Looking forward, we're entering an agentic coding era – one where autonomous AI agents could handle more significant parts of the software development lifecycle (SDLC) on our behalf, with humans being in part of the loop. In this post I'll explore how programming is evolving in this new world of CLIcoding agents, orchestrators, and backgroundAI-driven automation. I’ll touch on everything from Claude Code to AmpCode and beyond. Let's dive in.
The rise of coding agents
It helps to frame where we are coming from. Over the past couple of years, we've seen AI assistance in coding go from simple autocomplete (e.g. early Copilot) to more interactive pair-programming. These tools claim to dramatically boost individual productivity – Microsoft recently reported that over 30% of new code at the company is now AI-generated, with similar numbers at Meta and Google. This isn’t just happening in sandbox projects; it’s happening with production code running in systems used by billions. It’s clear we’ve hit an inflection point.
Tip: To improve AI coding, don’t just jump straight into tasks without planning. Planning first makes a big difference, as does including sufficient context. You can even setup custom rules for exactly how your mini-PRDs should be written.
The next leap is autonomous coding agents. Instead of just offering suggestions or one-file edits, these agents can execute high-level tasks: e.g. “Add a dark mode to my app” or “Fix all the failing tests and update outdated dependencies”. They will plan the work, modify multiple files, run tests or commands, and even produce pull requests – all with minimal human intervention beyond approval. In other words, we’re shifting from “AI as a coding assistant” to “AI as an autonomous coder”.
In just a few months, every major AI lab and tech company rolled out their take on an autonomous coding agent. Anthropic launched Claude Code, Google unveiled Gemini CLI and an async agent called Jules, OpenAI introduced a research preview of a new Codex agent, and Microsoft/GitHub announced a Copilot “autonomous agent” mode. Social media has been abuzz about a coming "rapid development" in AI coding platforms. It feels reminiscent of ChatGPT’s breakout moment – suddenly coding agents are everywhere, and developers are taking notice.
The answer many are converging on is that developers will evolve from "coders" to "conductors". We’ll spend less time grinding out boilerplate or hunting bugs, and more time orchestrating AI agents, providing high-level guidance, and verifying the results. In other words, the next level of abstraction in software engineering is here. Just as we moved from assembly to high-level languages, and from on-prem servers to cloud, we’re now moving to a world where you might “orchestrate fleets of agents, letting AI handle the implementation”. The best developers will be those who can communicate goals effectively to AIs, review and improve AI-generated code, and know when human insight must override AI output.
Tip: Having AI write tests first (e.g. TDD-style) and then the least amount of code needed to make them pass can minimize things going off the rails.
So, what does this agentic future look like in practice? Let’s explore some key categories of tools and patterns that are emerging:
AI Coding Agents in the terminal (CLI agents) – interactive command-line tools (Claude Code, Google’s Gemini CLI, OpenCode, etc.) that act as AI engineers living in your terminal. They can understand your entire codebase and perform multi-step coding tasks via a conversational interface.
Orchestrating multiple agents in parallel – tools that let you run multiple AI agents simultaneously on different tasks or parts of a project. Think of this as having an AI pair programming team at your disposal, managed via a single interface (Claude Squad, Conductor, Agent Farm, Magnet, etc.).
Asynchronous background coders – agents that run in the cloud or in the background (like Google’s Jules or OpenAI’s Codex agent), which you can assign tasks to. They work autonomously and come back with code changes or pull requests, while you continue other work.
AI-Assisted testing and CI – applying agentic AI to the adjacent stages of development: writing unit tests, detecting and fixing build failures, and automating code reviews. This includes “self-healing” CI pipelines that automatically correct failing tests, and bots that can propose fixes via PRs.
Integrated AI-First dev environments – new IDEs and platforms built around AI from the ground up (e.g. Cursor, Windsurf, Replit Ghostwriter, etc.), which blur the line between writing code and prompting an agent. These often combine aspects of the above categories into a unified experience.
Project orchestration & management – AI agents hooking into our project management tools (issues, tickets, docs) to close the loop. For example, starting from a GitHub or Linear issue and letting an AI agent implement the required code changes and update the ticket.
Along the way, I’ll also touch on challenges and open questions – like how we maintain code quality, handle AI mistakes, control costs, and ensure developers remain in the loop. Let’s start with the CLI agent revolution, since that’s been one of the most talked-about developments.
Coding with CLI agents: AI in your terminal
The terminal is the new IDE - CLI agents turn your shell into an action‑oriented interface where prompts translate into multi‑file commits and tests, collapsing traditional editor boundaries.
One striking trend is the resurgence of the command-line interface as a place for powerful developer tools – now supercharged with AI. Historically, many devs prefer the GUI of an IDE for serious coding, but the new generation of AI coding agents is making the terminal shockingly productive. I’ve personally found myself living in the terminal more, thanks to these tools.
Anthropic’s Claude Code is a prime example. It’s an “agentic coding tool that lives in your terminal and helps turn ideas into code faster”. Under the hood, Claude Code is essentially Anthropic’s Claude AI (a large language model like ChatGPT) augmented with the ability to act on your filesystem and execute commands.
You install it via npm (npm install -g @anthropic-ai/claude-code), navigate to a project directory, and just run claude. This drops you into an interactive CLI where you can have a conversation with Claude about your codebase. But unlike a chat in the browser, this agent can directly edit files, run tests, git commit changes, and more.
There’s an excellent beginners guide to Claude Code by above.
What can Claude Code do for you? Quite a lot:
Build features from descriptions – You can literally tell Claude Code what you want to build in plain English. It will break the task into steps, write or modify code across multiple files, and ensure it runs. Essentially, it handles implementation from a spec.
Debug and fix issues – If you describe a bug or paste an error, Claude Code will analyze the codebase to locate the problem and then implement a fix automatically. It’s not just suggesting a fix; it can apply it.
Navigate and answer questions about the codebase – Because it indexes your entire project (and even can fetch external info via Anthropic’s Model Context Protocol (MCP) hooks), you can ask questions like “Where is the user authentication logic defined?” or “What does this error mean in our context?”, and get answers that reference your actual code.
Automate tedious tasks – Need to do a boring refactor or cleanup? For example, “remove all deprecated API calls and update them to the new interface” – the agent can handle that. Fix lint issues, resolve merge conflicts, generate release notes, you name it.
In short, Claude Code tries to be a hands-on AI software engineer working alongside you. It not only chats, but takes action. It was important to Anthropic that this agent can follow the Unix philosophy – meaning you can script it and compose it with other tools. A fun example from their docs: you could pipe logs to it and have it monitor them, e.g. tail -f app.log | claude -p "Slack me if you see any anomalies". Another: run it in CI to automatically raise a PR if certain conditions are met (like new strings needing translation) This shows how deeply an AI agent can integrate into developer workflows beyond just writing code – it can observe and act on events.
