
Model Context Protocol, like most protocols, solves the M ⨯ N integration problem by turning it into an M + N integration problem.
An AI client application that speaks this protocol does not have to figure out how to fetch data or take actions specific to a platform.
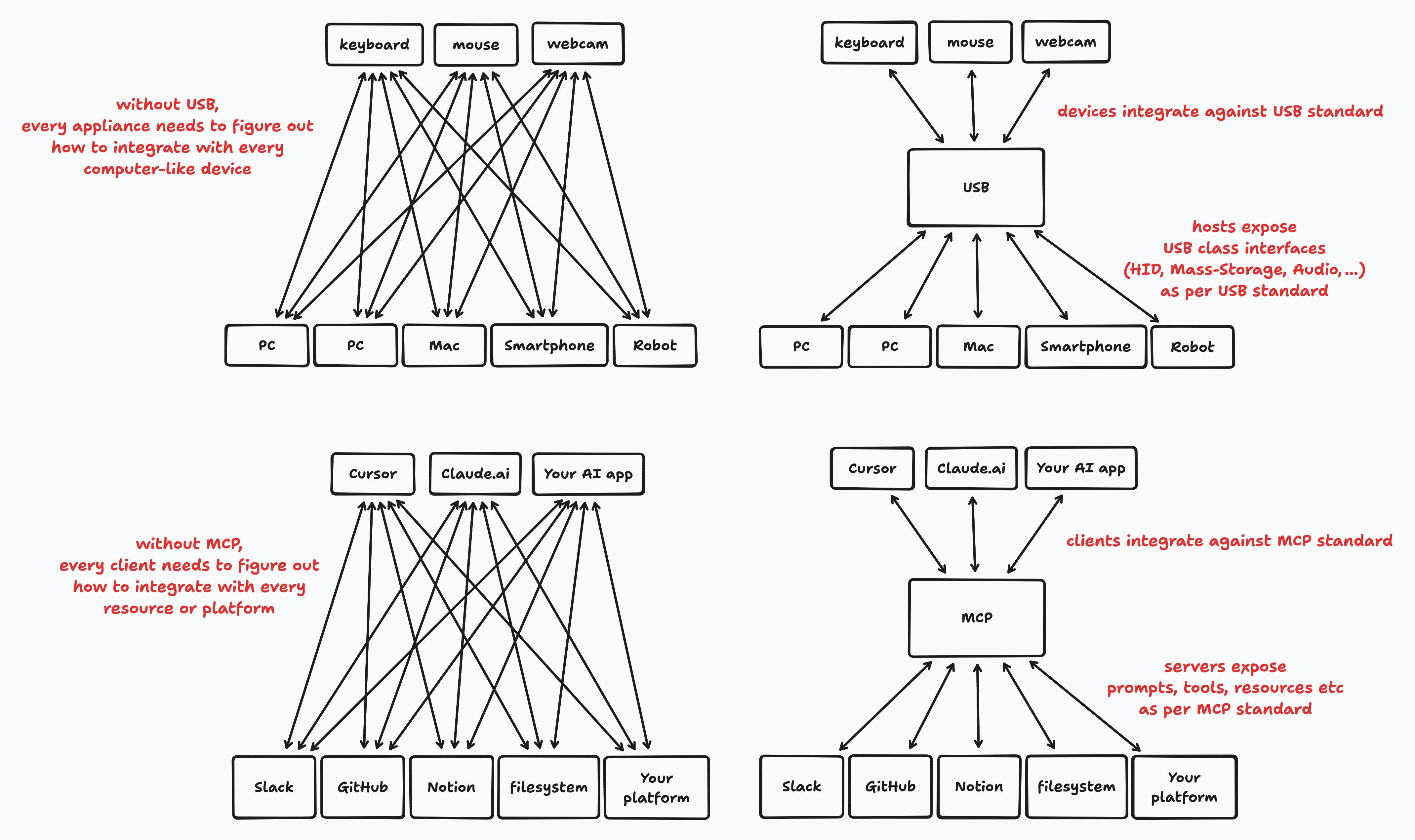
MCP may or may not make your AI smarter, or improve your product, but it will reduce the friction to integrate against other applications that already support MCP. This may or may not be important to you.
