
Building a code-writing robot and keeping it happy
 Tom MacWright
Tom MacWrighton
I recently gave this talk at a lovely event put on by our friends atJamsocket, where we discussed different experiencesrunning LLMs in production. With Townie,we’ve been dealing with the magic and eccentricities of this new kindof engineering.
For those who couldn’t make it or are interested in following along, hereare some slides and speaker notes.
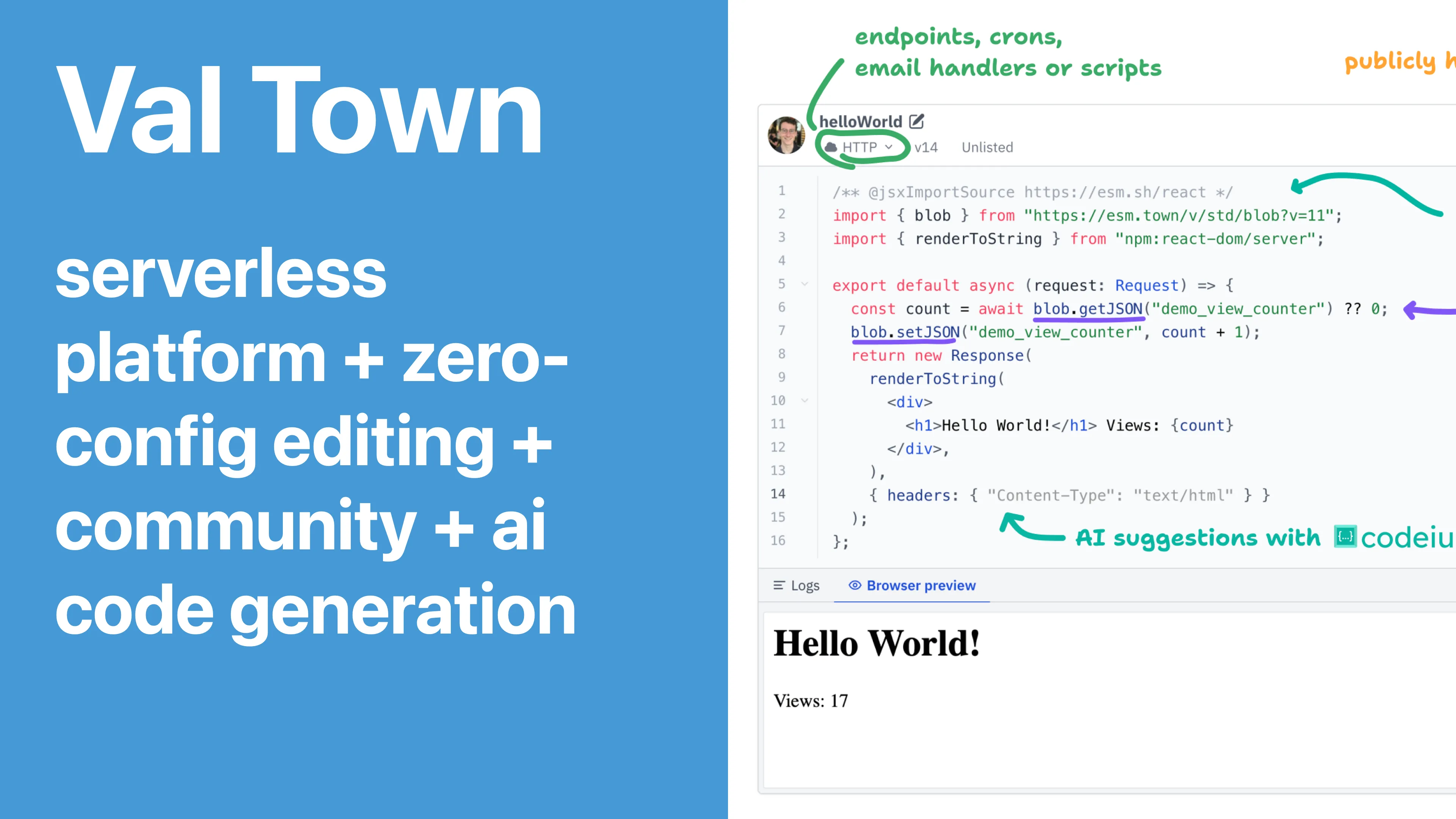
Val Town is mostly a platform for running little bits of JavaScript that we call “vals”, and it makes programming accessible to a lot of new people because vals can be super small, simple, and they don’t require any configuration. But we’ve been using LLMs to make it accessible to even more people who want to create things with natural language.
Here’s the feature I’m talking about today - Townie. It’s the Val Town bot. If you want to be old-fashioned, you can write the code yourself with your hands and fingers, but Townie will let you write it indirectly with English. It’s similar in broad strokes to Anthropic Artifacts or Vercel v0, but one of the biggest differences is that the artifacts have full-stack backends, can be shared and forked, and so on.
We’re running a pretty plain-vanilla LLM setup! The meat and potatoes of Val Town are the challenges of running a lot of user code, at scale, with good security guarantees, and building community and collaboration tools. We aren’t training our own models or running our own GPU clusters.
So for LLMs, we’re riding on the coattails of Anthropic and OpenAI and running none of our own LLM infrahttps://blog.val.town/_astro/slide-5.QRIgWo5d_1dLU66.webpe chaotic" loading="lazy" decoding="async" src="/_astro/slide-5.QRIgWo5d_1dLU66.webp">
But despite the simplicity, LLMs are pretty chaotic, and this has taken longer to build than we expected.

