
RecSys 2022 was held from 18th - 23rd September in Seattle. There were 50% more industry submissions relative to 2021, and 260% more relative to 2020. 15 industry papers and 15 industry talks were integrated into the main track. The majority of submissions were on algorithms (161) closely followed by real-world applications (116).

Distribution of paper submissions at RecSys 2022
Fairness & privacy and diversity & novelty continued to have an emphasis, making up two out of nine sessions. Sequential recommendations also gained momentum, making up two sessions on sequential recommendations and sessions & interactions. Reproducibility continued to be a theme with three papers reproducing BERT4Rec, implicit alternating least squares (iALS), and graph neural networks.
Here are summaries of several papers I found useful, starting with my three favorites️. (Also, summaries from previous years: RecSys 2020, RecSys 2021)
❤️ Effective and Efficient Training for Sequential Recommendation using Recency Sampling proposes to combine sequence continuation (i.e., next-item prediction) with item masking (i.e., BERT’s learning paradigm). One weakness of sequence continuation is that it doesn’t use the beginning of the sequence as labels (at the end of the sequence), thus discarding valuable data. Conversely, item masking is only weakly correlated with the objective of sequential recommendations.
The proposed recency-based sampling of sequences (RSS) probabilistically selects labels from sequences to build training sequences, where more recent interactions have a higher probability of being sampled as labels. Nonetheless, due to its probabilistic nature, even the oldest interactions have a non-zero probability of being selected as a label.
Given a sequence, we first compute the recency importance. The paper suggests the exponential function a^n-k, where n = length of the sequence and k = position of the item. Thus, when a = 1, each item has equal chance of being sampled as a label (similar to item masking). And when a is close to zero, items from the end of the sequence have a higher chance of being sampled. The recency importance is then normalized before sampling.
Next, we sample labels, for the end of the sequence, before using the rest of the sequence as the input. For the upper two grey boxes in the image, the labels sampled are {D, E} and {C, D} while the rest of the sequence is used as inpuhttps://eugeneyan.com/assets/recency-based-sampling.webpy-based-sampling.webp" loading="lazy" title="Recency-based sampling of sequences: Elements from the end have higher recency importance" alt="Recency-based sampling of sequences: Elements from the end have higher recency importance">
Recency-based sampling of sequences: Elements from the end have higher recency importance
RSS showed strong performance on several datasets (e.g., MovieLens-20M, Yelp, Gowalla, Booking.com) and models (e.g., GRU4Rec, SASRec), even outperforming BERT4Rec on ML-20M with https://eugeneyan.comhttps://eugeneyan.com/assets/rss-gains.webp.
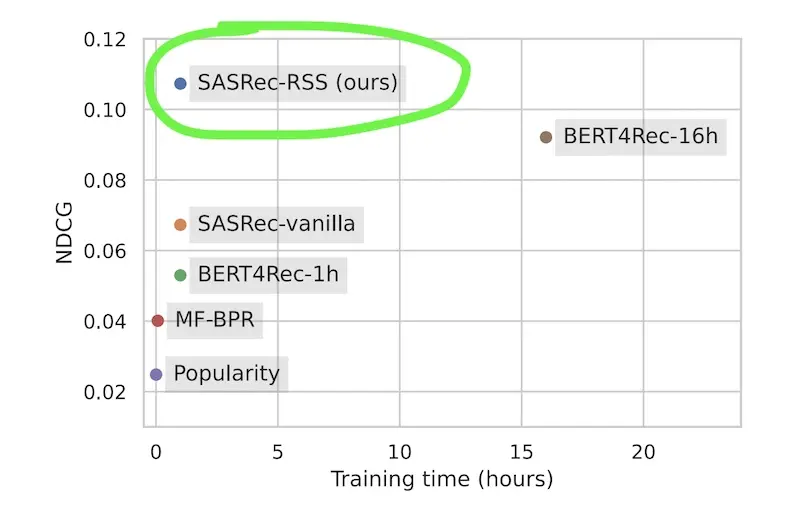
Improvements to NDCG and training time via recency-based sampling of sequences
Overall, an elegant pre-processing technique with potential to improve sequential recommendation performance while reducing training time and without any changes in model architecture. Highly recommended read.
❤️ Extending Open Bandit Pipeline to Simulate Industry Challenges (Booking.com) discusses several important questions about applying bandits in industry and partly answers them via simulations.
Question 1: When does off-policy learning outperform on-policy learning? Studies that compare on-policy vs. off-policy tend to favor the former. However, a practical downside of on-policy learning is that it can adversely affect user experience during the initial exploration phase. In contrast, off-policy learning lets us use existing training data and compare multiple policies without affecting the user experience. Via simulations, the authors show that off-policy learning via an inverse propensity weighted (IPW) bandit outperforms on-policy bandits https://eugeneyan.comhttps://eugeneyan.com/assets/off-policy-vs-on-policy.webpampling.
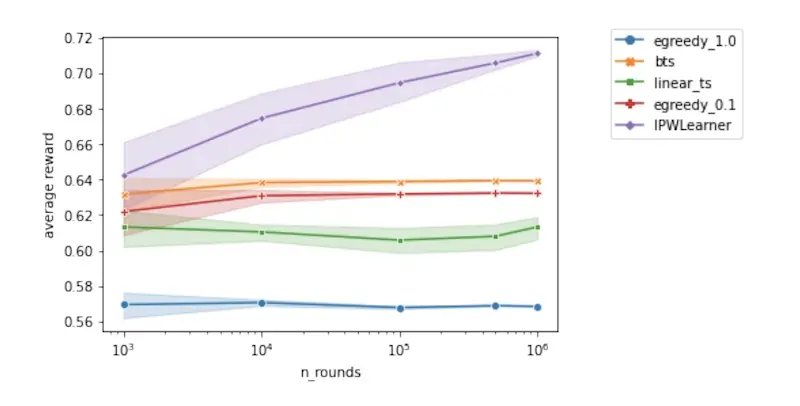
The off-policy IPW learner outperforms on-policy bandits
Question 2: Can bandits adapt well to concept drift/seasonality? While the majority of literature on bandits assume a stationary environment, most real-world environments are non-stationary. Via simulations, the authors showed that most bandits could not cope with a non-stationary environment and rewards. (I chatted with the authors and we discussed solutions such as https://eugeneyan.comhttps://eugeneyan.com/assets/seasonality.webpiding window and decaying past feedback.)