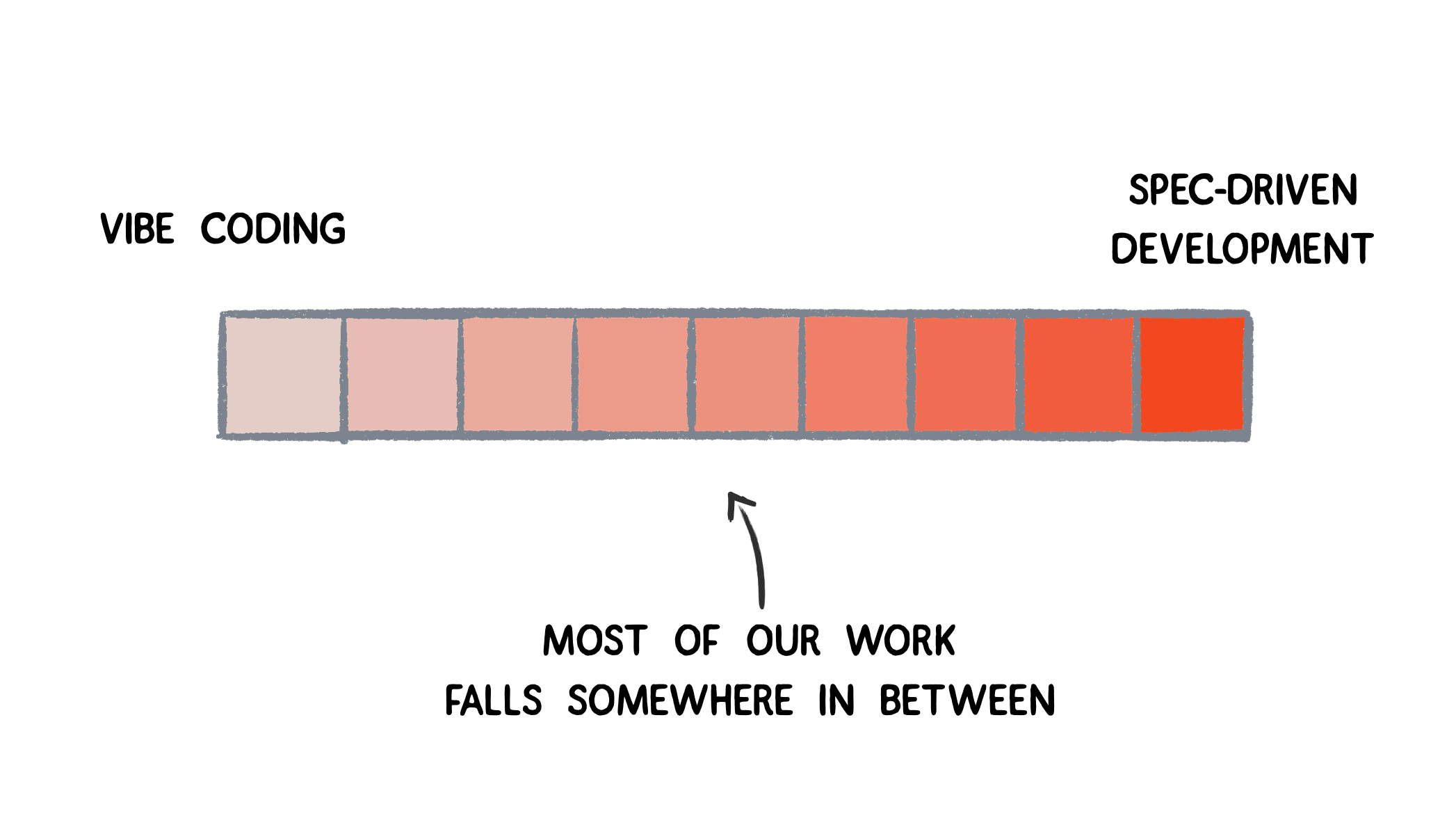
Tip: Spec-driven development is increasingly becoming common when using a CLI coding agent. This is for when you need a more structured approach with a detailed task breakdown vs. just going with the vibes via a simple prompt.
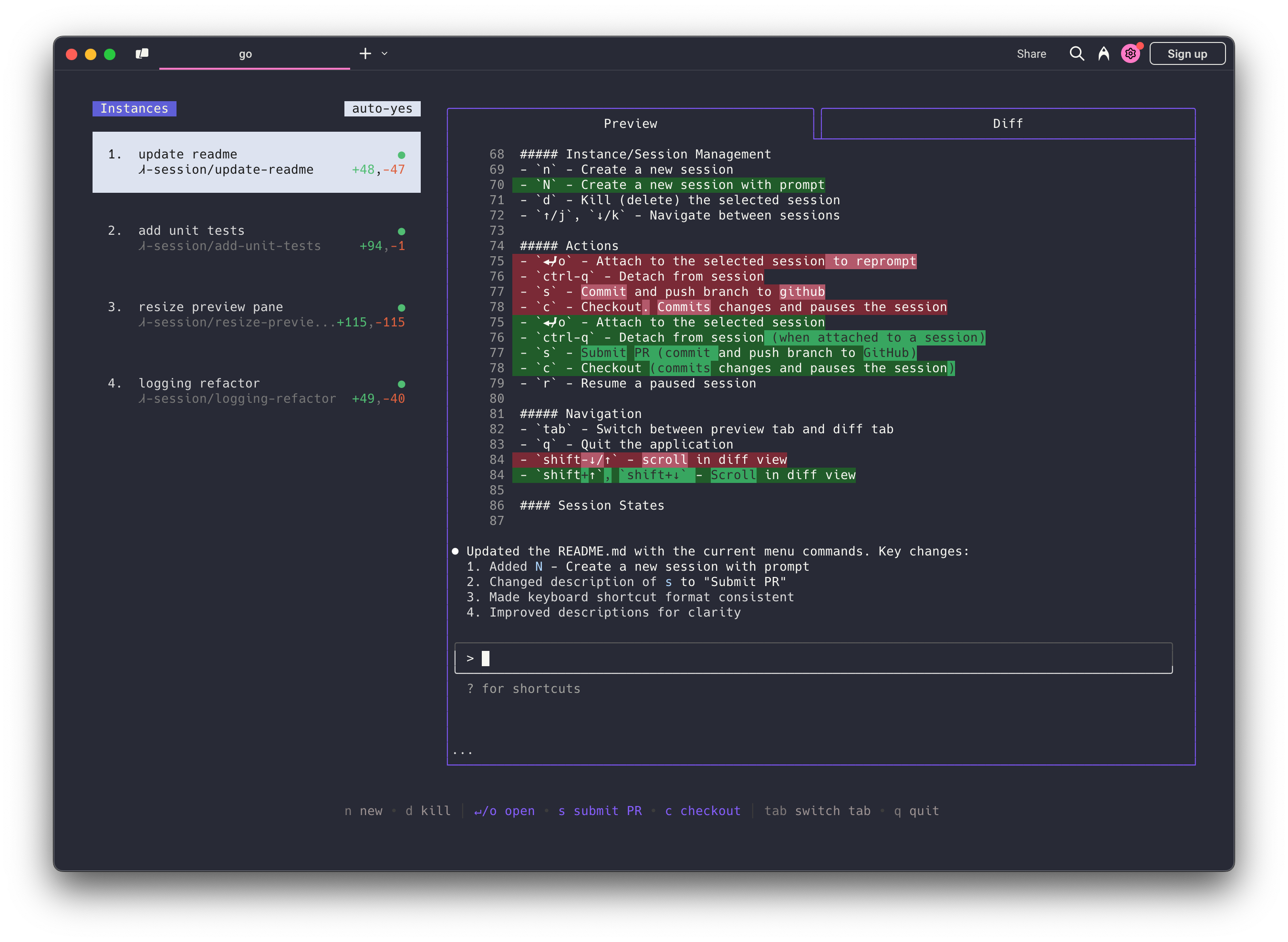
CLI agents have been evolving further lately and Claude Code just got a new feature: custom subagents. Subagents can create “teams” of custom agents, each designed to handle specialized tasks. These include architects, reviewers and testers. Each agent has it's own context and conversation history. Type `/agents` to get started:
Anthropic’s approach has resonated especially with more advanced developers who love the terminal. There’s no new editor to learn – the agent meets you where you already work. If you’re a vim + CLI person, Claude Code doesn’t force a GUI on you. And if you do prefer an IDE, they’ve made it easy to connect Claude Code to popular editors (via a local server that the IDE can talk to).
