
To learn how to build more maintainable and usable Python libraries, I’ve been reading some of the most widely used Python packages. Along the way, I learned some things about Python that are off the beaten path. Here are a few things I didn’t know before.
Using super() in base classes
Python’s super() lets us inherit base classes (aka super or parent classes) without having to explicitly refer to the base class. It’s usually used in the __init__ method. While this might be simply a nice-to-have in single inheritance, multiple inheritance is almost impossible without super().
However, one interesting use of super() is calling it in the base class. I find noticed this in requests’ BaseAdapter.
class BaseAdapter: """The Base Transport Adapter""" def __init__(self): super().__init__() def send(self, request, stream=False, timeout=None, verify=True, cert=None, proxies=None):Given that the base class doesn’t inherit from anything, why call super() in it?
After a bit of digging, here’s what I learned: Using super() in the base class allows for cooperative multiple inheritance. Without it, the __init__ calls of parent classes—after a non-supered class—are skipped. Here’s an example with a base class (BaseEstimator) and mixin (ServingMixin), both of which will be inherited by our DecisionTree class.
First, we have a BaseEstimator that doesn’t call super() in its __init__ method. It has a basic __repr__ method to print attributes.
class BaseEstimator: def __init__(self, name, **kwargs): self.name = name def __repr__(self): return f', '.join(f'{k}: {v}' for k, v in vars(self).items())Next, we inherit BaseEstimator via the DecisionTree subclass. Everything works fine—printing the DecisionTree instance shows the attributes of BaseEstimator and DecisionTree.
class DecisionTree(BaseEstimator): def __init__(self, depth, **kwargs): super().__init__(**kwargs) self.depth = depthdt = DecisionTree(name='DT', depth=1)print(dt)> name: DT, depth: 1Now, let’s also inherit ServingMixin and create an instance of DecisionTree.
class ServingMixin: def __init__(self, mode, **kwargs): super().__init__(**kwargs) self.mode = modeclass DecisionTree(BaseEstimator, ServingMixin): def __init__(self, depth, **kwargs): super().__init__(**kwargs) self.depth = depthdt = DecisionTree(name='Request Time DT', depth=1, mode='online')print(dt)> name: Request Time DT, depth: 1dt.mode> AttributeError: 'DecisionTree' object has no attribute 'mode'You’ll notice that ServingMixin isn’t inherited properly: The ServingMixin attribute (mode) doesn’t show when we print our decision tree instance and if we try to access the mode attribute, it doesn’t exist.
This is because, without super() on the BaseEstimator, DecisionTree doesn’t call the next parent class in the method resolution order.
We can fix this by calling super() in the BaseEstimator and DecisionTree works as expected.
class BaseEstimator: def __init__(self, name, **kwargs): self.name = name super().__init__(**kwargs) def __repr__(self): return f', '.join(f'{k}: {v}' for k, v in vars(self).items())class ServingMixin: def __init__(self, mode, **kwargs): super().__init__(**kwargs) self.mode = modeclass DecisionTree(BaseEstimator, ServingMixin): def __init__(self, depth, **kwargs): super().__init__(**kwargs) self.depth = depthdt = DecisionTree(name='Request Time DT', depth=1, mode='online')print(dt)> name: Request Time DT, mode: online, depth: 1dt.mode> 'online'And that’s why we might want to call super() in a base class.
Further reading:
When to use a Mixin
A mixin is a class that provides method implementations for reuse by multiple child classes. It is a limited form of multiple inheritance, and is a parent class that simply provides functionality for subclasses, does not contain state, and is not intended to be instantiated. Scikit-learn uses mixins liberally where they have ClassifierMixin, TransformerMixin, OutlierMixin, etc.
When should we use mixins? They are appropriate when we want to (i) provide a lot of optional features for a class and (ii) when we want to use a particular feature in a lot of different classes. Here’s an example of the former. We start with creating a basic request object in werkzeug.
from werkzeug import BaseRequestclass Request(BaseRequest): passIf we want to add accept header support, we would update it as follows.
from werkzeug import BaseRequest, AcceptMixinclass Request(AcceptMixin, BaseRequest): passNeed support for user agent, authentication, etc? No problem, just add the mixins.
from werkzeug import BaseRequest, AcceptMixin, UserAgentMixin, AuthenticationMixinclass Request(AcceptMixin, UserAgentMixin, AuthenticationMixin, BaseRequest): passBy having these features modularized as mixins—instead of adding them to the base class—we prevent our base class from getting bloated with features that only a few subclasses may use. In addition, these mixins can now be reused by other child classes (that may not inherit from BaseRequest).