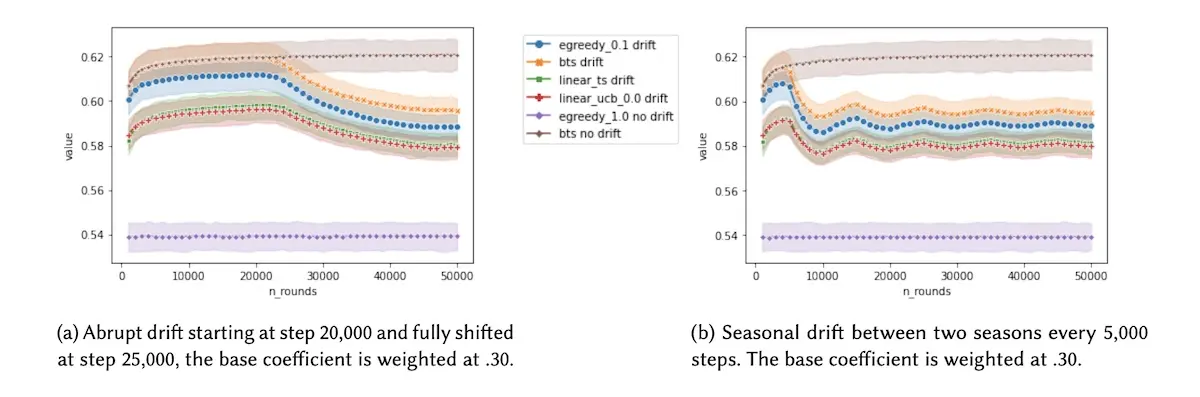
Introducing concept drift or seasonality reduces rewards relative to a stationary environment
Question 3: What is the impact of delayed rewards? In e-commerce settings, rewards (e.g., purchases, retention) may take many rounds to arrive. Also, learning from real-time rewards comes at the cost of operating data streams and a continuously learning pipeline. The authors showed that while policies on delayed reward take longer to converge, after about 10k steps both delayed and non-delayed policies have similar rewards.
There were also questions on (i) reward design and (ihttps://eugeneyan.comhttps://eugeneyan.com/assets/delayed-rewards.webpailability in the paper. Highly recommended read.
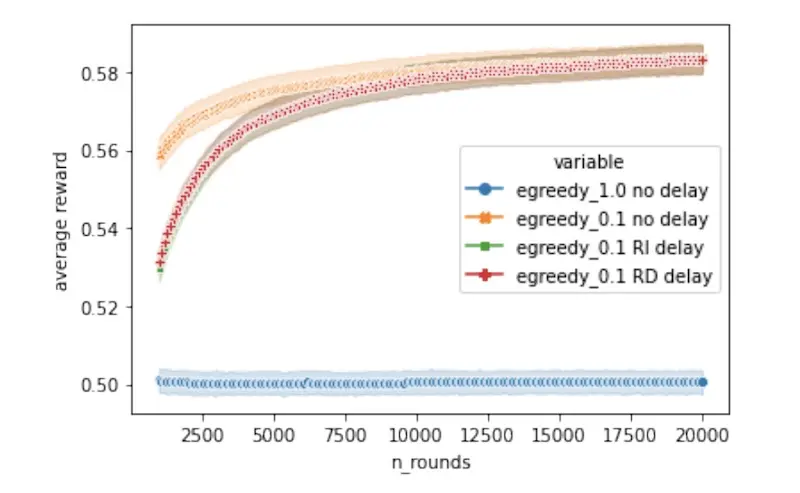
Bandit with delayed reward catches up to no-delay bandit after ~10k steps
❤️ On the Factory Floor: ML Engineering for Industrial-Scale Ads Recommendation Models (Google) shares actionable advice to tackle engineering and machine learning challenges of efficiency, reproducibility, calibration, and credit attribution in the context of the Google Ad’s CTR model. It’s by the same team that wrote Ad Click Prediction: a View from the Trenches nine years ago.
They shared three techniques to improve efficiency. First, bottleneck layers of low-rank matrices between layers of non-linearities can reduce scaling cost with only a small loss in accuracy. Second, they used AutoML to explore network configurations that provide neutral accuracy while decreasing training and serving costs. Third, they reduced training data size by (i) limiting the time range of data, (ii) neghttps://eugeneyan.comhttps://eugeneyan.com/assets/efficiency-gains.webppling examples unlikely to be seen by users due to their position on the page.