Personally, I enjoy the focus of the CLI – when I run claude in a project, I’m in a single-pane environment where the AI agent is front and center, not tucked in a small sidebar. A great description from one review: “that single terminal pane felt like a better interface… now that the agent was doing so much, I found myself saying: do I really need the file editor to be the primary focus?”. I can relate to that sentiment; when an agent is effectively handling multi-file changes, the traditional editor UI starts to feel like overhead.
Anthropic isn’t alone here. Google’s Gemini CLI is another major entrant. Announced in June 2025, Gemini CLI brings Google’s premier LLM (Gemini 2.5 Pro) right into your terminal. It’s free and open-source – you just log in with a Google account to get generous access (Google touts “unmatched free usage limits” for individuals, including a 1 million token context window for Gemini 2.5 Pro).
That context size is massive – it means the agent can theoretically take into account your entire codebase or large chunks of documentation when helping you. I and my teams have been enjoying using Gemini CLI for both work and personal projects.
Like Claude Code, Gemini CLI can do a lot more than code completion: it handles “coding, content generation, problem-solving, and task management” in the terminal. In practice, it overlaps many of Claude Code’s capabilities – editing code, answering questions, running commands, etc. Google integrated it tightly with their AI ecosystem: if you use Gemini Code Assist in VS Code, you can seamlessly move to the CLI agent and vice versa. It’s clear Google sees CLI agents as a cornerstone, not just a novelty.
gemini --sandbox is your safe playground (macOS Seatbelt, Docker and Podman support)
gemini --checkpointing = instant "undo" button with /restore
There’s a whole Gemini CLI cheat-sheet also available from Philipp Schmid, who has shared some great tips including using / commands for creating a plan based on your request and existing codebase:
There are other open-source CLI agents making waves. One noteworthy project is OpenCode CLI (by the team at SST) – a “powerful AI coding agent built for the terminal”. OpenCode is model-agnostic: you can plug in different providers (OpenAI, Anthropic, local models via Ollama, etc.) and it will use them to drive the agent.
OpenCode’s philosophy is similar: you navigate to your project and launch opencode to start an AI session in that context. It even supports a non-interactive mode (opencode run "your prompt") for quick answers or scripting usage. Being open source, developers can inspect the code and extend it – which builds trust. And because it’s not tied to a single model, you’re free to use whichever AI backend is best (or most cost-effective) for you.
What’s it like to use a CLI coding agent? In my experience, it feels like pair programming with a supercharged assistant who never gets tired. For example, I can say: “Add a new API endpoint for uploading a profile picture. Use Express and ensure the image is stored in Cloud Storage”. The agent will typically respond with a plan (e.g. “I will create a new route, a middleware for handling uploads, update the user model, and write a test for it”), then proceed to implement it step by step, asking for confirmation before running potentially destructive commands or big changes. Claude Code, for instance, asks yes/no before applying diffs or running a test suite. You remain the human in charge – but you’re delegating the heavy lifting.
Using these CLI agents effectively also requires prompting skill and a willingness to trust automation. The first few times I watched an agent refactor code, I was nervous – it was changing code faster than I could fully parse. It’s important to review diffs carefully (the tools make this easier by showing colorized diffs in the terminal and summarizing changes). Over time, I’ve grown more comfortable, especially as I see that I can always rollback a commit if needed. The CLI context actually encourages a commit-per-change workflow, which is nice (Claude Code will often commit changes with descriptive messages as it goes, so you have a history of what the AI did).
Tip: For cost savings, you can ask Claude Code or other CLI agents to use Gemini CLI to build a plan for Claude to take action on. This is useful with its 1M context window and free plan (in non-interactive mode) to research your codebase etc.
Finally, cost is a consideration. Some CLI agents are free or let you use your own API keys. When using these extensively, token usage can add up. I expect we’ll see more pricing options and competition driving costs down. For now, I treat the heavy agents like I’d treat running a cloud dev VM – immensely powerful, but remember to shut it down when not needed or consider using more cost-effective models.
The bottom line: CLI-based AI coding agents are here and surprisingly effective. They turn the humble terminal into a smart, action-oriented IDE. For many tasks, I’ve found myself preferring the CLI agent over clicking around an editor. It’s a different way of working – more conversational and higher-level. And as these tools improve (with bigger contexts, integration of web search, etc.), the gap between “describe what you want” and “get working code” is closing fast.
Toad
The technical implementation of terminal-based agents has room for improvement, as highlighted by Will McGugan's Toad project. McGugan, former CEO of Textualize and creator of the Textual framework, identified fundamental user experience issues in existing CLI agents including visual flickering, poor text selection, and interface degradation during terminal resizing. These problems stem from how current agents update terminal content by removing and rewriting entire sections rather than performing targeted updates.
Toad demonstrates an alternative architectural approach that separates the user interface layer from the AI interaction logic through a JSON-based protocol over stdin/stdout. This separation enables flicker-free updates, proper text selection capabilities, and smooth scrolling while maintaining the lightweight, keyboard-driven experience that developers expect from terminal applications. The architecture also allows for language-agnostic backend implementations, meaning the AI processing can be written in any language while the interface remains consistent.
While still in early development and available to GitHub sponsors, Toad represents an important consideration for the future of terminal-based development tools: the quality of the user interface implementation significantly impacts developer productivity and adoption, even when the underlying AI capabilities are sophisticated.
Before I get carried away letting a single agent handle everything, it’s worth noting another development: why use one agent when you can use many? That leads us to orchestrators.
From solo agent to AI team: Orchestrating multiple coding agents
Parallel agent orchestration transforms a single helper into an AI “team”. You assign boundaries, isolate via branching, and supervise a swarm - scaling development horizontally with human oversight.
If one AI coding assistant can make you twice as productive, what could five or ten working in parallel do? This question has led to the rise of agent orchestrators – tools that let you spin up multiple AI coding agents to work concurrently on a project. It’s like having an army of AI developers, each handling a piece of the work, with you as the manager overseeing them. This pattern is quickly becoming feasible on everyday developer machines.
One of the pioneers here is an open-source project called Claude Squad (by @smtg-ai). Claude Squad is a terminal app that manages multiple Claude Code (and even other agents like OpenAI Codex or Aider) sessions in parallel. The idea is simple: each agent gets its own isolated Git workspace (e.g., using git worktree or branches), so they don’t step on each other’s toes, and you can assign different tasks to each. The tool provides a unified TUI (text UI) where you can monitor all agents at once. Why do this? Because certain large tasks can be broken down.
