AI agents. Agentic AI. Agentic architectures. Agentic workflows. Agentic patterns. Agents are everywhere. But what exactly are they, and how do we build robust and effective agentic systems? While the term "agent" is used broadly, a key characteristic is their ability to dynamically plan and execute tasks, often leveraging external tools and memory to achieve complex goals.
This post aims to explore common design patterns. Think of these patterns as blueprints or reusable templates for building AI applications. Understanding them provides a mental model for tackling complex problems and designing systems that are scalable, modular, and adaptable.
We'll dive into several common patterns, differentiating between more structured workflows and more dynamic agentic patterns. Workflows typically follow predefined paths, while agents have more autonomy in deciding their course of action.
Why Do (Agentic) Patterns Matter?
Patterns provide a structured way to think and design systems.Patterns allow us to build and grow AI applications in complexity and adapt to changing requirements. Modular designs based on patterns are easier to modify and extend.Patterns help manage the complexity of coordinating multiple agents, tools, and workflows by offering proven, reusable templates. They promote best practices and shared understanding among developers.
When (and When Not) to Use Agents?
Before diving into patterns, it's crucial to consider when an agentic approach is truly necessary.
Always seek the simplest solution first. If you know the exact steps required to solve a problem, a fixed workflow or even a simple script might be more efficient and reliable than a agent.Agentic systems often trade increased latency and computational cost for potentially better performance on complex, ambiguous, or dynamic tasks. Be sure the benefits outweigh these costs.Use workflows for predictability and consistency when dealing with well-defined tasks where the steps are known.Use agents when flexibility, adaptability, and model-driven decision-making are needed.Keep it Simple (Still): Even when building agentic systems, strive for the simplest effective design. Overly complex agent can become difficult to debug and manage.Agency introduces inherent unpredictability and potential errors. Agentic systems must incorporate robust error logging, exception handling, and retry mechanisms, allowing the system (or the underlying LLM) a chance to self-correct.
Below, we'll explore 3 common workflow patterns and 4 agentic patterns. We'll illustrate each using pure API calls, without relying on specific frameworks like LangChain, LangGraph, LlamaIndex, or CrewAI, to focus on the core concepts.
Pattern Overview
We will cover the following patterns:
Workflow: Prompt Chaining
The output of one LLM call sequentially feeds into the input of the next LLM call. This pattern decomposes a task into a fixed sequence of steps. Each step is handled by an LLM call that processes the output from the preceding one. It's suitable for tasks that can be cleanly broken down into predictable, sequential subtasks.
Use Cases:
Generating a structured document: LLM 1 creates an outline, LLM 2 validates the outline against criteria, LLM 3 writes the content based on the validated outline.Multi-step data processing: Extracting information, transforming it, and then summarizing it.Generating newsletters based on curated inputs.
import osfrom google import genai# Configure the client (ensure GEMINI_API_KEY is set in your environment)client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])# --- Step 1: Summarize Text ---original_text = "Large language models are powerful AI systems trained on vast amounts of text data. They can generate human-like text, translate languages, write different kinds of creative content, and answer your questions in an informative way."prompt1 = f"Summarize the following text in one sentence: {original_text}"# Use client.models.generate_contentresponse1 = client.models.generate_content( model='gemini-2.0-flash', contents=prompt1)summary = response1.text.strip()print(f"Summary: {summary}")# --- Step 2: Translate the Summary ---prompt2 = f"Translate the following summary into French, only return the translation, no other text: {summary}"# Use client.models.generate_contentresponse2 = client.models.generate_content( model='gemini-2.0-flash', contents=prompt2)translation = response2.text.strip()print(f"Translation: {translation}")
Workflow: Routing
An initial LLM acts as a router, classifying the user's input and directing it to the most appropriate specialized task or LLM. This pattern implements a separation of concerns and allows for optimizing individual downstream tasks (using specialized prompts, different models, or specific tools) in isolation. It improves efficiency and potentially reduces costs by using smaller models for simpler tasks. When a task is routed, the selected agent "takes over" responsibility for completion.