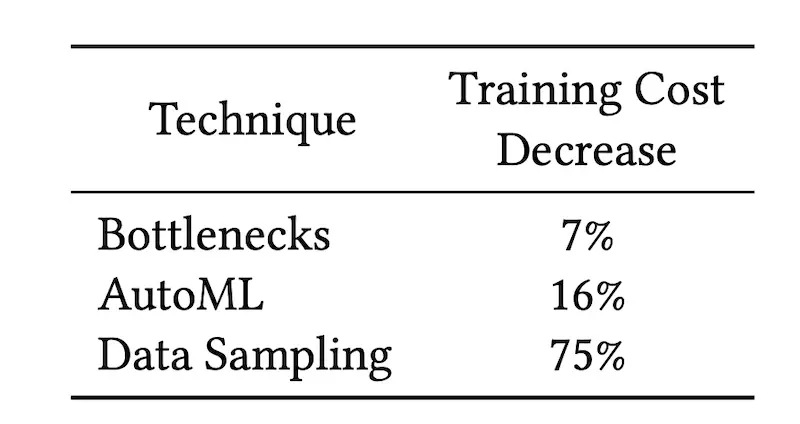
Training cost decrease due to bottlenecks, autoML, and data sampling
They also shared three techniques to improve accuracy. One technique is loss engineering. They found AUC per query to correlate well with business metrics. Thus, in addition to using PerQueryAUC during offline evaluation, they also added a relaxation of the metric, rank-loss, as a second training loss. They also adopted second-order optimization, via distributed Shampoohttps://eugeneyan.comhttps://eugeneyan.com/assets/accuracy-gains.webprgence and accuracy. Finally, they used deep and cross networks to effectively learn feature crosses.
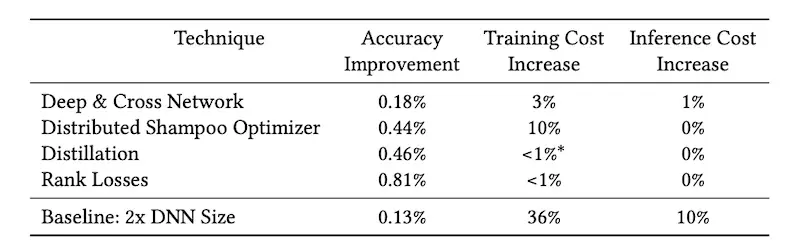
Accuracy increase due to DCN, distributed shampoo, distillation, and rank loss
The paper goes into further detail on reproducibility, generalization across UI, bias, etc. Highly recommended read.
Two-Layer Bandit Optimization for Recommendations (Apple) shares the two-stage bandit used in App Store’https://eugeneyan.comhttps://eugeneyan.com/assets/apple-bandits.webp. The goal is to increase downloads of Suggested items without decreasing engagement with the Search bar.
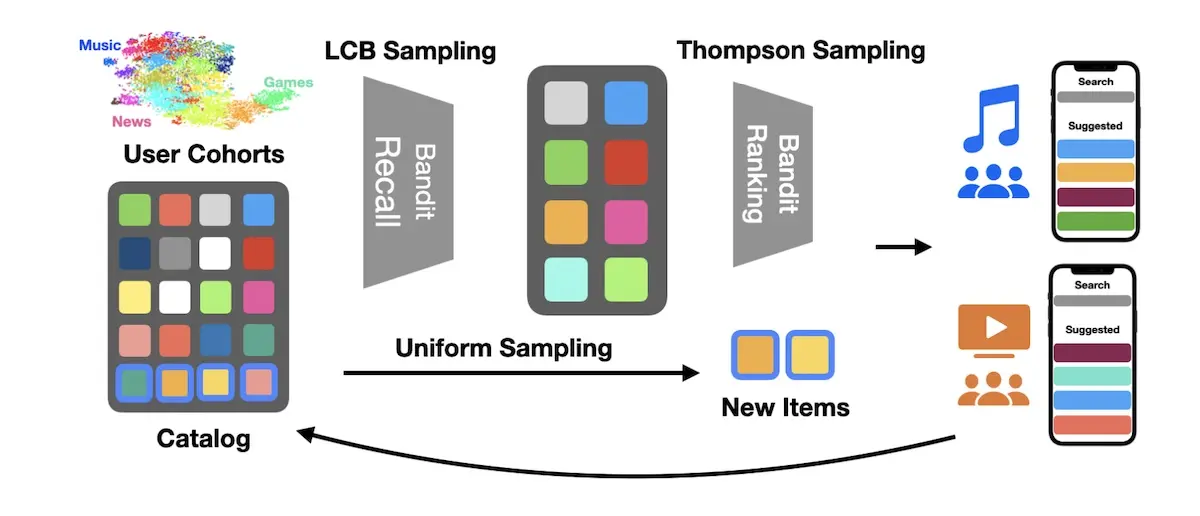
Overview of Apple's two-stage bandit for Suggested items in Search
To address the cannibalization of engagement from Search, their reward function jointly maximizes app downloads via Suggested items and engagement with the Search bar. Without the latter, user downloads via Search decreased during A/B testing. Lesson: Reward design makes a difference.
They also shared that reward is computed at the cohort level instead of the user level. Each cohort represents a group of users with similar tastes (e.g., games, sports) which is created via k-means clustering. This mitigates reward sparsity by aggregating rewards at the cohort level, as well as reducing time complexity and memory requirements of the model. Lesson: Smartly grouping users and contexts goes a long way.
For recommendations in Suggested, a two-stage bandit was adopted. Lower Confidence Bound (LCB) sampling is used in the recall stage before Thompson Sampling in the ranking stage. LCB is more conservative when sampling items: While UCB picks arms that have the highest potential, LCB picks arms with the lowest risk. Recall candidates are then sent to the Thompson Sampling ranker. They also append cold items via uniform sampling to reduce confirmation bias.
(I learned via informal chats that the Thompson Sampling ranker alone led to popularity bias and negative results via A/B testing. The addition of the LCB bandit in the recall stage was key to getting positive results. Lesson: Too much relevance and popularity can be bad.)
