
Published on September 30, 2025 11:53 AM GMT
OpenAI's new GDPval benchmark measures AI capabilities on real-world tasks from the sectors contributing most to the U.S. GDP. Given a task on GDPval, a human industry expert compares the model deliverable to a deliverable by industry experts and chooses the preferred one. Model performances are thus reported as win rates.

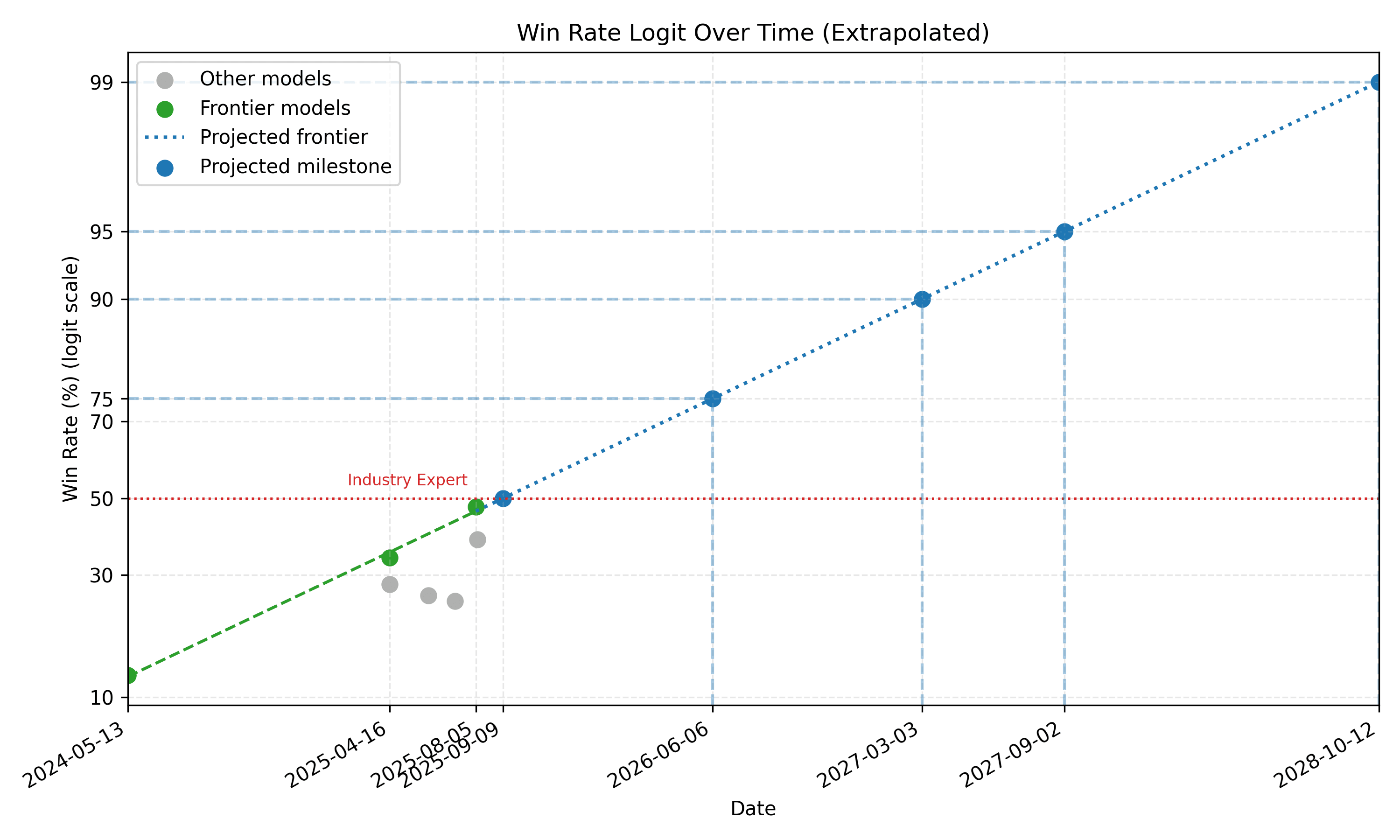
In the spirit of METR's task horizon study, here is a plot on the model performances from GDPval against model release dates.

The plot above uses a logit scale. Other scales can be found in the appendix below. Since only the best models concern us, the regression only uses models that outperforms previous models, labelled as the green "Frontier models" in the plot. There are only three datapoints, so this extrapolation is highly uncertain even if the $R^2$ is high.
Under this regression, a hypothetical model release today would have already outperformed an industry expert in an average task in GDPval. By mid-2026, human experts would prefer AI deliverables 75% of the time. By late-2027, human experts would prefer AI deliverables 95% of the time.
On job loss: GDPval contains tasks that are currently economically-useful. The usual argument holds: there could be novel tasks in the future that are economically-useful and that models do not perform well in.
The more interesting point is that most of the current U.S. GDP could be automated as early as 2027.
Thanks to Nikola Jurkovic for helpful comments.
Appendix
Repo Link
Next Steps
Fill in the data gap between GPT-4o and o3-high. This will involve running Sonnets 3.5, 3.7, 4, and possibly o1, on GDPval. Evaluate Sonnet 4.5, which is forecasted to score above 50%.
Extra Plots
Extrapolated dates
Raw win rate on the y-axis

Log win rate on the y-axis

Odds on the y-axis

Table of Extrapolated Dates
The table here includes results from regressing on all models reported in the paper, and not just the frontier ones.
Discuss