For example, if you have a big legacy codebase to modernize, you might run one agent to upgrade the frontend framework, another to refactor the database layer, and another to add tests – all in parallel. Claude Squad lets you supervise and coordinate this within one interface, and importantly, it isolates the changes until you choose to merge them, preventing conflicts. Early users have reported massive productivity boosts, essentially multiplying their output by N agents.
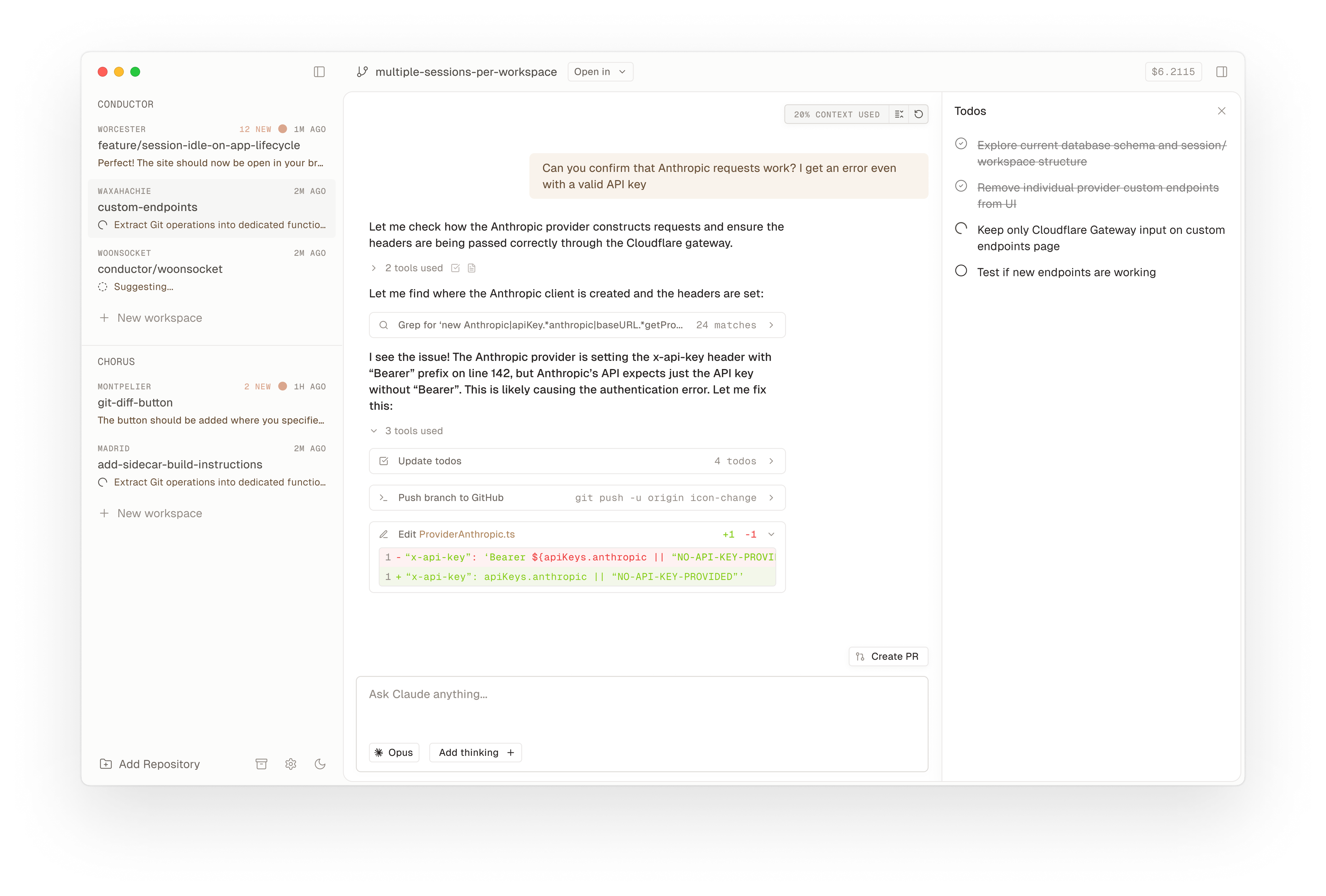
A similar commercial tool is Conductor (currently Mac-only). Conductor’s tagline is literally “Run a bunch of Claude Codes in parallel”. It provides a desktop app where you connect a repo, and can deploy multiple Claude Code agents simultaneously – each agent gets its own workspace (Conductor uses git worktrees under the hood, as confirmed in their FAQ).
The UI shows a list of agents and their status: you can see who’s working on what, who might be waiting for input, and importantly, what files have changed in each workspace. You act as the conductor (hence the name): assign tasks, monitor progress, and review code changes. Once satisfied, you can merge the changes back. As of now, Conductor supports Claude Code as the AI backend, but they hint at adding others soon. The fact that this is a user-friendly app (with a nice GUI) indicates that orchestrating multiple agents isn’t just a hacker’s experiment – it’s headed for mainstream developer workflows.
The Conductor app orchestrating multiple Claude Code agents on a project (each agent runs in an isolated git branch). The UI shows agent statuses, and allows reviewing their code changes before merging.
Another exciting open-source project is Claude Code Agent Farm by Jeffrey Emanuel (@doodlestein). With a name evoking “farming” a whole crop of Claude agents, it delivers on that imagery. Agent Farm is described as an orchestration framework to run “multiple Claude Code sessions in parallel to systematically improve your codebase”. It supports running 20 or more agents simultaneously (configurable up to 50!).
This blows my mind a bit – 50 AI instances attacking a codebase in concert. Of course, to manage that, the framework includes some sophisticated coordination features: a lock-based system to prevent conflicts, so agents won’t overwrite each other’s changes on the same file.
It’s also highly configurable, supporting 34 different tech stacks out of the box with custom workflow scripts for each. This means you can, say, unleash a swarm of agents to apply a set of best practices across a polyglot monorepo – one agent might handle updating React components, another fixes Python lint issues, another updates CI configs, etc., all guided by the frameworks provided. Agent Farm also provides a real-time dashboard with heartbeats and context usage warnings, automatic recovery if an agent crashes, and neat features like generating an HTML report of everything the agents did. Essentially, it’s turning the idea of a “code mod” (mass refactoring) into an AI-driven, parallelizable process.
While running dozens of agents locally might stress some machines (and certainly can rack up API usage costs), the concept is compelling. It reminds me of how build systems went from single-threaded to massively parallel – why not do the same for AI coding tasks? Many small changes that are independent (or can be partitioned by area) are perfect for parallelization. Of course, humans can’t effectively write or review 10 changes at once, but an orchestrator + agents can. The human (you) just need to oversee the results.
Tip: Open-source models like Qwen3 have become capable enough that developers are seriously evaluating them for these use-cases. Do keep in mind cost for self-hosted usage can add-up fast, especially if running multiple agents async.
Besides Claude-focused tools, we have Magnet (by Nicolae Rusan and team), which brands itself as “the AI workspace for agentic coding”. Magnet is a bit like an IDE + orchestrator + project management hybrid. It allows async AI workflows triggered by issue trackers.