LLMs are unlike everything else on the backend: they can easily blow up your server costs, they have plenty of downtime, they’re really hard to tune, and they can be super, super slow. Here’s a quick run-through of how we’ve been dhttps://blog.val.town/_astro/slide-7.Bng0vZ2J_Z1ge9wk.webpg alt="Good LLM models are expensive and eat money" loading="lazy" decoding="async" src="/_astro/slide-7.Bng0vZ2J_Z1ge9wk.webp">
The good models are expensive. LLMs eat money. We’re practicing financial disciplihttps://blog.val.townhttps://blog.val.town/_astro/slide-8.DYUuJ--S_Z1JTTuy.webp How do we do it?

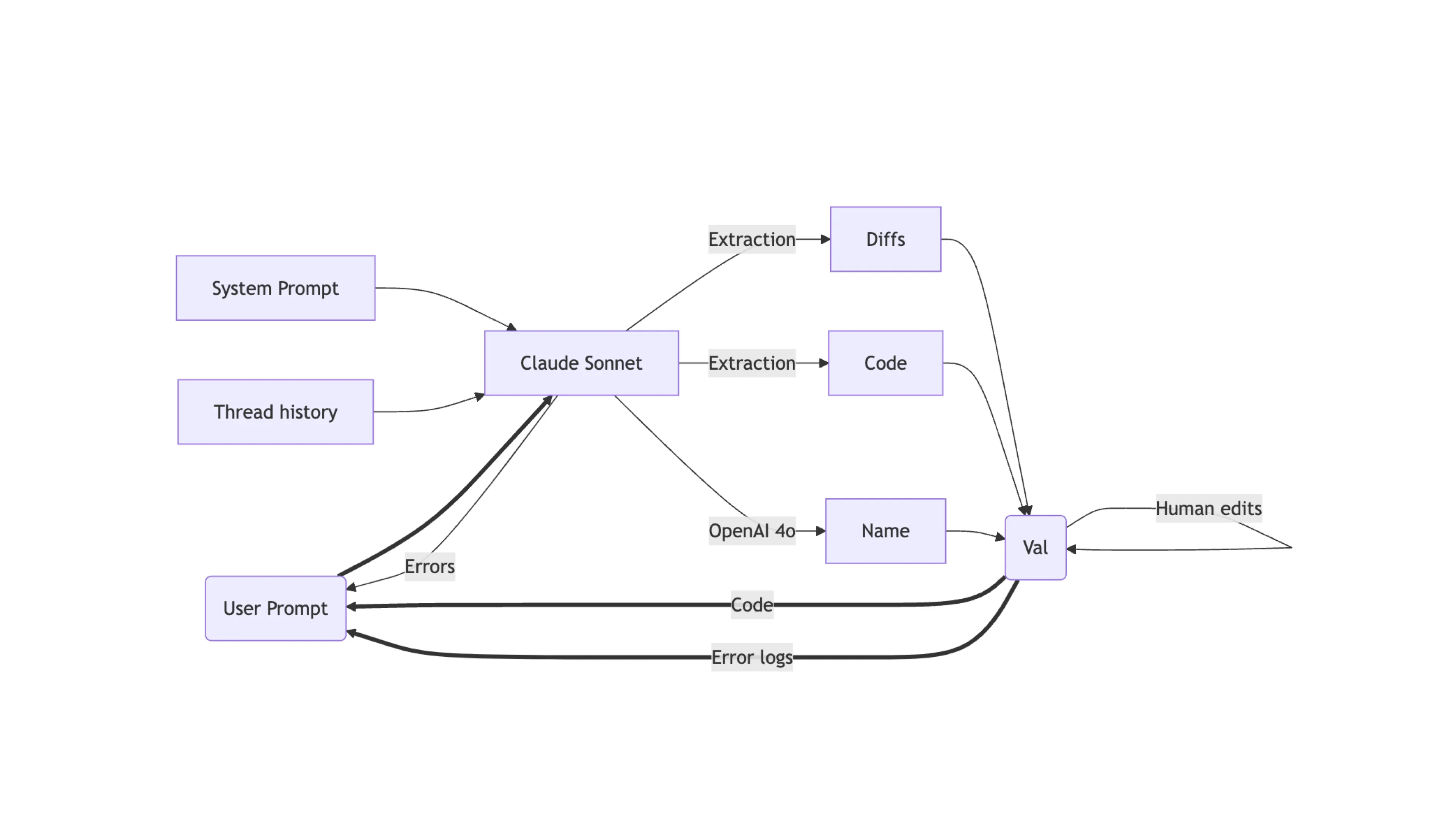
The easiest cost and performance alpha is just using different providers for different tasks. For example, when someone creates a val, we want to generate the TypeScript code for that val, which is pretty nitpicky work: it needs to work with Deno’s TypeScript environment and it should reliably know whether it’s running on the frontend or the backend, and so on. For that we use Sonnet, which is pretty expensive.
But then once we have the generated code, we want to generate a name for it, given both the prompt and response to that prompt: for that we use Openhttps://blog.val.townhttps://blog.val.town/_astro/slide-9.De7VQRuq_ZinY4t.webp and good enough.

And to use different models, it’s really nice to use an abstraction library like @vercel/ai, which is what we’ve been using. I know that there are several hundred options, so that isn’t a fully-rhttps://blog.val.townhttps://blog.val.town/_astro/slide-11.Dk3XCfG2_Z1QbsVN.webp it’s worked fine for us.