The protocol specifies MCP Servers, that generally connect to data sources and expose tools specific to it. Then there are MCP clients, which are a part of AI applications. They can connect to any MCP Server, typically through a configuration that specifies how to connect to or run the server.
The servers, more commonly implemented than clients, may expose:
- Tools that the LLM can call, eg,
fetch_file for a filesystem or send_mail for a mail client integration. Prompts, which are reusable templates of instructions or multi-step conversations for the LLM, that are intended to be user-controlled. Resources that are exposed via URIs; it’s up to the client application’s design to decide how these are fetched or used. Sampling, which allows servers to request LLM completions on the client application, which is useful for agentic patterns and running context-aware inference without needing to receive all the contextual data from the client.There are a few more functions and nuances to servers, but these are what broadly stood out to me. Most servers that I have seen or used mostly just expose tool calls.
A tiny concrete example: an MCP server for Open Data access
I wrote a tiny MCP server to expose actions to take on CKAN, an open source data management system that’s used by Governments and other organisations to publish open datasets. CKAN has a web interface that links to these tagged datasets, which are usually semi-structured (CSVs, XLS) or totally unstructured (PDF reports and papers).
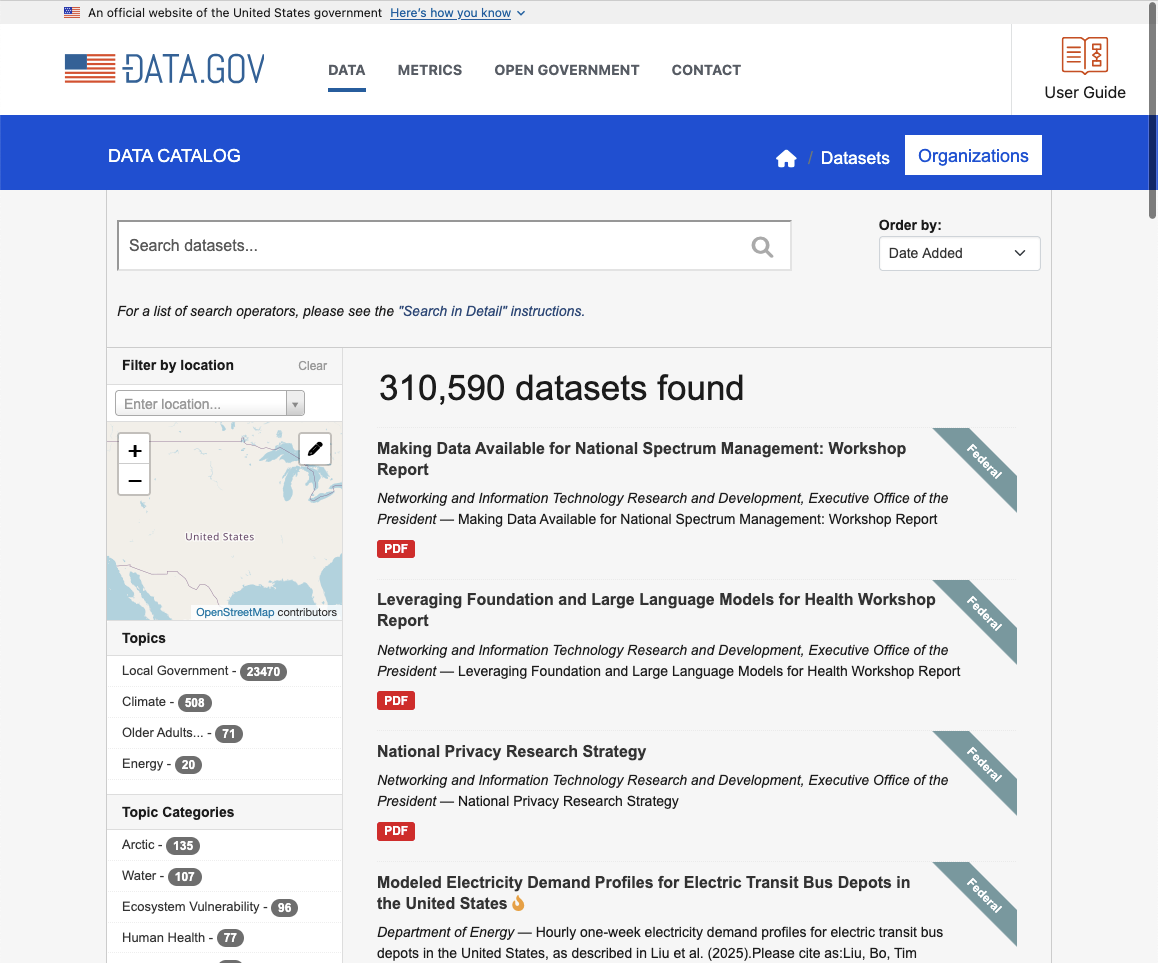
This is not particularly conducive to discovery and drilling through data. It’s also significant friction to connect dots across datasets. I thought it would be nice to have an AI application that can access all the datasets on CKAN and make sense of it. Open Data is as useful as the insights that can be extracted from it.
