It's the most wonderful time of the year. Of course, I'm not talking about Christmas but re:Invent. It is re:Inventtime.
photo from the keynote by Andy Jassy, rights belong to Amazon
In the opening keynote, Andy Jassy presented the AWS Lambda Container Support, which allows us to use custom container(docker) images up to 10GB as a runtime for AWS Lambda. With that, we can build runtimes larger than the previous 250 MBlimit, be it for "State-of-the-Art" NLP APIs with BERT or complex processing.
For those who are not that familiar with BERT was published in 2018 by Google and stands forBidirectional Encoder Representations from Transformers and is designed to learn word representations or embeddings froman unlabeled text by jointly conditioning on both left and right context. Transformers are since that the"State-of-the-Art" Architecture https://www.philschmid.de/static/blog/serverless-bert-with-huggingface-aws-lambda-docker/bert-context.pnga-docker/bert-context.png" alt="bert-context">
We are going to use the newest cutting edge computing power of AWS with the benefits of serverless architectures toleverage Google's "State-of-the-Art" NLP Model.
We deploy a BERT Question-Answering API in a serverless AWS Lambda environment. Therefore we use theTransformers library by HuggingFace,the Serverless Framework, AWS Lambda, and Amazon ECR.
The Transformers library provides state-of-the-art machine learningarchitectures like BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet, T5 for Natural Language Understanding (NLU) and NaturalLanguage Generation (NLG). It also provides thousands of pre-trained models in 100+ different languages.
AWS Lambda
AWS Lambda is a serverless computing service that lets yourun code without managing servers. It executes your code only when required and scales automatically, from a fewrequests per day to thousands per second.
Amazon Elastic Container Registry
Amazon Elastic Container Registry (ECR) is a fully managed container registry.It allows us to store, manage, share docker container images. You can share docker containers privately within yourorganization or publicly worldwide for anyone.
Serverless Framework
The Serverless Framework helps us develop and deploy AWS Lambda functions. It’s a CLIthat offers structure, automation, and best practices right out of the box.
Before we get started, make sure you have the Serverless Framework configured and set up. Youalso need a working docker environment. We use docker to create our own custom image including all needed Pythondependencies and our BERT model, which we then use in our AWS Lambda function. Furthermore, you need access to an AWSAccount to create an IAM User, an ECR Registry, an API Gateway, and the AWS Lambda function.
We design the API like that we send a context (small paragraph) and a question to it and respond with the answer to thequestion.
context = """We introduce a new language representation model called BERT, which stands forBidirectional Encoder Representations from Transformers. Unlike recent languagerepresentation models (Peters et al., 2018a; Radford et al., 2018), BERT isdesigned to pretrain deep bidirectional representations from unlabeled text byjointly conditioning on both left and right context in all layers. As a result,the pre-trained BERT model can be finetuned with just one additional outputlayer to create state-of-the-art models for a wide range of tasks, such asquestion answering and language inference, without substantial taskspecificarchitecture modifications. BERT is conceptually simple and empiricallypowerful. It obtains new state-of-the-art results on eleven natural languageprocessing tasks, including pushing the GLUE score to 80.5% (7.7% point absoluteimprovement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuADv2.0 Test F1 to 83.1 (5.1 point absolute improvement)."""question_one = "What is BERTs best score on Squadv2 ?"# 83 . 1question_two = "What does the 'B' in BERT stand for?"# 'bidirectional encoder representations from transformers'
What are we going to do:
create a Python Lambda function with the Serverless Framework.add the BERTmodel to our function and create an inference pipeline.Create a custom docker imageTest our function locally with LRIEDeploy a custom docker image to ECRDeploy AWS Lambda function with a custom docker imageTest our Serverless BERT API
This CLI command will create a new directory containing a handler.py, .gitignore, and serverless.yaml file. Thehandler.py contains some basic boilerplate code.
import jsondef hello(event, context): body = { "message": "Go Serverless v1.0! Your function executed successfully!", "input": event } response = { "statusCode": 200, "body": json.dumps(body) } return response
Add the BERTmodel to our function and create an inference pipeline.