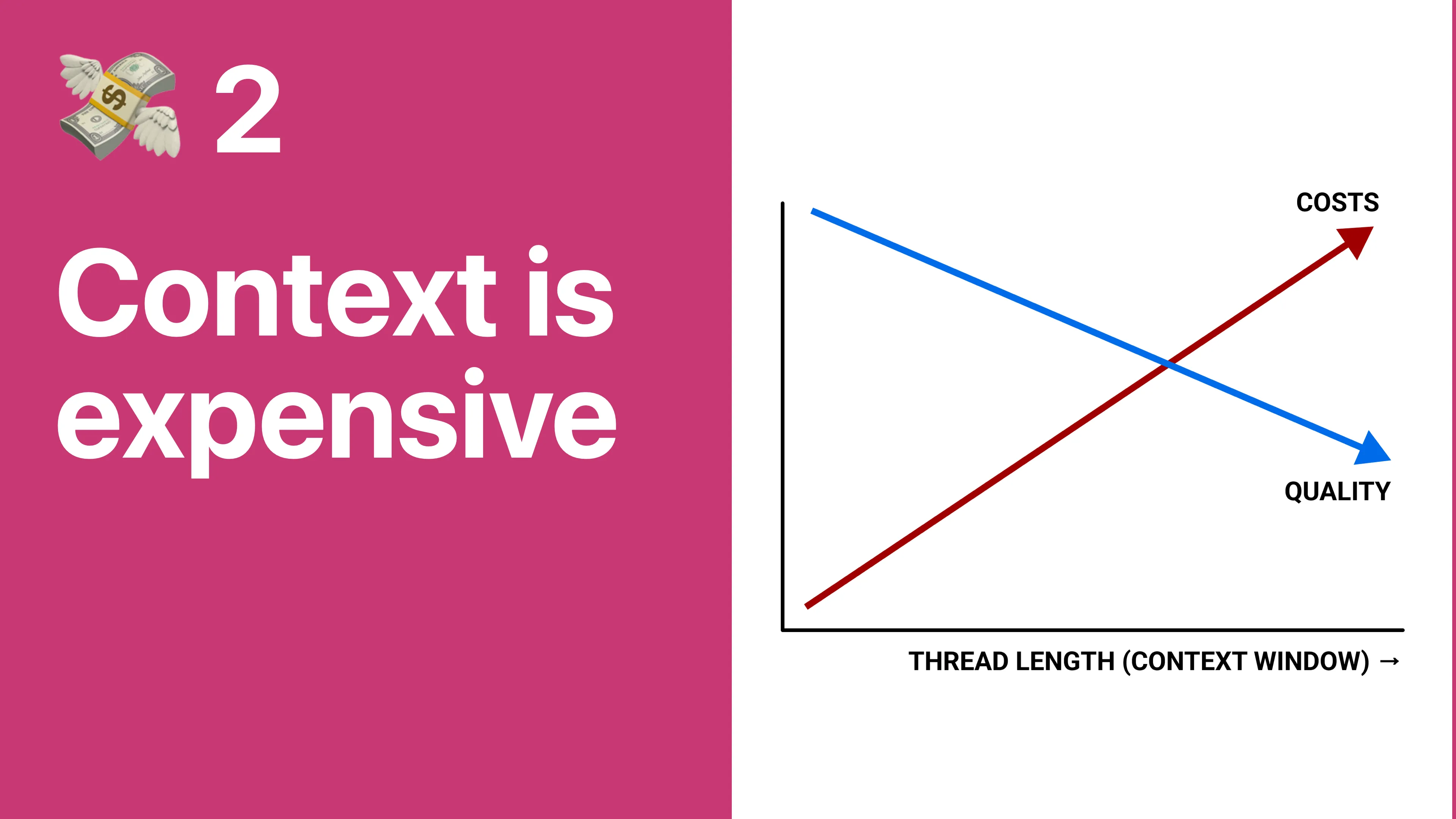
So the other problem is that this is a chat interface, and none of the LLM providers provide persistence: you have to put the whole chat history into context for every single new message. And the responses that we get from Claude can be pretty long - these are complete programs that we’re getting back, lots of tokens. So we’vehttps://blog.val.townhttps://blog.val.town/_astro/slide-12.BtIoD74W_25OjLc.webp approaches to this problem.
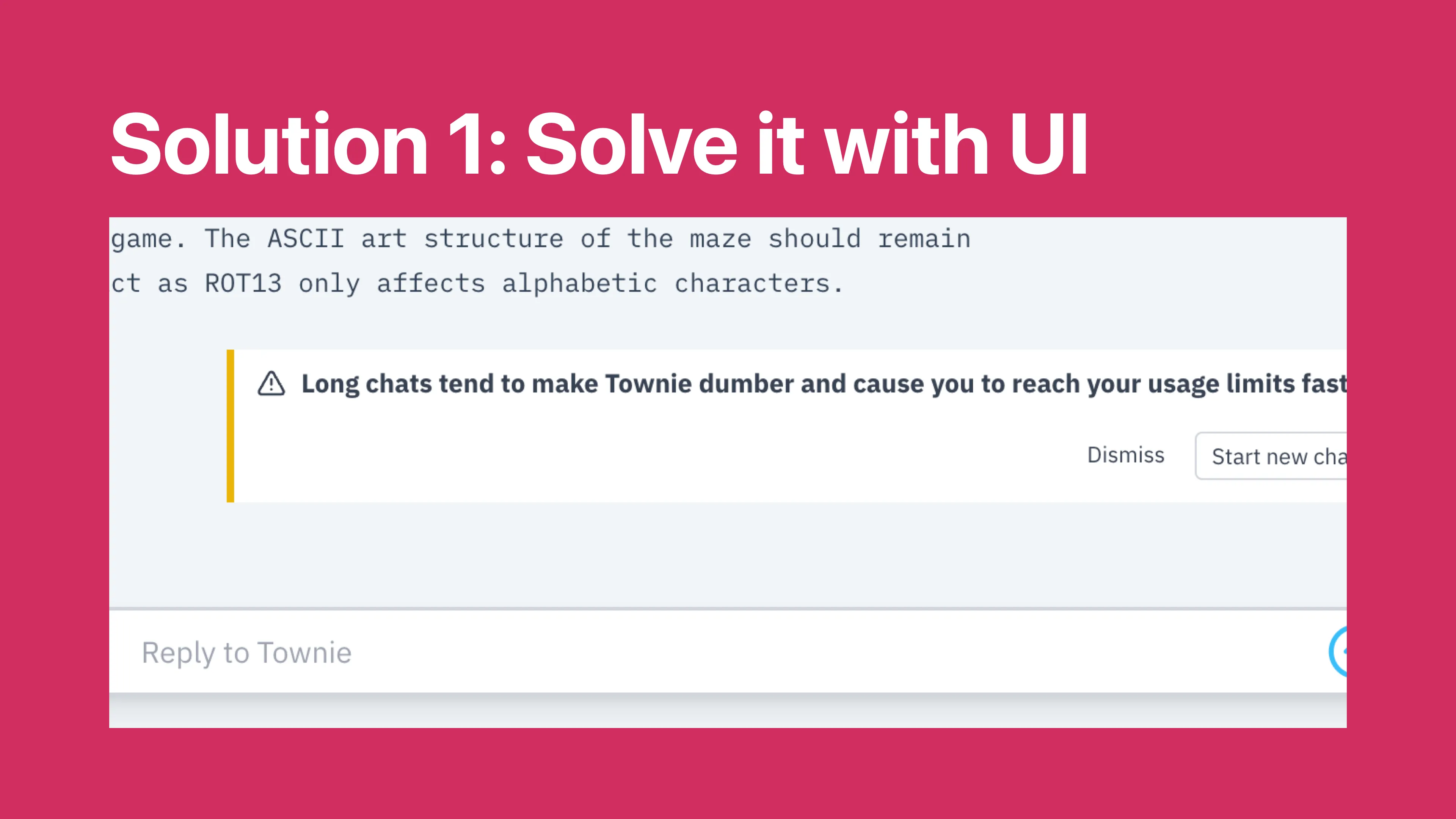
Our first line of defense against this is just reminding users that Townie gets dumber when you give it more input. This is pretty similar to the UIs in other tools that