
FLAN-T5, released with the Scaling Instruction-Finetuned Language Models paper, is an enhanced version of T5 that has been fine-tuned in a mixture of tasks, or simple words, a better T5 model in any aspect. FLAN-T5 outperforms T5 by double-digit improvements for the same number of parameters. Google has open sourced 5 checkpoints available on Hugging Face ranging from 80M parameter up to 11B parameter.
In a previous blog post, we already learned how to “Fine-tune FLAN-T5 for chat & dialogue summarization” using the base version (250M parameter) of the model. In this blog post, we look into how we can scale the training from the Base version to the XL (3B) or XXL (11B).
This means we will learn how to fine-tune FLAN-T5 XL & XXL using model parallelism, multiple GPUs, and DeepSpeed ZeRO.
You will learn about the following:
in addition to the tutorial, we have run a series of experiments to help you choose the right hardware setup. You can find the details in the Results & Experiments section.
Let's get started! 🚀
1. What is DeepSpeed ZeRO?
DeepSpeed ZeRO is part of the DeepSpeed Training Pillar, which focus on efficient large-scale Training of Transformer models. DeepSpeed ZeRO or Zero Redundancy Optimizer is a method to reduce the memory footprint. Compared to basic data parallelism, ZeRO partitions optimizer states, gradients, and model parameters to save significant memory across multiple devices.
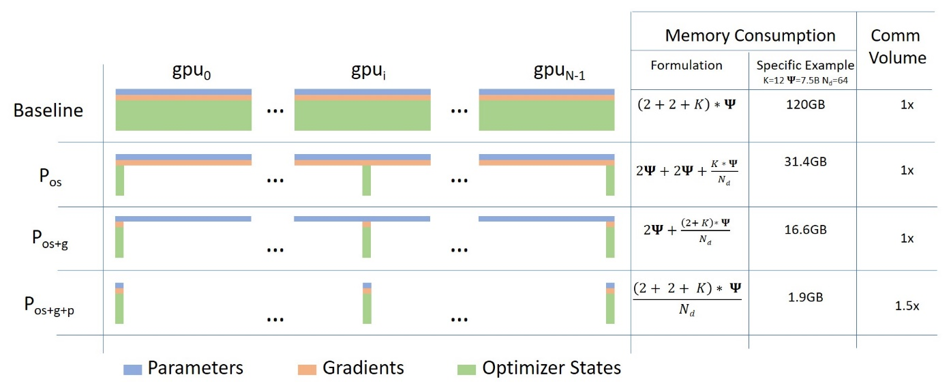
If you want to learn more about DeepSpeed ZeRO, checkout: ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters
DeepSpeed ZeRO is natively integrated into the Hugging Face Transformers Trainer. The integration enables leveraging ZeRO by simply providing a DeepSpeed config file, and the Trainer takes care of the rest.
Excerpt: DeepSpeed ZeRO-offload
DeepSpeed ZeRO not only allows us to parallelize our models on multiple GPUs, it also implements Offloading. ZeRO-Offload implements optimizations that offload optimizer and model to the CPU to train larger models on the given GPUs, e.g. 10B parameter GPT-2 on a single V100 GPU. We used ZeRO-offload for the experiments but will not use it in the tutorial.
2. Fine-tune FLAN-T5-XXL using Deepspeed
We now know that we can use DeepSpeed ZeRO together with Hugging Face Transformers to easily scale our hardware in cases where the model no longer fits on GPU. That's exactly what we need to solve since the FLAN-T5-XXL weights in fp32 are already 44GB big. This makes it almost impossible to fit on a single GPU when adding activations and optimizer states.
In this tutorial, we cover how to fine-tune FLAN-T5-XXL (11B version) on the CNN Dailymail Dataset for news summarization. The provided script and pre-processing can easily be adjusted to fine-tune FLAN-T5-XL and use a different dataset.
Note: This tutorial was created and run on a p4dn.24xlarge AWS EC2 Instance including 8x NVIDIA A100 40GB.
Setup Development Environment
The first step is to install the Hugging Face Libraries, including transformers and datasets, and DeepSeed. Running the following cell will install all the required packages.
# install torch with the correct cuda version, check nvcc --versionpip install torch --extra-index-url https://download.pytorch.org/whl/cu116 --upgrade# install Hugging Face Librariespip install "transformers==4.26.0" "datasets==2.9.0" "accelerate==0.16.0" "evaluate==0.4.0" --upgrade# install deepspeed and ninja for jit compilations of kernelspip install "deepspeed==0.8.0" ninja --upgrade# install additional dependencies needed for trainingpip install rouge-score nltk py7zr tensorboardLoad and prepare dataset
Similar to the “Fine-tune FLAN-T5 for chat & dialogue summarization” we need to prepare a dataset to fine-tune our model. As mentioned in the beginning, we will fine-tune FLAN-T5-XXL on the CNN Dailymail Dataset. The blog post is not going into detail about the dataset generation. If you want to learn the detailed steps check out the previous post.