For example, you can start an AI task directly from a Linear or GitHub issue inside Magnet. Magnet will automatically pull in relevant context (e.g. files related to that issue, based on the issue description), and even ask clarifying questions before proceeding. It’s designed to guide you end-to-end on a feature or bug fix.
One thing I love is that Magnet doesn’t just spew code – it often suggests considerations or alternative approaches to you as it works, acting like a thoughtful junior engineer might. Nicolae shared an example of shipping a new feature where Magnet not only correctly implemented it, but introduced him to a package he didn’t know about that offered a better solution. That kind of AI augmentation – not just doing the task but improving the solution – is powerful. Magnet also supports grouping tasks across multiple repositories (“Projects” feature). If a feature requires coordinated changes in backend, frontend, and database, the AI can handle each in the appropriate repo and tie them together. This hints at a future where AI agents aren’t limited to one codebase at a time, but can work across an entire software stack cohesively.
If running multiple agents sounds complex, it can be at first. But tools like the above are rapidly smoothing the experience. Even simple approaches work: I know folks who just open several terminal windows (using tmux, iTerm splits, or the new Ghostty terminal emulator) and run separate agent sessions manually in each. Ghostty, for instance, makes it easy to tile many terminals in one window, so you can visually monitor multiple agent sessions side by side.
I’ve tried this – running e.g. Gemini CLI in one pane doing a frontend change, and Claude Code CLI in another doing a backend change. It actually worked out fine, though I had to manage integrating the changes myself. Purpose-built orchestrators like Claude Squad or Magnet handle a lot of that housekeeping (branching, merging, preventing conflicts) automatically, which is definitely nicer.
We are still in early days of figuring out best practices for multi-agent dev. Some challenges to consider: dividing tasks well (so that agents don’t depend on each other’s yet-to-be-done work), ensuring consistency (if two agents need to agree on an interface contract, how do we coordinate that?), and not overwhelming the human overseer. There’s research happening on having the agents themselves coordinate – e.g. one agent acts as a “planner” and assigns subtasks to other agent instances. That starts to sound like AI project managers and AI developers working as a team. I wouldn’t be surprised if in a year or two, we have an “AI scrum master” that can spin up and manage a swarm of coding agents dynamically.
For now, the onus is on the developer to partition work and review outputs. But even in this form, parallel AI development is a force multiplier. I’ve felt a bit like a tech lead directing multiple junior devs – except these juniors work at superhuman speed and never get tired of dull tasks. If this pattern becomes common, our development workflows might shift towards queuing up tasks for AI agents to tackle overnight or while we handle higher-level design. Imagine coming into work to find overnight AI PRs for all the refactoring tasks you queued up – ready for your review.
That segues nicely into the next topic: agents that work asynchronously in the background, producing code while you do other things.
Async background coders: agents that code while you aren't watching
Background agents turn coding into delegated background work: submit a task, let it run in the cloud, review a completed PR later - coding as queued, asynchronous workflow.
One of the promises of agentic coding is the ability to offload coding tasks to an AI and let it work autonomously, notifying you when it’s done or if it needs input. This frees you to do other work (or get some sleep!). Several efforts in 2024-2025 have focused on these asynchronous coding agents. They differ from the interactive CLI agents in that you don’t babysit them in a live session; instead, you trigger them and they come back with results later (minutes or hours later, depending on the task).
The poster child here is Google’s Jules. Jules was first introduced in late 2024 as an experiment in Google Labs, and by May 2025 Google put it into public beta for everyone. They explicitly describe Jules not as a “co-pilot” or autocomplete assistant, but as “an autonomous agent that reads your code, understands your intent, and gets to work”.
Here’s how Jules works, in a nutshell:
You integrate Jules with your GitHub account/repositories. (Jules runs as a cloud service – specifically, it spins up a secure Google Cloud VM for each task).
You give Jules a high-level task. This can be done through a web UI or VS Code plugin (and soon by simply labeling a GitHub issue with “assign-to-jules”jules.google!). For example: “Write unit tests for all functions in the utils/ folder” or “Upgrade the project to Next.js v15 and refactor to the new app directory structure”.
Jules clones your repo into the VM, understands the full context of the codebase (thanks to using Gemini 2.5 which can handle huge context), and then generates a plan of action for the task. It actually shows you this plan for approval. For instance, it might say: “Plan: Update 22 files to migrate to Next.js 15 conventions”.
Once you approve, Jules executes the plan autonomously. It makes the code changes, runs tests if relevant, and so on. This might involve multiple internal steps, but you don't need to supervise them.
When done, Jules presents you with the diffs of all the changes it made for reviewjules.google. You can browse through the code changes (in the UI or as a PR on GitHub).
If you’re happy, you can tell Jules to create a pull request with those changes. Jules will then open a PR on your repository with the commits. (At this point, it’s just regular code – you or teammates can review, run CI, and merge as usual).
As a bonus, Jules can generate an audio summary of the changes – a spoken changelog you can listen to, highlighting what was done. This is a neat touch; I’ve tried it and it feels like a quick way to catch up on an agent’s work while I’m, say, commuting or doing something away from the screen.
All of this happens asynchronously. Jules is doing the heavy lifting in the cloud VM, possibly utilizing parallelism under the hood (Google mentioned it can handle concurrent tasks with speed and precision thanks to the cloud setup). Meanwhile, you could be focusing on another part of the project, or multiple Jules tasks could even run in parallel. It really is like having a background worker.
For cleaner results with Jules, give each distinct job its own task. E.g., 'write documentation' and 'fix tests' should be separate tasks in Jules.
Help Jules write better code: When prompting, ask Jules to 'compile the project and fix any linter or compile errors' after coding.
Do you have an instructions.md or other prompt related markdown files? Explicitly tell Jules to review that file and use the contents as context for the rest of the task
Jules can surf the web! Give Jules a URL and it can do web lookups for info, docs, or examples
What kind of tasks is Jules good at? These include: writing tests, building new features, providing audio changelogs, fixing bugs, bumping dependency versions. The common theme is tasks that have a clear goal and can be relatively well-defined in a prompt. Jules shines at maintenance chores like dependency upgrades or adding tests – things we often procrastinate on as developers. A developer in the Jules beta shared on HN that they could just tell Jules “achieve 100% test coverage” and it went off to write a comprehensive test suite. Another user mentioned Jules automatically fixed a bug and made a PR, saying “Jules just made her first contribution to a project I’m working on” – a sentence that felt sci-fi only a year ago!
OpenAI, not to be outdone, surprised the industry by releasing a research preview of their own coding agent, referred to as Codex. This new Codex agent reportedly can “write, fix bugs and answer codebase questions in a separate sandbox”, much like Jules.
GitHub (and Microsoft) also announced GitHub Copilot “agent” features around May 2025. At Build 2025, they demoed a Copilot that can handle entire coding workflows asynchronously. This includes monitoring your repo for to-do items, self-assigning tasks like generating a PR to fix an issue, etc. Essentially, GitHub is extending Copilot from inline suggestions to an autonomous mode that can act on your repository – in many ways, this sounds like their answer to Jules and Codex. Given GitHub’s deep integration in developer workflows, Copilot Agent could directly live in the GitHub UI (imagine a “Copilot, fix this issue” button on a Pull Request that triggers the agent).