A Systematic Review and Replicability Study of BERT4Rec for Sequential Recommendation went through 370 papers citing BERT4Rec before getting a final set of 40 papers comparing BERT4Rec and SASRec, making up 134 comparisons on 46 datasets.
They found that BERT4Rec was not consistently superior to SASRec and only beat it 64% of the time. In addition, the performance of BERT4Rec was dataset-dependent: It did well on ML-20M and Steam but poorly on Sports and Toys. Lesson: The dataset matters.
Furthermore, they were unable to replicate the reported results via the original BERT4Rec implementation and hyperparameters, getting 46.47% poorer recall@10 on Steam. However, training BERT4Rec for up to 30x longer than the original configuration lead to reproducing the results on the original paper.
They also proposed their own implementation of BERT4Rec based on the Huggingface Transformers library. It replicatehttps://eugeneyan.comhttps://eugeneyan.com/assets/bert-gains.webpon three out of four datasets with 1/20 of the training time. Lesson: Model implementation matters even if model architecture is the same.
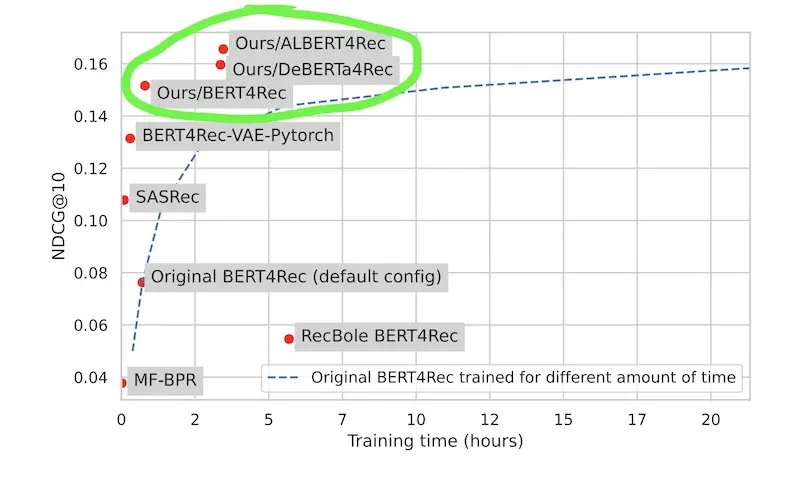
Improvements to NDCG and training time by swapping out the BERT implementation
(During the in-person Q&A, the author of SASRec commented that the paper was a great replication study and suggested also comparing on training time and inference latency.)
Recommendation as Language Processing (RLP): A Unified Pretrain, Personalized Prompt & Predict Paradigm (P5) propohttps://eugeneyan.comhttps://eugeneyan.com/assets/p5.webparn multiple recommendation tasks such as (i) rating prediction, (ii) sequence recommendations (iii) explanation generation, (iv) review-related, and (v) direct recommendation.
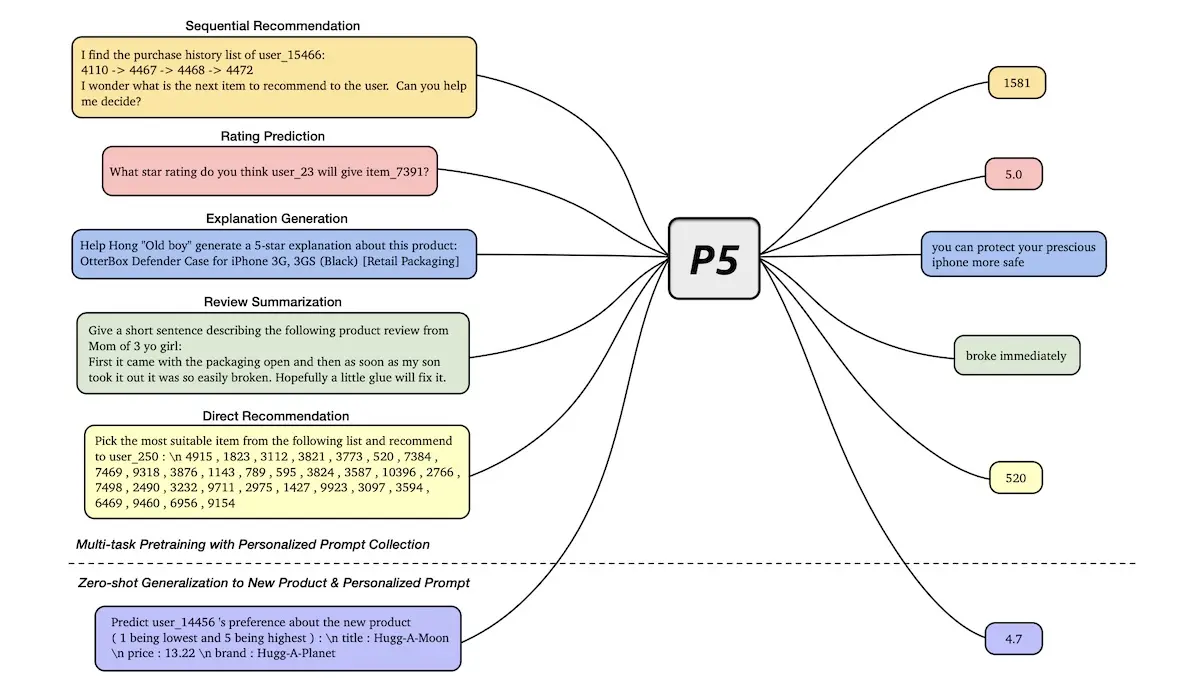
Learning multiple recommendation tasks via P5
It does this via a unified sequence-to-sequence framework. By formulating recommender tasks as prompt-based language tasks, P5 does away with feature-specific encoders. Thus, there is a single data format (text), a single model, and a single loss for multiple recommendation tasks.
https://eugeneyan.comhttps://eugeneyan.com/assets/p5-prompts.webpfor the user (e.g., user ID, user description) and items (e.g., item ID, item metadata and description). To achieve better generalization, multiple prompt types were designed for each task.