Further reading:
Using relative imports (almost all the time)
Relative imports ensure we search the current package (and import from it) before searching the rest of the PYTHONPATH. We use it by adding . before the package imported. Here’s an example from sklearn’s base.py.
from .utils.validation import check_X_yfrom .utils.validation import check_arrayWhat happens if base.py doesn’t use relative imports? If we have a package named utils in our script’s directory, during import, Python will search our utils package instead of sklearn’s utils package, thus breaking sklearn. The . ensures sklearn’s base.py searches its own utils first.
(That said, is there a reason not to use relative imports? Please comment below!)
Further reading
When to add to __init__.py
__init__.py marks directories as Python package directories. The common practice is to leave them empty. Nonetheless, many libraries I read had non-empty and sometimes long __init__.py files. This led me to dig into why we might add to __init__.py.
First, we might add imports to __init__.py when we want to refactor code that has grown into multiple modules without introducing breaking changes to existing users. Say we have a single module (models.py) that contains implementation for DecisionTree and Bandit. Over time, that single module grows into a models package with modules for tree and bandit. To ensure a consistent API for existing users, we might add the following to the __init__.py in the models package.
from .tree import DecisionTree, RandomForestfrom .bandit import Bandit, TSBanditThis ensures existing users can continue to import via from models import DecisionTree instead of from models.tree import DecisionTree. To them, there’s no change in API and existing code doesn’t break.
This brings us to another reason why we might add to __init__.py—to provide a simplified API so users don’t have to dig into implementation details. Consider the example package below.
app __init__.py model_implementation.py data_implementation.pyInstead of having users figure out what to import from model_implementation and data_implementation, we can simplify by adding to app’s __init__.py below.
from .model_implementation import SimpleModelfrom .data_implementation import SimpleDataLoaderThis states that SimpleModel and SimpleDataLoader are the only parts of app that users should use, streamlining how they use the app package (i.e., from app import SimpleModel, SimpleDataLoader). And if they know what they’re doing and want to import directly from model_implementation, that’s doable too.
Libraries that do this include Pandas, where datatypes, readers, and the reshape API are imported in __init__.py, and Hugging Face’s Accelerate.
Other than what’s mentioned above, we might also want to (i) initialize a logger in the main package’s __init__.py for use across multiple modules and (ii) perform compatibility checks.
Further reading
When to use instance, class, and static methods
A quick recap of the various methods we can implement for a class:
- Instance methods need a class instance and can access the instance through
self Class methods don’t need an instance. Thus, they can’t access the instance (self) but have access to the class (cls) Static methods don’t have access to self or cls. They work like regular functions but belong to the class namespace.When should we use class or static methods? Here are some basic guidelines I found.
We use class methods when we want to call it without creating an instance of the class. This is usually when we don’t need instance information but need class information (i.e., its other class or static methods). We might also use class methods as a constructor. The benefit of class methods is that we don’t have to hardcode the class, thus allowing subclasses to use the methods too.
We use static methods when we don’t need class or instance arguments, but the method is related to the class and it is convenient for the method to be in the class’s namespace. For example, utility methods specific to the class. By decorating a method as a static method, we improve readability and understanding by telling others that the method doesn’t depend on the class or instance.
Further reading:
A hidden feature of conftest.py
The common use of conftest.py is to provide fixtures for the entire directory. By defining fixtures in conftest.py, they can be used by any test in the package without having to import them. Beyond that, it’s also used to load external plugins and define hooks such as setup and teardown methods.
However, while browsing sklearn, I came across an empty conftest.py which had this interesting comment.
# Even if empty this file is useful so that when running from the root folder# ./sklearn is added to sys.path by pytest. See# https://docs.pytest.org/en/latest/explanation/pythonpath.html for more# details. For example, this allows to build extensions in place and run pytest# doc/modules/clustering.rst and use sklearn from the local folder rather than# the one from site-packages.It turns out that sklearn was taking advantage of a lesser-known feature of conftest.py: By having it in the root path, it ensures that pytest recognizes the modules without having to specify the PYTHONPATH. In the background, pytest modifies the sys.path by including all submodules found in the root path.
Further reading:
Papers that explain a library’s design principles
Other than reading code, we can also learn by reading papers explaining a library. Let’s focus on the design principles of each library.
Scikit-learn’s design principles include (i) consistency, where all objects share a consistent interface composed of a limited set of methods, and (ii) composition where objects are implemented via existing building blocks wherever feasible.