One challenge with background agents is trust. If an AI is working for an hour on your repo unsupervised, you want to be sure it doesn’t go off the rails. The current implementations mitigate risk by operating in sandboxes or branches, and requiring human review before changes get to main. Jules, for instance, works on a separate branch and requires you to approve its diff and PR. OpenAI’s Codex sandbox implies it doesn’t directly touch your actual repo until you merge its output. This is good – it keeps the human in the loop at key checkpoints.
Another challenge is scoping the task well. If you give an overly broad instruction, an agent might attempt a huge refactor that becomes hard to validate. The best use cases are somewhat bounded tasks. I've found that even if you ultimately want something big, it helps to break it down. For example, instead of "migrate my whole app from Django to FastAPI" (which is enormous), you might start with "generate a plan for migrating from Django to FastAPI" and then feed sub-tasks. Future agents might be smart enough to do this decomposition themselves (some already attempt it – Jules internally creates a plan). But guiding them with manageable tasks makes for better outcomes today.
One very cool aspect of Jules: it can handle multiple requests simultaneously in parallel. That means if you have several tasks (write tests, update deps, etc.), Jules will utilize multiple agents or threads to do them concurrently in the cloud VM. In the demo at Google I/O, they showed Jules fixing several bugs in parallel. This parallelism in async mode is like combining the ideas of the previous section (multiple agents) with the cloud scale – you as a developer might just fire off a batch of tasks and come back later to find a set of PRs ready. It’s a glimpse of a near-future developer experience where a lot of the "busy work" in coding truly happens without constant human attention.
The developer community’s reaction to these async agents has been a mix of awe and healthy skepticism. Awe, because when it works, it feels magical (folks sharing on Twitter how Jules fixed something while they worked on something else). Skepticism, because sometimes the agents get things wrong or produce suboptimal code, and a human has to clean it up. From my perspective, even if these agents are only 70% good right now, they’re improving rapidly. And even 70% is a huge help if they can knock out the boring stuff.
I personally tried Jules on a few tasks in a side project – one being “upgrade this project to the latest version of Node.js and fix any compatibility issues”. It actually did it: it bumped the Node version in config, updated a couple of libraries, found some deprecated API usage and changed it, and all tests passed. It left a few things untouched that maybe could be improved, but it saved me a chunk of time. Another time, I asked it to generate an audio summary of recent changes in a repo, and listening to that felt like a mini podcast of my codebase’s progress. These experiences felt like early glimpses of offloading the “maintenance engineer” duties to an AI.
In summary, async coding agents like Jules and Codex are turning coding into a background activity for certain tasks. You assign a job and check back on results. It’s a different workflow – almost like how you delegate to a build server or a CI pipeline. In fact, it’s natural to integrate these agents with CI, which leads us to the next topic: what about using AI agents to maintain code quality and fix issues continuously?
When multiple capabilities converge
Enterprise-grade platforms are emerging that combine CLI, IDE, orchestration, and async capabilities into unified development experiences, challenging the single-purpose tool approach.
While specialized tools excel in specific categories - CLI agents, orchestrators, or async coders - a new class of integrated platforms is emerging that combines multiple agentic capabilities into comprehensive development ecosystems. These platforms represent the maturation of AI coding tools from experimental single-purpose agents to production-ready development environments that can handle end-to-end workflows.
In recent months, Sourcegraph’s Amp (or AmpCode) has gained significant attention, especially among enterprise users seeking robust AI coding agents. Positioned in a research preview phase, it already demonstrates unique strengths that distinguish it from other agents. Installation is seamless: users can enable Amp via a VS Code extension (including Cursor, VSCodium, Insiders forks), or choose to run it directly as a command-line tool. This flexibility reflects Amp’s design philosophy - deeply integrated yet adaptable to diverse developer workflows. Here’a a demo from Amp’s Daniel Mac showing how to add a new model provider to an AI chat app, using 'Oracle', Amp's o3 based sub-agent, to research and create a plan:
One of Amp’s most discussed technical advantages is its fixed 200,000-token context window. The design aggressively leverages this to retain as much relevant codebase context as possible. When conversations grow large, developers can use features like compact thread summarization or spawn new threads initialized with summaries - preserving continuity without exceeding token constraints (Reddit discussion).
In terms of extensibility, Amp incorporates MCP in a straightforward interface accessible from its chat UI. Pre-bundled MCP servers support dynamic tasks - such as generating mermaid graphs inside conversation threads - and developers can define command allowlists stored directly in their repository. These features form a thoughtful foundation for secure and auditable agent execution in enterprise environments (Reddit overview). Here’s a demo from Justin Dorfman of Playwright MCP, one of the prebundled MCPs, to identify slow-loading pages on localhost:
One user I spoke to appreciated Amp’s ability to act like a junior engineer - compiling, running tests, making coordinated changes across classes or modules - while another cautioned about token costs and the importance of review processes. As one thread noted, “Amp does walk you through the changes it’s making… I actually prefer this over Cursor’s one-by-one change
However, Amp’s design choices are not without tradeoffs. Current iterations rely heavily on Claude Sonnet, with little support for other models, open API keys, or private deployments. Sourcegraph frames this as a deliberate decision to deeply optimize around a single model rather than spreading across many, but it limits flexibility for organizations requiring model governance or internal hosting.
“No model selector, always the best models. You don’t pick models, we do. Instead of offering selectors and checkboxes and building for the lowest common denominator, Amp is built to use the full capabilities of the best models.” is an intentional principle in their docs.
Several aspects of Amp’s state also raised caution among reviewers. Threads are stored on Sourcegraph’s servers by default, which may conflict with stringent data policies; edit operations can be auto-applied (though Git review remains available as a safety net); and features like leaderboards or shared prompts may feel misaligned with professional developer norms - even though they can be disabled upon user request. Context leakage across large monorepos was an initial concern, later clarified by insiders: Amp does not pull in entire repositories inadvertently - unlike its predecessor Cody - though prompt token usage remains nontrivial (Reddit thread).
Across from Amp, Warp’s Agentic Development Environment offers a very different vision of platform integration. Rethinking the terminal from the ground up, Warp 2.0 delivers a Rust-based, GPU-accelerated interface where traditional shell commands coexist with natural-language agent interactions. Warp allows users to manage multiple agent sessions in parallel, share commands via Warp Drive, and selectively approve AI-generated diffs before they are applied.
Warp agents notify you when they need human help: approving a code diff, running a kubectl command, approving a commit message. Plus, you can keep track of all your agents in one, centralized panel.
Warp’s approach as creating a workspace that is neither IDE nor plain terminal: it is built to let developers coordinate and supervise AI agents across tasks like deployment, debugging, and log analysis. Here’s a demo I liked by Zach Lloyd showing Here's how he uses Warp’s Agent Mode to update PR descriptions as he codes:
Warp’s controls restrict risky actions (for example deleting files) until explicit human consent is given. This agentive model mirrors classic command-line workflows but with integrated AI oversight.
