
I noticed a few folks mention the new Zonos TTS release today, so I wanted to try it out locally. You can read more about it in the beta release announcement.
I’m on Ubuntu 22.04 and I’ve got a 4090, so I need to test new models when they release in order to justify my purchase.
Main Takeway
Using this through Gradio with the default settings isn’t very impressive. When I have more time I’ll fiddle more. The voice cloning is neat, but out of the box right now, I much prefer Kokoro. If you’ve played with it and gotten it to work well, please share what you did.
Installation
If you use Linux and have a 4090 you probably don’t need a guide to help you get Zonos working. Too bad, here it is.
You need espeak-ng installed:
sudo apt install -y espeak-ng
Clone the git repo:
git clone https://github.com/Zyphra/Zonos.git
Move into the new repo:
cd Zonos
Their repo instructions recommend using uv as a package manager, I guess because it’s faster. I’ve never used it but I can’t refuse a recommended tag so I installed it:
uv sync
This creates a new virtual environment which installs Torch and all the nvidia stuff, so it’ll take a few minutes.
Once it has installed all the packages, you then run:
uv sync --extra compile
To test you can then run:
uv run sample.py
This automatically downloaded the model.safetensors file for me, which was 3.25G, but downloaded ridiculously fast (there’s no amount of nostalgia that makes me yearn for the 56k days again).
If everything goes well, you should have a sample.wav file in your directory. It’ll say “hello world”, or at least it’ll supposed to. It’ll really say “hello worl,” because it cuts off the end of everything, unless they fixed that since I’ve written this.
A two second, cut off clip is exciting and all, but I decided to launch the Gradio interface they provided to test it properly:
uv run gradio_interface.py
That’s when I ran into an issue.
OSError: Cannot find empty port in range: 7860-7860. You can specify a different port by setting the GRADIO_SERVER_PORT environment variable or passing the `server_port` parameter to `launch()`.Oops, I’m already using that port. Without checking, it’s probably Kokoro, since I set it up to be my TTS for OpenWebUI.
I opened up the gradio_interface.py file and changed the port:
if __name__ == "__main__": demo = build_interface() demo.launch(server_name="0.0.0.0", server_port=7861, share=True)Then it launched just fine.
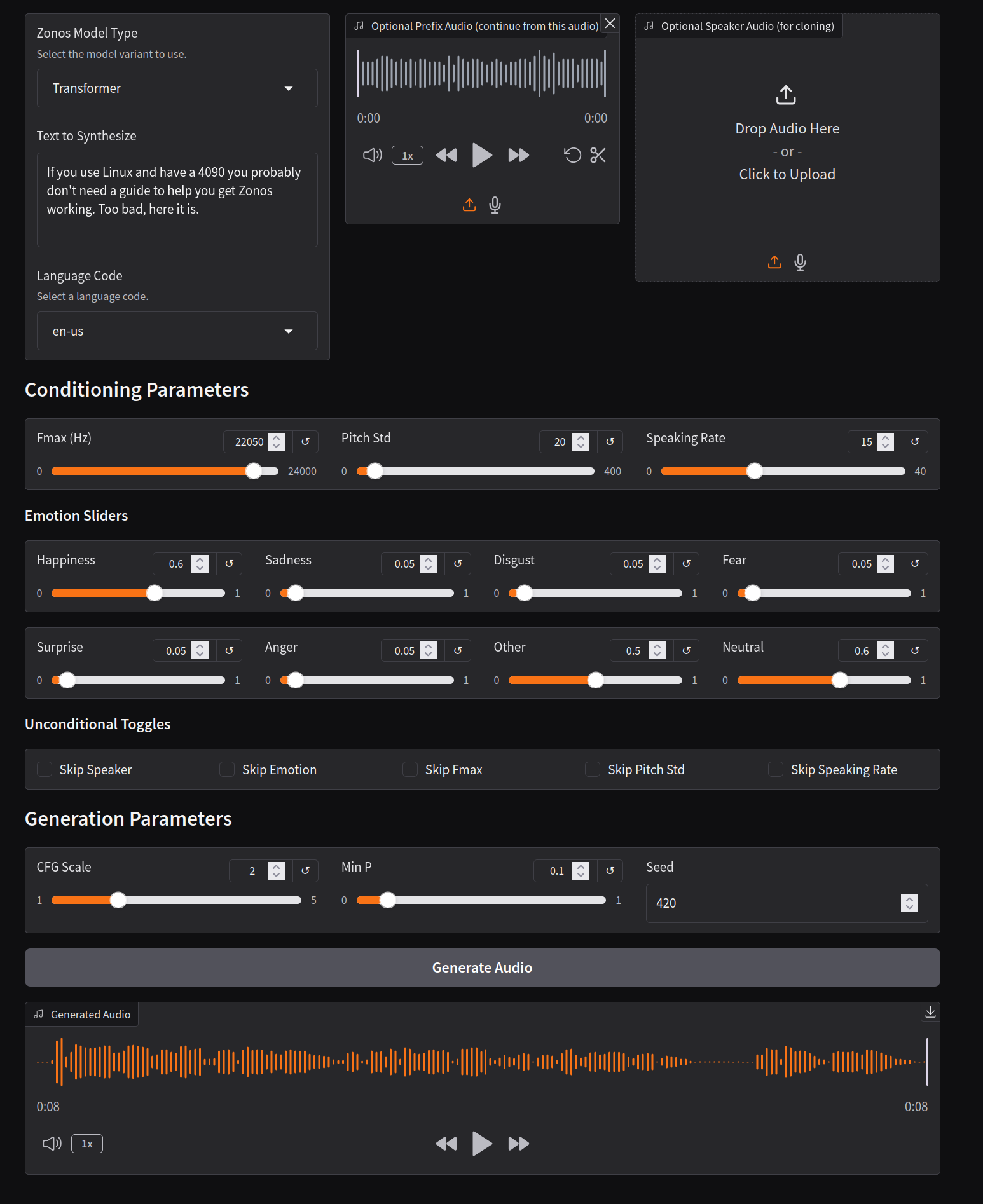
Results
Ok, now what? Well I really wanted to test the voice cloning, because the pranking potential is so high, but first I dutifully testing the straightforward TTS quality.
(Actually, I spent about two hours setting up a screenshot > jsDelivr pipeline so that I could include screenshots in these blog posts easily. But I’ll write about that tomorrow.)
My first test was the introductory paragraph from Winnie-the-Pooh.
It was very… meh, until 30 seconds in, when it got exciting, and by exciting, I mean it burst my eardrums.
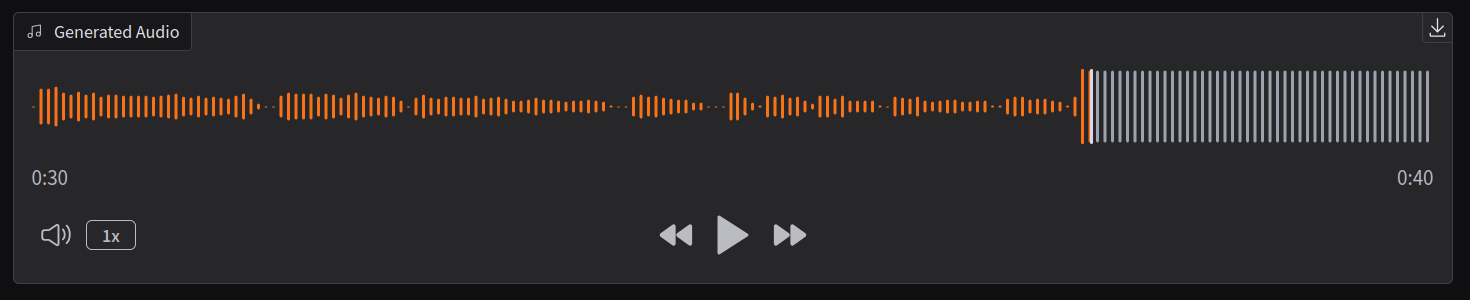
You don’t need to be an audio engineer to know that a waveform probably shouldn’t look like that.
So I tried again, curious to see if 30 seconds was the cutoff.
First impression: It’s not all that fast. The claim is it’s 2X realtime with a 4090. I’ve got a 4090, and… maybe? Most recently I’ve used Kokoro and that’s way, way faster than this, not even close.
Second impression: My first impression might be wrong because it’s over 300 seconds now generating a dinosaur joke I asked phi4 to make. It’s probably borked somehow… yeah errors abound in terminal. It works now, and it’s fairly fast too.
There’s definitely a 30 cut off here. And the quality is weird.
Ok I’m wondering if there’s more of an issue with the Gradio default settings, or me doing something wrong, because this isn’t anywhere as good as Kokoro. I just opened up the Kokoro Gradio interface and tested the same input - Kokoro is much faster, sounds better, and doesn’t choke on anything longer than 30 seconds.
Voice cloning
At this point I’m sure I need to understand how to tune the controls to make this better, but before I spend the time, I wanted to test the voice cloning. I recorded a 20 second .wav of myself, dropped that into the section in Gradio, and then popped in the text I read.
The result was… not bad! Not great, but considering it was only 20 seconds and I haven’t really gotten the hang of using this model yet, I can see why people are excited about this feature.
I’ll keep a cautiously optimistic eye out on this one.