We define some parameters, which we use throughout the whole example, feel free to adjust it to your needs.
# experiment configmodel_id = "google/flan-t5-xxl" # Hugging Face Model Iddataset_id = "cnn_dailymail" # Hugging Face Dataset Iddataset_config = "3.0.0" # config/verison of the datasetsave_dataset_path = "data" # local path to save processed datasettext_column = "article" # column of input text issummary_column = "highlights" # column of the output text# custom instruct prompt startprompt_template = f"Summarize the following news article:\n{{input}}\nSummary:\n"Compared to the previous example, we are splitting the processing and training into two separate paths. This allows you to run the preprocessing outside of the GPU instance. We process (tokenize) the dataset and save it to disk and then load in our train script from disk again.
from datasets import load_datasetfrom transformers import AutoTokenizerimport numpy as np # Load dataset from the hubdataset = load_dataset(dataset_id,name=dataset_config)# Load tokenizer of FLAN-t5-basetokenizer = AutoTokenizer.from_pretrained(model_id) print(f"Train dataset size: {len(dataset['train'])}")print(f"Test dataset size: {len(dataset['test'])}") # Train dataset size: 287113# Test dataset size: 11490We defined a prompt_template in our config, which we will use to construct an instruct prompt for better performance of our model. Our prompt_template has a “fixed” start and end, and our document is in the middle. This means we need to ensure that the “fixed” template parts + document are not exceeding the max length of the model. Therefore we calculate the max length of our document, which we will later use for padding and truncation
prompt_lenght = len(tokenizer(prompt_template.format(input=""))["input_ids"])max_sample_length = tokenizer.model_max_length - prompt_lenghtprint(f"Prompt length: {prompt_lenght}")print(f"Max input length: {max_sample_length}") # Prompt length: 12# Max input length: 500We know now that our documents can be “500” tokens long to fit our template_prompt still correctly. In addition to our input, we need to understand better our “target” sequence length meaning and how long are the summarization ins our dataset. Therefore we iterate over the dataset and calculate the max input length (at max 500) and the max target length. (takes a few minutes)
from datasets import concatenate_datasetsimport numpy as np # The maximum total input sequence length after tokenization.# Sequences longer than this will be truncated, sequences shorter will be padded.tokenized_inputs = concatenate_datasets([dataset["train"], dataset["test"]]).map(lambda x: tokenizer(x[text_column], truncation=True), batched=True, remove_columns=[text_column, summary_column])max_source_length = max([len(x) for x in tokenized_inputs["input_ids"]])max_source_length = min(max_source_length, max_sample_length)print(f"Max source length: {max_source_length}") # The maximum total sequence length for target text after tokenization.# Sequences longer than this will be truncated, sequences shorter will be padded."tokenized_targets = concatenate_datasets([dataset["train"], dataset["test"]]).map(lambda x: tokenizer(x[summary_column], truncation=True), batched=True, remove_columns=[text_column, summary_column])target_lenghts = [len(x) for x in tokenized_targets["input_ids"]]# use 95th percentile as max target lengthmax_target_length = int(np.percentile(target_lenghts, 95))print(f"Max target length: {max_target_length}")We now have everything needed to process our dataset.
import os def preprocess_function(sample, padding="max_length"): # created prompted input inputs = [prompt_template.format(input=item) for item in sample[text_column]] # tokenize inputs model_inputs = tokenizer(inputs, max_length=max_source_length, padding=padding, truncation=True) # Tokenize targets with the `text_target` keyword argument labels = tokenizer(text_target=sample[summary_column], max_length=max_target_length, padding=padding, truncation=True) # If we are padding here, replace all tokenizer.pad_token_id in the labels by -100 when we want to ignore # padding in the loss. if padding == "max_length": labels["input_ids"] = [ [(l if l != tokenizer.pad_token_id else -100) for l in label] for label in labels["input_ids"] ] model_inputs["labels"] = labels["input_ids"] return model_inputs # process datasettokenized_dataset = dataset.map(preprocess_function, batched=True, remove_columns=list(dataset["train"].features)) # save dataset to disktokenized_dataset["train"].save_to_disk(os.path.join(save_dataset_path,"train"))tokenized_dataset["test"].save_to_disk(os.path.join(save_dataset_path,"eval"))Fine-tune model using deepspeed
Done! We can now start training our model! We learned in the introduction that we would leverage the DeepSpeed integration with the Hugging Face Trainer. Therefore we need to create a deespeed_config.json. In the DeepSpeed Configuration, we define the ZeRO strategy we want to use and if we want to use mixed precision training. The Hugging Face Trainer allows us to inherit values from the TrainingArguments in our deepspeed_config.json to avoid duplicate values, check the documentation for more information.
We created 4 deepspeed configurations for the experiments we ran, including CPU offloading and mixed precision:
Depending on your setup, you can use those, e.g. if you are running on NVIDIA V100s, you have to use the config without bf16 since V100 are not support bfloat16 types.