say the same thttps://blog.val.townhttps://blog.val.town/_astro/slide-14.B57boPhP_k8fPO.webptenth reply or so, Townie will start losing the thread of what you wanted in the first place.

Caching old messages somehow lets Anthropic amortize the cost of parsing messages and turning them into embeddinghttps://blog.val.townhttps://blog.val.town/_astro/slide-15.MydtCPdQ_ZLyToy.webprepresentation they have. It costs more money to create the cached stuff initially, but less to use it later.
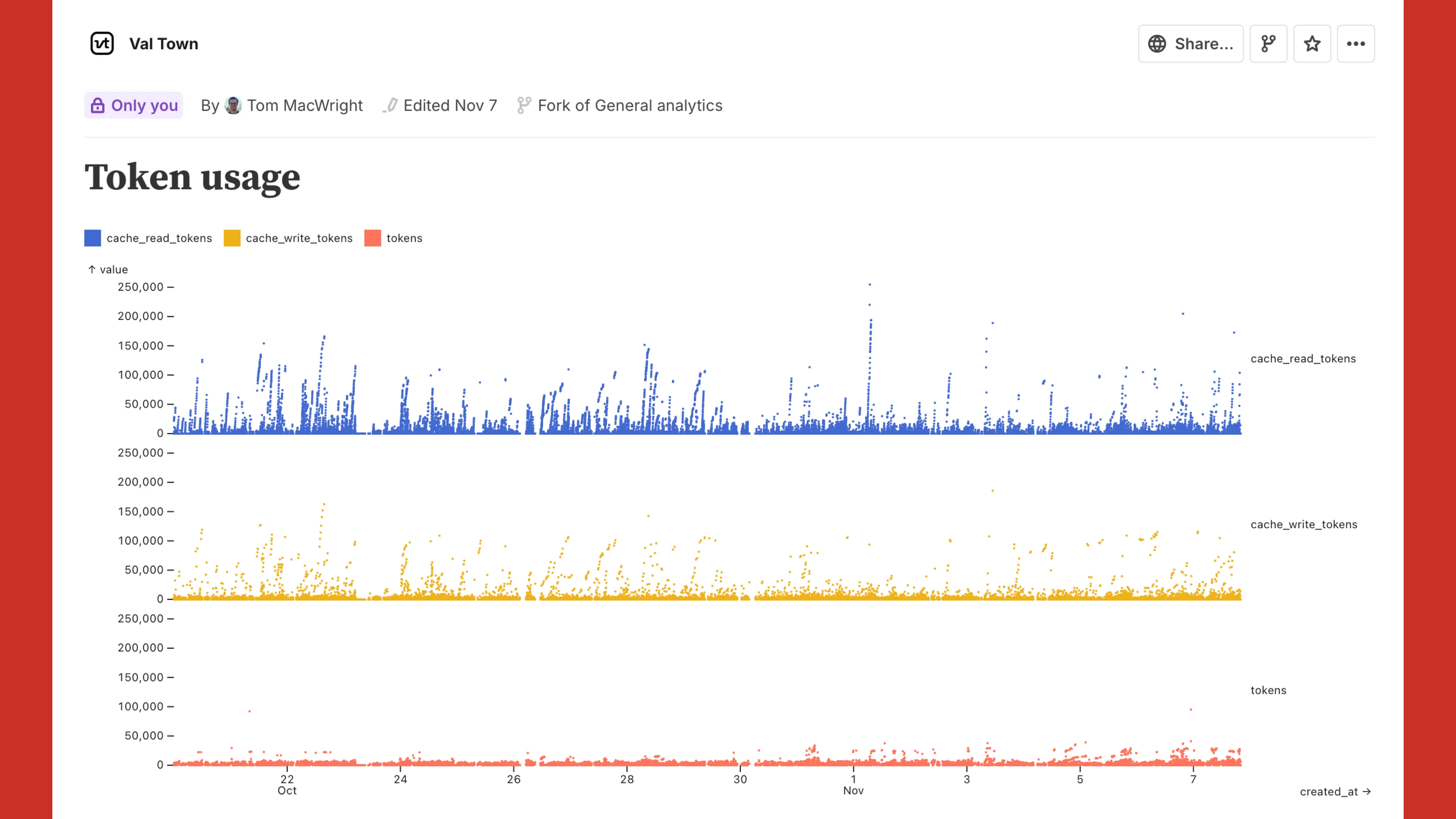
Storing all of this in the database was also a pretty big win - so I was able to just query this from our messages table right into an Observable notebook.
