AI behaviors, writing evals and refining prompts as one would refine code after profiling.
In embracing context engineering, you’re essentially saying: I, the developer, am responsible for what the AI does. It’s not a mysterious oracle; it’s a component I need to configure and drive with the right data and rules.
This mindset shift is empowering. It means we don’t have to treat the AI as unpredictable magic – we can tame it with solid engineering techniques (plus a bit of creative prompt artistry).
Practically, how can you adopt this context-centric approach in your work?
Invest in data and knowledge pipelines. A big part of context engineering is having the data to inject. So, build that vector search index of your documentation, or set up that database query that your agent can use. Treat knowledge sources as first-class citizens in development. For example, if your AI assistant is for coding, make sure it can pull in code from the repo or reference the style guide. A lot of the value you’ll get from an AI comes from the external knowledge you supply to it.
Develop prompt templates and libraries. Rather than ad-hoc prompts, start creating structured templates for your needs. You might have a template for “answer with citation” or “generate code diff given error”. These become like functions you reuse. Keep them in version control. Document their expected behavior. This is how you build up a toolkit of proven context setups. Over time, your team can share and iterate on these, just as they would on shared code libraries.
Use tools and frameworks that give you control. Avoid black-box “just give us a prompt, we do the rest” solutions if you need reliability. Opt for frameworks that let you peek under the hood and tweak things – whether that’s a lower-level library like LangChain or a custom orchestration you build. The more visibility and control you have over context assembly, the easier to debug when something goes wrong.
Monitor and instrument everything. In production, log the inputs and outputs (within privacy limits) so you can later analyze them. Use observability tools (like LangSmith, etc.) to trace how context was built for each request. When an output is bad, trace back and see what the model saw – was something missing? Was something formatted poorly? This will guide your fixes. Essentially, treat your AI system as a somewhat unpredictable service that you need to monitor like any other – dashboards for prompt usage, success rates, etc.
Keep the user in the loop. Context engineering isn’t just about machine-machine info; it’s ultimately about solving a user’s problem. Often, the user can provide context if asked the right way. Think about UX designs where the AI asks clarifying questions or where the user can provide extra details to refine the context (like attaching a file, or selecting which codebase section is relevant). The term “AI-assisted” goes both ways – AI assists user, but user can assist AI by supplying context. A well-designed system facilitates that. For example, if an AI answer is wrong, let the user correct it and feed that correction back into context for next time.
Train your team (and yourself). Make context engineering a shared discipline. In code reviews, start reviewing prompts and context logic too (“Is this retrieval grabbing the right docs? Is this prompt section clear and unambiguous?”). If you’re a tech lead, encourage team members to surface issues with AI outputs and brainstorm how tweaking context might fix it. Knowledge sharing is key because the field is new – a clever prompt trick or formatting insight one person discovers can likely benefit others. I’ve personally learned a ton just reading others’ prompt examples and post-mortems of AI failures.
As we move forward, I expect context engineering to become second nature – much like writing an API call or a SQL query is today. It will be part of the standard repertoire of software development. Already, many of us don’t think twice about doing a quick vector similarity search to grab context for a question; it’s just part of the flow. In a few years, “Have you set up the context properly?” will be as common a code review question as “Have you handled that API response properly?”.
In embracing this new paradigm, we don’t abandon the old engineering principles – we reapply them in new ways. If you’ve spent years honing your software craft, that experience is incredibly valuable now: it’s what allows you to design sensible flows, to spot edge cases, to ensure correctness. AI hasn’t made those skills obsolete; it’s amplified their importance in guiding AI. The role of the software engineer is not diminishing – it’s evolving. We’re becoming directors and editors of AI, not just writers of code. And context engineering is the technique by which we direct the AI effectively.
Start thinking in terms of what information you provide to the model, not just what question you ask. Experiment with it, iterate on it, and share your findings. By doing so, you’ll not only get better results from today’s AI, but you’ll also be preparing yourself for the even more powerful AI systems on the horizon. Those who understand how to feed the AI will always have the advantage.
Happy context-coding!
I’m excited to share I’m writing a new AI-assisted engineering book with O’Reilly. If you’ve enjoyed my writing here you may be interested in checking it out.