To add our BERT model to our function we have to load it from themodel hub of HuggingFace. For this, I have created a python script. Before we canexecute this script we have to install the transformers library to our local environment and create a modeldirectory in our serverless-bert/ directory.
mkdir model & pip3 install torch==1.5.0 transformers==3.4.0
After we installed transformers we create get_model.py file in the function/ directory and include the scriptbelow.
from transformers import AutoModelForQuestionAnswering, AutoTokenizerdef get_model(model): """Loads model from Hugginface model hub""" try: model = AutoModelForQuestionAnswering.from_pretrained(model,use_cdn=True) model.save_pretrained('./model') except Exception as e: raise(e)def get_tokenizer(tokenizer): """Loads tokenizer from Hugginface model hub""" try: tokenizer = AutoTokenizer.from_pretrained(tokenizer) tokenizer.save_pretrained('./model') except Exception as e: raise(e)get_model('mrm8488/mobilebert-uncased-finetuned-squadv2')get_tokenizer('mrm8488/mobilebert-uncased-finetuned-squadv2')
To execute the script we run python3 get_model.py in the serverless-bert/ directory.
Tip: add the model directory to gitignore.
The next step is to adjust our handler.py and include our serverless_pipeline(), which initializes our model andtokenizer and returns a predict function, we can use in our handler.
import jsonimport torchfrom transformers import AutoModelForQuestionAnswering, AutoTokenizer, AutoConfigdef encode(tokenizer, question, context): """encodes the question and context with a given tokenizer""" encoded = tokenizer.encode_plus(question, context) return encoded["input_ids"], encoded["attention_mask"]def decode(tokenizer, token): """decodes the tokens to the answer with a given tokenizer""" answer_tokens = tokenizer.convert_ids_to_tokens( token, skip_special_tokens=True) return tokenizer.convert_tokens_to_string(answer_tokens)def serverless_pipeline(model_path='./model'): """Initializes the model and tokenzier and returns a predict function that ca be used as pipeline""" tokenizer = AutoTokenizer.from_pretrained(model_path) model = AutoModelForQuestionAnswering.from_pretrained(model_path) def predict(question, context): """predicts the answer on an given question and context. Uses encode and decode method from above""" input_ids, attention_mask = encode(tokenizer,question, context) start_scores, end_scores = model(torch.tensor( [input_ids]), attention_mask=torch.tensor([attention_mask])) ans_tokens = input_ids[torch.argmax( start_scores): torch.argmax(end_scores)+1] answer = decode(tokenizer,ans_tokens) return answer return predict# initializes the pipelinequestion_answering_pipeline = serverless_pipeline()def handler(event, context): try: # loads the incoming event into a dictonary body = json.loads(event['body']) # uses the pipeline to predict the answer answer = question_answering_pipeline(question=body['question'], context=body['context']) return { "statusCode": 200, "headers": { 'Content-Type': 'application/json', 'Access-Control-Allow-Origin': '*', "Access-Control-Allow-Credentials": True }, "body": json.dumps({'answer': answer}) } except Exception as e: print(repr(e)) return { "statusCode": 500, "headers": { 'Content-Type': 'application/json', 'Access-Control-Allow-Origin': '*', "Access-Control-Allow-Credentials": True }, "body": json.dumps({"error": repr(e)}) }
Create a custom docker image
Before we can create our docker we need to create a requirements.txt file with all the dependencies we want toinstall in our docker.
We are going to use a lighter Pytorch Version and the transformers library.
To containerize our Lambda Function, we create a dockerfile in the same directory and copy the following content.
FROM public.ecr.aws/lambda/python:3.8# Copy function code and models into our /var/taskCOPY ./ ${LAMBDA_TASK_ROOT}/# install our dependenciesRUN python3 -m pip install -r requirements.txt --target ${LAMBDA_TASK_ROOT}# Set the CMD to your handler (could also be done as a parameter override outside of the Dockerfile)CMD [ "handler.handler" ]
Additionally we can add a .dockerignore file to exclude files from your container image.
AWS also released the Lambda Runtime Interface Emulatorthat enables us to perform local testing of the container image and check that it will run when deployed to Lambda.
We can start our docker by running.