Use Cases:
Customer support systems: Routing queries to agents specialized in billing, technical support, or product information.Tiered LLM usage: Routing simple queries to faster, cheaper models (like Llama 3.1 8B) and complex or unusual questions to more capable models (like Gemini 1.5 Pro).Content generation: Routing requests for blog posts, social media updates, or ad copy to different specialized prompts/models.
import osimport jsonfrom google import genaifrom pydantic import BaseModelimport enum# Configure the client (ensure GEMINI_API_KEY is set in your environment)client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])# Define Routing Schemaclass Category(enum.Enum): WEATHER = "weather" SCIENCE = "science" UNKNOWN = "unknown"class RoutingDecision(BaseModel): category: Category reasoning: str# Step 1: Route the Queryuser_query = "What's the weather like in Paris?"# user_query = "Explain quantum physics simply."# user_query = "What is the capital of France?"prompt_router = f"""Analyze the user query below and determine its category.Categories:- weather: For questions about weather conditions.- science: For questions about science.- unknown: If the category is unclear.Query: {user_query}"""# Use client.models.generate_content with config for structured outputresponse_router = client.models.generate_content( model= 'gemini-2.0-flash-lite', contents=prompt_router, config={ 'response_mime_type': 'application/json', 'response_schema': RoutingDecision, },)print(f"Routing Decision: Category={response_router.parsed.category}, Reasoning={response_router.parsed.reasoning}")# Step 2: Handoff based on Routingfinal_response = ""if response_router.parsed.category == Category.WEATHER: weather_prompt = f"Provide a brief weather forecast for the location mentioned in: '{user_query}'" weather_response = client.models.generate_content( model='gemini-2.0-flash', contents=weather_prompt ) final_response = weather_response.textelif response_router.parsed.category == Category.SCIENCE: science_response = client.models.generate_content( model="gemini-2.5-flash-preview-04-17", contents=user_query ) final_response = science_response.textelse: unknown_response = client.models.generate_content( model="gemini-2.0-flash-lite", contents=f"The user query is: {prompt_router}, but could not be answered. Here is the reasoning: {response_router.parsed.reasoning}. Write a helpful response to the user for him to try again." ) final_response = unknown_response.textprint(f"\nFinal Response: {final_response}")
Workflow: Parallelization
A task is broken down into independent subtasks that are processed simultaneously by multiple LLMs, with their outputs being aggregated. This pattern uses concurrency for tasks. The initial query (or parts of it) is sent to multiple LLMs in parallel with individual prompts/goals. Once all branches are complete, their individual results are collected and passed to a final aggregator LLM, which synthesizes them into the final response. This can improve latency if subtasks don't depend on each other, or enhance quality through techniques like majority voting or generating diverse options.
Use Cases:
RAG with query decomposition: Breaking a complex query into sub-queries, running retrievals for each in parallel, and synthesizing the results.Analyzing large documents: Dividing the document into sections, summarizing each section in parallel, and then combining the summaries.Generating multiple perspectives: Asking multiple LLMs the same question with different persona prompts and aggregating their responses.Map-reduce style operations on data.
import osimport asyncioimport timefrom google import genai# Configure the client (ensure GEMINI_API_KEY is set in your environment)client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])async def generate_content(prompt: str) -> str: response = await client.aio.models.generate_content( model="gemini-2.0-flash", contents=prompt ) return response.text.strip()async def parallel_tasks(): # Define Parallel Tasks topic = "a friendly robot exploring a jungle" prompts = [ f"Write a short, adventurous story idea about {topic}.", f"Write a short, funny story idea about {topic}.", f"Write a short, mysterious story idea about {topic}." ] # Run tasks concurrently and gather results start_time = time.time() tasks = [generate_content(prompt) for prompt in prompts] results = await asyncio.gather(*tasks) end_time = time.time() print(f"Time taken: {end_time - start_time} seconds") print("\n--- Individual Results ---") for i, result in enumerate(results): print(f"Result {i+1}: {result}\n") # Aggregate results and generate final story story_ideas = '\n'.join([f"Idea {i+1}: {result}" for i, result in enumerate(results)]) aggregation_prompt = f"Combine the following three story ideas into a single, cohesive summary paragraph:{story_ideas}" aggregation_response = await client.aio.models.generate_content( model="gemini-2.5-flash-preview-04-17", contents=aggregation_prompt ) return aggregation_response.textresult = await parallel_tasks()print(f"\n--- Aggregated Summary ---\n{result}")
An agent evaluates its own output and uses that feedback to refine its response iteratively. This pattern is also known as Evaluator-Optimizer and uses a self-correction loop. An initial LLM generates a response or completes a task. A second LLM step (or even the same LLM with a different prompt) then acts as a reflector or evaluator, critiquing the initial output against the requirements or desired quality. This critique (feedback) is then fed back, prompting the LLM to produce a refined output. This cycle can repeat until the evaluator confirms the requirements are met or a satisfing output is achieved.