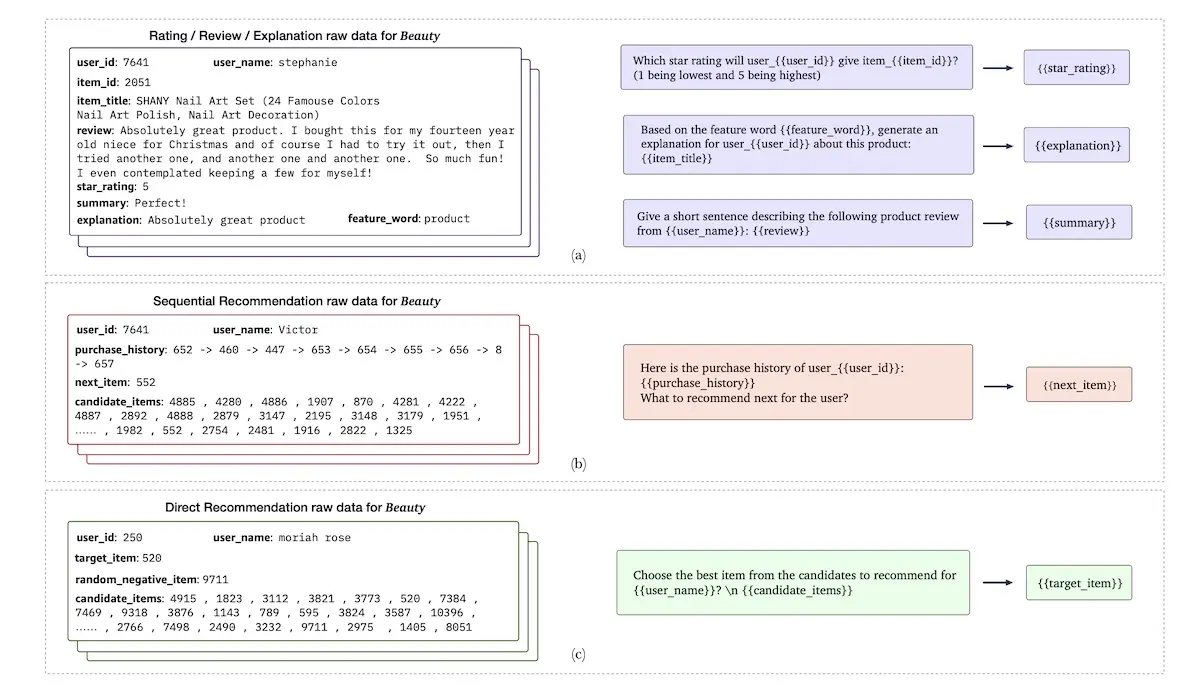
Inference on multiple recommendation tasks via various prompts
They shared that P5 could generalize to unseen personalization prompts, suggesting that P5 was robust enough to understand new prompts. It could also generalize to new items when they provided prompts on a new product and predicted ratings and generated explanations. It’s interesting how the generative paradigm has gone from text and code (2020) to images (2022) and now, recommendations. Not sure about the evaluation, testing, and QA required though.
Client Time Series Model: a Multi-Target Recommender System based on Temporally-Masked Encoders (Stitch Fix) shared how Stitch Fix designed a unified customer embedding and reduced organizational and system complexity.
Historically, Stitch Fix developed specialized recommender systems for each application (e.g., Style Shuffle, Fix Checkout, Freestyle Outfits, etc.) because domain-agnostic models did not perform well. This led to increased complexity, especially when signalhttps://eugeneyan.comhttps://eugeneyan.com/assets/coupled.webpcross applications in real-time (image below). And as they expanded across business segments and regions, the codebase and number of models increased significantly, leading to development and maintenance overhead.
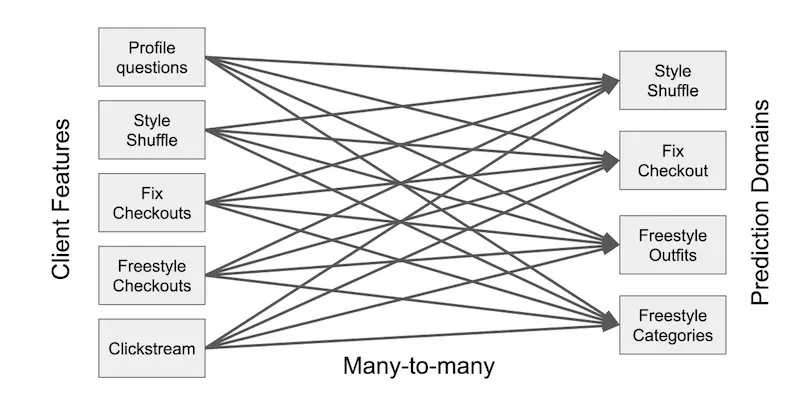
Many-to-many coupling between input data and applicathttps://eugeneyan.comhttps://eugeneyan.com/assets/unified-embedding.webpped a unified customer embedding (image below) that can learn from, and be used, across multiple applications. It was A/B tested via the Freestyle application and led to a 5.8% lift in revenue and 4.1% lift in re-engagement.