docker run -p 8080:8080 bert-lambda
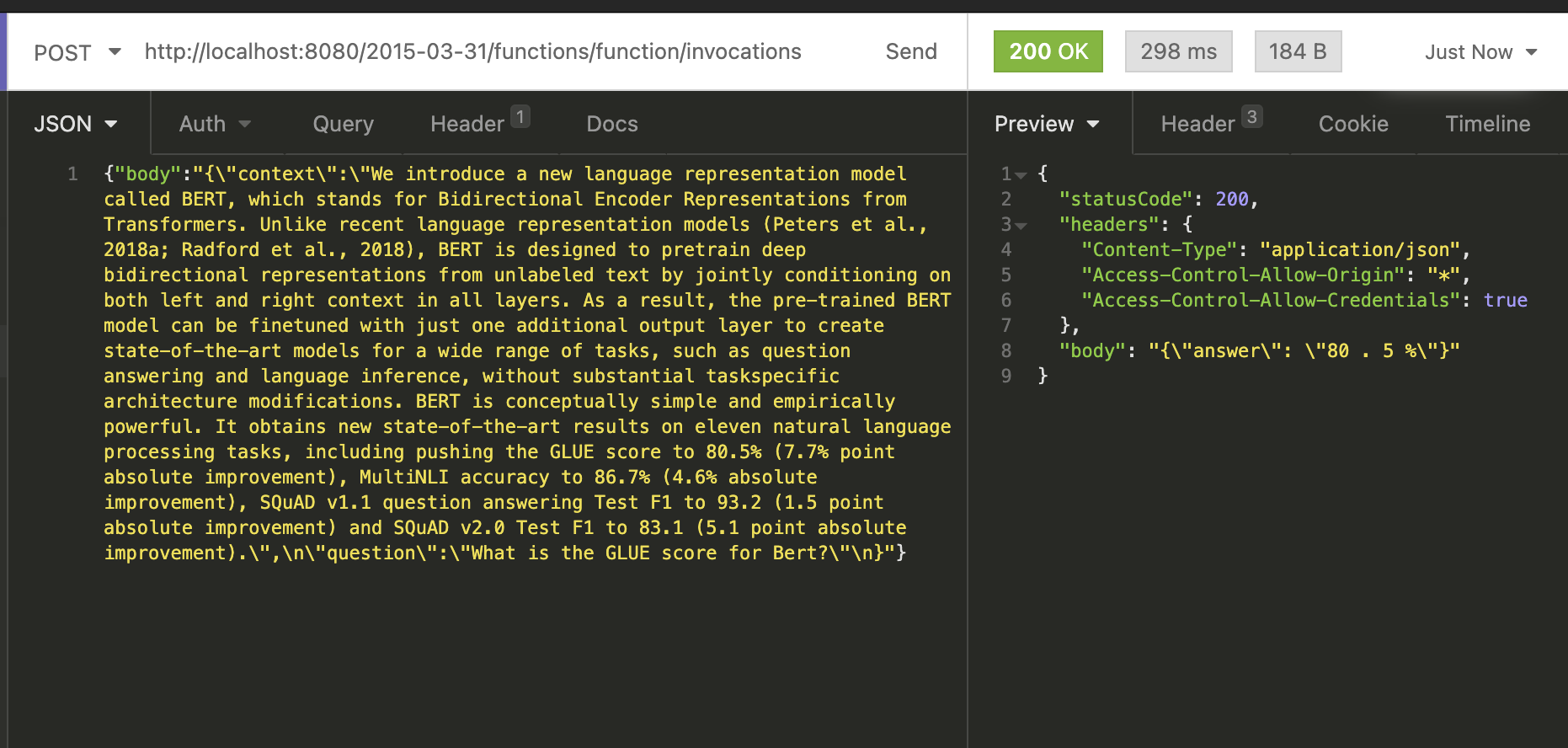
Afterwards, in a separate terminal, we can then locally invoke the function using curl or a REST-Client.
curl --request POST \ --url http://localhost:8080/2015-03-31/functions/function/invocations \ --header 'Content-Type: application/json' \ --data '{"body":"{\"context\":\"We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers. Unlike recent language representation models (Peters et al., 2018a; Radford et al., 2018), BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).\",\n\"question\":\"What is the GLUE score for Bert?\"\n}"}'# {"statusCode": 200, "headers": {"Content-Type": "application/json", "Access-Control-Allow-Origin": "*", "Access-Control-Allow-Credentials": true}, "body": "{\"answer\": \"80 . 5 %\"}"}%
Beware we have to stringify
Deploy a custom docker image to ECR
Since we now have a local docker image we can deploy this to ECR. Therefore we need to create an ECR repository withthe name bert-lambda.
To be able to push our images we need to login to ECR. We are using the aws CLI v2.x. Therefore we need to define someenvironment variables to make deploying easier.