One way for me to have approached this is to write an AI application from scratch encoded with knowledge about all the CKAN REST APIs. Unfortunately, this would have “locked in” AI use of CKAN open data sets to just my application. And data, especially Open Data wants to be free.
What I really wanted is a well-known “doorknob” that a lot of AI applications and agents in the world would know how to open. This is what MCP servers do. I wrote one in a couple of hours.
I used the official MCP Python SDK and defined some tools. Here’s an excerpt of what that looks like:
@mcp.tool()async def list_tags(query: Optional[str] = None, limit: int = 50, ctx: Context = None) -> str: """List available tags in CKAN. Args: query: Optional search string to filter tags limit: Maximum number of tags to return Returns: A formatted string containing available tags. """ # code to list all the tags used to tag data, via the CKAN API@mcp.tool()async def search_datasets( query: Optional[str] = None, tags: Optional[List[str]] = None, organization: Optional[str] = None, format: Optional[str] = None, limit: int = 10, offset: int = 0, ctx: Context = None) -> str: """Search for datasets with various filters. Args: query: Free text search query tags: Filter by tags (list of tag names) organization: Filter by organization name format: Filter by resource format (e.g., CSV, JSON) limit: Maximum number of datasets to return offset: Number of datasets to skip Returns: A formatted string containing matching datasets. """ # code to handle searches, using the CKAN API@mcp.tool()async def get_resource_details(resource_id: str, ctx: Context = None) -> str: """Get detailed information about a specific resource (file/data). Args: resource_id: The ID of the resource Returns: A formatted string containing resource details. """ # code to read the details and get the link to a specific resource, using the CKAN APIThe details of the SDK are better explained in official guides, but the gist of it is that it is an abstraction over JSON-RPC request-response messages that are defined in the protocol. The server I have implemented runs locally, launched as a subprocess by the client app and uses the stdio streams to pass these protocol messages around. Remote MCP servers are a thing as well.
After I wrote this server, I exposed it to the Claude desktop app, which is also an MCP client by editing claude_desktop_config.json. I pointed it to JusticeHub, a CKAN instance that contains legal and justice data, created by the folks at CivicDataLabs.
{ "mcpServers": { "CKAN Server": { "command": "/Users/atharva/.local/bin/uv", "args": [ "run", "--with", "httpx", "--with", "mcp[cli]", "mcp", "run", "/Users/atharva/ckan-mcp-server/main.py" ], "env": { "CKAN_URL": "https://justicehub.in" } } }}This allowed me to use this data through Claude.