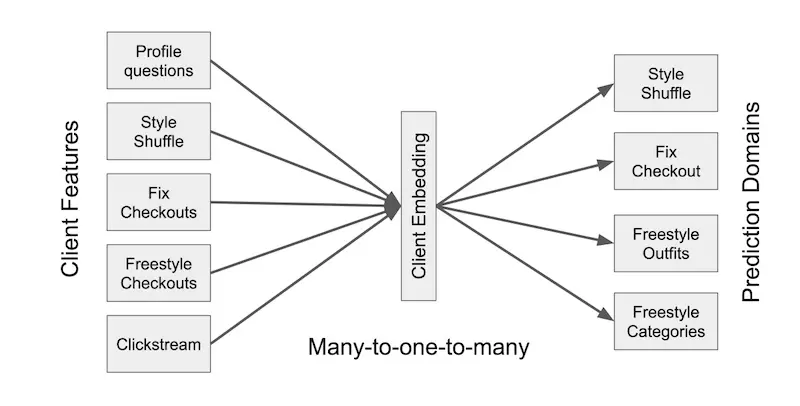
Unified customer embedding as a mediator to decouple inputs and applications
It’s unclear if the results will transfer to other applications but this is a promising way to reduce duplicate work by multiple teams learning customer embeddings for their specific applications, and prune organization complexity. Lesson: Model innovation improves machine learning metrics; system innovation improves organizational metrics.
Denoising Self-Attentive Sequential Recommendation (Visa), the recipient of the RecSys 2022 best paper award, proposed Rhttps://eugeneyan.comhttps://eugeneyan.com/assets/noisy-attention.webp in real-world item sequences. For example, purchase sequences, such as those Visa has, may mix interests across categories such as fashion, electronics, and groceries. Or a large portion of purchases may simply be non-related recurring purchases.
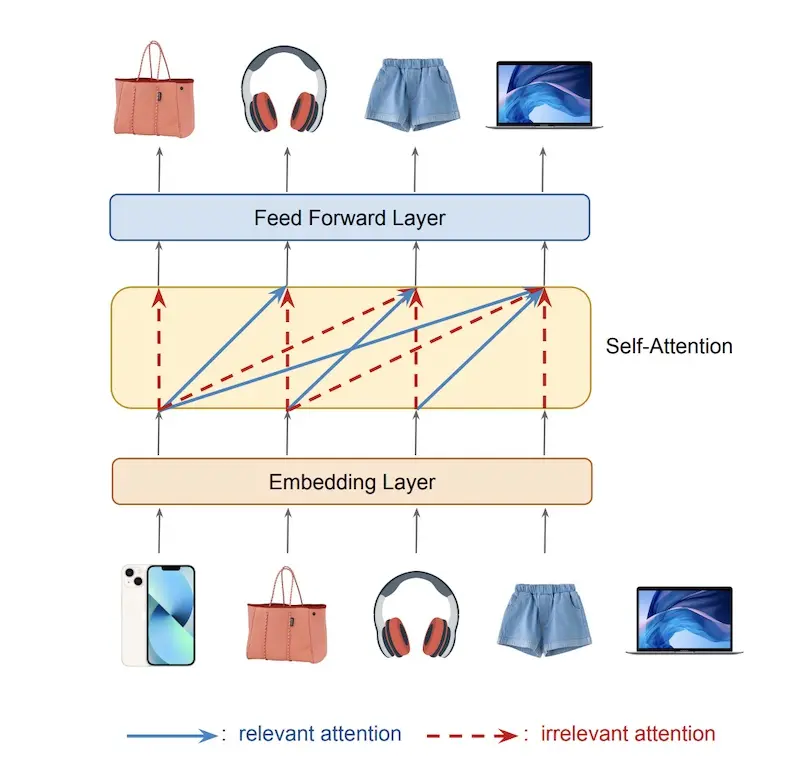
Noisy sequences can lead to irrelevant attention
Rec-denoiser attaches a trainable binary mask (aka trained dropout) to each self-attention layer. However, this binary mask can’t be learned via standard backpropagation. Thus, they adopted a gradient estimation technique (augment-REINFORCE-merge). Unfortunately, the model now requires two forward passes, instead of the usual single forward pass, doubling the training time. They also applied Jacobian regularization to improve the robustness of attention on noisy sequences. (IMHO, not sure if the 2x training time and increased complexity is worth it.)
Revisiting the Performance of iALS on Item Recommendation Benchmarks (Google) noted that most papers that report poor results from iALS haven’t tuned it properly. It also shared some advice on hyperparameter optimization for iALS. This paper is by the same team that overturned the findings of neural collaborative filtering via Neural Collaborative Filtering vs. Matrix Factorization Revisited.
Personalizing Benefits Allocation Without Spending Money (Booking.com) spelled out the opportunity cost of giving promotions to users. First, a user may have transacted even without the promotion. Thus, the promotion didn’t increashttps://eugeneyan.comhttps://eugeneyan.com/assets/uplift-curve.webpcurred cost (“Doesn’t make a difference”). Furthermore, a user might have transacted without the promotion, but upon getting the promotion, they don’t transact (“Don’t treat”). Maybe the promotion led them to compare prices on other platforms or the promotion UX was bad.