Next we need to tag / rename our previously created image to an ECR format. The format for this is{AccountID}.dkr.ecr.{region}.amazonaws.com/{repository-name}
docker tag bert-lambda $aws_account_id.dkr.ecr.$aws_region.amazonaws.com/bert-lambda
https://www.philschmid.dehttps://www.philschmid.de/static/blog/serverless-bert-with-huggingface-aws-lambda-docker/docker-image.png image with our tag as name
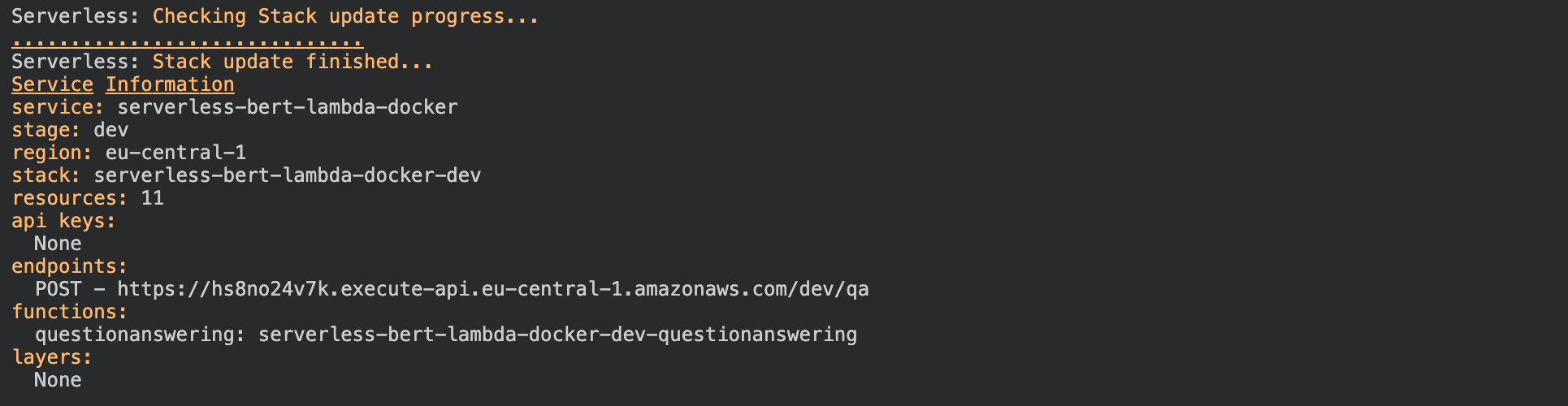
Deploy AWS Lambda function with a custom docker image
I provide the complete serverless.yaml for this example, but we go through all the details we need for our dockerimage and leave out all standard configurations. If you want to learn more about the serverless.yaml, I suggest youcheck outScaling Machine Learning from ZERO to HERO. Inthis article, I went through each configuration and explain the usage of them.
service: serverless-bert-lambda-dockerprovider: name: aws # provider region: eu-central-1 # aws region memorySize: 5120 # optional, in MB, default is 1024 timeout: 30 # optional, in seconds, default is 6functions: questionanswering: image: 891511646143.dkr.ecr.eu-central-1.amazonaws.com/bert-lambda:latest #ecr url events: - http: path: qa # http path method: post # http method
To use a docker image in our serverlss.yaml we have to image and in our function section. The image has theURL to our docker image also value.
For an ECR image, the URL should look like this {AccountID}.dkr.ecr.{region}.amazonaws.com/{repository-name}@{digest}
In order to deploy the function, we run serverless dephttps://www.philschmid.dehttps://www.philschmid.de/static/blog/serverless-bert-with-huggingface-aws-lambda-docker/serverless-deploy.pngcess is done we should see something like this.