Warp's performance credentials are impressive - scoring #1 on Terminal-Bench and achieving 71% on SWE-Bench Verified demonstrates that their integrated approach doesn't sacrifice capability for convenience. According to user feedback, users value Warp’s speed, command-sharing features, secret redaction and seamless customization of terminal blocks - all positioning it as a terminal that truly harnesses AI while preserving developer control.
That said, Reddit commentary flags areas for improvement in large-scale use: some users report indexing challenges with large repositories, and concerns around high request volume - prompt cost multiplied across heavy agent activity - are increasingly common. That said, Warp still allows complete AI functionality toggling; absent AI, the terminal reverts to its previous lightweight state.
Taken together, Amp and Warp exemplify two complementary trajectories in agentic developer tooling. Amp is designed for deep code-intelligence workflows and enterprise collaboration, excelling where coordinated refactoring across extensive codebases matters. Warp instead focuses on synergies between command-line power and agent orchestration, delivering a modern terminal that supports supervised AI activity across development tasks.
Both platforms signal a broader industry shift from narrow, single-purpose assistants toward holistic, outcome-oriented AI environments. Developers can now work with agents capable of multitasking, context-driven planning, and end-to-end execution - minimizing manual intervention while ensuring procedural oversight and enterprise readiness. As individual tools, they embody the new generation of AI-augmented development platforms rather than incremental, model-bound utilities.
Self-healing codebases? AI in testing, debugging and CI/CD
CI becomes self‑healing when agents not only detect failures but propose, validate, and apply fixes - making builds proactively resilient and developer flow unbroken.
Coding doesn’t stop at writing features. A huge part of the SDLC is testing, debugging, code review, and continuous integration (CI) – ensuring that the software works and continues to work with each change. It’s in these “adjacent” stages that AI is also making a big impact, often in ways that complement the coding agents we discussed. After all, what good is an AI-generated PR if it breaks your build or introduces subtle bugs? Thankfully, we are seeing patterns for AI-assisted testing and CI that could make our codebases more resilient (perhaps more resilient than purely human-driven ones).
One exciting development is AI-powered self-healing CI pipelines. The idea: when your CI tests fail, instead of just notifying you and waiting for you to fix it, an AI agent can automatically diagnose and even fix the issue. The Nx team (creators of the Nx build system for monorepos) recently announced Nx Cloud Self-Healing CI, which does exactly this.
They described a scenario: you push some code, and CI fails due to a silly mistake (like a missing import or a small test assertion fail). Normally, you might not notice for 30 minutes, then have to context-switch to fix it, push again, and waste time. With Self-Healing CI, what happens instead is “magical”:
Failure detected: Upon a test failure, automatically start an AI agent to investigate.
AI diagnosis: The agent looks at the error logs and, importantly, has knowledge of your codebase structure. So it knows where to look.
Proposes a fix: The agent comes up with a fix – e.g., add the missing import, adjust the test expectation, etc. – and presents it to you, either in your IDE or as a comment on the PR.
Validates the fix: In parallel, the agent runs the tests again (or the subset that failed) with the proposed change to ensure it actually resolves the issue.
Human approval: You get a notification (e.g., in VS Code) that says “AI fix available: added missing import X”. You can review the one-line change. If it looks good and the validation passed, you hit approve.
Apply and re-run: Once approved, the fix commit is applied to your PR automatically, and the full CI runs again (which now likely passes).
All of this can happen in a short time window.
Crucially, they emphasize that the developer stays in control – the AI doesn’t just commit changes on its own without your OK. This “human in the loop” approach is wise; it builds trust. Over time, if these AI fixes prove consistently correct, maybe teams will auto-approve minor ones, but it’s good that initial designs assume oversight.
Self-healing CI addresses a real pain: so much time is lost in the dev cycle due to trivial breakages and the latency of feedback. If an AI can shave that down, it keeps developers in flow. And it’s not just Nx; we’re seeing similar ideas elsewhere. There’s a tool called GitAuto that can analyze a failing CI run and automatically create a fix PR with the necessary changes. CircleCI published a guide on using AI (with their platform’s APIs) to resolve test failures with zero guesswork. GitLab is integrating AI to suggest fixes right within Merge Request UI when something fails.
Beyond CI, consider runtime debugging. There was a rather bold experiment shared on Reddit: a developer let an AI agent attempt to fix production bugs for 27 days straight, automatically generating PRs for any exceptions caught in production. According to their post, the AI managed to resolve a bunch of issues on its own, and the dev team only intervened occasionally. That’s a bit bleeding-edge and risky for many, but it shows where things could head: an AI ops agent that monitors logs/errors and continuously improves the code.
AI code review is another adjacent area. I anticipate that having an “AI reviewer” will become common. GitHub is already previewing features where Copilot will automatically suggest improvements in a pull request, highlight insecure code, or summarize a PR’s changes for the human reviewers. Open source projects like pr-agent hook models into your PR workflow to do things like explain the code changes or point out potential issues. While not fully trusted to approve/deny PRs, these AI reviews are like having a diligent junior reviewer who never gets tired. They can enforce style guides, catch obvious bugs, ensure test coverage, etc. I’ve used one such tool to get a second opinion on my PRs – sometimes it’s surface-level, but occasionally it points out something I missed, like “This function isn’t handling X case; is that intentional?”. It’s easy to see every team having an AI reviewer integrated into GitHub or GitLab, raising the baseline quality of code reviews.
Let’s talk about flaky tests and maintenance as well. Companies like Trunk.io advertise an “AI DevOps agent” that, among other things, can detect flaky tests, quarantine them, or suggest fixes. Maintenance tasks such as updating dependencies, cleaning up warnings, etc., can be handled by periodic AI agent runs. Some teams have scheduled jobs where an AI opens PRs weekly for dependency bumps (tools like Dependabot do minor version bumps, but an AI could handle major upgrades that need code changes). This merges into the idea of continuous improvement bots.
In essence, the agentic future isn’t just writing new features – it’s also maintaining and improving code continuously. A lot of engineering effort (some say ~30-50%) in a mature codebase goes into maintenance, refactoring, keeping tests green, etc. If AI can take a chunk of that, it frees humans to focus on more complex design and new functionality.
To illustrate how far things have come, consider this: Just two years ago, “AI in coding” mostly meant code completion or maybe a bot that could create a simple PR from a template. Now we’re talking about AI autonomously monitoring, coding, and fixing software in a loop. And it’s actually happening in real projects.
Of course, developers still have to make judgment calls. Not every failing test should be “fixed” by changing the code – sometimes the test caught a real bug in the logic or the fix might have side effects. So a human needs to ensure the AI’s solution is correct for the broader requirements. This again highlights the evolving role: we become the reviewers and approvers, ensuring the AI’s outputs align with what’s truly needed.
In summary, the future of coding involves AI not just in writing code but in verifying and polishing it.
We’ll have agents that act as testers, reviewers, and ops engineers. The codebase could become a more living thing that partially maintains itself. This doesn’t eliminate the need for human oversight – rather, it raises the baseline so that humans deal with the more complex issues.
Now, let’s step back and consider how all these pieces come together in our day-to-day tools and workflows. The line between “coding” and “prompting” is blurring. IDEs are changing, and new ones are emerging built from the ground up for this agentic paradigm.