This works! You can see some of the effects here, wherehttps://blog.val.townhttps://blog.val.town/_astro/slide-16.DqwFpdYr_Z1DC2eW.webpare people having super long conversations with Townie, but instead of hitting the tokens statistic, they’re being read from the cache.
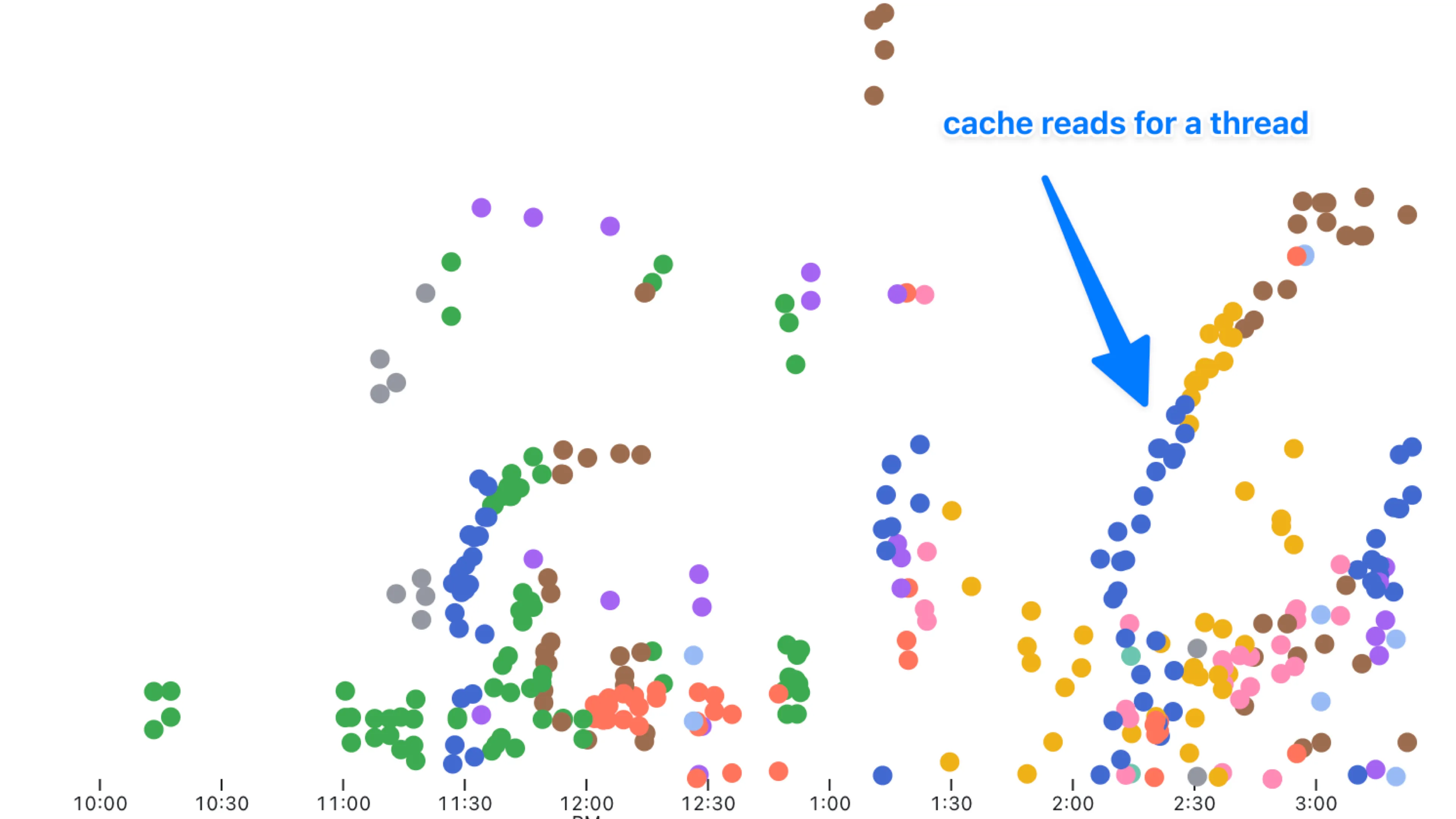
https://blog.val.townhttps://blog.val.town/_astro/slide-17.DnwfFpuz_doHaA.webpnd enhance style, colored by which thread they’re part of: you can see some spots where it’s just the same exact thread that’s benefiting from the caching.

A funny thing that doesn’t work is trying to truncate old messages. Like, you’re sending code back and forth, right - so if the LLM writes code and fixes some bug you have two copies of the code in the context window. So we tried replacing old code replhttps://blog.val.townhttps://blog.val.town/_astro/slide-18.Ywk3LOJs_Z1BlikW.webptruncated for brevity,” but the LLM took this very literally. We found that if we truncated code in the conversation history, the LLM decides to truncate code in its responses, too.

Another potential solution that we’ve struggled to implement successfully is diffs. Claude can convincingly provide a good unified diff some percentage of the time, but it is very slophttps://blog.val.townhttps://blog.val.town/_astro/slide-20.Dm71Wtjb_1na3HC.webpthe wrong line numbers or missing context, ahttps://blog.val.townhttps://blog.val.town/_astro/slide-21.Baova9tT_Z1G4yWM.webpelf merge implementations. We’ve implemented our own fuzzy merge solution, but even then, diffs haven’t been reliable enough for regular usage.