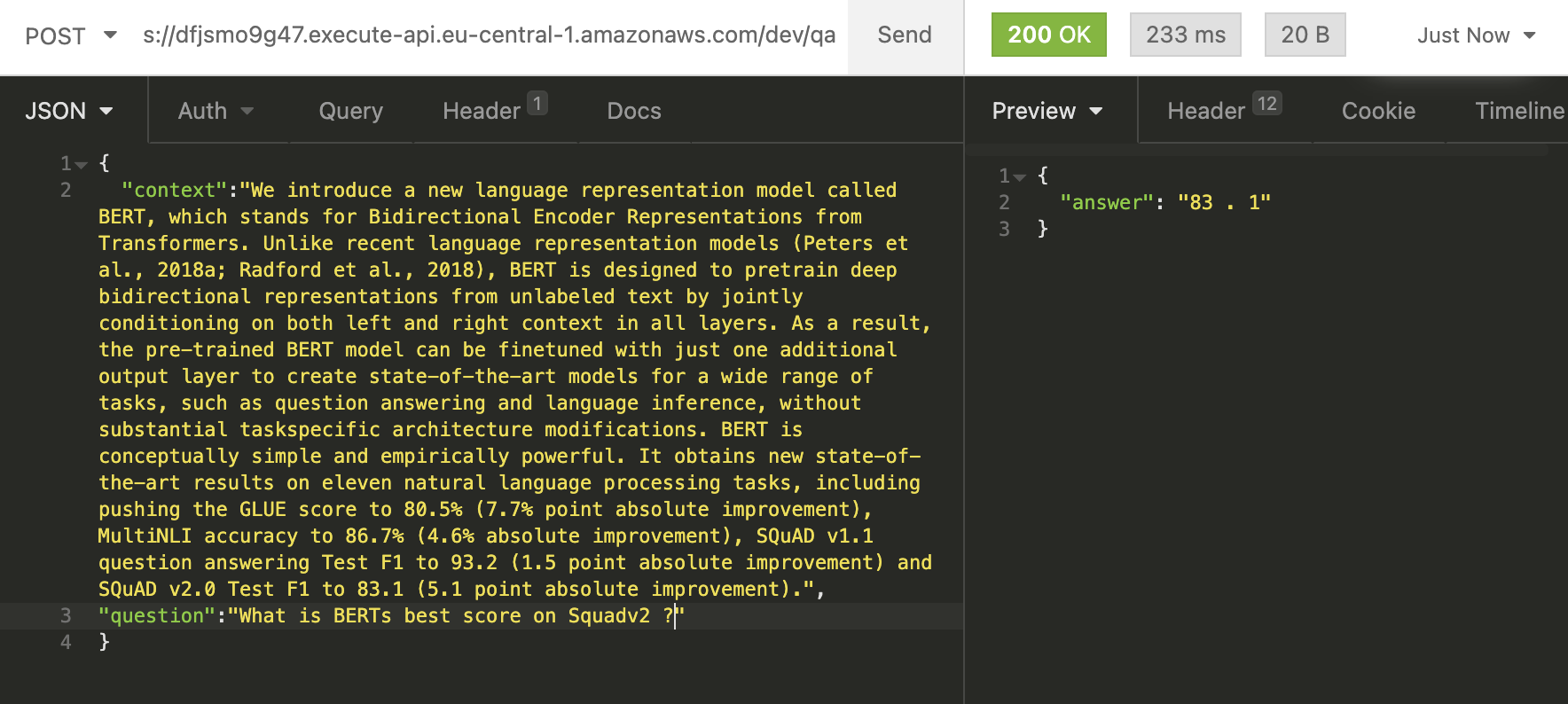
Test our Serverless BERT API
To test our Lambda function we can use Insomnia, Postman, or any other REST client. Just add a JSON with a context anda question to the body of your request. Let´s try it with our example from the colab notebook.
{ "context": "We introduce a new language representation model called BERT, which stands for idirectional Encoder Representations from Transformers. Unlike recent language epresentation models (Peters et al., 2018a; Radford et al., 2018), BERT is designed to pretrain deep bidirectional representations from unlabeled text by jointly conditioning on both left and right context in all layers. As a result, the pre-trained BERT model can be finetuned with just one additional output layer to create state-of-the-art models for a wide range of tasks, such as question answering and language inference, without substantial taskspecific architecture modifications. BERT is conceptually simple and empirically powerful. It obtains new state-of-the-art results on eleven natural language processing tasks, including pushing the GLUE score to 80.5% (7.7% point absolute improvement), MultiNLI accuracy to 86.7% (4.6% absolute improvement), SQuAD v1.1 question answering Test F1 to 93.2 (1.5 point absolute improvement) and SQuAD v2.0 Test F1 to 83.1 (5.1 point absolute improvement).", "question": "What is BERTs best score on Squadv2 ?" answered our question correctly with 83.1.
The first request after we deployed our docker based Lambda function took 27,8s. The reason is that AWS apparentlysaves the docker container somewhere on the first initial call to provide it suitably.
I waited extra more than 15 minutes and tested it again. The cold start now took 6,7s and a warm request around 220ms
Conclusion
The release of the AWS Lambda Container Support enables much wider use of AWS Lambda and Serverless. It fixes manyexisting problems and gives us greater scope for the deployment of serverless applications.
We were able to deploy a "State-of-the-Art" NLP model without the need to manage any server. It will automatically scaleup to thousands of parallel requests without any worries. The increase of configurable Memory and vCPUs boosts this coldstart even more.
The future looks more than golden for AWS Lambda and Serverless.