When fine-tuning
T5models we cannot usefp16since it leads to overflow issues, see: #4586, #10830, #10956
As mentioned in the beginning, we are using a p4dn.24xlarge AWS EC2 Instance including 8x NVIDIA A100 40GB. This means we can leverage bf16, which reduces the memory footprint of the model by almost ~2x, which allows us to train without offloading efficiently.
We are going to use the ds_flan_t5_z3_config_bf16.json. If you are irritated by the auto values, check the documentation.
{ "bf16": { "enabled": "auto" }, "optimizer": { "type": "AdamW", "params": { "lr": "auto", "betas": "auto", "eps": "auto", "weight_decay": "auto" } }, "scheduler": { "type": "WarmupLR", "params": { "warmup_min_lr": "auto", "warmup_max_lr": "auto", "warmup_num_steps": "auto" } }, "zero_optimization": { "stage": 3, "overlap_comm": true, "contiguous_gradients": true, "sub_group_size": 1e9, "reduce_bucket_size": "auto", "stage3_prefetch_bucket_size": "auto", "stage3_param_persistence_threshold": "auto", "stage3_max_live_parameters": 1e9, "stage3_max_reuse_distance": 1e9, "stage3_gather_16bit_weights_on_model_save": false }, "gradient_accumulation_steps": "auto", "gradient_clipping": "auto", "steps_per_print": 2000, "train_batch_size": "auto", "train_micro_batch_size_per_gpu": "auto", "wall_clock_breakdown": false}Now, we need our training script. We prepared a run_seq2seq_deepspeed.py training script based on the previous blog post, which supports our deepspeed config and all other hyperparameters.
We can start our training with the deepspeed launcher providing the number of GPUs, the deepspeed config, and our hyperparameters, including our model id for google/flan-t5-xxl.
deepspeed --num_gpus=8 scripts/run_seq2seq_deepspeed.py \ --model_id google/flan-t5-xxl \ --dataset_path data \ --epochs 3 \ --per_device_train_batch_size 8 \ --per_device_eval_batch_size 8 \ --generation_max_length 129 \ --lr 1e-4 \ --deepspeed configs/ds_flan_t5_z3_config_bf16.jsonDeepspeed now loads our model on the CPU and then splits it across our 8x A100 and starts the training. The training using the CNN Dailymail Dataset takes roughly 10 hours and costs ~$322
3. Results & Experiments
During the creation of the tutorial and to get a better understanding of the hardware requirements, we ran a series of experiments for FLAN-T5 XL & XXL, which should help us evaluate and understand the hardware requirements and cost of training those models.We ran the experiments only for ~20% of the training without evaluation and calculated the duration based on this estimate.
Below you'll find a table of the experiments and more information about the setup.
Dataset: CNN Dailymail Dataset with a train dataset size of 287113 samples with a sequence length of 512
Hyperparameters: Epoch 3
Setup and instance types:
- 4x V100 16GB: p3.8xlarge4x A10G 24GB: g5.24xlarge8x V100 16GB: p3.16xlarge8x A100 40GB: p4dn.24xlarge
| Model | DS ZeRO offload | Hardware | batch size per GPU | precision | duration | cost |
|---|---|---|---|---|---|---|
| FLAN-T5-XL (3B) | No | 4x V100 16GB | OOM | fp32 | - | - |
| FLAN-T5-XL (3B) | No | 8x V100 16GB | 1 | fp32 | 105h | ~$2570 |
| FLAN-T5-XL (3B) | No | 8x A100 40GB | 72 | bf16 | 2,5h | ~$81 |
| FLAN-T5-XL (3B) | Yes | 4x V100 16GB | 8 | fp32 | 69h | ~$828 |
| FLAN-T5-XL (3B) | Yes | 8x V100 16GB | 8 | fp32 | 32h | ~$768 |
| FLAN-T5-XXL (11B) | Yes | 4x V100 16GB | OOM | fp32 | - | - |
| FLAN-T5-XXL (11B) | Yes | 8x V100 16GB | OOM | fp32 | - | - |
| FLAN-T5-XXL (11B) | Yes | 4x A10G 24GB | 24 | bf16 | 90h | ~$732 |
| FLAN-T5-XXL (11B) | Yes | 8x A100 40GB | 48 | bf16 | 19h | ~$613 |
| FLAN-T5-XXL (11B) | No | 8x A100 40GB | 8 | bf16 | 10h | ~$322 |
We can see that bf16 provides significant advantages over fp32. We could fit FLAN-T5-XXL on 4x A10G (24GB) but not on 8x V100 16GB.
We also learned that if the model fits on the GPUs with a batch size > 4 without offloading, we are ~2x faster and more cost-effective than offloading the model and scaling the batch size.
Thanks for reading! If you have any questions, feel free to contact me on Twitter or LinkedIn.