Multi-modal and “full stack” agents – As AI models gain capabilities like vision, we’ll see development agents that can handle not just code, but also UI design, graphic assets, etc. OpenAI’s Operator agent for web browsing shows that an AI can operate a browser UI like a human. Translate that to dev tools: an AI could use a GUI builder or drag-drop interface. Perhaps the agent of the future could open Figma designs and generate corresponding code, or vice versa. In fact, Anthropic’s Claude Code via MCP can pull in design docs or Figma assets to understand what needs to be built. That’s an early step toward multi-modal development assistance.
Collaboration with human developers is also being rethought. For instance, suppose a team of 5 devs is working on a project. In the future, maybe each dev has their own AI agent that learns their coding style and assists them, and the agents also communicate with each other (with permission) to ensure their code changes align. It sounds wild, but I imagine something like a “team of 5 devs + 5 AI sidekicks” where the AIs exchange notes (like one agent says “hey, Alice’s agent, I’m updating the API interface, you might want to update Alice’s UI code usage of it”). This would essentially mirror how a well-coordinated team works, but at light speed. Early hints of this appear in orchestrator tools that share context between agents. Magnet’s approach of clarifying questions and context sharing between tasks is a manual form of that. Perhaps soon the agents will negotiate task splits themselves.
The norm likely to emerge: A few years down the line, I suspect it will be completely normal for a software engineer to have a development environment where:
You describe what you want at a high level, and an AI agent generates an initial implementation.
You then engage in a back-and-forth with the agent to refine it (maybe using both CLI and IDE interactions).
If it’s a big task, you delegate subtasks to multiple agents (possibly with specialized skills).
When you hit “run tests” or “deploy”, AI agents automatically fix small issues and ensure the pipeline is green.
Code reviews are partially automated – AI gives feedback, humans focus on higher-level concerns.
Documentation and ancillary artifacts are updated by AI.
The developer’s main job is defining goals, constraints, reviewing important changes, and making architectural decisions. Essentially the human provides vision and oversight, the AI handles execution details.
We’re already living a prototype of that workflow in 2025; it’s just not evenly distributed. Some bleeding-edge teams are close to this, while others are just now trying a Copilot suggestion for the first time. But the trajectory is clear enough that I feel confident this will be widespread.
Challenges, Limitations, and the human touch
As humans shift from coder to conductor, the core skill becomes oversight - writing good briefs, reviewing agent output, and catching edge‑case failures. AI amplifies mistakes if unchecked.
Before concluding, it’s important to temper the excitement with some reality checks. As amazing as these tools are becoming, they introduce challenges – technical, ethical, and professional.
Quality and correctness: AI agents can produce wrong or inefficient code. They lack true understanding and may not foresee edge cases. We’ve all seen LLMs hallucinate or make up facts; in code, that might mean introducing a subtle bug or using an outdated API. Testing mitigates this, but not everything is easily testable (e.g. did the AI inadvertently create a security vulnerability or a performance bottleneck?). So we still need skilled engineers to audit and refine AI output. In the near future, one of the most valuable skills will be AI-assisted debugging: understanding where the AI’s reasoning might have gone astray and correcting it. It’s the “verify and validate” loop where humans excel.
Prompt engineering and task specification: Getting the best out of an agent requires clear communication. If you underspecify a task, the AI might do something unexpected. If you overspecify, you might as well code it yourself. We’ll need to learn how to write effective “AI specs” – akin to writing a good spec for a junior developer, but even more explicit at times. Interestingly, this might force us to think more clearly about what we want before diving in, which could be a good thing. I’ve found myself writing out the desired behavior in detail for the AI, and realizing in the process that I had gaps in my own plan.
Cost considerations: While many examples we discussed have free tiers or personal limits (Gemini CLI free access, Jules free beta), ultimately someone pays for those cycles. Running dozens of agents in parallel might burn through tokens (and $$) quickly if not managed. Organizations will have to factor AI compute into their dev costs. It’s possible that AI-augmented development, despite saving time, could increase cloud costs (at least until model inference gets cheaper). Open-source models running locally offer an alternative for some cases, but the best capabilities still reside in large proprietary models as of 2025. However, given the competition, we may see more cost-effective options or even hardware optimized for these tasks (imagine your dev machine having a built-in AI accelerator to run 20 local model instances cheaply).
Despite these challenges, I’m optimistic. Every new abstraction in programming (from assembly to high-level, from manual memory to garbage collection, etc.) faced skepticism, yet ultimately made us more productive and enabled building more complex systems. Agentic AI for coding feels like a similar leap. We just have to apply the same rigor we always have in software engineering: code review, testing, monitoring in production – those practices don’t go away; they adapt to include AI in the loop.
Conclusion
The way we write software in the post-2025 world is transforming into something both exhilarating and a bit surreal. Programming is becoming less about typing out every line and more about guiding, supervising, and collaborating with these agentic tools.
To recap the key patterns shaping this future:
AI coding agents (CLI and IDE) are enabling us to work at a higher level of abstraction – focusing on what we want to build, while the AI figures out how in code. Tools like Claude Code, Gemini CLI, OpenCode, Cursor, and Windsurf exemplify this, each bringing their twist but all moving in the same direction.
Parallel AI development allows scaling our efforts horizontally – it’s now feasible for a single developer to supervise multiple AI “developers” working simultaneously. Early orchestrators (Claude Squad, Conductor, Agent Farm, Magnet) show that this can drastically speed up complex or large-scale code modifications.
Asynchronous agents like Jules and Codex let coding happen in the background, turning software development into a more continuous, autonomous process. You can go to lunch and come back to find a feature implemented or a bug fixed (with a PR and diff ready to review).
AI in testing/CI closes the loop, catching and fixing issues so that the code an AI writes is also verified by AI. Self-healing CI, automated test generation, and AI code reviews collectively push us toward a world of self-maintaining codebases.
AI-first workflows and environments are emerging, from fully AI-driven IDEs to deeper integration in platforms like GitHub. They point to a norm where having multiple AI “assistants” as part of your dev team is just how things are done.
The developer’s role is shifting to higher-level decision making, providing oversight, and handling the creative and complex aspects that AI still struggles with. We’ll increasingly act as architects and conductors of software, not just bricklayers of code.
New tools and projects are popping up constantly, especially in open source. The community on Reddit, Hacker News, and Twitter is actively discussing and iterating on these ideas. For every major product like Copilot or Jules, there’s an open-source equivalent or experiment that often sparks the next innovation.
So, how do we prepare and adapt? My approach has been to embrace these tools early and experiment with integrating them into real workflows. If you’re a software engineer reading this, I encourage you to try some of the mentioned tools on a personal project. Experience the feeling of hitting a button and watching an AI write your tests or refactor your code. It’s eye-opening. Simultaneously, practice the skill of critically reviewing AI output. Treat it like you would a human colleague’s work – with respect but also scrutiny.
As we head into this agentic world, I keep an eye on one guiding principle: developer experience (DX). The best tools will be the ones that feel natural in our workflow and amplify our abilities without getting in the way. It’s easy to be seduced by autonomy for its own sake, but ultimately these agents must serve the developer’s intent.
I’m encouraged that many of the projects I discussed are being built by developers for developers, with active feedback loops.
I’m excited to share I’m writing a new AI-assisted engineering book with O’Reilly. If you’ve enjoyed my writing here you may be interested in checking it out.