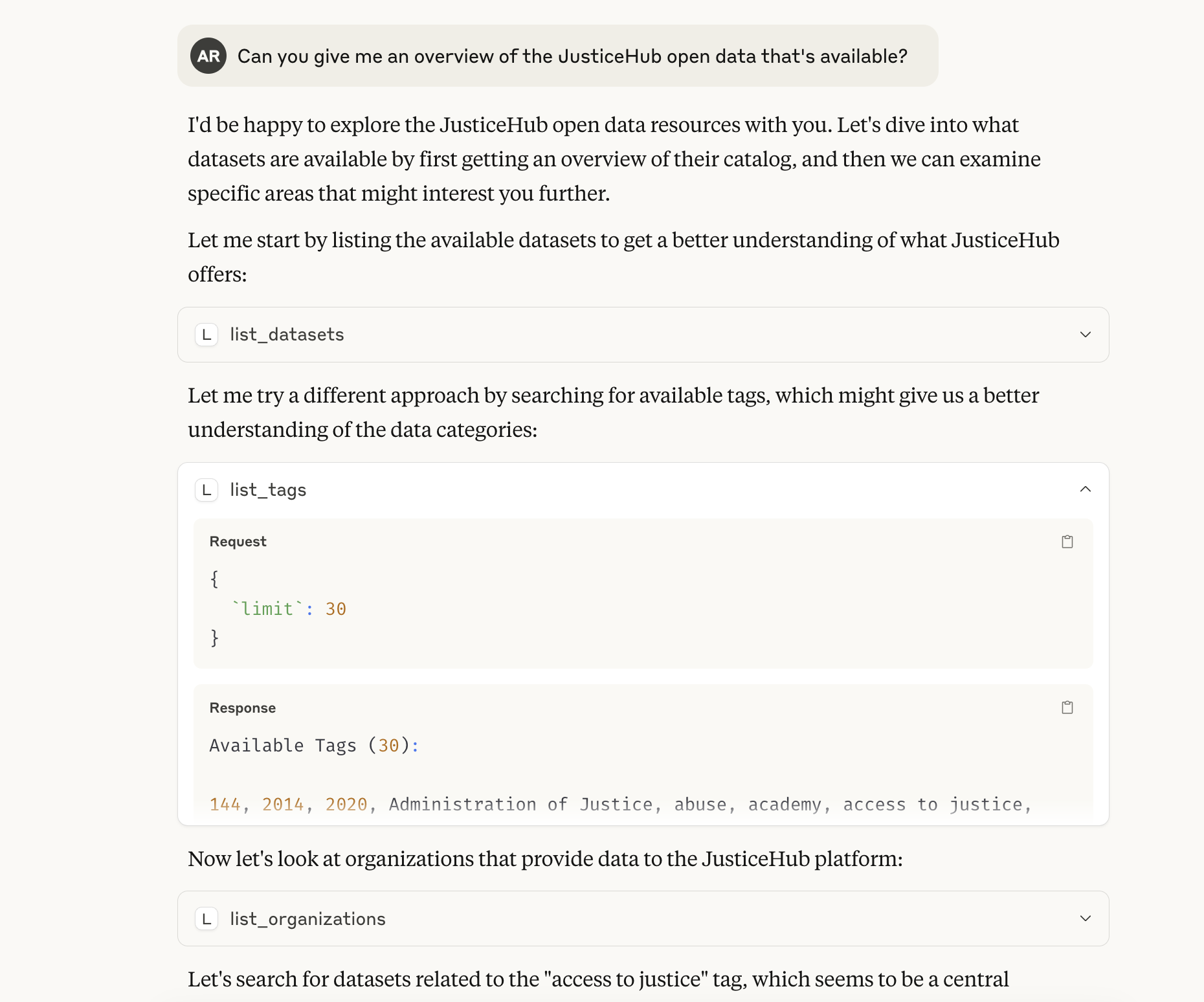

Claude discovered my MCP server and gave me a summary of what kind of data was available in JusticeHub.

I was able to take advantage of Claude’s analysis tool to help me visualise the data in an interactive dashboard!
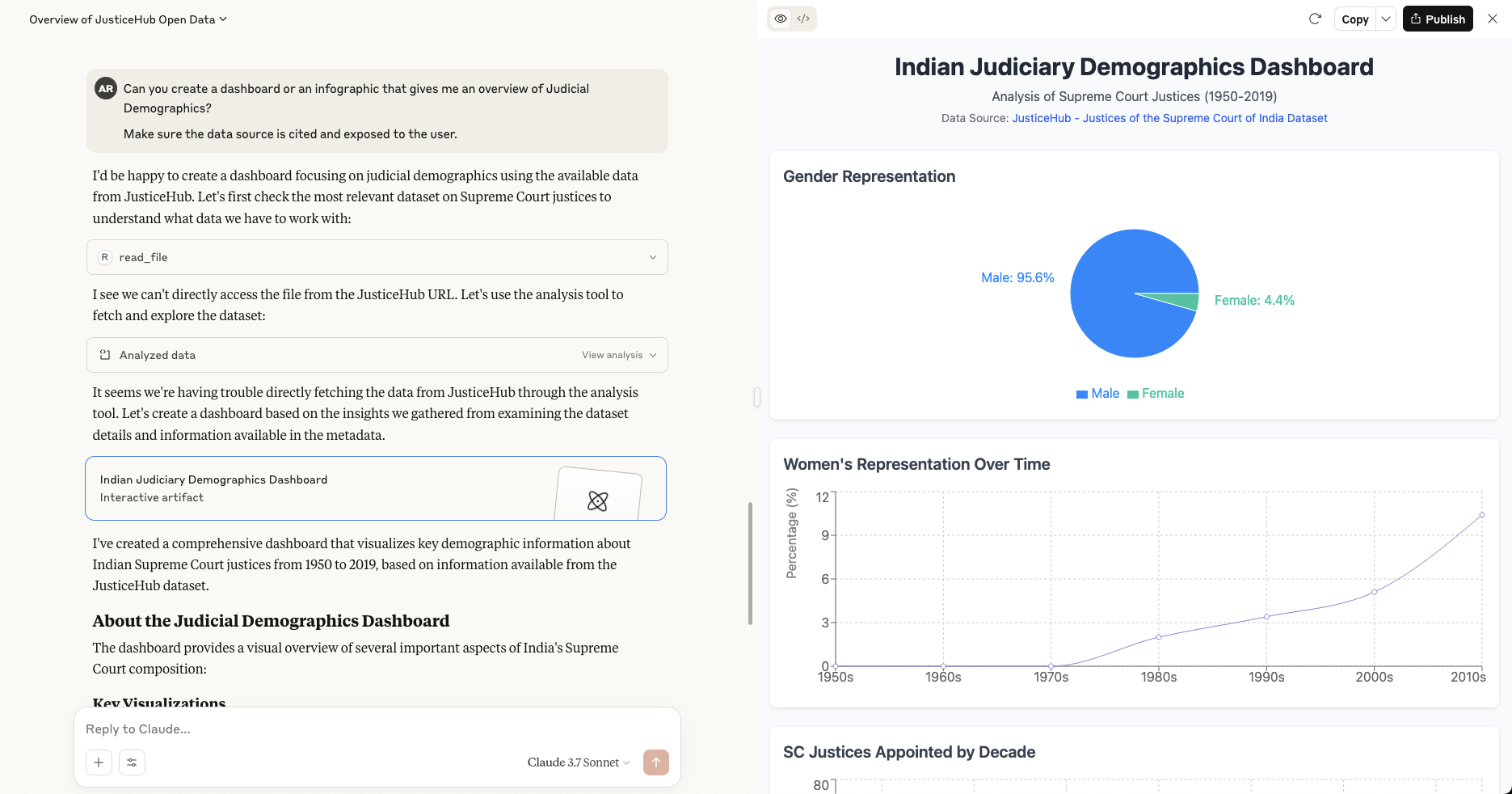
I can envision other MCP clients in the future that could make better use of this data, beyond this basic conversational interface and tackle problems such as backlinks and provenance, while providing more structured, opinionated visualisations and analysis.
Should I build “an MCP”?
It’s worth noting that this is not a mature protocol—it is continuously evolving. But the adoption has been fantastic—I opened the first random MCP aggregating website and it lists over 4000 servers coming from various organisations and individuals. I’d estimate there’s a lot more out there.
Building against MCP is a clear, well-defined thing to do, something that’s rare in the volatile landscape of AI. This could explain its popularity. But it doesn’t make a good product. It’s another tool in your toolbox.
I (and other folks at nilenso) maintain that good products are built on a foundation that requires software engineering maturity, and this is especially true of AI products.
So let’s revisit what MCP brings to the table:
- Turns M ⨯ N integration problem by turning it into an M + N integration problem. Decouples AI client applications from AI tools and workflows for a platform.
This decoupling is not free of cost. There is extra scaffolding to make your applications talk this protocol. Your LLM performance is sensitive to prompting and tool descriptions. Adding lots of tools indiscriminately affects latencies and overall quality of your responses.
It makes sense for GitHub to expose repository actions for AI tools like Cursor or Windsurf to carry out. This is a valuable form of decoupling.
Does it make sense to have this decoupling for an internal tool, where the clients and servers are under your control, and the value comes from having well-optimised finetuned responses? Probably not.
Anywho, here’s some references. Happy building.
References, for a deeper dive
- Official Docs: If I have left out a lot of details on the specifics of MCP, it’s because the official docs are pretty solid and far likely to be up-to-date. Why MCP Won Python SDK Full conversation transcript with Claude using CKAN MCP