Use Cases:
Code generation: Writing code, executing it, using error messages or test results as feedback to fix bugs.Writing and refinement: Generating a draft, reflecting on its clarity and tone, and then revising it.Complex problem solving: Generating a plan, evaluating its feasibility, and refining it based on the evaluation.Information retrieval: Searching for information and using an evaluator LLM to check if all required details were found before presenting the answer.
import osimport jsonfrom google import genaifrom pydantic import BaseModelimport enum# Configure the client (ensure GEMINI_API_KEY is set in your environment)client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])class EvaluationStatus(enum.Enum): PASS = "PASS" FAIL = "FAIL"class Evaluation(BaseModel): evaluation: EvaluationStatus feedback: str reasoning: str# --- Initial Generation Function ---def generate_poem(topic: str, feedback: str = None) -> str: prompt = f"Write a short, four-line poem about {topic}." if feedback: prompt += f"\nIncorporate this feedback: {feedback}" response = client.models.generate_content( model='gemini-2.0-flash', contents=prompt ) poem = response.text.strip() print(f"Generated Poem:\n{poem}") return poem# --- Evaluation Function ---def evaluate(poem: str) -> Evaluation: print("\n--- Evaluating Poem ---") prompt_critique = f"""Critique the following poem. Does it rhyme well? Is it exactly four lines? Is it creative? Respond with PASS or FAIL and provide feedback.Poem:{poem}""" response_critique = client.models.generate_content( model='gemini-2.0-flash', contents=prompt_critique, config={ 'response_mime_type': 'application/json', 'response_schema': Evaluation, }, ) critique = response_critique.parsed print(f"Evaluation Status: {critique.evaluation}") print(f"Evaluation Feedback: {critique.feedback}") return critique# Reflection Loop max_iterations = 3current_iteration = 0topic = "a robot learning to paint"# simulated poem which will not pass the evaluationcurrent_poem = "With circuits humming, cold and bright,\nA metal hand now holds a brush"while current_iteration < max_iterations: current_iteration += 1 print(f"\n--- Iteration {current_iteration} ---") evaluation_result = evaluate(current_poem) if evaluation_result.evaluation == EvaluationStatus.PASS: print("\nFinal Poem:") print(current_poem) break else: current_poem = generate_poem(topic, feedback=evaluation_result.feedback) if current_iteration == max_iterations: print("\nMax iterations reached. Last attempt:") print(current_poem) https://www.philschmid.de/static/blog/agentic-pattern/tool-use.pngimg src="/static/blog/agentic-pattern/tool-use.png" alt="">
LLM has the ability to invoke external functions or APIs to interact with the outside world, retrieve information, or perform actions. This pattern often referred to as Function Calling and is the most widely recognized pattern. The LLM is provided with definitions (name, description, input schema) of available tools (functions, APIs, databases, etc.). Based on the user query, the LLM can decide to call one or more tools by generating a structured output (like JSON) matching the required schema. This output is used to execute the actual external tool/function, and the result is returned to the LLM. The LLM then uses this result to formulate its final response to the user. This vastly extends the LLM's capabilities beyond its training data.
Use Cases:
Booking appointments using a calendar API.Retrieving real-time stock prices via a financial API.Searching a vector database for relevant documents (RAG).Controlling smart home devices.Executing code snippets.