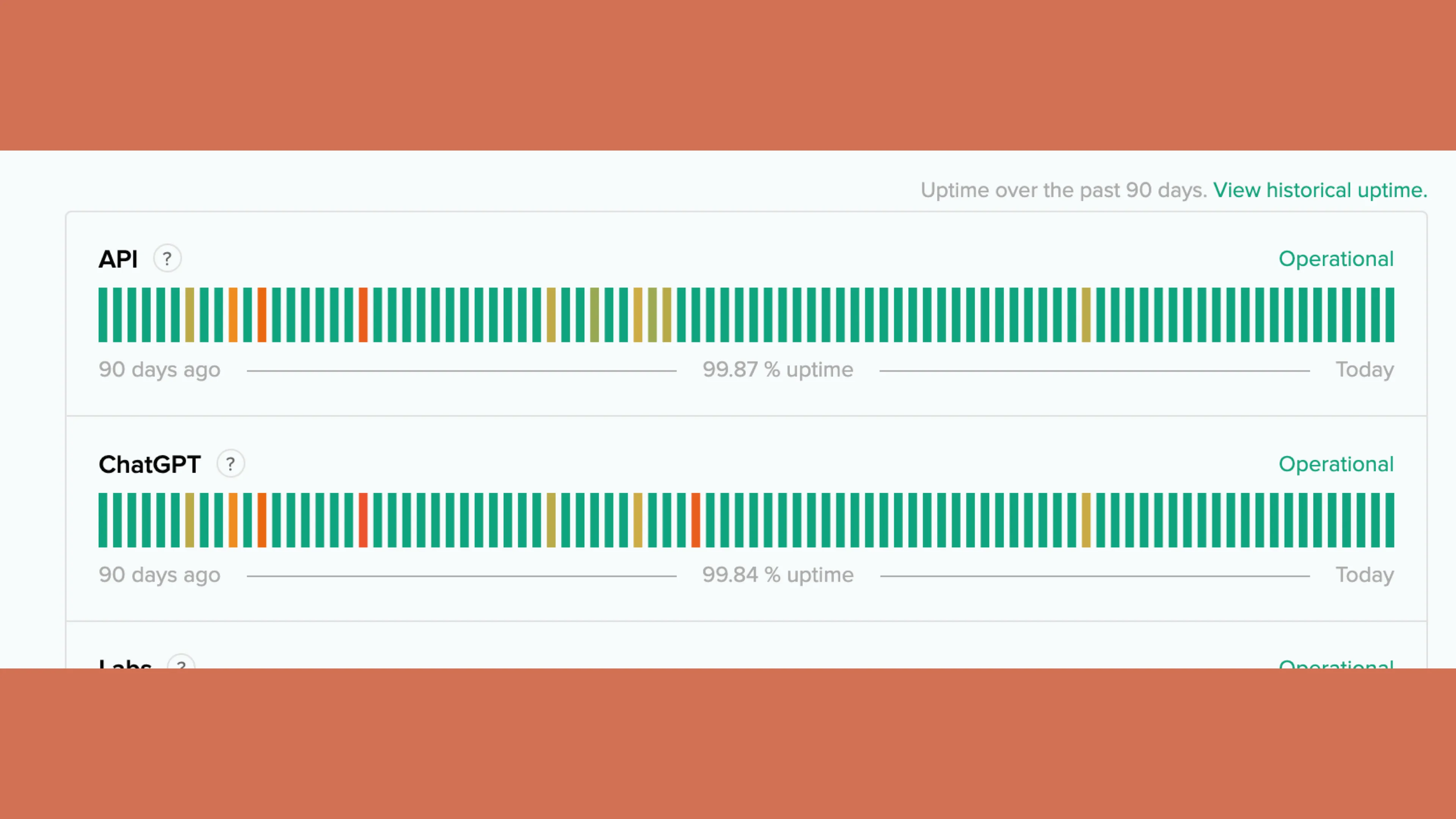
Unfortunately, we’ve also hit reliability issues with both Anthropic and OpenAI – both center around two nines of uptime recently. They’re doing magical things, it’s understandable that there are some speed bumps along the way! But there’s not too much we can do abouthttps://blog.val.townhttps://blog.val.town/_astro/slide-26.CZj_mNkY_Z2U1Y8.webpelves, so we have just decided to really double down on implementing good error handling in our application and have recently adopted neverthrow to improve how we use errors in TypeScript.

We’ve also spent a lot of time tuning our custom prompt, which felt like shooting in the dark until we started using a system for evals. Braintrust has been great for this.