As a result, most machine learning models and data transformers have a fit() method. In addition, machine learning models have a predict() method and data transformers have a transform() method. This consistency and simplicity contributes to sklearn’s ease of use. The principle of composition also explains why sklearn is built on multiple inheritance of base classes and mixins.
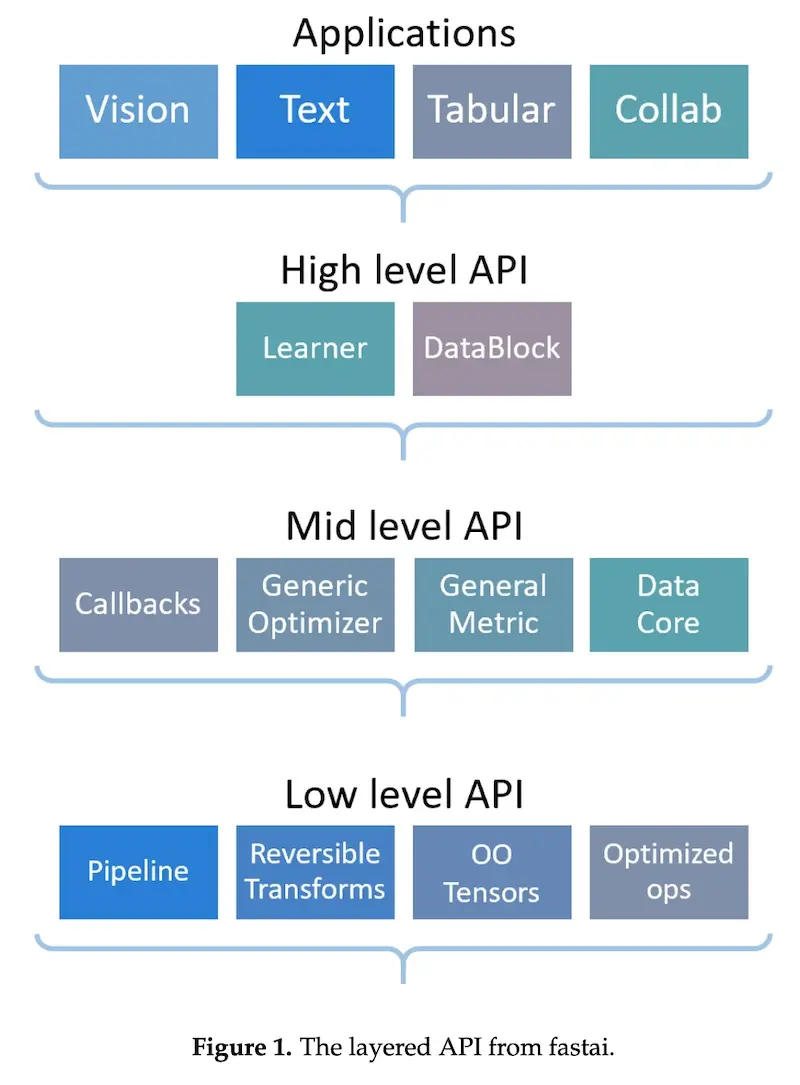
Another example is fastai which uses a layered approach. It provides a high-level API that provides ready-to-use functionality to train models for various applications. The high-level API is built on a hierarchy of lower-level APIs which provide composable building blocks. This layered approach enables one to quickly build a prototype before customizing by tweaking the middle-layer APIs.
PyTorch also shared its design principles such as (i) provide pragmatic performance and (ii) worse is better. The former states that, to be useful, a library needs to deliver compelling performance but not at the expense of ease of use. Thus, PyTorch is willing to trade off 10% speed, but not 100% speed, for a significantly simpler to use library. The latter states that it’s better to have a simple but slightly incomplete solution than a comprehensive but hard-to-maintain design.
• • •
Those are some of the uncommon usages of Python I’ve learned while reading several libraries such as requests, flask, fastapi, scikit-learn, pytorch, fastai, pydantic, and django. I’m sure I only scratched the surface—did I miss anything? Please comment below!
If you found this useful, please cite this write-up as:
Yan, Ziyou. (Jul 2022). Uncommon Uses of Python in Commonly Used Libraries. eugeneyan.com. https://eugeneyan.com/writing/uncommon-python/.
or
@article{yan2022python, title = {Uncommon Uses of Python in Commonly Used Libraries}, author = {Yan, Ziyou}, journal = {eugeneyan.com}, year = {2022}, month = {Jul}, url = {https://eugeneyan.com/writing/uncommon-python/}}