import osfrom google import genaifrom google.genai import types# Configure the client (ensure GEMINI_API_KEY is set in your environment)client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])# Define the function declaration for the modelweather_function = { "name": "get_current_temperature", "description": "Gets the current temperature for a given location.", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco", }, }, "required": ["location"], },}# Placeholder function to simulate API calldef get_current_temperature(location: str) -> dict: return {"temperature": "15", "unit": "Celsius"}# Create the config object as shown in the user's example# Use client.models.generate_content with model, contents, and configtools = types.Tool(function_declarations=[weather_function])contents = ["What's the temperature in London right now?"]response = client.models.generate_content( model='gemini-2.0-flash', contents=contents, config = types.GenerateContentConfig(tools=[tools]))# Process the Response (Check for Function Call)response_part = response.candidates[0].content.parts[0]if response_part.function_call: function_call = response_part.function_call print(f"Function to call: {function_call.name}") print(f"Arguments: {dict(function_call.args)}") # Execute the Function if function_call.name == "get_current_temperature": # Call the actual function api_result = get_current_temperature(*function_call.args) # Append function call and result of the function execution to contents follow_up_contents = [ types.Part(function_call=function_call), types.Part.from_function_response( name="get_current_temperature", response=api_result ) ] # Generate final response response_final = client.models.generate_content( model="gemini-2.0-flash", contents=contents + follow_up_contents, config=types.GenerateContentConfig(tools=[tools]) ) print(response_final.text) else: print(f"Error: Unknown function call requested: {function_call.name}")else: print("No function call found in the response.") print(response.text)
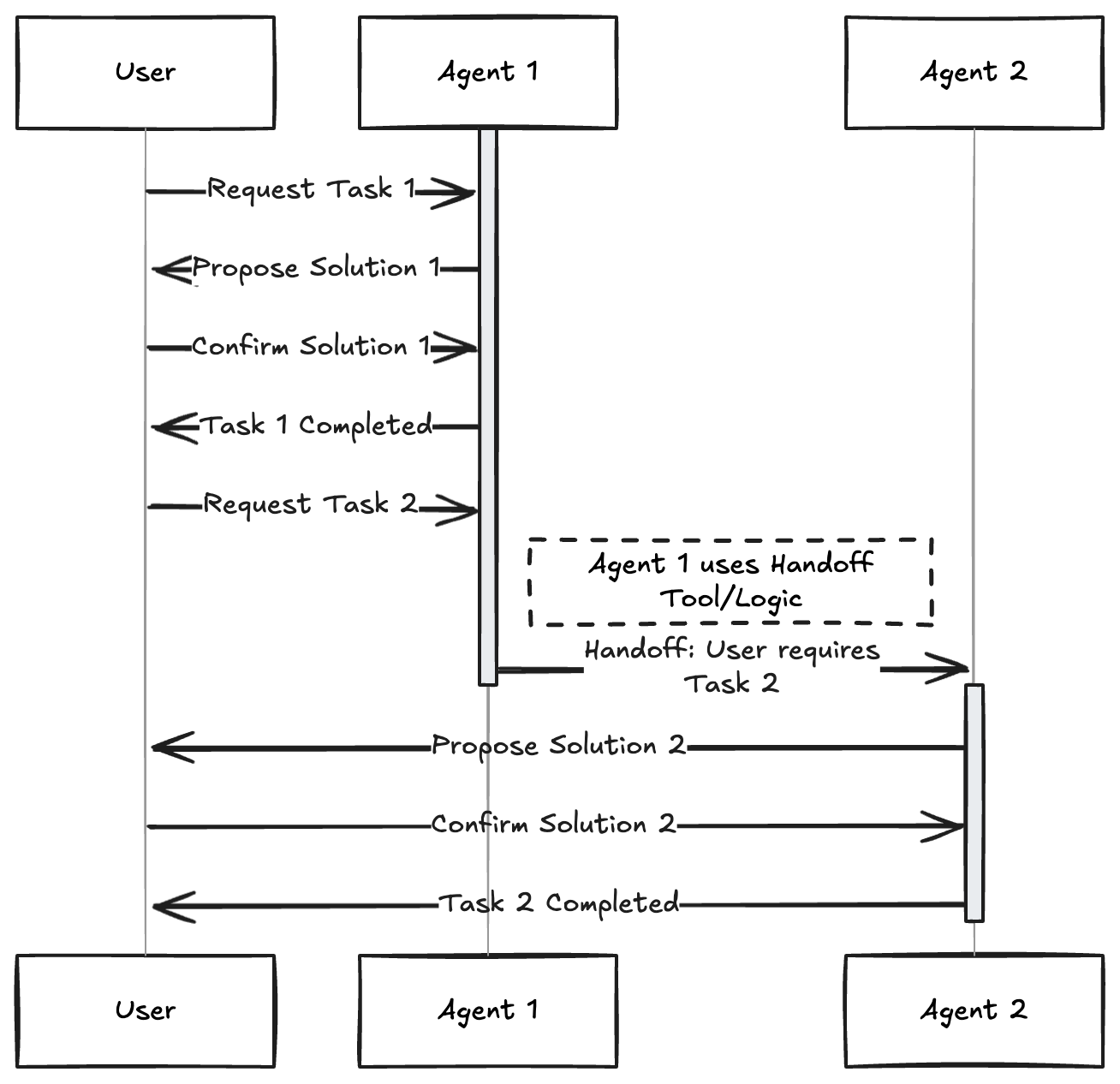
Multiple distinct agents each assigned a specific role, persona, or expertise collaborate to achieve a common goal. This pattern uses autonomous or semi-autonomous agents. Each agent might have a unique role (e.g., Project Manager, Coder, Tester, Critic), specialized knowledge, or access to specific tools. They interact and collaborate, often coordinated by a central "coordinator" or "manager" agent (like the PM in the diagram) or using handoff logic, where one agent passes the control to another agent.