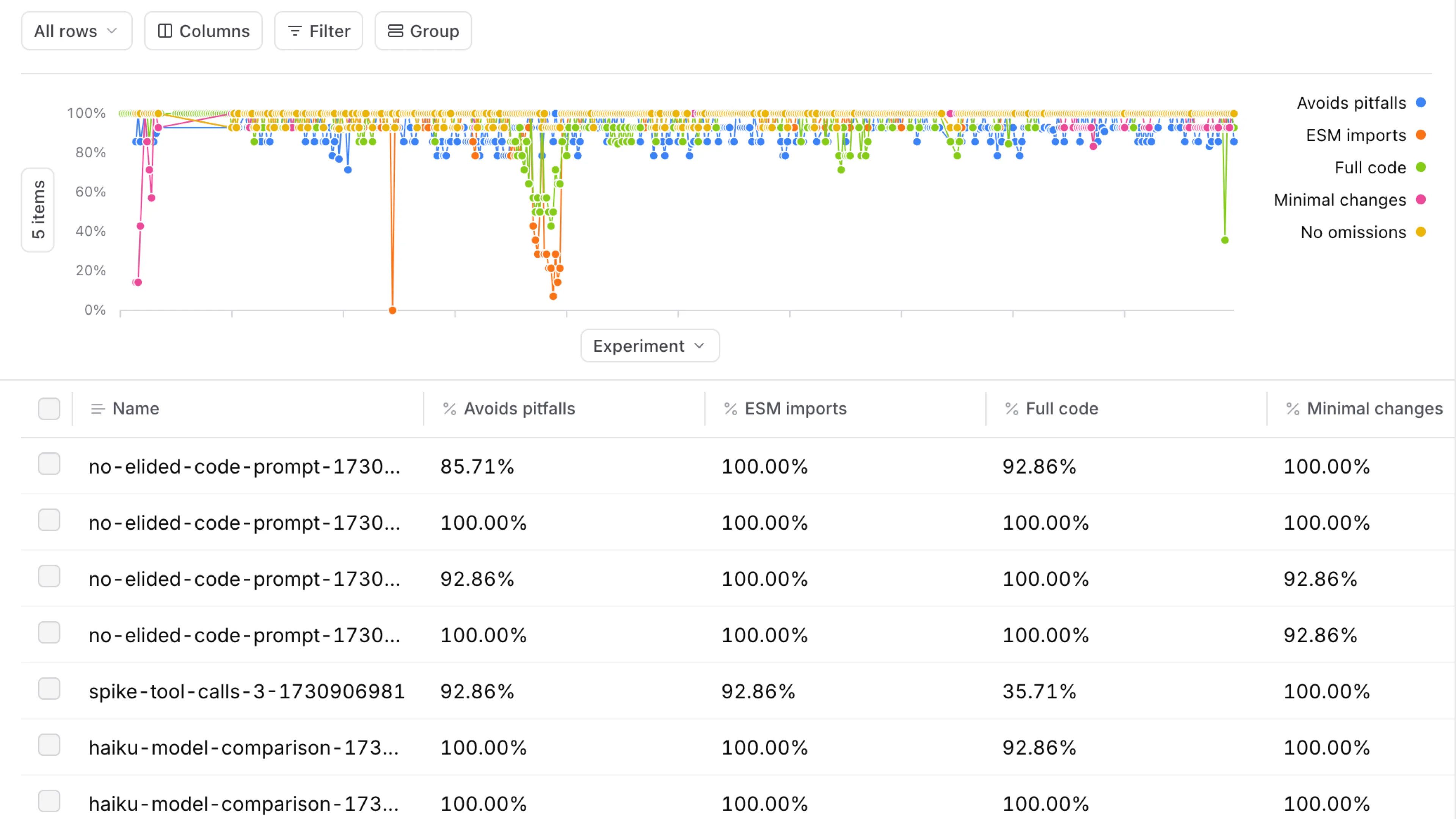
Here’s our progress with Braintrust over time. We https://blog.val.townhttps://blog.val.town/_astro/slide-28.gj7oRaum_dznIJ.webpat we want to forbid from our outputs: things like using require() instead of import, using the alert() method, or omitting code from results. Some evals rely on simple string matching, while ohttps://blog.val.townhttps://blog.val.town/_astro/slide-34.yCiX_02N_Z5izhK.webpsults from the “smart” LLM.
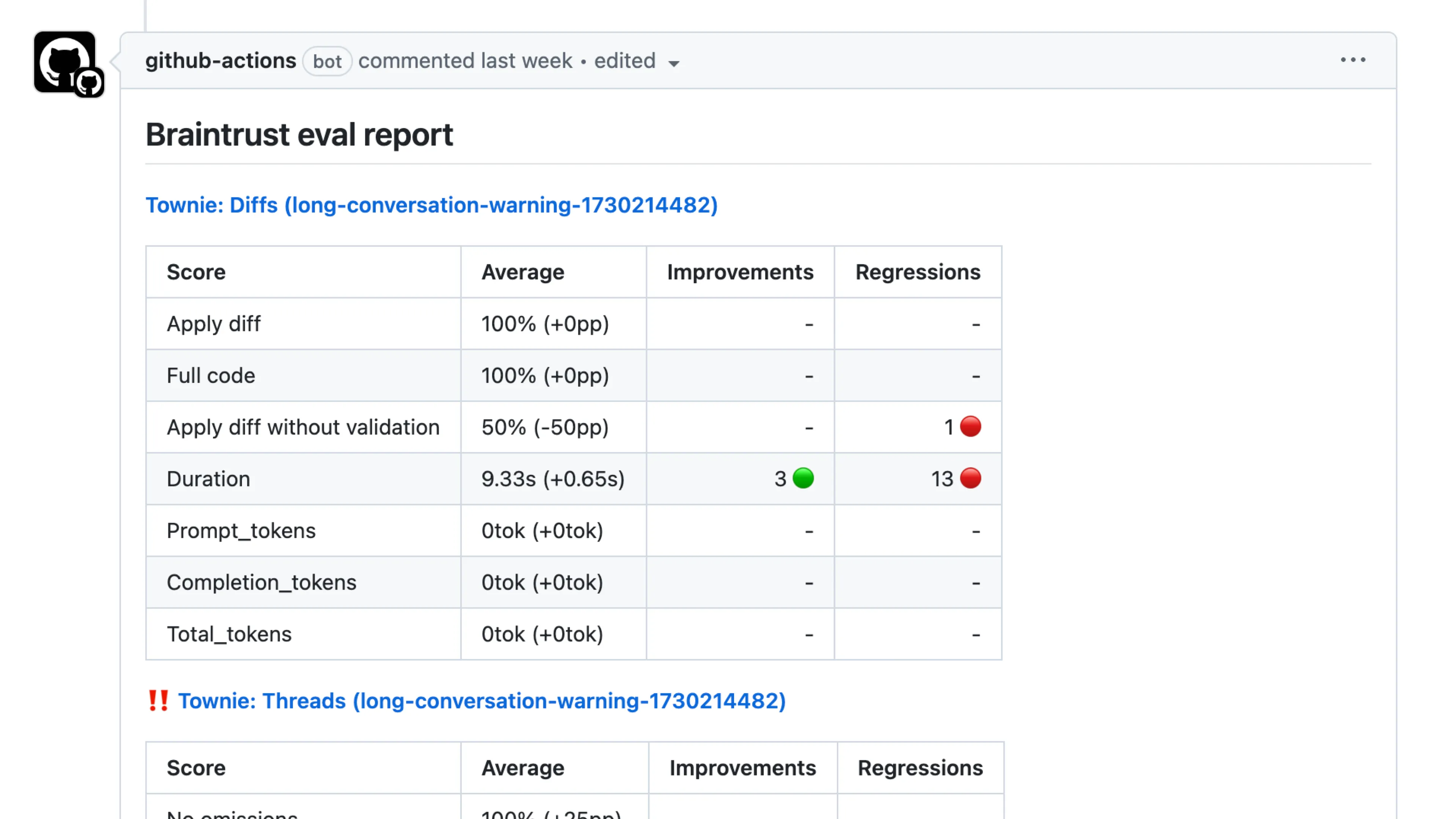
Braintrust gives us notifications on each Pull Request, letting us know whether a given system prompt change is a regression or improvement in quality.