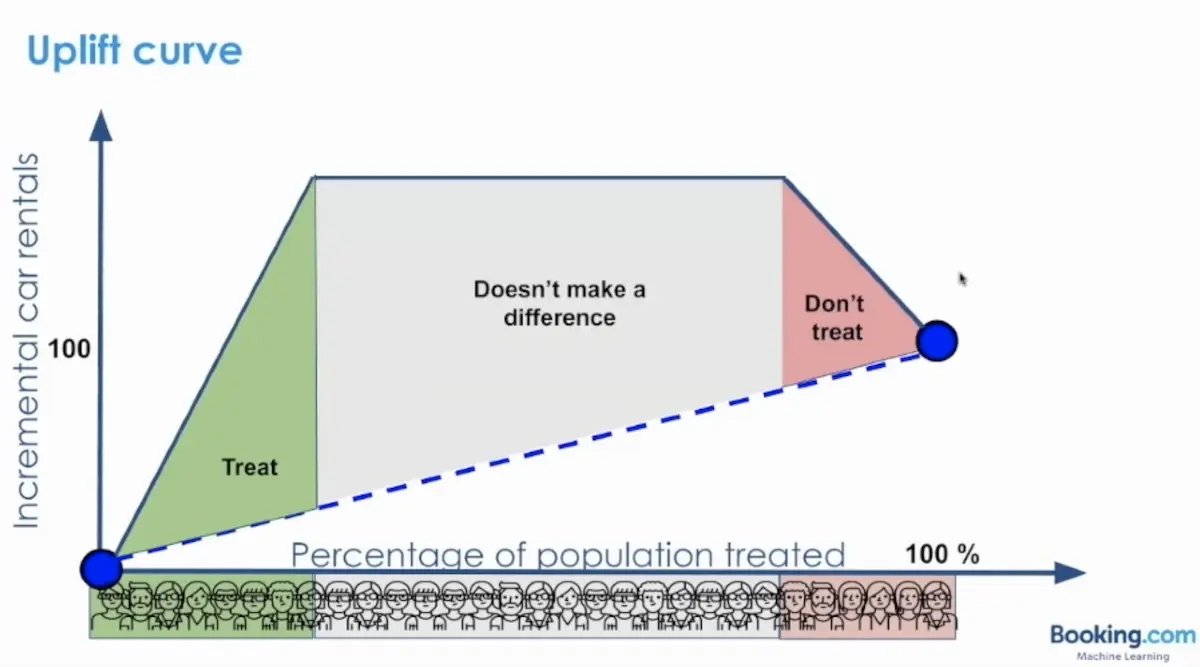
Customers to give (green) and not give (grey and red) promotions to
One way to address this is via estimating the conditional average treatment effect (CATE) of a specific treatment on an individual. This is also known as uplift modeling.
Learning Users’ Preferred Visual Styles in an Image Marketplace (Shutterstock) showehttps://eugeneyan.comhttps://eugeneyan.com/assets/image-mlp.webpinct preferences for image styles. Furthermore, these user preferences may shift over time, even for the same user, as the user works on different projects with different visual styles. Image style can be learned via a combination of metadata (e.g., category, color, style, angle) and the image.
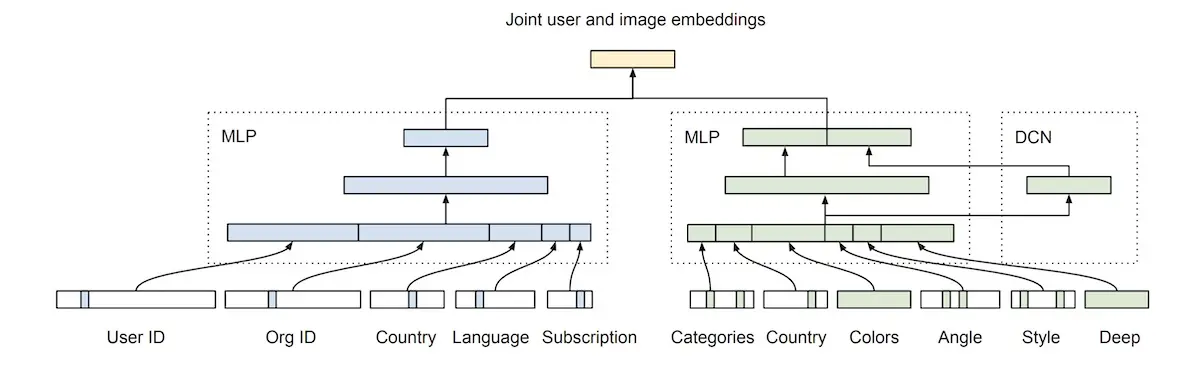
Combining customer (blue) and image (green) attribuhttps://eugeneyan.comhttps://eugeneyan.com/assets/pinterest-short-term.webpnces
Rethinking Personalized Ranking at Pinterest: An End-to-End Approach (Pinterest) shares their journey towards adding short-term intention, via real-time event sequences, to an existing model for long-term interests.
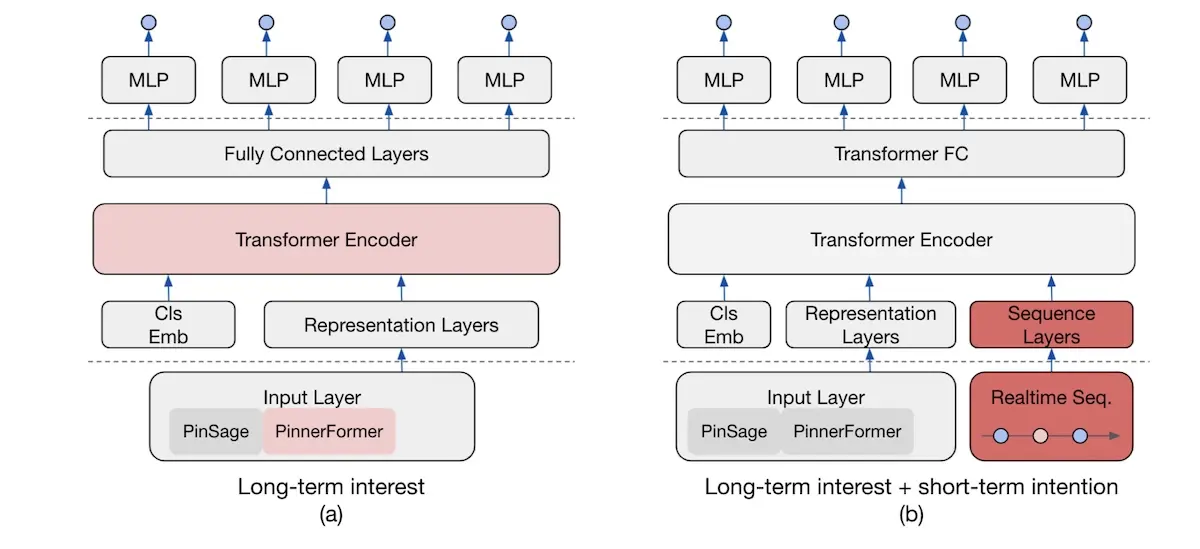
Moving from long-term preferences (left) to long + short-term preferences (right)
A previous attempt to include real-time action features led to the model being too responsive to a user’s recent actions—this was not the desired user experience. As a solution, they added time-window masks to the real-time action sequences during training—this reduced model sensitivity. Adding the real-time information increased repins and ad CTR lift by 5% each.