Use Cases:
Simulating debates or brainstorming sessions with different AI personas.Complex software creation involving agents for planning, coding, testing, and deployment.Running virtual experiments or simulations with agents representing different actors.Collaborative writing or content creation processes.
Note: The example below a simplified example on how to use the Multi-Agent pattern with handoff logic and structured output. I recommend to take a look at LangGraph Multi-Agent Swarm or Crew AI
from google import genaifrom pydantic import BaseModel, Field# Configure the client (ensure GEMINI_API_KEY is set in your environment)client = genai.Client(api_key=os.environ["GEMINI_API_KEY"])# Define Structured Output Schemasclass Response(BaseModel): handoff: str = Field(default="", description="The name/role of the agent to hand off to. Available agents: 'Restaurant Agent', 'Hotel Agent'") message: str = Field(description="The response message to the user or context for the next agent")# Agent Functiondef run_agent(agent_name: str, system_prompt: str, prompt: str) -> Response: response = client.models.generate_content( model='gemini-2.0-flash', contents=prompt, config = {'system_instruction': f'You are {agent_name}. {system_prompt}', 'response_mime_type': 'application/json', 'response_schema': Response} ) return response.parsed# Define System Prompts for the agentshotel_system_prompt = "You are a Hotel Booking Agent. You ONLY handle hotel bookings. If the user asks about restaurants, flights, or anything else, respond with a short handoff message containing the original request and set the 'handoff' field to 'Restaurant Agent'. Otherwise, handle the hotel request and leave 'handoff' empty."restaurant_system_prompt = "You are a Restaurant Booking Agent. You handle restaurant recommendations and bookings based on the user's request provided in the prompt."# Prompt to be about a restaurantinitial_prompt = "Can you book me a table at an Italian restaurant for 2 people tonight?"print(f"Initial User Request: {initial_prompt}")# Run the first agent (Hotel Agent) to force handoff logicoutput = run_agent("Hotel Agent", hotel_system_prompt, initial_prompt)# simulate a user interaction to change the prompt and handoffif output.handoff == "Restaurant Agent": print("Handoff Triggered: Hotel to Restaurant") output = run_agent("Restaurant Agent", restaurant_system_prompt, initial_prompt)elif output.handoff == "Hotel Agent": print("Handoff Triggered: Restaurant to Hotel") output = run_agent("Hotel Agent", hotel_system_prompt, initial_prompt)print(output.message)
Combining and Customizing These Patterns
It's important to remember that these patterns aren't fixed rules but flexible building blocks. Real-world agentic systems often combine elements from multiple patterns. A Planning agent might use Tool Use, and its workers could employ Reflection. A Multi-Agent system might use Routing internally for task assignment.
The key to success with any LLM application, especially complex agentic systems, is empirical evaluation. Define metrics, measure performance, identify bottlenecks or failure points, and iterate on your design. Resist to over-engineer.
Acknowledgements
This overview was created with the help of deep and manual research, drawing inspiration and information from several excellent resources, including:
Thanks for reading! If you have any questions or feedback, please let me know on Twitter or LinkedIn.


 Swarm approach
Swarm approach