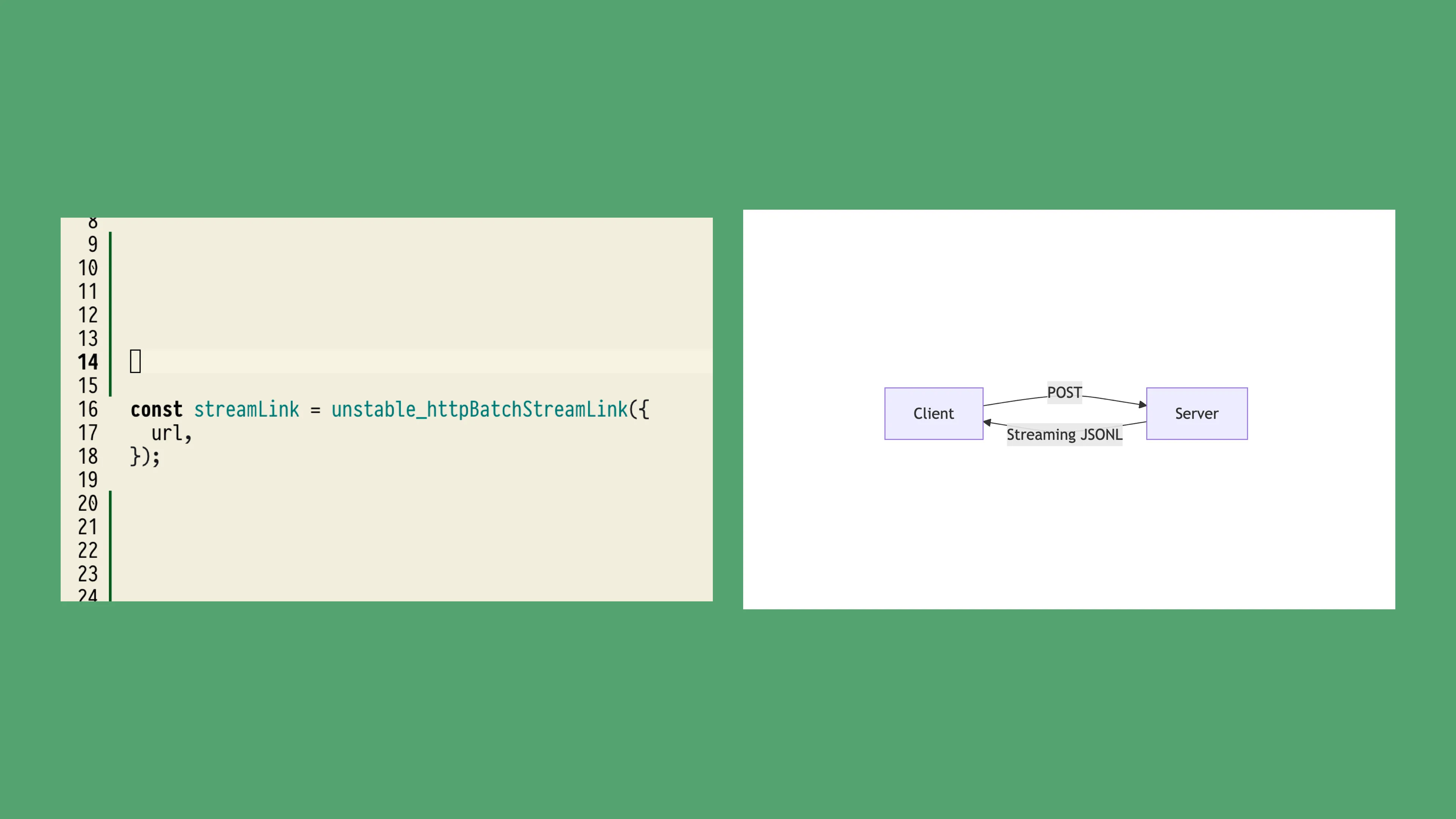
The final challenge of Townie is simply implementing the UI, which is anything but simple. We’ve found a nice middle ground between an overly traditional request/response flow and a fully real-time, streaming, WebSocket-based infrastructure. We’re using tRPC’s Batch Stream Link, which pairs traditional POST requests with streaming responses. It gives us the nice type-safety of tRPC and lets us structure our responses using Async Generators on the server-side.
That’s it! Thanks for following along.
Edit this page