Identifying New Podcasts with High General Appeal Using a Pure https://eugeneyan.comhttps://eugeneyan.com/assets/popularity-baseline.webpdit Strategy (Spotify) shares how to efficiently explore a neverending supply of cold-start items with a budget constraint via the ISHA algorithm (Infinite Successive Halving Algorithm). The paper also provides a data point on the strength of the popularity baseline where it outperformed AdaBoost and Random Forest models.
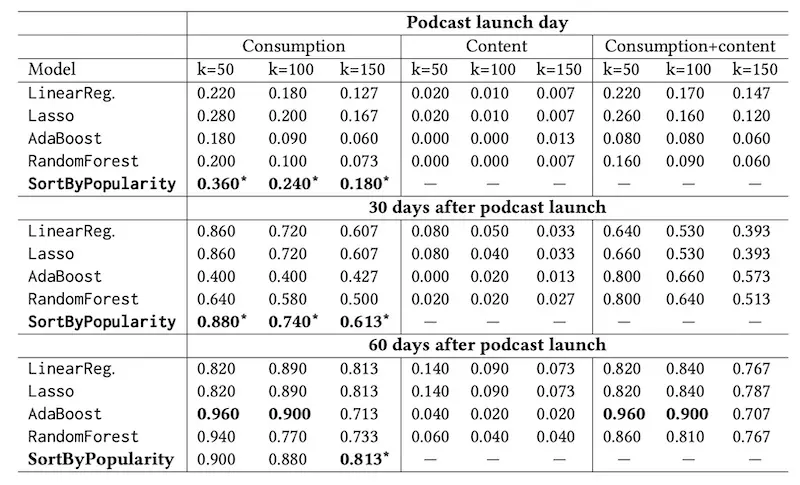
Popularity baseline easily outperforms AdaBoost and RandomForest
Don’t Recommend the Obvious: Estimate Probability Ratios (Amazon) trained recommenders to estimate point-wise mutual information (PMI), creating personalized systems that don’t recommend obviously popular products. It outperformed SOTA baseline during offline evaluation. Lesson: Objective functions can matter more than architecture.
TorchRec: a PyTorch Domain Library for Recommendation Systems (Meta) is a PyTorch library used to train recommenders at Meta. It helped Meta transition from CPU-based asynchronous training to GPU-based fully-synchronous training. It supports quantization and pruning, as well as GPU inference.
A Lightweight Transformer for Next-Item Product Recommendation (Wayfair) shares the nuance of getting offline evaluation metrics to correlate well with online A/B testing. They noticed that the default discount (log2) in nDCG is too low. By using an empirically determined dhttps://eugeneyan.comhttps://eugeneyan.com/assets/netflix-query-rec.webprrelation between offline evaluation and online A/B testing results.
Augmenting Netflix Search with In-Session Adapted Recommendations (Netflix) shares the components needed for a real-time, in-session recommender, of which machine learning only plays a small part.
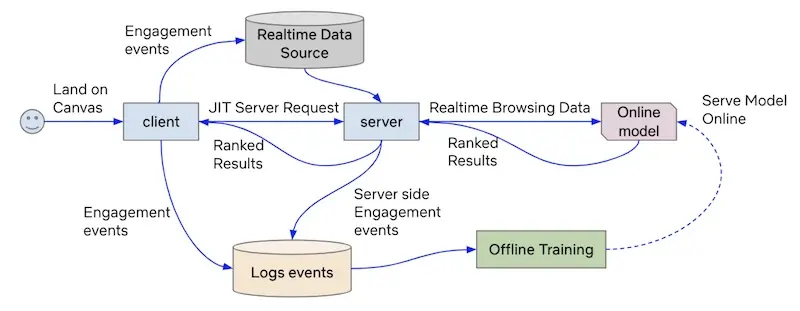
High level overview of in-session recommendations for Netflix Search
• • •
That’s my recap of RecSys 2022 and my three favorite papers. Did I miss any important papers or talks? Please share in the comments below!
P.S., I also gave a keynote at the RecSys 2022 Workshop for Online Recommender Systems. More on the talk here.
If you found this useful, please cite this write-up as:
Yan, Ziyou. (Oct 2022). RecSys 2022: Recap, Favorite Papers, and Lessons. eugeneyan.com. https://eugeneyan.com/writing/recsys2022/.
or
@article{yan2022recsys, title = {RecSys 2022: Recap, Favorite Papers, and Lessons}, author = {Yan, Ziyou}, journal = {eugeneyan.com}, year = {2022}, month = {Oct}, url = {https://eugeneyan.com/writing/recsys2022/}}